1.本发明涉及计算机视觉技术,具体涉及一种基于邻域一致和残差排序的指导性数据采样方法及系统。
背景技术:
2.鲁棒模型拟合是人工智能中的一项基础性任务,已用于各种人工智能应用,如视频编码变换估计、增强现实、3d刚性配准和平面检测。鲁棒模型拟合的目是拟合数据中的几何模型假设,并进一步恢复有意义的结构,例如对象形状和运动对象。其中,数据是从输入图像中提取的并且包含离群点和噪声。鲁棒模型拟合技术的成功取决于其采样方法生成的准确假设。大多数采样方法都致力于采样干净的最小子集,以生成更准确的模型假设。
3.基于残差排序的采样算法是最具潜力的指导采样算法之一,因为这类算法善于发现属于同一模型实例(即结构)的内点。然而,从残差排序中计算采样概率相对耗时,并且大多数现有的基于残差排序的采样算法需要计算所有输入数据的采样概率p-1次,以采样包括p个数据点的最小子集。最近,我们提出了一种改进的算法(即ags),该算法只计算对最小子集进行采样的一次采样概率。具体而言,ags首先像大多数现有的基于残差排序的采样算法那样从输入数据中随机选择一个数据点,然后通过使用信息论原理和残差排序计算出的采样概率来选择有意义数据,最后从所选择的有意义数据中采样最小子集。然而,如果这些采样算法选择的第一个数据是离群点,则所采样的数据子集将无效。同时,数据包含的离群点越高,第一个随机选择的数据越有可能是离群点。因此,这些算法不能有效地处理包含高比例离群点的多结构数据。
技术实现要素:
4.有鉴于此,本发明的目的在于提供一种基于邻域一致和残差排序的指导性数据采样方法,可以用于鲁棒模型拟合中,从而应用于视频编码变换估计、增强现实、3d刚性配准和平面检测等计算机视觉任务。
5.为实现上述目的,本发明采用如下技术方案:
6.一种基于邻域一致和残差排序的指导性数据采样方法,包括以下步骤:
7.步骤s1:从输入数据中随机选取一个数据,然后通过计算选定数据点的邻域一致信息来判断该数据点是否为内点;如果选定的数据点是内点,则将选择该数据点作为种子数据,否则,重复执行步骤s1,直到选择一个内点或达到最大重复次数,如果在迭代执行上述步骤后未找到一个内点,则随机选择一个数据点作为种子数据;
8.步骤s2:选定种子数据后,通过残差索引来计算种子数据和输入数据的采样权重;
9.步骤s3利用采样权重从除种子数据以外的输入数据中选取数据子集的其它数据。
10.进一步的,所述步骤s1具体为:
11.(1):给定输入数据x,采样次数z,初始模型假设的个数l,马尔可夫链蒙特卡罗的参数β,种子数据选择最大次数g和批次大小b。
12.(2):判断当前采样次数τ是否小于等于z,如果小于,那么执行步骤(3)至步骤(8);否则,结束程序。
13.(3):判断当前采样次数τ是否小于l,如果小于,那么执行步骤(4);否则,执行步骤(5);
14.(4):用随机采样算法从输入数据中采样一个最小数据子集s
τ
;
15.(5):判断生成的随机数是否小于β,如果小于,那么执行步骤(6);否则,执行步骤(7);
16.(6):使用参数g和领域一致信息尝试选择数据子集的第一个数据,即种子数据;
17.(7):判断是否找到种子数据,如果没有,那么执行步骤(8);
18.(8):随机选择一个数据作为种子数据。
19.进一步的,所述步骤(6),具体为:
20.步骤s61:从输入数据中随机选择一个数据xi={ui,vi};
21.步骤s62:用式(1)判断xi是否为内点
[0022][0023]
其中α是尺度个数,kj是领居个数,表示和特征点ui最近的kj邻居的索引,而表示特征点ui和vi的相同特邻居个数。若pi大于指定阈值,判定xi为内点;否则,为离群点;
[0024]
步骤s63:若xi为内点,把xi设为种子数据并结束子程序;否则,重新执行步骤s61至步骤s63。
[0025]
进一步的,所述残差索引,具体为:
[0026]
(1)把第i个数据点xi与θ中包含的n个模型假设的残差向量记为其中是xi与第j个模型假设的残差;
[0027]
(2)非降序地排列ri中的元素,得到残差索引向量中的元素,得到残差索引向量
[0028]
(3)由残差索引向量,计算不同数据间相关性,相关性值越大,越可能来自同一结构,xi与xj的相关性计算如下的相关性计算如下其中表示κi中的前h个元素,而表示和相同的索引个数。
[0029]
一种基于邻域一致和残差排序的指导性数据采样系统,包括处理器、存储器以及存储在所述存储器上的计算机程序,所述处理器执行所述计算机程序时,具体执行如上所述的基于邻域一致和残差排序的指导性数据采样方法中的步骤。
[0030]
本发明与现有技术相比具有以下有益效果:
[0031]
1、本发明有效地结合了残差排序和邻域一致性信息的优点来进行高效的数据采样;
[0032]
2、本发明采样方法可以用于鲁棒模型拟合中,从而应用于视频编码变换估计、增强现实、3d刚性配准和平面检测等计算机视觉任务。
附图说明
[0033]
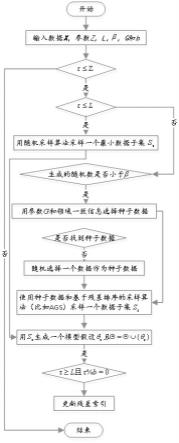
图1是本发明一实施例中算法流程示意图;
[0034]
图2是采用本实施例方法进行三维运动物体分割的例子。
具体实施方式
[0035]
下面结合附图及实施例对本发明做进一步说明。
[0036]
请参照图1-2,本发明提供一种基于邻域一致和残差排序的指导性数据采样方法,包括以下步骤:
[0037]
步骤s1:从输入数据中随机选取一个数据,然后通过计算选定数据点的邻域一致信息来判断该数据点是否为内点;如果选定的数据点是内点,则将选择该数据点作为种子数据,否则,重复执行步骤s1,直到选择一个内点或达到最大重复次数,如果在迭代执行上述步骤后未找到一个内点,则随机选择一个数据点作为种子数据;
[0038]
步骤s2:选定种子数据后,通过残差索引来计算种子数据和输入数据的采样权重;
[0039]
步骤s3利用采样权重从除种子数据以外的输入数据中选取数据子集的其它数据。
[0040]
参考图1,在本实施例中,基于邻域一致和残差排序的指导性数据采样方法,具体为:
[0041]
(1):给定输入数据x,采样次数z,初始模型假设的个数l,马尔可夫链蒙特卡罗的参数β,种子数据选择最大次数g和批次大小b。
[0042]
(2):判断当前采样次数τ是否小于等于z,如果小于,那么执行步骤(3)至步骤(8);否则,结束程序。
[0043]
(3):判断当前采样次数τ是否小于l,如果小于,那么执行步骤(4);否则,执行步骤(5);
[0044]
(4):用随机采样算法从输入数据中采样一个最小数据子集s
τ
;
[0045]
(5):判断生成的随机数是否小于β,如果小于,那么执行步骤(6);否则,执行步骤(7);
[0046]
(6):使用参数g和领域一致信息尝试选择数据子集的第一个数据,即种子数据;
[0047]
(7):判断是否找到种子数据,如果没有,那么执行步骤(8);
[0048]
(8):随机选择一个数据作为种子数据;
[0049]
(9):使用种子数据和基于残差排序的采样算法(比如ags)采样一个数据子集s
τ
。
[0050]
(10):用s
τ
生成一个模型假设θ
τ
并使θ=θ∪{θ
τ
};
[0051]
(11):如果τ大于等于l并且τ整除b,那么执行(12);
[0052]
(12):更新残差索引。
[0053]
优选的,在本实施例中,步骤(6)具体为:
[0054]
步骤s61:从输入数据中随机选择一个数据xi={ui,vi}。
[0055]
步骤s62:用公式(一)判断xi是否为内点
[0056][0057]
其中α是尺度个数,kj是领居个数,表示和特征点ui最近的kj邻居的索引,而
表示特征点ui和vi的相同特邻居个数。若pi大于指定阈值,判定xi为内点;否则,为离群点。
[0058]
步骤s63:若xi为内点,把xi设为种子数据并结束子程序;否则,重新执行步骤s61至步骤s63。
[0059]
在本实施例中,残差索引,具体为:
[0060]
(1)把第i个数据点xi与θ中包含的n个模型假设的残差向量记为其中是xi与第j个模型假设的残差;
[0061]
(2)非降序地排列ri中的元素,得到残差索引向量中的元素,得到残差索引向量
[0062]
(3)由残差索引向量,计算不同数据间相关性,相关性值越大,越可能来自同一结构,xi与xj的相关性计算如下的相关性计算如下其中表示κi中的前h个元素,而表示和相同的索引个数。
[0063]
参考图2,在本实施例中,将图2中的四个场景图像分别作为本实施例方法的输入图像数据,经本实施例步骤后输出的模型参数进行拟合后,把图像中的数据分割为属于不同运动物体的点,不同物体的点用不同形状标识。
[0064]
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。