1.本发明涉及计算机视觉领域,尤其涉及一种基于图神经网络的视频语义生成方法。
背景技术:
2.视频语义生成是计算机视觉领域的一个重要的研究目标。视频语义生成算法接收一个视频输入,根据视频内容生成自然语言描述。这项任务需要算法准确地检测和识别出视频中出现的对象以及这些对象的行为。在完成视频内容检测和识别之后,相关的视觉信息都需要用自然语言进行合理的组织,生成一个可理解且符合语法规则的文本描述。随着计算机视觉技术的不断发展,目标检测、动作识别等技术逐渐成熟,对于视频内容的理解也在往更细致、具体的方向发展。如何在当前已有的技术基础上输出描述更准确、流畅的文本,是当前研究的重点。现有视频语义生成方法对于以下问题仍未提出有效的解决方案:
3.1)忽略了视频中的对象和整个场景的视觉特征的区分,没有充分利用对象和动作特征之间的关联。
4.2)提取出的视频特征含有大量冗余信息,严重影响模型生成的描述文本质量。
技术实现要素:
5.本发明的目的是为了提供一种基于图神经网络的视频语义生成方法,求解了特征之间的关联,有效地去除了特征中存在的冗余信息,提高了生成文本内容的准确性。
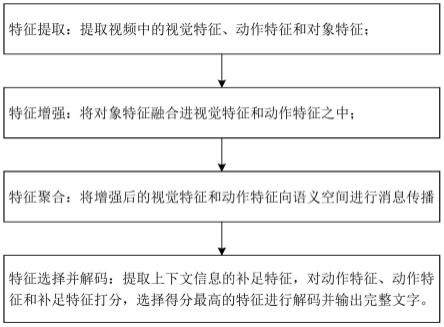
6.为解决以上技术问题,本发明的技术方案为:一种基于图神经网络的视频语义生成方法,包括以下步骤:
7.步骤1,特征提取:提取视频中的视觉特征、动作特征和对象特征;
8.步骤2,特征增强:利用图神经网络求解特征之间的关联,将对象特征融合进视觉特征和动作特征之中,输出增强后的视觉特征和动作特征;
9.步骤3,特征聚合:利用图神经网络的将增强后的视觉特征和动作特征映射至语义空间,将图神经网络的消息传播过程限制在语义空间内部;
10.步骤4,特征选择并解码:提取上下文信息的补足特征,对动作特征、动作特征和补足特征进行打分,选择得分最高的特征进行解码并输出完整文字。
11.进一步地,所述步骤1具体包括:
12.步骤1.1:对于视频中的每一帧采用2d特征提取网络提取包含整体场景信息的视觉特征a;
13.步骤1.2:对于整段视频采用3d特征提取网络提取包含时间轴运动信息的动作特征m;
14.步骤1.3:对于视频中的每一帧进行分区域2d特征提取,得到包含局部对象信息的对象特征o。
15.进一步地,所述步骤1特征提取之前,还包括视频的预处理步骤:原始视频被均匀
采样为视频帧序列。
16.进一步地,步骤2具体包括:
17.步骤2.1:增强视觉特征,具体为:建立视觉特征图神经网络;单帧的视觉特征作为图的一个节点,与所有帧的对象特征节点相连;通过图神经网络的消息传播,将对象特征融合进视觉特征之中,通过计算视觉特征和对象特征之间的长距离依赖,对视觉特征进行增强;
18.视觉特征增强过程如下:
19.a’=a w
·
r(a,o)
20.其中,a’为增强后的视觉特征,r(,)表示计算两个特征之间的相似度,w为调整权重;
21.步骤2.2:用增强视觉特征相同的方式增强动作特征,获得增强后的动作特征m’。
22.进一步地,所述步骤3具体包括:
23.步骤3.1:对视觉特征进行聚合,获得视觉语义特征,具体包括:
24.步骤3.11:将增强后的视觉特征a’作为图神经网络中的节点,构成视觉特征图;在语义空间生成小于视觉特征节点数量的d个新的语义节点za,语义节点za的值随机初始化;将语义节点za与视觉特征a’全连接,形成视觉语义图神经网络;
25.步骤3.12:在视觉语义图神经网络中,由视觉特征节点a’向语义节点za进行消息传播;消息传播流程为:对于每个语义节点与视觉特征a’节点进行全连接,计算关联度编码,对于关联度高的节点进行加权合并后传递给语义节点za;消息传播完成后,视觉语义空间中的节点含有了所有的视频特征信息;
26.步骤3.13:在视觉语义节点之间全连接,进行内部两两消息传播,通过计算视觉语义节点之间的关联度,对节点进行聚合操作,去除冗余节点,得到特征聚合后的视觉语义特征
27.步骤3.2:通过与步骤3.1中聚合视觉特征同样的方式,获得动作语义特征
28.进一步地,所述步骤3.12中,由原始特征空间向视觉语义空间映射的消息传播公式如下:
[0029][0030]
其中,表示第d个语义节点,d的取值范围为1≤d≤d,f代表视频帧序列的长度,a’f
表示增强过后的第f帧视觉特征;ψ(a’f
,θd)表示对a’f
,两个节点之间的关联度进行计算,其中θd是可学习的参数。
[0031]
进一步地,所述步骤3.13中,视觉特征语义空间内部的聚合公式如下:
[0032][0033]
其中,f(φk,φd)表示对两个特征向量进行关联度计算;φk,φd均为可学习的参数;表示内部消息传播过程完成聚合后的网络节点,汇集成视觉语义特征
[0034]
进一步地,所述步骤4具体为:
[0035]
步骤4.1:引入补足特征s,通过对前序时间步生成的文本信息的上下文信息进行编码得到补足特征s;
[0036]
步骤4.2:建立打分模块,在解码器的每个时间步为视觉语义特征动作语义特征和补足特征s计算得分;打分模块由两个全连接层和一个线性激活函数构成;
[0037]
步骤4.3:在正向传播时,根据每个特征的得分选择得分最高的特征作为当前时间步的特征值送入解码器进行解码,输出完整文字;在反向传播时,引入gumbel softmax策略来近似模拟最大值采样;解码器输出和参考文本的语法差距使用kl散度来进行损失计算。
[0038]
进一步地,所述步骤4.2的特征分数计算公式如下:
[0039]
score(v)=fc(tanh(fc(v)))
[0040]
其中,v是s中的一种特征;fc表示全连接层所有特征的平均值,tanh为全连接层激活函数。
[0041]
本发明具有如下有益效果:
[0042]
一、本发明通过图神经网络实现特征增强,求解了对象特征和视觉特征、动作特征之间的关联,捕获了特征之间的长距离依赖,有效地将对象信息融合进视频的视觉特征和动作特征之中,缩小了生成模型的解空间,使得解码器对视频内容的推断更加准确。
[0043]
二、本发明通过图神经网络,将增强后的视频特征映射至语义空间进行精炼,有效地去除了特征矩阵中的冗余向量,突出了视频的重要特征,降低了解码器的解码难度。
[0044]
三、本发明所提出基于特征选择的解码器,在每一个时间步挑选一个合适的特征进行解码,每个被挑选的特征都对应着特定的语法结构。特征选择过程突出了解码器所需要的重要特征,解决了特征融合的难题,提高了生成文本语法结构的准确性。本发明能准确识别视频中出现的对象及其行为,生成语法正确的视频描述。
附图说明
[0045]
图1为本发明方法整体流程图;
[0046]
图2为特征空间向量映射至语义空间示意图;
[0047]
图3为语义空间内部消息传播示意图。
具体实施方式
[0048]
为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图和具体实施例对本发明作进一步详细说明。
[0049]
本发明为一种基于图神经网络的视频语义生成方法,该方法的整体流程图如图1所示,包括以下步骤:
[0050]
骤1,特征提取:提取视频中的视觉特征、动作特征和对象特征;
[0051]
步骤2,特征增强:利用图神经网络求解特征之间的关联,捕获特征之间的长距离依赖,将对象特征融合进视觉特征和动作特征之中,输出增强后的视觉特征和动作特征;
[0052]
步骤3,特征聚合:利用图神经网络的将增强后的视觉特征和动作特征映射至语义空间,将图神经网络的消息传播过程限制在语义空间内部,有效地去除了视频特征的冗余
信息;
[0053]
步骤4,特征选择并解码:提取上下文信息的补足特征,在解码器的每一个时间步对动作特征、动作特征和补足特征进行打分,根据生成文本的语法结构选择得分最高的特征进行解码并输出完整文字。
[0054]
步骤1为特征提取部分,在步骤1中的特征提取之前,对视频进行预处理,原始视频会被均匀采样为视频帧序列。步骤1具体包括:
[0055]
步骤1.1:对于视频预采样后的每一帧采用2d特征提取网络提取包含整体场景信息的视觉特征a;本实施例中,采用inceptionresnetv2(irv2)进行视觉特征提取;
[0056]
步骤1.2:对于整段视频采用3d特征提取网络提取包含时间轴运动信息的动作特征m;本实施例中,采用i3d对视频进行动作特征提取;
[0057]
步骤1.3:对于视频中的每一帧进行分区域2d特征提取,得到包含局部对象信息的对象特征o;本实施例中,采用fasterrcnn的2d深度学习对象提取网络对视频预采样后的每一帧的分区域图像进行对象特征提取。
[0058]
步骤2为特征增强部分,通过对象特征o对视觉特征a和动作特征m进行增强,得到增强后视觉特征a’和增强后动作特征m’;步骤2具体包括:
[0059]
步骤2.1:增强视觉特征,具体为:建立视觉特征图神经网络;单帧的视觉特征作为图的一个节点,与所有帧的对象特征节点相连;通过图神经网络的消息传播,将对象特征融合进视觉特征之中,对视频中某一帧的视觉特征进行增强时,全局的对象特征都会被考虑进去,丰富了特征的上下文信息;通过计算视觉特征和对象特征之间的长距离依赖,对视觉特征进行增强;
[0060]
视觉特征增强过程如下:
[0061]
a’=a w
·
r(a,o)
[0062]
其中,a’为增强后的视觉特征,r(,)表示计算两个特征之间的相似度,w为调整权重;步骤2.2:用增强视觉特征相同的方式增强动作特征,获得增强后的动作特征m’。
[0063]
步骤3为特征聚合部分,对特征进行冗余去除;步骤3具体包括:
[0064]
步骤3.1:对视觉特征进行聚合,获得视觉语义特征,具体包括:
[0065]
步骤3.11:将增强后的视觉特征a’作为图神经网络中的节点,节点之间互不相连接,构成视觉特征图;在语义空间生成小于视觉特征节点数量的d个新的语义节点za,语义节点za的值随机初始化;将语义节点za与视觉特征a’全连接,如图2所示,形成视觉语义图神经网络;
[0066]
步骤3.12:在视觉语义图神经网络中,由视觉特征节点a’向语义节点za进行消息传播,消息传播权重是可学习的参数,用于计算网络节点之间的关联;消息传播流程为:对于每个语义节点与视觉特征a’节点进行全连接,计算关联度编码,对于关联度高的节点进行加权合并后传递给语义节点za;消息传播完成后,视觉语义空间中的节点含有了所有的视频特征信息;
[0067]
由原始特征空间向视觉语义空间映射的消息传播公式如下:
[0068]
[0069]
其中,表示第d个语义节点,d的取值范围为1≤d≤d,f代表视频帧序列的长度,a’f
表示增强过后的第f帧视觉特征;ψ(a’f
,θd)表示对a’f
,两个节点之间的关联度进行计算,其中θd是可学习的参数;
[0070]
步骤3.13:在视觉语义节点之间全连接,进行内部两两消息传播,如图3所示,通过计算视觉语义节点之间的关联度,对节点进行聚合操作,去除冗余节点,得到特征聚合后的视觉语义特征
[0071]
视觉特征语义空间内部的聚合公式如下:
[0072][0073]
其中,f(φk,φd)表示对两个特征向量进行关联度计算;φk,φd均为可学习的参数;表示内部消息传播过程完成聚合后的网络节点,汇集成视觉语义特征
[0074]
步骤3.2:通过与步骤3.1中聚合视觉特征同样的方式,获得动作语义特征
[0075]
步骤4基于特征选择器的解码算法,特征选择机制突出解码器需要的重要特征信息,提高解码器生成文本的质量;步骤4具体为:
[0076]
步骤4.1:引入补足特征s,通过对前序时间步生成的文本信息的上下文信息进行编码得到补足特征s;前面步骤输出的视觉特征用于生成视频描述的主语和宾语,动作特征用于生成视频描述的谓语,补足特征用于生成描述文本中的其余语法成分,从而保证描述文本的语法正确性;
[0077]
步骤4.2:建立打分模块,在解码器的每个时间步为视觉语义特征动作语义特征和补足特征s计算得分;打分模块由两个全连接层和一个线性激活函数构成;
[0078]
特征分数计算公式如下:
[0079]
score(v)=fc(tanh(fc(v)))
[0080]
其中,v是s中的一种特征;fc表示全连接层所有特征的平均值,tanh为全连接层激活函数。
[0081]
步骤4.3:在正向传播时,根据每个特征的得分选择得分最高的特征作为该时间步的特征值送入解码器进行解码,输出完整文字;在反向传播时,引入gumbel softmax策略来近似模拟最大值采样;解码器输出和参考文本的语法差距使用kl散度来进行损失计算。
[0082]
本发明未涉及部分均与现有技术相同或采用现有技术加以实现。
[0083]
以上内容是结合具体的实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
