基于boosting与深度森林及单细胞测序数据的细胞通讯预测方法及应用
技术领域
1.本发明涉及生物信息学的技术领域,更具体地,涉及基于boosting与深度森林及单细胞测序数据的细胞通讯预测方法及应用。
背景技术:
2.在多细胞生物体中,细胞通讯协调各种细胞类型的活动,进而形成组织、器官和系统,并进一步完成各种生物功能。细胞通讯对于复杂的机体过程也是必不可少的,例如,免疫反应、生长以及在健康或疾病条件下的动态平衡。为了解每种细胞类型在其组织中的生物学功能,我们需要了解各类细胞传递的蛋白质信息。
3.单细胞测序技术能准确定量一个单细胞核中基因拷贝数目。由于癌细胞中基因组部分被删除,或者扩增,从而引起关键基因的缺失,或者表达过量,干扰正常细胞生长,因此利用这种方法就能分析基因拷贝数目,从而在癌症诊断上有着广泛的应用。单细胞测序往往能够提供大量的基因数据,如何筛选出细胞之间关键的相互关系有助于揭示通讯细胞间的调控机制,提高研究人员对组织在稳态中的功能以及在疾病变化中的预测准确性。在cn202011620086.x一种细胞通讯分析方法及系统公开了通过细胞通讯预测和配体-靶基因调控预测;细胞通讯预测包括配受体对表达丰度分析、配受体对数目分析、显著富集配受体对数目分析和细胞交互网络图构建;配体-靶基因调控预测包括配体活性分析和配体-靶基因调控潜力分析来描述细胞间的关联关系。虽然该专利的细胞通讯分析过程较为高效、全面。但是,该方法性能较低,未能将预测结果可视化,同时缺乏对肿瘤微环境的分析,对于细胞内通讯的分泌配体和质膜受体之间的相互作用调节,即配体-受体相互作用来说,对配体-受体相互作用预测的准确性仍有一定的限制。
技术实现要素:
4.本发明要解决的技术问题是针对现有由配体-受体相互作用介导的细胞通讯预测准确性不足、有待提高的问题,提供一种基于boosting与深度森林及单细胞测序数据的细胞通讯预测方法。
5.本发明的另一技术问题是提供基于boosting与深度森林及单细胞测序数据的细胞通讯预测方法的应用。
6.本发明的目的通过以下技术方案予以实现:
7.一种基于boosting与深度森林及单细胞测序数据的细胞通讯预测方法,步骤包括:
8.s1.对配体和受体的序列进行生物特征提取,使用极限梯度算法选择每个配体-受体对的生物特征;
9.s2.采用梯度提升算法lri-catboost,根据配体-受体对的生物特征对其进行分类;
10.s3.采用基于自然梯度提升模型lri-ngboost,根据配体-受体对的生物特征对其进行分类;
11.s4.采用深度森林算法,将配体-受体的生物特征分为正类和负类,分别计算并选择具有较大概率的类别并作为最终类别;
12.s5.对过滤已知及预测的配体-受体相互作用数据进行过滤;
13.s6.根据过滤后的的配体-受体相互作用、单细胞测序数据和评分方法进行计算得到最终的细胞通讯强度。
14.进一步地,所述生物特征包括400维的monomono、8000维的monodi、8000维的dimono、147维的ctd及80维的pseudoaac。
15.进一步地,所述极限梯度算法为:
[0016][0017]
其中,i为第i个样本,i
l
表示左侧节点空间中的样本数,gi为一阶偏导数,hi为二阶偏导数,λ和γ表示正则化参数。
[0018]
进一步地,梯度提升算法lri-catboost分类步骤包括:
[0019]
s21.使用自上而下的贪心算法以实现对称决策树,每个决策规则r由一个特征i∈{1,..,l}和一个阈值v∈r组成,在树的每一层,决策规则r将k个不相交的集合分割成2k个不相交的子集,对于一个具有k'级的完整二叉树k=2k′
,一组特征向量x∈r被分成两个完全独立的子集(x
l
和xr),对于每个x∈x,lri-catboost根据这两个子集来确定其类别:
[0020][0021]
s22.当给定一个集合和一个目标函数t:r
l
→
r,分割规则定义为:
[0022][0023]
其中m用于评估x1,..,xk上的分割规则r的最优性;
[0024]
s23.得到预测模型m
i,j
,其中m
i,j
(i)表示基于排列σr中前j个样本的第i个样本的结果,在每次迭代t中,从{σ1,...,σs}构建一棵树t
t
并计算其梯度:
[0025][0026]
s24.计算每个样本i的梯度grad
r,σ(i)-1
(i),当所有可能的作用对都被预测后,样本i的叶子值通过计算之前与样本i属于同一叶子的样本的梯度grad
r,σ(i)-1
(i)的平均值得出,建立树状结构t
t
后,对未知的配体-受体对进行分类。
[0027]
进一步地,m可以定义为:
[0028][0029]
其中表示关于xi中样本的目标分数集合。
[0030]
进一步地,lri-ngboost模型由三部分组成:基本学习器、参数概率分布和预测规则。对于一个样本x,lri-ngboost通过条件分布p
θ
预测其标签y,其中参数θ是由初始θ
(0)
和m个基础分类器输出的组合实现的。对于参数为μ和logσ的正态分布,每个阶段都有两个基础分类器和因此
[0031]
进一步地,对于一个样本x,lri-ngboost通过条件分布p
θ
预测其标签y,其中参数θ是由初始θ
(0)
和m个基础分类器输出的组合实现的,对于参数为μ和logσ的正态分布,每个阶段都有两个基础分类器和和预测的输出是由阶段性的比例系数p
(m)
和学习率η来评估的,其中缩放因子ρ
(m)
是一个单一的标量:
[0032][0033]
进一步地,选择随机森林和额外树作为基分类器,对于一个配体-受体相互作用特征,每个预测器计算每层中对应于正类和负类的特征样本的比率,从所有预测器得到的类别概率产生一个类别向量,该向量与原始的配体-受体相互作用特征向量相连接,并作为下面一层深度森林的输入;
[0034]
当预测性能优于前面的所有层时,在模型中增加一个新层;当后面两层的性能没有提高时,训练终止,最后分别对属于正类和负类的每个配体-受体对计算相互作用概率的平均值,具有较大平均相互作用概率的类别被作为最终类别。
[0035]
进一步地,所述评分方法为表达乘积法和表达阈值法的结合,其细胞通讯分数计算方法为:
[0036][0037]
其中,f1(k1,k2)为基于表达乘积法计算的细胞通讯分数,g1(k1,k2)为基于表达阈值法计算的细胞通讯分数。
[0038]
进一步地,所述基于表达乘积法计算的细胞通讯分数为:
[0039][0040]
所述基于表达阈值法计算的细胞通讯分数为:
[0041][0042]
其中,为基于表达乘积法计算的、由配体i-受体j相互作用介导的细胞类型和的通讯强度得分,为基于表达阈值法计算的、由配体i-受体j相互作用介导的细胞类型和的通讯强度得分。
[0043]
进一步地,本发明还可以对细胞通讯预测的结果可视化。
[0044]
根据上述基于boosting与深度森林及单细胞测序数据的细胞通讯预测方法应用于预测人类肿瘤组织中的细胞通讯。
[0045]
与现有技术相比,有益效果是:
[0046]
本发明通过在提取配体和受体生物特征的基础上,设计极限梯度提升算法选择配体-受体对的特征。然后基于类别特征梯度提升算法、自然梯度提升算法和深度森林模型,设计集成框架预测配体-受体相互作用。再根据单细胞测序数据过滤已知和预测的配体-受体相互作用,并结合表达乘积法和表达阈值法对肿瘤微环境下的细胞通讯进行预测。本发明所述方法能够提高细胞通讯的预测效果。
附图说明
[0047]
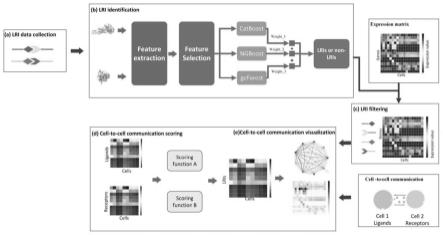
图1是细胞通讯预测流程图;
[0048]
图2是配体-受体相互作用预测框架流程图;
[0049]
图3是本发明所述方法在数据集1-4的auc曲线图;
[0050]
图4是本发明所述方法在数据集1-4的aupr曲线图;
[0051]
其中,a为数据集1,b为数据集2,c为数据集3,d为数据集4;
[0052]
图5是人类头颈部鳞状细胞癌组织中细胞通讯配体-受体相互作用热力图;
[0053]
图6是人类头颈部鳞状细胞癌组织中细胞通讯强度热力图;
[0054]
图7是人类头颈部鳞状细胞癌组织中细胞通讯强度网络图;
[0055]
图8是人类乳腺癌组织中细胞通讯配体-受体相互作用热力图;
[0056]
图9是人类乳腺癌组织中细胞通讯强度热力图;
[0057]
图10是人类乳腺癌组织中细胞通讯强度网络图。
具体实施方式
[0058]
下面结合实施例进一步解释和阐明,但具体实施例并不对本发明有任何形式的限定。若未特别指明,实施例中所用的方法和设备为常规方法和设备,所用原料均为常规市售原料。
[0059]
实施例1
[0060]
如图1-2,本实施例提供一种基于boosting与深度森林及单细胞测序数据的细胞通讯预测方法,具体步骤包括:
[0061]
s1.对配体和受体的序列进行生物特征提取,得到包括400维的monomono、8000维的monodi、8000维的dimono、147维的ctd及80维的pseudoaac。每个配体或受体可以被描述为一个16,627维的向量,一个配体-受体对可以被表示为一个33,254维的向量。使用极限梯度算法选择每个配体-受体对的生物特征。所述的极限梯度算法为:
[0062][0063]
其中,i
l
表示左侧节点空间中的样本数。λ和γ表示正则化参数。
[0064]
更高的特征增益意味着更有效和更重要的特征。在特征选择后,每个配体-受体对被描述为一个d维向量。
[0065]
s2.采用梯度提升算法lri-catboost,基于配体-受体相互作用的生物特征进行分类;
[0066]
设d=(x,y)表示具有n个配体-受体对的数据集,其中x表示具有d维特征向量的训练样本,y∈y表示其标签。对于第i个配体-受体对xi,如果它相互作用,yi=1,否则yi=0。
[0067]
使用自上而下的贪心算法来实现对称决策树,每个决策规则r由一个特征i∈{1,..,l}和一个阈值v∈r组成,在树的每一层,决策规则r将k个不相交的集合分割成2k个不相交的子集。特别是,对于一个具有k'级的完整二叉树k=2k′
,一组特征向量x∈r被分成两个完全独立的子集(x
l
和xr)。对于每个x∈x,lri-catboost可以根据这两个子集来确定其类别:
[0068][0069]
因此,基于分割规则的任意k个互不相干的集合都可以用来实现2k个互不相干的集合
[0070]
当给定一个集合和一个目标函数t:r
l
→
r,分割规则定义为:
[0071][0072]
其中m用于评估x1,..,xk上的分割规则r的最优性。m可以定义为:
[0073][0074]
其中表示关于xi中样本的目标分数集合。
[0075]
得到预测模型m
i,j
,其中m
i,j
(i)表示基于排列σr中前j个样本的第i个样本的结果。在每次迭代t中,从{σ1,...,σs}构建一棵树t
t
并计算其梯度:
[0076][0077]
对于每个样本i,其梯度grad
r,σ(i)-1
(i)可以被计算出来。当所有可能的作用对都被预测后,样本i的叶子值可以通过计算之前与样本i属于同一叶子的样本的梯度grad
r,σ(i)-1
(i)的平均值得出。当树状结构t
t
建立后,可以对未知的配体-受体相互作用数据进行分类。
[0078]
s3.采用自然梯度提升模型lri-ngboost,预测每一个配体-受体对的相互作用概率;
[0079]
lri-ngboost模型由三部分组成:基分类器(f)、参数概率分布(p
θ
)和预测规则(s)。对于一个样本x,lri-ngboost通过条件分布p
θ
预测其标签y,其中参数θ是由初始θ
(0)
和m个基础分类器输出的组合实现的。对于参数为μ和logσ的正态分布,每个阶段都有两个基分类器和因此因此预测的输出是由阶段性的比例系数p
(m)
和学习率η来评估的,其中缩放因子ρ
(m)
是一个单一的标量:
[0080][0081]
s4.采用深度森林算法,将配体-受体的生物特征分为正类和负类,分别计算并选择具有较大平均相互作用概率的类别被作为最终类别;
[0082]
选择随机森林和额外树作为基分类器,每个级联层由2个随机森林和2个额外树组成。每个预测器由100棵决策树组成。对于一个配体-受体相互作用特征,每个预测器计算每层中对应于正类和负类的特征样本的比率。从所有预测器得到的类别概率产生一个类别向
量。该向量与原始的配体-受体相互作用特征向量相连接,并作为下面一层深度森林的输入。
[0083]
当预测性能优于前面的所有层时,我们在模型中增加一个新层。当后面两层的性能没有提高时,训练将终止。最后,分别对属于正类和负类的每个配体-受体对的相互作用概率计算平均值。具有较大平均相互作用概率的类别被作为最终类别。
[0084]
最后,我们通过集成lri-catboost、lri-ngboost和lri-df的结果,得到每个配体-受体对的最终分类。
[0085]
s5.过滤已知及已识别的配体-受体相互的作用。如果某个配体-受体相互作用中的配体或受体在单细胞测序数据的细胞中没有表达,则该配体-受体相互作用被排除在相应的细胞通讯中。
[0086]
s6.根据过滤后的的配体-受体相互作用、单细胞测序数据和评分方法进行计算得到最终通讯分数。
[0087]
所述评分方法采用表达乘积法和表达阈值法的组合。
[0088]
(1)表达乘积法:预测配体i和受体j与两种细胞类型和相互作用的得分,其中表示配体i和受体j在细胞类型中的算术平均值:
[0089][0090]
和之间的细胞通讯分数f1(k1,k2)可以计算出来:
[0091][0092]
(2)表达阈值法:预测配体i和受体j与两种细胞类型和的相互作用得分,其中σi和σj表示标准偏差:
[0093][0094]
和之间的细胞通讯分数g1(k1,k2)可以计算出来:
[0095][0096]
对基于表达乘积法和表达阈值法计算的和之间的细胞通讯分数f1(k1,k2)和g1(k1,k2),将其结合起来得到最终的细胞通讯分数。也就是说,和之间的细胞通讯分数可通过下式计算出来:
[0097][0098]
实施例2
[0099]
本实施例提供本发明所述细胞通讯预测算法和四种有代表性的蛋白质相互作用预测方法,即极限梯度提升算法、支持向量机、基于决策树算法的分布式梯度提升框架和基于序数回归的循环卷积神经网络算法的性能,进行了20次5折交叉验证来评估,以auc和aupr作为评估指标,auc和aupr数值越高意味着算法性能越好。
[0100]
将极限梯度提升算法、支持向量机和基于决策树算法的分布式梯度提升框架的参数设置为默认值。对于基于序数回归的循环卷积神经网络算法,参数设置如下:learning_rate=0.01,n_estimators=20,max_depth=3,criterition=friedman_mse,loss=
deviance,min_samples_split=2。对于本发明提出的细胞通讯预测算法,我们分别将lri-catboost中的boosting类型、max_depth和n_estimators设置为ordered、10和2000;lri-ngboost中的学习率、自然梯度、frac和eval设置为0.01、true、1.0和100;lri-df中的n_trees设置为100,以及predictor设置为森林。降维后配体-受体相互作用特征向量的维度设置为300。
[0101]
在本实验中,我们收集了四个不同的配体-受体相互作用数据集。数据集1和2均来自celltalk数据库。数据集3是由skelly等人构建。数据集4是由ximerakis等人构建。具体的数据集情况如下表1所示:
[0102]
表1
[0103]
数据集配体受体配体-受体相互作用数据集18127803390数据集26505882031数据集35745592006数据集4112913356585
[0104]
根据上述不同方法获得的性能如下表2所示:
[0105]
表2
[0106][0107]
由上表2以及图3-4可知,本发明所述的配体-受体相互作用预测算法在四个数据集上获得了最好的auc和aupr,在四个数据集上获得的最佳auc分别为0.8533、0.8316、0.8150和0.8434,分别比排名第二的基于决策树算法的分布式梯度提升框架性能高出1.39%、3.29%、3.59%和1.89%。同时,本发明也在四个数据集上取得了最佳aupr,分别为0.8681、0.8442、0.8259和0.8632,分别比排名第二的基于决策树算法的分布式梯度提升框架性能高出1.11%、2.19%、2.11%和1.54%。本发明所述的配体-受体相互作用预测算法lri-cnbdp在本实验所用四个数据集上取得了最好的auc和aupr,证明了其强大的配体-受体相互作用预测性能。
[0108]
实施例3
[0109]
本实施例提供本发明所述方案在实际中的预测应用,分别从geo数据库下载人类头颈部鳞状癌组织中细胞,细胞类型包括头颈部鳞状细胞癌细胞、母纤维细胞、b细胞、肌细
胞、巨噬细胞、内皮细胞、t细胞、树突状细胞和肥大细胞的相关测序数据,并结合本发明中过滤后的配体-受体相互作用和单细胞测序数据,建立与乳腺癌相关的细胞通讯网络,进行人类组织中的细胞通讯预测。如图5-7所示,本发明所述方法发现在人类头颈部鳞状细胞中,母纤维细胞与人类头颈部鳞状细胞癌细胞的通讯强度更高。
[0110]
实施例4
[0111]
本实施例提供本发明所述方案在实际中的预测应用,分别从geo数据库下载人类乳腺组织中细胞癌组织中的相关测序数据,并结合本发明中过滤后的配体-受体相互作用和单细胞测序数据,建立与乳腺癌相关的细胞通讯网络,进行人类组织中的细胞通讯预测。如图8-10所示,在人类乳腺癌组织中,免疫细胞和乳腺癌细胞的通讯概率更高。
[0112]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。