1.本发明属于自然语言处理的文本摘要技术中序列到序列文本摘要技术领域,并特别涉及一种基于因果关系的序列到序列文本摘要生成方法及系统。
背景技术:
2.自动文本摘要技术旨在从输入文档中自动识别重要主题和关键信息,并生成准确、简洁又流畅的文本作为摘要。早期的摘要技术主要围绕人工设计的启发式规则和模板进行探究;如今,基于神经网络的深度文本摘要技术成为主流。它通过有监督训练端到端地学习原文和摘要的匹配模式,可分为抽取式和生成式摘要方法。
3.深度抽取式摘要方法抽取原文中的句子子集作为摘要文本。它通常将摘要任务转换为序列标注或排序形式的任务,通过对文档中每个侯选句子进行二分类标注,或者对侯选句子按照重要程度排序来选择关键句子构成摘要。深度生成式摘要方法则将摘要任务视为序列到序列的生成任务,以词语或短语作为基本生成单元,从无到有地生成摘要。由于摘要文本不拘泥于原始文本的表达,因此该方法生成的摘要具备更高的灵活性和多样性,适用性更强。
4.近年来,以transformer为主要结构的预训练模型为深度文本摘要方法进一步带来了性能增益。生成式方法从预训练模型中继承了优秀的语言表达能力。结合自身适用性强的优势,基于预训练模型的生成式摘要方法逐渐成为主流的研究课题。
5.基于预训练模型的生成式摘要方法存在以下缺点。
6.(1)首先,现有技术中的数据驱动方法缺乏可解释性。这是由于在端到端的训练方式中,用户只需给模型喂入样本及其标签,模型自动学习原文和摘要的匹配模式,这种“黑盒模式”对用户来说是不可理解的。
7.(2)然后,现有技术生成的摘要常会包含多余的信息。这些冗余信息并非原文中的核心信息。这是由于现有技术在学习原文和摘要的匹配模式时,倾向于利用数据集中所有的相关关系,其中包含大量伪相关关系,继承了训练语料库中的统计偏差。这时模型容易被数据集中易学的表面特征所误导,比如高频共现但不具备必然联系的文本对。例如,“红色枫叶”作为高频共现的文本对,“红色”和“枫叶”具备高度统计相关性,但不具备必然的因果关系,“枫叶”也可以是“绿色”的。
技术实现要素:
8.本发明的目的是解决上述现有技术过度依赖相关关系、容易受伪相关误导的问题,提出了一种受因果理论启发的序列到序列框架。
9.本发明还提出了一种基于因果关系的序列到序列文本摘要生成方法,其中包括:
10.步骤1、将原文档输入基于神经网络的双隐变量变分编码器,该双隐变量变分编码器对该原文档进行多次采样提取该原文档中摘要相关特征和摘要无关特征;
11.步骤2、拼接该摘要相关特征和摘要无关特征,得到摘要综合特征,基于该摘要综
合特征对原文档进行重构,得到重构文档,并以该原文档为训练目标,基于该重构文档和该训练目标构建损失函数,训练双隐变量变分编码器;
12.步骤3、采用训练完成后的双隐变量变分编码器提取该原文档的摘要相关特征作为目标特征,基于该目标特征,得到该原文档的文本摘要。
13.所述的基于因果关系的序列到序列文本摘要生成方法,其中该步骤1包括:
14.通过文档编码器得到文档的编码表示向量,该双隐变量变分编码器中的文档编码器对该原文档x进行编码,得到文档的编码表示向量h
doc
;
15.双隐变量变分编码器模块中的变分编码器对文档的编码表示向量h
doc
进行编码及采样,分别得到隐变量hc和h
nc
;
16.将hc和h
nc
输入原文重构解码器,得到每个位置上的输出oi;叠加hc和h
nc
和oi,输入语言模型输出层生成重构的原文档x
′
;根据x
′
和x计算重构损失lr;存储lr最小时对应的隐变量表示hc和h
nc
分别作为该摘要相关特征和该摘要无关特征。
17.所述的基于因果关系的序列到序列文本摘要生成方法,其中该步骤3包括:
18.摘要预测解码器根据该目标特征,计算每个位置上的输出rj;叠加该目标特征和rj,输入语言模型输出层,得到词表分布概率,以生成对应的词语组成该文本摘要。
19.所述的基于因果关系的序列到序列文本摘要生成方法,其中该双隐变量变分编码器、该摘要预测解码器和该原文重构解码器三者的训练方法为:
20.获取训练文档和对应的参考摘要,将训练文档输入基于神经网络的双隐变量变分编码器,得到隐变量表示hc和h
nc
;同时分别得到hc和h
nc
的高斯分布和
21.使用隐变量表示hc和h
nc
生成重构原文;并使用隐变量表示hc生成摘要结果;
22.基于训练文档和重构原文构建原文重构损失lr;基于该参考摘要和该摘要结果构建摘要预测损失l
p
;基于标准正态分布和该高斯分布计算kl散度;
23.最终的训练损失函数为l=lr l
p
λl
kl
,其中λ用于调整分布规范化约束的程度,基于该训练损失函数为l训练该双隐变量变分编码器、该摘要预测解码器和该原文重构解码器。
24.本发明还提出了一种基于因果关系的序列到序列文本摘要生成系统,其中包括:
25.采样模块,用于将原文档输入基于神经网络的双隐变量变分编码器,该双隐变量变分编码器对该原文档进行多次采样提取该原文档中摘要相关特征和摘要无关特征;
26.拼接模块,用于拼接该摘要相关特征和摘要无关特征,得到摘要综合特征,基于该摘要综合特征对原文档进行重构,得到重构文档,并以该原文档为训练目标,基于该重构文档和该训练目标构建损失函数,训练双隐变量变分编码器;
27.提取模块,用于以训练完成后的双隐变量变分编码器提取该原文档的摘要相关特征作为目标特征,基于该目标特征,得到该原文档的文本摘要。
28.所述的基于因果关系的序列到序列文本摘要生成系统,其中该采样模块用于:
29.通过文档编码器得到文档的编码表示向量,该双隐变量变分编码器中的文档编码器对该原文档x进行编码,得到文档的编码表示向量h
doc
;
30.双隐变量变分编码器模块中的变分编码器对文档的编码表示向量h
doc
进行编码及采样,分别得到隐变量hc和h
nc
;
31.将hc和h
nc
输入原文重构解码器,得到每个位置上的输出oi;叠加hc和h
nc
和oi,输入语言模型输出层生成重构的原文档x
′
;根据x
′
和x计算重构损失lr;存储lr最小时对应的隐变量表示hc和h
nc
分别作为该摘要相关特征和该摘要无关特征。
32.所述的基于因果关系的序列到序列文本摘要生成系统,其中该提取模块用于:
33.摘要预测解码器根据该目标特征,计算每个位置上的输出rj;叠加该目标特征和rj,输入语言模型输出层,得到词表分布概率,以生成对应的词语组成该文本摘要。
34.所述的基于因果关系的序列到序列文本摘要生成系统,其中该双隐变量变分编码器、该摘要预测解码器和该原文重构解码器三者的训练方法为:
35.获取训练文档和对应的参考摘要,将训练文档输入基于神经网络的双隐变量变分编码器,得到隐变量表示hc和h
nc
;同时分别得到hc和h
nc
的高斯分布和
36.使用隐变量表示hc和h
nc
生成重构原文;并使用隐变量表示hc生成摘要结果;
37.基于训练文档和重构原文构建原文重构损失lr;基于该参考摘要和该摘要结果构建摘要预测损失l
p
;基于标准正态分布和该高斯分布计算kl散度;
38.最终的训练损失函数为l=lr l
p
λl
kl
,其中λ用于调整分布规范化约束的程度,基于该训练损失函数为l训练该双隐变量变分编码器、该摘要预测解码器和该原文重构解码器。
39.本发明还提出了一种存储介质,用于存储执行所述任意一种基于因果关系的序列到序列文本摘要生成方法的程序。
40.本发明还提出了一种客户端,用于所述任意一种基于因果关系的序列到序列文本摘要生成系统。
41.由以上方案可知,本发明的ci-seq2seq框架与现有技术相比的优势在于:
42.(1)更强的可解释性。与现有技术笼统地学习原文的表示相比,本专利提出的方法能够有效地判别和提取原文中sc和snc的隐变量表示hc和h
nc
。我们通过t-sne可视化分析对所学隐变量表示的分布情况进行验证,如图1所示。从图1可以看出学到的hc和h
nc
表示的分布空间明显不同:hc的分布空间更加集中,而h
nc
的分布空间则更加分散。这证明了sc和snc分别学到了核心信息和表示多样性的信息。
43.(2)更好的摘要性能。与现有技术相比,本专利提出的方法能够有效地提升摘要生成的质量。我们在公开的摘要数据集cnn/dm和xsum上进行实验,将ci-seq2seq与其他基线模型对比。对比的基线模型包括两个同样基于变分自编码器实现的unified vae-pgn、vhtm,三个经典的通用预训练模型t5、bart、glm,以及使用对比学习、对抗学习和长度可控等方法实现的cliff、debiased-ext和ptlaam。评价指标是rouge-1、rouge-2和rouge-l,它们分别衡量了单词、二元词组和最长公共子序列的召回率。对比结果如表1所示。根据表1可以看到,不仅是和其他基于变分自编码器实现的模型、通用强大的预训练模型,还是和使用其他训练技巧的模型相比,我们提出的方法在两个数据集上的所有指标都能获得明显提
升。
44.表1:cnn/dm和xsum数据集上的摘要性能比较
[0045][0046]
(3)更强的泛化能力。与现有技术相比,本专利提出的方法能够有效地提升模型的泛化能力。我们将在cnn/dm上训练的模型用于xsum测试集,将在xsum上训练的模型用于cnn/dm测试集,由此测试不同模型在未见过的数据集上的表现能力,实验结果见表2。通过与原始框架bart进行对比,我们的方法能够获得一定的提升,证明了我们的模型具备更强的泛化能力。
[0047]
表2:cnn/dm和xsum数据集上交叉实验的泛化性能比较
[0048]
附图说明
[0049]
图1为t-sne可视化分析示意图;
[0050]
图2是使用ci-seq2seq生成摘要文本的总流程图;
[0051]
图3是使用ci-seq2seq生成摘要文本时,通过n次采样得到初始隐变量表示和的流程图;
[0052]
图4是使用ci-seq2seq生成摘要文本时,通过k轮迭代更新得到最优隐变量表示和的流程图;
[0053]
图5是使用ci-seq2seq生成摘要文本时,使用最优隐变量表示生成摘要的流程图;
[0054]
图6是本发明方法的训练过程图。
具体实施方式
[0055]
发明人结合因果理论对文本摘要任务进行研究时,发现现有技术生成冗余摘要的缺陷是由对数据集中相关关系的过度依赖导致的。现有技术过度依赖摘要任务中各成分的相关关系,而没有考虑更本质的因果关系。因果关系描述了潜在的数据生成过程,现有技术仅仅依赖可观测变量难以刻画数据背后自然的因果关系。
[0056]
本发明引入两个不可观测变量并使用因果感知建模相应的数据生成过程,以解决现有技术过度依赖相关关系、容易受伪相关误导的问题。具体而言,本发明为摘要任务设计了一个结构因果模型,其中涉及到的变量除了可观测的原文和摘要外,还包含两个不可观测变量,分别表示决定摘要内容的信息(summary-causal factors,sc),如原文中的核心信息,和语料库中不决定摘要内容的其他信息(summary-non-causal factors,snc),如导致
原文生成多样性的边缘信息。两个不可观测变量的根本区别在于只有前者sc是摘要产生的原因。通过显式地区分两种信息,本发明设计了一个受因果理论启发的序列到序列框架(causality inspired sequence-to-sequence model,ci-seq2seq)来刻画摘要和文本的生成过程,在生成摘要时只利用sc,而在生成原文时两者都使用。模型结构上,本发明对传统的序列到序列框架中的编码器-解码器架构做出如下改进:将单编码器、单解码器改进为双隐变量变分编码器、原文重构解码器和摘要预测解码器。具体来说本发明包括如下关键技术点:
[0057]
关键点1,从数据生成过程的角度设计的文本摘要结构因果模型;技术效果:根据该结构因果模型设计的文本摘要方法能够显式地区分两种信息,学到sc和snc各自的表示,具备更强的可解释性;
[0058]
关键点2,受因果理论启发的序列到序列框架ci-seq2seq;技术效果:该框架能够有效区分sc和snc并获得各自的表示,其中sc的表示用于生成摘要,sc和snc都用于生成原文;该框架基于有监督的变分自编码器实现,能有效提高生成摘要的质量。其中核心模块包括:双隐变量变分编码器:利用神经网络,将原文编码为sc和snc的隐变量表示;原文重构解码器:利用神经网络,将sc和snc的隐变量表示进行解码,用于重构原文;摘要预测解码器:利用神经网络,将sc的隐变量表示进行解码,用于预测摘要。
[0059]
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
[0060]
如图2所示,是相应的总流程图。本发明生成摘要文本的总体流程包括以下几个步骤:
[0061]
步骤s1:输入原文档x,将输入原文档x输入基于神经网络的双隐变量变分编码器模块。
[0062]
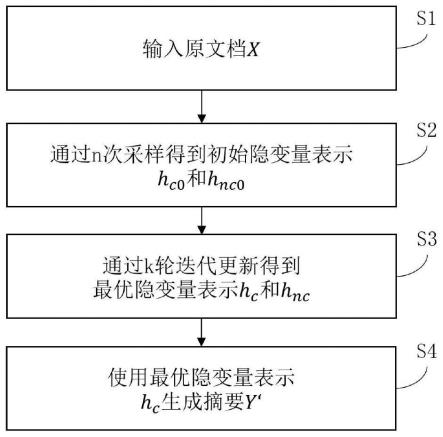
步骤s2:通过n次采样得到初始隐变量表示h
c0
和h
nc0
。具体流程如图3所示,包括如下子步骤:
[0063]
步骤s201:通过文档编码器得到文档的编码表示向量h
doc
。双隐变量变分编码器模块中的文档编码器对输入的原文档x进行编码,得到文档的编码表示向量h
doc
。
[0064]
步骤s202:通过变分编码器得到隐变量sc和snc的高斯分布。双隐变量变分编码器模块中的变分编码器对文档的编码表示向量h
doc
进行进一步编码,得到隐变量sc和snc的高斯分布(分布参数为μc、μ
nc
和)。
[0065]
步骤s203:通过隐变量采样器获得隐变量表示hc和h
nc
。隐变量采样器根据上一步得到的高斯分布进行采样,分别得到隐变量sc和snc的表示hc和h
nc
。其中采样过程通过经典的再参量化(reparametrization)技术完成。具体来说,先从标准正态分布中采样得到变量εc和ε
nc
,即,即再根据如下公式分别得到所需的隐变量表示hc和h
nc
:
[0066]
hc=μc σc*εc,
[0067]hnc
=μ
nc
σ
nc
*ε
nc
.
[0068]
步骤s204:将隐变量表示hc和h
nc
拼接得到的h
cnc
输入原文重构解码器。将上一步得到的隐变量表示hc和h
nc
进行拼接,得到h
cnc
,作为原文重构解码器的初始输入。
[0069]
步骤s205:通过原文重构解码器得到oi。原文重构解码器根据初始输入,计算每个
位置上的输出oi。位置即原文词序列中,按照从左到右的顺序,每个位置对应一个词。
[0070]
步骤s206:叠加h
cnc
和oi,输入语言模型输出层。将步骤s204得到的h
cnc
叠加到上一步得到的oi上,作为语言模型输出层的输入。其中语言模型输出层是现有技术,基于线性变换和束搜索(beam search)实现。
[0071]
步骤s207:通过语言模型输出层生成重构的原文档x
′
。语言模型输出层将上一步得到的结果通过线性变换映射到词表上,得到词表分布概率,并根据束搜索方法生成对应的词语组成原文档x
′
。
[0072]
步骤s208:根据x
′
和x计算重构损失lr。将重构的原文档x
′
和输入的原文档x进行比对,计算重构损失lr。
[0073]
生成原文是为了获取对于当前原文来说最佳的sc表示hc和snc表示h
nc
,其中hc将用于摘要的生成。因训练和测试时原文都是给定的,所以本发明使用原文作为监督信号:重构原文后,将生成的原文x
′
和给定的原文x比对,根据重构的误差确定最优的隐变量表示hc和h
nc
,其中hc将用于摘要的生成。即准确的sc表示既能和snc共同作用,很好地重构原文信息,又能单独作用生成摘要。当一个sc表示能够很好地重构原文时,即也适合用来生成摘要。
[0074]
步骤s209:存储当前最小lr对应的隐变量表示hc和h
nc
。对比本次循环中的lr和目前最小lr的大小,将本次循环后最小lr对应的隐变量表示hc和h
nc
进行存储。
[0075]
步骤s210:得到初始隐变量表示h
c0
和h
nc0
。将上述步骤(s203~s209)重复n次,通过多次采样,返回使重构损失lr最小的隐变量表示hc和h
nc
作为初始隐变量表示h
c0
和h
nc0
。
[0076]
步骤s3:通过k轮迭代更新得到最优隐变量表示hc和h
nc
。如图4所示,具体流程包括以下子步骤:
[0077]
步骤s301:使用初始隐变量表示h
c0
和h
nc0
初始化隐变量表示hc和h
nc
。根据步骤s2得到的初始隐变量表示h
c0
和h
nc0
,初始化隐变量sc和snc的表示hc和h
nc
。
[0078]
步骤s302:将隐变量表示hc和h
nc
拼接得到的h
cnc
输入原文重构解码器。将上一步得到的隐变量表示hc和h
nc
进行拼接,得到h
cnc
,作为原文重构解码器的初始输入。
[0079]
步骤s303:通过原文重构解码器得到oi。原文重构解码器根据初始输入,计算每个位置上的输出oi。
[0080]
步骤s304:叠加h
cnc
和oi,输入语言模型输出层。将步骤s302得到的h
cnc
叠加到上一步得到的oi上,作为语言模型输出层的输入。
[0081]
步骤s305:通过语言模型输出层生成重构的原文档x
′
。语言模型输出层将上一步得到的结果映射到词表上,得到词表分布概率,并生成对应的词语组成原文档x
′
。
[0082]
步骤s306:根据x
′
和x计算重构损失lr。将重构的原文档x
′
和输入的原文档x进行比对,计算重构损失lr。
[0083]
步骤s307:优化得到新的隐变量表示hc和h
nc
。根据重构损失lr和adam优化算法优化隐变量表示hc和h
nc
。具体的优化过程如下:首先将隐变量表示设置为可学习的参数,然后对其设置专门的adam优化器;对于上一步计算的重构损失lr,通过反向传播算法进行梯度回传,最后根据adam算法直接更新可学习的隐变量表示hc和h
nc
。
[0084]
步骤s308:得到最优隐变量表示hc和h
nc
。将上述步骤(s302~s307)重复k次,通过多次优化,返回最优隐变量表示hc和h
nc
。
[0085]
综上,步骤s2和s3的目的都是为了获得准确的隐变量表示,其评价依据均为重构损失。s2作为s3的前序步骤,用于后者的初始化。技术上,它获得隐变量的方式是多次采样。而s3则是基于s2得到的最优初始化向量进行后续的优化操作。具体的优化过程如下:首先将隐变量表示设置为可学习的参数,然后对其设置专门的adam优化器;对于上一步计算的重构损失lr,通过反向传播算法进行梯度回传,最后根据adam算法直接更新可学习的隐变量表示hc和h
nc
。好的初始化对于优化过程来说至关重要,并且优化操作的耗时更长。因此在s2时先通过多次采样的方式来选择当前最佳的表示,更加快捷。
[0086]
步骤s4:使用最优隐变量表示hc生成摘要y
′
。如图5所示,具体流程包括以下子步骤:
[0087]
步骤s401:将最优隐变量表示hc输入摘要预测解码器。将步骤s3得到的最优隐变量表示hc作为摘要预测解码器的初始输入。
[0088]
步骤s402:通过摘要预测解码器得到rj。摘要预测解码器根据初始输入,计算每个位置上的输出rj。
[0089]
步骤s403:叠加hc和rj,输入语言模型输出层。将步骤s401的hc叠加到上一步得到的rj上,作为语言模型输出层的输入。
[0090]
步骤s404:通过语言模型输出层生成预测的摘要y
′
。语言模型输出层将上一步得到的结果映射到词表上,得到词表分布概率,并生成对应的词语组成摘要y
′
。
[0091]
上述是本发明的使用过程,现对本发明方法的训练过程说明如下。相应的训练流程图如图6所示。
[0092]
步骤s1:输入原文档x和参考摘要y。将输入原文档x输入基于神经网络的双隐变量变分编码器模块。
[0093]
步骤s2:通过采样得到隐变量表示hc和h
nc
。具体步骤参考使用过程的s201~s203。该步骤会得到隐变量sc和snc的高斯分布和(分布参数μc、μ
nc
为均值,为方差)。
[0094]
步骤s3:使用隐变量表示hc和h
nc
生成原文x
′
。具体步骤参考使用过程的s204~s207。
[0095]
步骤s4:使用隐变量表示hc生成摘要y
′
。具体步骤参考使用过程的s4。
[0096]
步骤s5:计算训练损失并优化模型。
[0097]
训练损失由三部分组成:原文重构损失lr、摘要预测损失l
p
以及分布约束损失l
kl
。
[0098]
原文重构损失lr是基于输入的原文档x和重构的x
′
计算的交叉熵,目的是为了训练双隐变量变分编码器和原文重构解码器。
[0099]
摘要预测损失l
p
是基于输入的参考摘要y和预测的y
′
计算的交叉熵,目的是为了训练双隐变量变分编码器和摘要预测解码器。
[0100]
分布约束损失l
kl
是基于标准正态分布(0,i)和隐变量sc/snc的高斯分布(由步骤s2得到)计算的kl散度,目的是为了训练双隐变量变分编码器,使预测的变量分布更加规范化。
[0101]
最终的训练损失函数为l=lr l
p
λl
kl
,其中λ用于调整分布规范化约束的程度。
[0102]
根据上述训练损失函数,采用adam优化器训练模型。
[0103]
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
[0104]
本发明还提出了一种基于因果关系的序列到序列文本摘要生成系统,其中包括:
[0105]
采样模块,用于将原文档输入基于神经网络的双隐变量变分编码器,该双隐变量变分编码器对该原文档进行多次采样提取该原文档中摘要相关特征和摘要无关特征;
[0106]
拼接模块,用于拼接该摘要相关特征和摘要无关特征,得到摘要综合特征,基于该摘要综合特征对原文档进行重构,得到重构文档,并以该原文档为训练目标,基于该重构文档和该训练目标构建损失函数,训练双隐变量变分编码器;
[0107]
提取模块,用于以训练完成后的双隐变量变分编码器提取该原文档的摘要相关特征作为目标特征,基于该目标特征,得到该原文档的文本摘要。
[0108]
所述的基于因果关系的序列到序列文本摘要生成系统,其中该采样模块用于:
[0109]
通过文档编码器得到文档的编码表示向量,该双隐变量变分编码器中的文档编码器对该原文档x进行编码,得到文档的编码表示向量h
doc
;
[0110]
双隐变量变分编码器模块中的变分编码器对文档的编码表示向量h
doc
进行编码及采样,分别得到隐变量hc和h
nc
;
[0111]
将hc和h
nc
输入原文重构解码器,得到每个位置上的输出oi;叠加hc和h
nc
和oi,输入语言模型输出层生成重构的原文档x
′
;根据x
′
和x计算重构损失lr;存储lr最小时对应的隐变量表示hc和h
nc
分别作为该摘要相关特征和该摘要无关特征。
[0112]
所述的基于因果关系的序列到序列文本摘要生成系统,其中该提取模块用于:
[0113]
摘要预测解码器根据该目标特征,计算每个位置上的输出rj;叠加该目标特征和rj,输入语言模型输出层,得到词表分布概率,以生成对应的词语组成该文本摘要。
[0114]
所述的基于因果关系的序列到序列文本摘要生成系统,其中该双隐变量变分编码器、该摘要预测解码器和该原文重构解码器三者的训练方法为:
[0115]
获取训练文档和对应的参考摘要,将训练文档输入基于神经网络的双隐变量变分编码器,得到隐变量表示hc和h
nc
;同时分别得到hc和h
nc
的高斯分布和
[0116]
使用隐变量表示hc和l
nc
生成重构原文;并使用隐变量表示hc生成摘要结果;
[0117]
基于训练文档和重构原文构建原文重构损失lr;基于该参考摘要和该摘要结果构建摘要预测损失l
p
;基于标准正态分布和该高斯分布计算kl散度;
[0118]
最终的训练损失函数为l=lr l
p
λl
kl
,其中λ用于调整分布规范化约束的程度,基于该训练损失函数为l训练该双隐变量变分编码器、该摘要预测解码器和该原文重构解码器。
[0119]
本发明还提出了一种存储介质,用于存储执行所述任意一种基于因果关系的序列到序列文本摘要生成方法的程序。
[0120]
本发明还提出了一种客户端,用于所述任意一种基于因果关系的序列到序列文本
摘要生成系统。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。