1.本发明属于供应搜索技术领域,具体涉及一种寻找供应商的搜索方法。
背景技术:
2.在建筑建造领域中,服务于不同领域的供应商数量众多,例如供应钢筋材料的供应商有十几万家,供应混凝土的供应商也有七万家以上。由于建筑建造领域对原材料质量、工艺等都有相关要求,并且大规模材料运输会导致成本增高,所以采购商需要考虑在建筑地寻找符合原材料要求的优良供应商。目前采购商主要是通过线下供需会、微信、交换名片等方式,这将使得采购商难以快速准确获取供应商信息,严重伤害了采购体验,甚至延误项目进展周期。
3.因此,本发明提供了一种寻找供应商的搜索方法,以至少解决上述部分技术问题。
技术实现要素:
4.本发明要解决的技术问题是:提供一种寻找供应商的搜索方法,用于解决当下供采双方在时间、人力、费用上等无效消耗,有助于改善寻找供应商的匹配度。
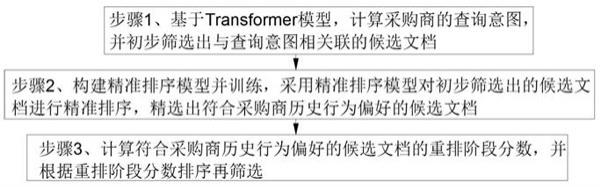
5.为实现上述目的,本发明采用的技术方案如下:一种寻找供应商的搜索方法包括以下步骤:步骤1、基于transformer模型,计算采购商的查询意图,并初步筛选出与查询意图相关联的候选文档;步骤2、构建精准排序模型并训练,采用精准排序模型对初步筛选出的候选文档进行精准排序,精选出符合采购商历史行为偏好的候选文档;步骤3、计算符合采购商历史行为偏好的候选文档的重排阶段分数,并根据重排阶段分数排序再筛选。
6.进一步地,所述步骤1包括:步骤11、基于查询向量qi和候选文档集合向量di,构建短期历史查询日志us和长期历史查询日志u
l
;步骤12、将查询向量qi和历史查询日志us作为输入,通过transformer模型得到采购商当前的查询意图qs;步骤13、将长期历史查询日志u
l
作为输入,通过transformer模型得到采购商的长期交互行为输出o
l
,再由长期交互行为输出o
l
和查询意图qs加权求和得到查询意图qs的动态表征;步骤14、将查询意图qs的动态表征与候选文档d进行匹配,筛选出与查询意图相关联的候选文档,并结合查询意图qs计算出采购商查询意图与候选文档的相关性。
7.进一步地,所述短期历史查询日志us构建为:将查询向量qi和候选文档集合向量di的平均值相加,得到搜索意图hi=qi average(di),构建us={h
n 1
,...h
t-1
},其中n是历史会话中发出的查询数,t为当前时间戳;所述长期历史查询日志u
l
构建为:将查询向量qi和候选文档集合向量di的平均值相加得到搜索意图hi=qi average(di),构建u
l
={h1,...hn},其中n是历史会话中发出的查询
数。
8.进一步地,所述查询意图qs构建为:将短期历史查询日志us={h
n 1
,...h
t-1
}和查询向量qi输入至transformer模型中,由公式qs=transformer
last
([us,q])得到查询意图qs,其中q为当前查询关键词,last表示transformer模型输出最后位置表征向量。
[0009]
进一步地,所述长期交互行为输出o
l
构建为:将长期历史查询日志u
l
={h1,...hn}输入至transformer模型中,由公式o
l
=transformer(u
l
)得到长期交互行为输出o
l
;所述动态表征由公式得到,其中,oi为长期交互行为输出o
l
的某个长期交互,为长期交互oi的权重;所述通过查询意图qs和对应的长期交互oi作为mlp网络的输入获取得到,具体公式为:,其中为激活函数。
[0010]
进一步地,所述候选文档的相关性采用相关性分数进行评价,所述相关性分数由公式计算,其中pd为文档的相关性分数、d为候选文档集合向量di中的某个文档向量,q为当前查询关键词,函数sim(
·
)通过余弦相似度计算得到,c是一个闸门权重调节长期和当前兴趣的因子。
[0011]
进一步地,所述精准排序模型构建为:保留deepfm模型的fm部分,并将deepfm模型的dnn部分替换为share bottom模型的共享底层结构,并构建精准排序模型的损失函数为:其中xi为输入特征,yi为点击目标的类标,zi为供应商停留时长,为采购商和供应商线上发起时通信系统的会话轮数,f
ctr
(xi,θ)为模型输出的预估点击概率,f
dur
(xi,θ)为模型输出的预估停留时长,f
im
(xi,θ)为精准排序模型输出的预估会话轮数,l1为二分类交叉熵损失函数,θ为精准排序模型的排序参数,分别为采购商的点击时长、停留时长和会话轮数的调节权重,n为样本总数。
[0012]
进一步地,所述精准排序模型的的预测分数为:进一步地,所述精准排序模型的的预测分数为:为fm部分的输出结果,为dnn部分的输出结果。
[0013]
进一步地,所述重排阶段分数计算公式为:,,其中l为精排排序列表总长度,i表示供应商位置的索引值,page表示供应商页数的索引值,表示分页惩罚因子,γ是位置惩罚因子,score为精准排序模型的的预测分数。
[0014]
与现有技术相比,本发明具有以下有益效果:传统搜索引擎通常采用同一套规则进行排序,极易产生头部效应,形成强者更强
情形。本发明以采购商长短期历史查询意图为依据,个性化召回符合该采购商兴趣的供应信息,然后构建精准排序模型进一步精排,充分发掘采购商的历史行为偏好,并综合供应商的基本信息、风控信息等达到对采购商的个性化排序搜索效果,确保搜索的有效性和公平性。
附图说明
[0015]
图1为本发明方法流程图。
具体实施方式
[0016]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进一步详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0017]
transformer模型是一种机器学习模型。
[0018]
deepfm模型是一种深度学习模型,包括deepfm模型和dnn部分;fm全称为factorization machines,是因子分解机;deepfm模型中的fm部分是用于进行一阶和二阶的特征交叉;deepfm模型中dnn部分是深度神经网络部分。
[0019]
share bottom为一种多目标学习模型。
[0020]
如图1所示,本发明提供的一种寻找供应商的搜索方法,包括以下步骤:步骤1、基于transformer模型,计算采购商的查询意图,并初步筛选出与查询意图相关联的候选文档;步骤2、构建精准排序模型并训练,采用精准排序模型对初步筛选出的候选文档进行精准排序,精选出符合采购商历史行为偏好的候选文档;步骤3、计算符合采购商历史行为偏好的候选文档的重排阶段分数,并根据重排阶段分数排序再筛选。搜索引擎中,用户(采购商)通常会在一个会话中对单个需求提出一系列查询。因此,短期历史记录中最近的交互有助于澄清当前查询的意图,特别是当前查询不明确时。
[0021]
本发明所述步骤1基于采购商查询意图,应用transformer模型对候选文档进行个性化召回并粗步筛选,对于短期历史中的每个交互的查询和文档,通过word2vec向量表示并通过单词嵌入将单词相加。所述短期历史查询日志us构建为:将查询向量qi和候选文档集合向量di的平均值相加,得到搜索意图hi=qi average(di),构建us={h
n 1
,...h
t-1
},其中n是历史会话中发出的查询数,t为当前时间戳。然后将查询向量qi和历史查询日志us作为输入,通过transformer模型得到采购商当前的查询意图qs。所述查询意图qs构建为:将短期历史查询日志us={h
n 1
,...h
t-1
}和查询向量qi输入至transformer模型中,由公式qs=transformer
last
([us,q])得到查询意图qs,其中q为当前查询关键词,last表示transformer模型输出最后位置表征向量。
[0022]
长期的搜索行为通常反映了用户稳定的兴趣,为了模拟用户的长期兴趣,本发明基于transformer模型构建表示历史行为之间长期依赖关系的长期历史查询日志u
l
。所述长期历史查询日志u
l
构建为:将查询向量qi和候选文档集合向量di的平均值相加得到搜索
意图hi=qi average(di),构建u
l
={h1,...hn},其中n是历史会话中发出的查询数。然后将长期历史查询日志u
l
={h1,...hn}输入至transformer模型中,由公式o
l
=transformer(u
l
)得到长期交互行为输出o
l
={o1,...on}。然而并不是所有的长期交互oi都对当前的查询意图具有价值,为此由公式得到动态表征,其中为对应于长期交互行为输出o
l
中每个长期交互oi的权重。特别地,所述通过查询意图qs和对应的oi作为mlp网络的输入获取,具体公式为:。
[0023]
最后,将查询意图qs的动态表征与候选文档d进行匹配,筛选出与查询意图相关联的候选文档,并结合查询意图qs计算出采购商查询意图与候选文档的相关性。查询意图与候选文档的相关性采用相关性分数进行评价,相关性分数可作为后期候选文档筛选的其他考虑参数。所述相关性分数由公式计算,其中pd为文档的相关性分数、d为候选文档集合向量di中的某个文档向量,q为当前查询关键词,函数通过余弦相似度计算得到,c是一个闸门权重调节长期和当前兴趣的因子。为此,以采购商长短期历史查询意图为依据,个性化召回符合该采购商查询兴趣的供应信息,步骤1可初步筛选出2000~3000个符合采购商查询兴趣的候选文档。
[0024]
本发明所述步骤2为初筛选候选文档的进一步精准排序,构建精准排序模型并训练,采用精准排序模型对初步筛选出的候选文档进行精准排序,精选出符合采购商历史行为偏好的候选文档。所述精准排序模型为deepfm模型加上share bottom模型,具体构建为:保留deepfm模型的fm部分,并将deepfm模型的dnn部分替换为share bottom模型共享底层结构,被用作多目标排序,有助于降低过拟合风险,利用任务之间的关联性使模型学习效果更强;deepfm加上share bottom模型输入比粗排模型多了交互类特征,如历史履约信息(如:近60或120天历史履约商品、区域、品牌等),为此精选出符合采购商历史行为偏好的候选文档。基于上述步骤1初选出的2000~3000个候选文档,步骤2进一步进行筛选,得到500~800个候选文档。deepfm模型加上share bottom模型训练数据选取点击样本为正样本,曝光未点击样本为负样本,点击目标使用二分类交叉熵,停留时长目标使用平方损失对停留时长做回归,会话轮数目标使用平均绝对值误差损失做回归,具体表现为精准排序模型的损失函数为:其中,xi为输入特征,yi为点击目标的类标,zi为供应商停留时长,为采购商和供应商线上发起时通信系统的会话轮数,f
ctr
(xi,θ)为模型输出的预估点击概率,f
dur
(xi,θ)为模型输出的预估停留时长,f
im
(xi,θ)为精准排序模型输出的预估会话轮数,l1为二分类交叉熵损失函数,θ为精准排序模型的排序参数,α、β、δ分别为采购商的点击时长、停留时长和会话轮数的调节权重,n为样本总数。
[0025]
所述精准排序模型的输入特征主要供应商基础信息(如:公司id,公司名称,注册地区,经营区域,成立时长等)、履约信息(履约商品名称,履约品牌名称,履约区域等)、关联
履约信息,(如:采购商历史招标品类,区域,品牌等)、风控信息(违约次数,立案信息数量,失信公告数量等),综合供应商的各种信息优化个性化排序。
[0026]
在一种实施例中,所述精准排序模型的的预测分数为:在一种实施例中,所述精准排序模型的的预测分数为:为fm部分的输出结果,为dnn部分的输出结果。
[0027]
为了进一步提高部分尾部供应商的露出机会,保证供应商互相公平竞争,本发明对符合采购商历史行为偏好的候选文档重排再筛选,通过计算符合采购商历史行为偏好的候选文档的重排阶段分数,并根据重排阶段分数排序再筛选。所述重排阶段分数计算公式为:,,其中l为精排排序列表总长度,i表示供应商位置的索引值,page表示供应商页数的索引值,α0表示分页惩罚因子,γ是位置惩罚因子,score为精准排序模型的的预测分数。根据试验所得,γ取值越小或者α0取值越大时,重排效果越不明显,反之效果明显,经试验证明,α0=1.1、γ=0.25时,重排效果最好。根据各候选文档的重排阶段分数,由大到小对候选文档进行排序,最终可筛选出100~200个候选文档。
[0028]
最后应说明的是:以上各实施例仅仅为本发明的较优实施例用以说明本发明的技术方案,而非对其限制,当然更不是限制本发明的专利范围;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围;也就是说,但凡在本发明的主体设计思想和精神上作出的毫无实质意义的改动或润色,其所解决的技术问题仍然与本发明一致的,均应当包含在本发明的保护范围之内;另外,将本发明的技术方案直接或间接的运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
