技术特征:
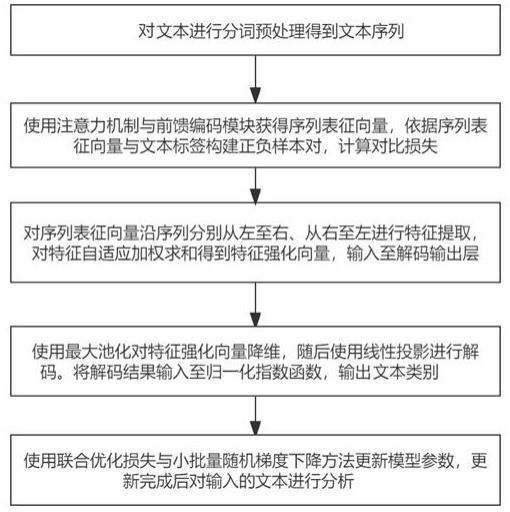
1.用于文本情感分析的对比优化编解码模型,其特征在于,包括:编码对比层:通过预处理分词模块对文本进行预处理分词,通过自注意力模块和前馈编码模块将预处理分词后的文本编码为序列表征向量,并计算有监督对比学习损失;自适应特征强化层:对序列表征向量进行局部语义抽取与强化,得到相应的特征强化向量;解码输出层;将特征强化向量进行解码,得到解码结果并最终输出模型判定的文本情感类别,并对模型判定的文本情感类别与数据集标签计算分类损失;以及优化分析层:有监督对比学习损失和分类损失的联合损失为模型联合优化损失,通过模型联合优化损失与小批量随机梯度下降方法更新模型各项参数矩阵与自适应系数后,使用优化模型对输入的文本进行情感分析。2.根据权利要求1所述的用于文本情感分析的对比优化编解码模型,其特征在于,所述编码对比层包括:对文本进行预处理分词得到文本序列的预处理分词阶段;以及将预处理后的文本编码为序列表征向量,并计算有监督对比学习损失的编码对比阶段;其中,所述编码对比阶段包括:s2.1:将待分析文本映射为词向量、编码向量、句间分隔向量,三种向量相加得到输入向量,s2.2:将输入向量传输至自注意力模块,计算文本序列中上下文语义之间关联程度,得到注意力序列,其中,为信息文本批量大小,为序列字符长度,为词向量维度,、与为注意力权重矩阵,与相乘得到注意力权重变量、,为向量的维度;s2.3:将注意力序列传输至前馈编码模块,进行维度转化与随机丢弃;根据不同的丢弃率对同一注意力序列进行两次编码得到序列表征向量与,
其中,为具有单隐藏层的全连接层;s2.4:将序列表征向量、及批量大小中具有相同标签的共同组成正样本对,剩余样本构成负样本对计算有监督对比学习,其中,是数据集样本总数,为超参数,计算公式如下:。3.根据权利要求2所述的用于文本情感分析的对比优化编解码模型,其特征在于,所述自注意力模块将向量作为输入,计算文本序列中上下文语义之间关联程度,得到注意力序列,其中,为信息文本批量大小,为序列字符长度,为词向量维度。4.根据权利要求3所述的用于文本情感分析的对比优化编解码模型,其特征在于,所述前馈编码模块将注意力序列作为输入,进行维度转化与随机丢弃;根据不同的丢弃率对同一注意力序列进行两次编码得到序列表征向量与。5.根据权利要求2所述的用于文本情感分析的对比优化编解码模型,其特征在于,所述自适应特征强化层对输入的序列表征向量进行局部语义抽取与强化,得到相应的特征强化向量,包括:s3.1:将隐藏状态 与细胞状态初始化为0,当前时刻输入为,此时为从左至右遍历取得的文本表征向量,运算得到、、、四种候选状态:
其中,为相应的权重系数矩阵,为上一时刻的隐藏状态,;s3.2:根据、、、四种候选状态得到传输状态、与局部特征向量,其中,为权重系数矩阵,为哈德玛积;s3.3:将隐藏状态 与细胞状态初始化为0,当前时刻输入;其中为信息文本批量大小,为序列字符长度,为词向量维度,此时为从右至左遍历取得的文本表征向量,按照公式(10)-(16)计算得到局部特征;s3.4:对局部特征向量与进行自适应加权求和得到特征强化向量,其中,为自适应系数,由模型优化学习得到。6.根据权利要求5所述的用于文本情感分析的对比优化编解码模型,其特征在于,所述解码输出层的解码输出阶段包括:s4.1:使用最大池化操作在dim=1维度上,将特征强化向量降维成;s4.2:通过线性投影将解码映射为,
其中,为信息文本标签类别数量,为投影权重系数矩阵,为投影偏差;s4.3:将输入至归一化指数函数,输出模型判定的信息文本情感类别,s4.4:对模型判定的信息文本情感类别与数据集标签进行损失计算,得到分类损失,其中,,为信息文本批量大小,为当前计算的样本。7.根据权利要求6所述的用于文本情感分析的对比优化编解码模型,其特征在于,所述优化分析包括:s5.1:模型联合优化损失为有监督对比学习损失与分类损失的联合损失,;s5.2:通过模型联合优化损失与小批量随机梯度下降方法更新模型各项参数矩阵与自适应系数;s5.3:冻结更新优化完毕的模型参数,使用模型对输入的信息文本进行情感分析。8.用于文本情感分析的对比优化编解码方法,其特征在于,包括数据集构建阶段:构建待分析文本的文本分类数据集并进行标签化;编码对比阶段:将通过预处理分词模块预处理分词后的文本编码为序列表征向量,并计算有监督对比学习损失;自适应特征强化阶段:对序列表征向量进行局部语义抽取与强化,得到相应的特征强化向量;解码输出阶段:对特征强化向量进行解码,得到解码结果并最终输出模型判定的文本情感类别,并对模型判定的文本情感类别与数据集标签计算分类损失,优化分析阶段:有监督对比学习损失和分类损失的联合损失为模型联合优化损失,通过模型联合优化损失与小批量随机梯度下降方法更新模型各项参数矩阵与自适应系数后,使用优化模型对输入的文本进行情感分析。
技术总结
本发明公开了用于文本情感分析的对比优化编解码模型及方法,包括:将通过预处理分词模块预处理分词后的文本编码为序列表征向量,并计算有监督对比学习损失;对序列表征向量进行局部语义抽取与强化,得到相应的特征强化向量;对特征强化向量进行解码,得到解码结果并最终输出模型判定的文本情感类别,并对模型判定的文本情感类别与数据集标签计算分类损失,有监督对比学习损失和分类损失的联合损失为模型联合优化损失,通过模型联合优化损失与小批量随机梯度下降方法更新模型各项参数矩阵与自适应系数后,使用优化模型对输入的文本进行情感分析;实现一文多义文本的语义分离、有效提升文本分析精确度。效提升文本分析精确度。效提升文本分析精确度。
技术研发人员:熊曙初 吴佳妮 李轩 孟晗 殷琪 段金焱 方诺基
受保护的技术使用者:湖南工商大学
技术研发日:2022.12.05
技术公布日:2022/12/30
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。