技术特征:
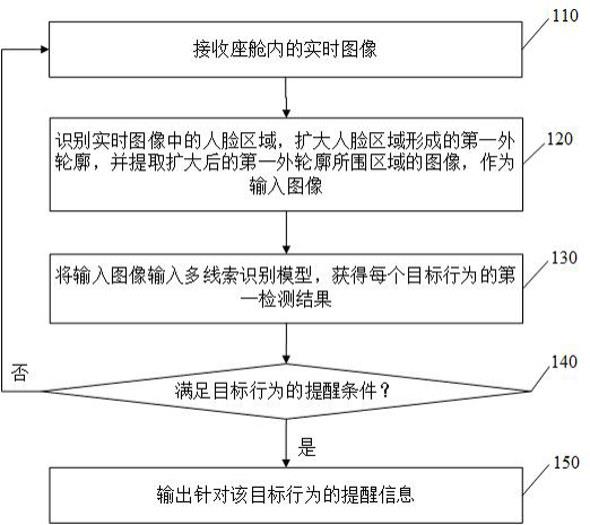
1.一种基于多任务的座舱内行为检测方法,其特征在于,包括:接收座舱内的实时图像;识别所述实时图像中的人脸区域,扩大所述人脸区域形成的第一外轮廓,并提取扩大后的第一外轮廓所围区域的图像,作为输入图像;其中,所述扩大后的第一外轮廓所围区域包括与多个目标行为对应的物体所在的第一区域;将所述输入图像输入多线索识别模型,获得每个目标行为的第一检测结果;所述多线索识别模型中,每个目标行为对应一个线索;对每个目标行为的第一检测结果进行分析,并判断是否满足提醒条件;若满足,则输出针对所述目标行为的提醒信息。2.根据权利要求1所述的基于多任务的座舱内行为检测方法,其特征在于, 所述多线索识别模型的训练方法包括:对初始识别模型进行信息融合训练,获得第一识别模型;利用所有目标行为的教师模型分别对所述第一识别模型进行知识蒸馏,获得所述多线索识别模型。3. 根据权利要求2所述的基于多任务的座舱内行为检测方法,其特征在于, 对初始识别模型进行信息融合训练,获得第一识别模型,具体包括自学习训练,所述自学习训练包括:获取样本图像中与每个目标行为对应的目标面部部位的关键点信息,将每个目标面部部位的关键点信息形成的第二外轮廓扩大,形成增强区域,将所有目标面部部位的增强区域的图像组合作为第一输入信息;其中,扩大后的第二外轮廓所围区域包括与所述增强区域内的目标面部部位对应的物体所在的第二区域;获取样本图像中与每个目标行为对应的物体所在的第三区域的图像,将获取到的与所有目标行为对应的第三区域的图像组合作为第二输入信息;将所述第一输入信息和所述第二输入信息融合,获得多线索图像;将所述多线索图像和所述样本图像同时输入所述初始识别模型进行训练,获得第二识别模型,将所述第二识别模型作为所述第一识别模型。4.根据权利要求3所述的基于多任务的座舱内行为检测方法,其特征在于, 对初始识别模型进行信息融合训练,获得第一识别模型,还包括互学习训练,在所述互学习训练中,利用第三识别模型和所述第二识别模型进行互学习,训练完成后的第二识别模型作为所述第一识别模型;其中,所述第三识别模型的输入数据为所述第二输入信息。5.根据权利要求4所述的基于多任务的座舱内行为检测方法,其特征在于,初始状态下,所述第二识别模型的特征提取器和所述第三识别模型的特征提取器的非多线索预训练参数相同。6.根据权利要求2所述的基于多任务的座舱内行为检测方法,其特征在于,知识蒸馏过程中,所述第一识别模型输出的每个目标行为的第二检测结果均与对应的教师模型的输出结果进行后验概率分布约束。7.根据权利要求2或6所述的基于多任务的座舱内行为检测方法,其特征在于,所述教师模型为基于多线索信息的教师模型,每个目标行为的教师模型对于自身目标行为的预测
效果最佳。8.根据权利要求7所述的基于多任务的座舱内行为检测方法,其特征在于,所述教师模型的输出数据为所有目标行为的检测结果。9.一种基于多任务的座舱内行为检测装置,其特征在于,包括接收模块、提取模块、识别模块、分析模块以及输出模块;所述接收模块用于接收座舱内的实时图像;所述提取模块用于识别所述实时图像中的人脸区域,扩大所述人脸区域形成的第一外轮廓,并提取扩大后的第一外轮廓所围区域的图像,作为输入图像;其中,所述扩大后的第一外轮廓所围区域包括与多个目标行为对应的物体所在的第一区域;所述识别模块用于将所述输入图像输入多线索识别模型,获得每个目标行为的第一检测结果;所述多线索识别模型中,每个目标行为对应一个线索;所述分析模块用于对每个目标行为的第一检测结果进行分析,并判断是否满足提醒条件;所述输出模块用于在满足提醒条件时输出针对所述目标行为的提醒信息。10.根据权利要求9所述的基于多任务的座舱内行为检测装置,其特征在于,还包括训练模块,所述训练模块包括信息融合训练模块和知识蒸馏模块;所述信息融合训练模块用于对初始识别模型进行信息融合训练,获得第一识别模型;所述知识蒸馏模块用于利用所有目标行为的教师模型分别对所述第一识别模型进行知识蒸馏,获得所述多线索识别模型。11.根据权利要求10所述的基于多任务的座舱内行为检测装置,其特征在于,所述信息融合训练模块包括第一输入信息获取模块、第二输入信息获取模块、融合模块以及多信息训练模块;所述第一输入信息获取模块用于获取样本图像中与每个目标行为对应的目标面部部位的关键点信息,将每个目标面部部位的关键点信息形成的第二外轮廓扩大,形成增强区域,将所有目标面部部位的增强区域的图像组合作为第一输入信息;其中,扩大后的第二外轮廓所围区域包括与所述增强区域内的目标面部部位对应的物体所在的第二区域;所述第二输入信息获取模块用于获取样本图像中与每个目标行为对应的物体所在的第三区域的图像,将获取到的与所有目标行为对应的第三区域的图像组合作为第二输入信息;所述融合模块用于将所述第一输入信息和所述第二输入信息融合,获得多线索图像;所述多信息训练模块用于将所述多线索图像和所述样本图像同时输入所述初始识别模型进行训练,获得第二识别模型,将所述第二识别模型作为所述第一识别模型。12.根据权利要求11所述的基于多任务的座舱内行为检测装置,其特征在于,所述信息融合训练模块还包括互学习模块,所述互学习模块用于执行互学习训练,在互学习训练中,利用第三识别模型和所述第二识别模型进行互学习,训练完成后的第二识别模型作为所述第一识别模型;其中,所述第三识别模型的输入数据为所述第二输入信息。13.一种基于多任务的座舱内行为检测设备,其特征在于,包括:一个或多个处理器、存储器以及一个或多个计算机程序,其中所述一个或多个计算机
程序被存储在所述存储器中,所述一个或多个计算机程序包括指令,当所述指令被所述座舱内行为检测设备执行时,使得所述座舱内行为检测设备执行如权利要求1~8任一项所述的座舱内行为检测方法。
技术总结
本发明公开了一种基于多任务的座舱内行为检测方法、装置以及设备,座舱内行为检测方法包括:接收座舱内的实时图像;识别所述实时图像中的人脸区域,扩大所述人脸区域形成的第一外轮廓,并提取扩大后的第一外轮廓所围区域的图像,作为输入图像;将所述输入图像输入多线索识别模型,获得每个目标行为的第一检测结果;所述多线索识别模型中,每个目标行为对应一个线索;对每个目标行为的第一检测结果进行分析,并判断是否满足提醒条件;若满足,则输出针对所述目标行为的提醒信息。本发明既充分利用了人脸全图语义信息,降低了误触发率,又减少了识别模型的数量,大大提高了车机的运行效率。率。率。
技术研发人员:沈锦瑞 林垠 殷保才 胡金水 殷兵
受保护的技术使用者:科大讯飞股份有限公司
技术研发日:2022.11.07
技术公布日:2022/12/30
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。