一种基于改进yolov5模型的安全帽佩戴检测方法
技术领域
1.本发明涉及图像处理技术领域,特别涉及一种基于改进yolov5模型的安全帽佩戴检测方法。
背景技术:
2.当前,我国建筑行业仍处于一个持续发展的阶段,每年建筑从业人员都在增长,在施工现场的安全管理中,安全帽作为一种能够有效预防头部损伤事故发生的防护用品,能够有效吸收高空坠落物对施工人员头部的冲击力,避免或减少高空坠物对头部的伤害,是安全生产法规定的生产施工活动中必须佩戴的个人防护用品。确保安全帽在施工场景下的正确佩戴,能够有效地减少生产事故中人员的伤亡率,对保障安全生产具有重要意义。
3.目前,在建筑工地中大多仍然采用人工监督的方法判断工作人员是否佩戴安全帽,这种方式容易造成人力物力的浪费,且存在较大的工作范围与人工作业易产生疲劳等局限性使得监督效果较差等问题。
4.近年来,随着目标检测技术的不断发展,在安全帽检测研究中取得了一定的成果;相较于传统耗时耗力的人工巡检,基于机器视觉的方法具有自动化程度高、易扩展等特点,因此成为当下的一种迫切需求。
5.但是,现有的基于传统机器学习的检测方法主要通过安全帽的形状和颜色特征进行识别,例如使用皮肤颜色检测方法对人脸进行定位,通过使用支持向量机的方法实现安全帽的检测;虽然传统机器学习的安全帽检测算法检测速度较快,但需要为特定的检测对象进行特征和训练分类器的设计,同时由于其泛化能力较差、特征较为单一等特点,无法在复杂的施工环境下对目标进行有效检测,容易出现小目标漏检、误检的问题,复杂环境下安全帽佩戴检测精度较低。
6.因此,如何避免在复杂环境下对安全帽佩戴进行检测时出现小目标漏检、误检的问题,提高安全帽佩戴检测的精度,是本领域技术人员亟需解决的问题。
技术实现要素:
7.有鉴于此,本发明提出了至少解决上述部分技术问题的一种基于改进yolov5模型的安全帽佩戴检测方法,该方法在yolov5模型的特征提取部分嵌入倒置残差模块与倒置残差注意力模块,便于获得丰富的小目标空间信息和深层语义信息,提升小目标的检测精度;在特征融合部分设计多尺度特征融合模块,提升模型对小尺寸目标的识别能力,减少小目标的漏检,该方法可以在复杂的环境下对安全帽佩戴进行有效检测,避免了出现小目标漏检、误检,提升了复杂环境下安全帽佩戴检测的精度。
8.为实现上述目的,本发明采取的技术方案为:本发明实施例提供一种基于改进yolov5模型的安全帽佩戴检测方法,包括以下步骤:s1、获取安全帽佩戴图像数据集,从所述安全帽佩戴图像数据集中随机选取n张图
像进行图像数据增强,得到数据增强后的图像;s2、将所述数据增强后的图像输入至改进yolov5模型中进行训练,得到训练后的改进yolov5模型;所述改进yolov5模型包括:在特征提取部分嵌入倒置残差模块与倒置残差注意力模块进行图像特征提取;在特征融合部分设计多尺度特征融合模块进行特征融合,并生成四个不同感受野的检测头;优化预测框回归损失函数;s3、将待检测图像输入至所述训练后的改进yolov5模型,得到相关人员是否佩戴安全帽的检测结果。
9.进一步地,所述步骤s1中,从所述安全帽佩戴图像数据集中随机选取n张图像进行图像数据增强,所述图像数据增强包括:对图像进行翻转、缩放和色域变换;将翻转、缩放和色域变换后的图像按照预设模板随机裁剪后进行拼接。
10.进一步地,所述对图像进行缩放具体为:在所述安全帽佩戴图像数据集中随机选择n张图像,将图像的宽和高作为边界值,对图像进行t
x
和ty缩放倍率的缩放;t
x
=fr(tw,tw δtw)ty=fr(th,th δth)其中,tw和th分别为宽和高缩放倍率的最小值,δtw和δth分别为宽和高缩放倍率随机区间的长度,fr表示随机值函数。
11.进一步地,将缩放的图像按照预设模板随机裁剪后进行拼接具体为:确定高为h、宽为w的图像模板作为输出图像尺寸,同时在宽高方向随机生成四条分割线进行剪裁,然后将九张裁剪好的图像进行拼接,并裁剪掉溢出的边框部分;将内部重叠部分进行二次裁剪,经过裁剪后,得到拼接完成的图像;将该图像作为yolov5卷积神经网络的输入层数据。
12.进一步地,所述步骤s2中,所述在特征提取部分嵌入倒置残差模块与倒置残差注意力模块进行图像特征提取;具体包括以下步骤:a、将所述数据增强后的图像输入特征提取模块,输入的图像通过第一层focus卷积,具体每一张图片中每隔一个像素取一个值,与下采样相类似,通过这种方式分割成四张图片,四张图片相似但没有信息丢失,通过这种操作将信息集中到了通道空间,将输入通道扩充了4倍,即拼接图片的通道为12通道,然后将图片再经过卷积操作,最终得到特征图通过focus卷积和3
×
3的卷积层后得到特征图feature_c0;b、将所述特征图feature_c0输入至第一倒置残差模块,采用通道扩张的方式放大浅层的特征,通过对输入特征的通道扩张,利用线性变换实现高维到低维的特征映射,获取丰富的浅层信息,利用卷积进行特征提取,通过残差连接的方式进行特征重复学习,输出特征图feature_c1;c、将所述特征图feature_c1经过一层卷积和第二倒置残差模块后得到特征图feature_c2,再经过一层卷积输入到第一倒置残差注意力模块中,得到特征图feature_c3;将所述特征图feature_c3经过卷积核大小为3
×
3的卷积并经过空间金字塔池化后,进入第二倒置残差注意力模块中,得到特征图feature_c4,作为多尺度特征融合模块的输入。
13.进一步地,所述步骤s2中,所述在特征融合部分设计多尺度特征融合模块进行特征融合,并生成四个不同感受野的检测头,具体包括以下步骤:
1)、将所述特征图feature_c4通过卷积核大小为3
×
3、通道数为512的卷积并经过上采样操作获得特征图feature_up1;2)、将所述特征图feature_up1与特征提取模块的所述特征图feature_c3特征进行融合,再经过c3模块,得到融合后的特征图feature_fuse1,将融合后的所述特征图feature_fuse1通过卷积核大小为3
×
3、通道数为256的卷积并经过上采样操作获得特征图feature_up2;3)、将所述特征图feature_up2与所述特征图feature_c2融合后得到特征图feature_fuse2,重复上述操作,通过卷积并经过上采样操作获得特征图feature_up3;4)、将所述特征图feature_up3与所述特征图feature_c1进行级联操作得到特征图feature_fuse3,然后通过c3模块和卷积核大小为1
×
1的卷积层进行特征提取获得特征图f4,其特征尺寸为原图像的1/4,用于极小目标的检测;5)、将所述特征图feature_fuse3经过c3模块和卷积核大小为3
×
3的卷积得到特征图feature_fuse4,与所述特征图feature_up2进行级联,进一步与所述特征图feature_c2进行级联操作获得特征图f3,其特征图尺寸为原图像的1/8,用于小目标的检测;6)、将所述特征图feature_fuse4经过c3模块和卷积核大小为3
×
3的卷积与所述特征图feature_fuse1经过c3模块和卷积核大小为3
×
3的卷积后进行级联,得到特征图feature_fuse5,然后通过c3模块和卷积核大小为1
×
1的卷积层进行特征提取获得特征图f2,其特征尺寸为原图像的1/16,用于中目标的检测;7)、将所述特征图feature_fuse5经过c3模块和卷积核大小为3
×
3的卷积与所述特征图feature_c4经过卷积核大小为3
×
3的卷积后进行级联,得到特征图feature_fuse6,然后通过c3模块和卷积核大小为1
×
1的卷积层进行特征提取获得特征图f1,其特征尺寸为原图像的1/32,用于大目标的检测。
14.进一步地,所述优化预测框回归损失函数中:采用ciou损失函数作为改进yolov5模型算法的预测框回归损失函数l
ciou
,其定义为:l
ciou
=1-ciou其中,iou代表预测框和真实框的交并比,b代表预测框的中心点,b
gt
代表真实框的中心点,ρ代表为欧式距离,ρ2(b,b
gt
)代表计算预测框的中心点和真实框的中心点之间欧氏距离的平方,c代表能够同时包含预测框和真实框的最小外接矩形的对角线距离;α代表用于做权衡的参数,v代表衡量长宽比一致性的参数;其中,α和v的参数表达式如下:其中,α和v的参数表达式如下:其中,w和h分别为预测框的宽度和高度;w
gt
和h
gt
分别为真实框的宽度和高度。
15.与现有技术相比,本发明具有如下有益效果:1、本发明实施例提供的一种基于改进yolov5模型的安全帽佩戴检测方法,通过在
特征提取部分嵌入倒置残差模块与倒置残差注意力模块,便于获得丰富的小目标空间信息和深层语义信息,提升了安全帽佩戴检测中小目标的检测精度;2、本发明实施例提供的一种基于改进yolov5模型的安全帽佩戴检测方法,在特征融合部分设计多尺度特征融合模块进行特征融合,并生成四个不同感受野的检测头,提升了模型对小尺寸目标的识别能力,减少了安全帽佩戴检测中小目标的漏检;3、本发明实施例提供的一种基于改进yolov5模型的安全帽佩戴检测方法,设计了马赛克混合数据增强方法,建立数据之间的线性关系,增加图像背景复杂度,提升算法的鲁棒性,可以在复杂的环境下对安全帽佩戴进行有效检测。
附图说明
16.图1为本发明实施例提供的基于改进yolov5模型的安全帽佩戴检测方法的流程图。
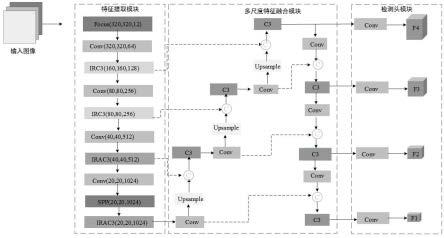
17.图2为本发明实施例提供的改进yolov5卷积神经网络的结构示意图。
18.图3为本发明实施例提供的倒置残差模块的模型示意图。
19.图4为本发明实施例提供的倒置残差注意力模块的模型示意图。
20.图5为本发明实施例提供的改进yolov5模型在训练100次后的平均精度均值指标图。
21.图6为本发明实施例提供的yolov5模型改进前后安全帽佩戴检测结果的对比图。
22.图7为本发明实施例提供的yolov5模型改进前后安全帽佩戴检测结果的另一对比图。
具体实施方式
23.为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
24.在本发明的描述中,需要说明的是,术语“上”、“下”、“左”、“右”、“前端”、“后端”、“两端”、“一端”、“另一端”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,序号
“①”
、
“②”
等仅用于描述目的,而不能理解为指示或暗示相对重要性。
25.下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
26.本发明实施例将基于卷积神经网络的目标检测算法应用到安全帽佩戴检测上,在yolov5模型的基础上结合安全帽佩戴检测的任务特点进行优化改进,从而实现更精准更智能化的检测方案。
27.参照图1所示,本发明提供的一种基于改进yolov5模型的安全帽佩戴检测方法,包括以下步骤:s1、获取安全帽佩戴图像数据集,从所述安全帽佩戴图像数据集中随机选取n张图
像进行图像数据增强,得到数据增强后的图像;s2、将所述数据增强后的图像输入至改进yolov5模型中进行训练,得到训练后的改进yolov5模型;所述改进yolov5模型包括:在特征提取部分嵌入倒置残差模块与倒置残差注意力模块进行图像特征提取;在特征融合部分设计多尺度特征融合模块进行特征融合,并生成四个不同感受野的检测头;优化预测框回归损失函数;s3、将待检测图像输入至所述训练后的改进yolov5模型,得到相关人员是否佩戴安全帽的检测结果。
28.下面分别对上述各个步骤进行详细的说明:在上述步骤s1中,首先获取安全帽佩戴图像数据集,对该数据集进行数据增强,图像数据增强包括:对图像进行翻转、缩放和色域变换;将翻转、缩放和色域变换后的图像按照预设模板随机裁剪后进行拼接;本实施例中,采用改进马赛克数据增强方法,具体为:在安全帽佩戴图像数据集中随机选择9张图像,将图像的宽和高作为边界值,对图像进行t
x
和ty缩放倍率的缩放;t
x
=fr(tw,tw δtw)ty=fr(th,th δth)其中,tw和th分别为宽和高缩放倍率的最小值,δtw和δth分别为宽和高缩放倍率随机区间的长度,fr表示随机值函数。
29.进一步地,确定高为h、宽为w的图像模板作为输出图像尺寸,同时在宽高方向随机生成四条分割线,然后将九张裁剪好的图片进行拼接,并裁剪掉溢出的边框部分;并将内部重叠部分进行二次裁剪,经过裁剪后,得到拼接完成的图像,将该图像作为yolov5模型卷积神经网络的输入层数据。
30.本实施例中,改进马赛克数据增强方法是在采用四张图片进行随机拼接的基础上增加至9张。即每一张图像都有其对应的框,并且将九张图像经过随机裁剪、随机拼接后组合在一起,实现了不同尺度目标间的平衡。
31.在上述步骤s2中,将数据增强后的图像输入至改进yolov5模型中进行训练,得到训练后的改进yolov5模型;本发明实施例中,改进yolov5模型包括:1.在特征提取部分嵌入倒置残差模块(irc3)与倒置残差注意力模块(irac3)进行图像特征提取;2.在特征融合部分设计多尺度特征融合模块进行特征融合,并生成四个不同感受野的检测头;3.优化预测框回归损失函数。
32.①
特征提取部分:特征提取的主要目的是利用卷积神经网络来学习高分辨率图像和低分辨率图像之间的映射关系。如图2所示,本发明实施例中,在特征提取模块中,其主要由切片卷积层(focus conv)、卷积层(conv)、倒置残差c3(inverted residuals c3,irc3)模块、倒置残差注意力c3(inverted residuals attention c3,irac3)模块以及特征金字塔模块(spp)构成;其中,irc3和irac3的结构分别如图3和图4所示;其中,conv代表卷积,h代表特征图的高,w代表特征图的宽,c代表特征图的通道数,2c代表两倍扩张后得通道数,
⊕
代表融合操作,
©
代表拼接操作,dwconv(depthwise convolution)代表深度卷积,pwconv(pointwise convolution)代表逐点卷积,eca-net(efficient channel attention)代表有效通道注意力,sd(stochastic depth,sd)代表随机深度。
33.参见图2所示,特征提取的具体流程如下:s1、输入图像经过第一层切片卷积(focus conv), 具体每一张图片中每隔一个像素取一个值,与下采样相类似,通过这种方式分割成四张图片,四张图片相似但没有信息丢失,通过这种操作将信息集中到了通道空间,将输入通道扩充了4倍,即拼接图片的通道为12通道,然后将图片再经过卷积操作,得到特征图feature_c0,以减少参数量并提升训练速度;s2、经过卷积层(conv)之后进入倒置残差c3模块(irc3),在该模块中,首先,利用扩张因子对输入特征图实现通道数扩张,然后,利用线性变化将高维的通道映射到低维的通道,获取丰富的浅层特征,并通过残差操作将恒等映射与输入特征相结合得到特征图feature_c1;s3、特征图feature_c1经过一个卷积层和一个倒置残差c3模块后得到特征图feature_c2,再经过一个卷积层后进入倒置残差注意力c3(irac3)模块;本发明实施例中,倒置残差注意力c3模块中包含深度可分离卷积和有效通道注意力模块,首先通过深度卷积模块,该模块设计使用参数量少且计算复杂度低的深度卷积替代3
×
3的标准卷积。如下式所示:其中表示深度卷积核,i、j表示卷积核大小,k、l表示特征图大小,中的第c个卷积核应用于与之相乘特征中的第c个通道,为特征图的第c个通道,通过一个1
×
1卷积来计算深度卷积输出的特征,并对其进行线性组合,表示对特征图feature_c2进行3x3卷积之后的特征。
34.进一步地,经过深度可分离卷积之后,进一步通过有效通道注意力,有效通道注意力通过对每个通道以及其k个相邻的通道来捕获局部的跨通道交互信息;最后经过卷积核大小为1
×
1的点卷积后,将通道数降维为原通道,得到特征图feature_c3;进一步地,将得到特征图feature_c3经过卷积核大小为3
×
3的卷积并进一步经过空间金字塔池化(spatial pyramid pooling,spp)后,进入特征提取模块中的第二个irac3模块,得到特征图feature_c4。
35.②
特征融合部分:参见图2所示,特征融合的具体流程如下:s1、特征提取部分最后的特征图feature_c4进入多尺度特征融合模块,首先通过卷积核大小为3
×
3、通道数为512的卷积(在图中卷积由conv表示,以下同理)并经过上采样操作(上采样操作由图2中“upsample”表示,以下同理)后获得特征图feature_up1;s2、将特征图feature_up1与特征提取模块的feature_c3进行连接合并,再经过c3模块,得到融合后的特征图feature_fuse1;将融合后的特征图feature_fuse1经过卷积核大小为3
×
3、通道数为256的卷积并经过上采样操作后获得特征图feature_up2;s3、重复上述s2的操作,通过特征图feature_up2与特征提取模块的得到feature_c2融合后得到特征图feature_fuse2并经过卷积核上采样操作后得到特征图feature_up3;s4、将得到的特征图feature_up3与主干网络(特征提取模块)中的feature_c1进行级联操作得到特征图feature_fuse3,然后通过c3模块和卷积核大小为1
×
1的卷积层进
行特征提取获得特征图f4 ,其特征尺寸为原图像的1/4,用于极小目标的检测;s5、特征图feature_fuse3经过c3模块和卷积核大小为3
×
3的卷积得到特征图feature_fuse4,与特征融合模块的特征图feature_up2进行级联,进一步与特征提取模块中的特征图feature_c2进行级联操作获得特征图f3,其特征图尺寸为原图像的1/8,用于小目标的检测;s6、将所述特征图feature_fuse4经过c3模块和卷积核大小为3
×
3的卷积与所述特征图feature_fuse1经过c3模块和卷积核大小为3
×
3的卷积后进行级联,得到特征图feature_fuse5,然后通过c3模块和卷积核大小为1
×
1的卷积层进行特征提取获得特征图f2,其特征尺寸为原图像的1/16,用于中目标的检测;s7、将所述特征图feature_fuse5经过c3模块和卷积核大小为3
×
3的卷积与所述特征图feature_c4经过卷积核大小为3
×
3的卷积后进行级联,得到特征图feature_fuse6,然后通过c3模块和卷积核大小为1
×
1的卷积层进行特征提取获得特征图f1,其特征尺寸为原图像的1/32,用于大目标的检测。
36.③
优化预测框回归损失函数:本发明实施例中,采用ciou损失函数作为改进yolov5模型算法的预测框回归损失函数l
ciou
,其定义为:l
ciou
=1-ciou其中,iou代表预测框和真实框的交并比,b代表预测框的中心点,b
gt
代表真实框的中心点,ρ代表为欧式距离,ρ2(b,b
gt
)代表计算预测框的中心点和真实框的中心点之间欧氏距离的平方,c代表能够同时包含预测框和真实框的最小外接矩形的对角线距离;α代表用于做权衡的参数,v代表衡量长宽比一致性的参数;其中,α和v的参数表达式如下:其中,α和v的参数表达式如下:其中,w和h分别为预测框的宽度和高度;w
gt
和h
gt
分别为真实框的宽度和高度。
37.进一步地,设置训练参数:批次大小16,迭代次数100,初始学习率0.01,终止学习率0.2,动量为0.937,权重衰减为0.0005,并采用随机梯度下降策略进行随机衰减;本发明实施例中,还采用旋转和水平镜像的方法增加不同角度的安全帽图像并结合改进马赛克方法提升对物体的识别能力;使用改进后的卷积神经网络并结合优化后的损失函数进行训练,训练完成得到最终的改进yolov5卷积神经网络。
38.进一步地,本发明实施例中,采用平均精度均值(mean average precision, map0.5)作为衡量模型性能的相关指标,如图5所示,其显示了改进yolov5s模型后在训练100次后达到的平均精度均值指标。
39.进一步地,将两张复杂环境下的安全帽佩戴图像输入至所述训练后的改进yolov5模型,得到相关人员是否佩戴安全帽的检测结果;并和未改进的yolov5模型的检测结果进
行对比,对比结果如图6和图7所示,其中图6a和图7a为未改进yolov5模型的安全帽佩戴的检测结果,图6c和图7c为未改进yolov5模型的安全帽佩戴的检测结果的局部放大图;图6b和图7b部分为本发明改进yolov5模型的安全帽佩戴的检测结果,图6d和图7d部分为本发明改进yolov5模型的安全帽佩戴的检测结果的局部放大图;从图6中左右对比可以看出未改进yolov5模型存在小目标中安全帽佩戴漏检(图6c中显示检出三个安全帽佩戴目标,图6d中显示检出四个安全帽佩戴目标);从图7中也可以看出未改进yolov5模型同样存在小目标中安全帽佩戴漏检的情况,(图7c中显示检出两个安全帽佩戴目标,图7d中显示检出三个安全帽佩戴目标);从图6和图7中可以获知,本发明方法可以有效解决密集目标中的安全帽佩戴漏检问题,即使在复杂的场景下,也能对目标实现安全帽佩戴的有效检测,避免小目标漏检。
40.通过上述实施例描述,本领域技术人员可知本发明提供了一种基于改进yolov5模型的安全帽佩戴检测方法,首先设计了改进mosaic数据增强方法,丰富了图像样本的多样性,建立数据之间的线性关系,提升算法的鲁棒性;其次针对小目标检测精度较低问题对模型主干网络进行优化,在主干网络部分嵌入倒置残差模块与倒置残差注意力模块,利用低维向高维的特征信息映射,从而获得丰富的小目标空间信息和深层语义信息,提升小目标的检测精度;最后,在特征融合部分设计多尺度特征融合模块,融合浅层空间信息和深层语义信息,并生成四个不同感受野的检测头,提升模型对小尺寸目标的识别能力,减少小目标的漏检,使用该方法可以有效改善施工现场视频监控图像中小目标漏检、误检的问题,提高了安全帽佩戴检测的精度。
41.对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。