1.本技术涉及图像检测技术领域,具体涉及一种非极大值抑制算法的优化方法。
背景技术:
2.非极大值抑制算法是一种在局部区域内去除冗余的非极大值目标,从而搜索出局部内极大值目标的算法,随着深度学习在计算机视觉任务(例如,目标检测、目标分割等)中的迅猛发展,非极大值抑制算法被普遍使用作为深度学习目标检测类算法中候选框的筛选方法。
3.在相关技术中,采用中央处理器(cpu,central processing unit) 图形处理器(gpu,graphics processing unit)的联合执行的方式实现非极大值抑制算法的运行,在非极大值抑制算法的运行过程中,cpu与gpu之间会频繁进行数据拷贝,当处理的数据量庞大的情况下,将会增加数据拷贝的时长,导致目标检测框的检测效率降低。
技术实现要素:
4.本发明旨在至少在一定程度上解决相关技术中的技术问题之一。为此,本发明的一个目的在于提出一种具有能够提高目标检测框的检测效率的非极大值抑制算法的优化方法。
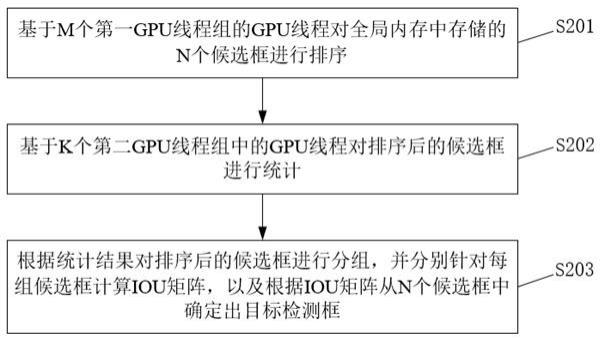
5.根据本发明实施例的非极大值抑制算法的优化方法,包括:基于m个第一gpu线程组中的gpu线程对全局内存中存储的n个候选框进行排序,其中包括:根据n和第一目标并行度确定排序轮次的数量和每个排序轮次所使用的第一gpu线程组的数量,其中,m为各排序轮次所使用第一gpu线程组数量的加和;在第i排序轮次中,所使用的各第一gpu线程组中的各gpu线程从第i-1排序轮次的排序结果中选择2i个候选框进行排序,其中,i为正整数;基于k个第二gpu线程组中的gpu线程对排序后的候选框进行统计,其中,k根据n和第二目标并行度确定;根据统计结果对排序后的候选框进行分组,并分别针对每组候选框计算交并比iou矩阵,以及根据iou矩阵从n个候选框中确定出目标检测框。
6.在上述方案中,在第i排序轮次中,对于类别相同的候选框,按照置信度大小降序排列,对于类别不同的候选框,按照类别取值升序排序。
7.在上述方案中,基于k个第二gpu线程组中的gpu线程对排序后的候选框进行统计,包括:将统计过程分为两个统计轮次,并对应第一统计轮次用到的k-1个第二gpu线程组设置k-1组共享内存块,其中,每组共享内存块包括第一共享内存块和第二共享内存块;在第一统计轮次中,执行多次候选框加载,每次加载时,通过当前第二gpu线程中的预设线程将当前候选框序列中的前p
count
个存储至对应的第一共享内存块,并通过当前第
二gpu线程组中的gpu线程从第一共享内存块加载候选框进行比较,以及将比较结果存入对应的第二共享内存块,其中,p
count
为第二目标并行度,当前候选框序列为排序后的候选框当前剩余的候选框组成的序列;在第二统计轮次中,通过剩余的一个第二gpu线程组中的gpu线程对各第二共享内存块的存储数据进行统计,并将统计结果存储在全局内存中。
8.上述方案中,比较结果为对应第一共享内存块中各类别候选框在对应第一共享内存块中的位置区间,统计结果为排序后的候选框中各类别候选框在全局内存中的位置区间。
9.上述方案中,在通过当前第二gpu线程组中的gpu线程从第一共享内存块加载候选框进行比较时,各gpu线程按照自身的索引值对相邻两个候选框进行比较;其中,当进行比较的两候选框类别不同时,将两候选框中前者的类别和所使用gpu线程的索引值加1后的取值存入对应的第二共享内存块。
10.上述方案中,根据统计结果对排序后的候选框进行分组,包括:根据排序后的候选框中各类别候选框在全局内存中的位置区间,对排序后的候选框进行分组,每组中的候选框类别相同。
11.上述方案中,p
sort
为第一目标并行度,p
count
为第二目标并行度,第一gpu线程组的数量m=(n p
sort-1)/p
sort
,第二gpu线程组的数量k=(n p
count-1)/p
count
1。
12.本发明还提供了一种非极大值抑制算法的优化装置,包括:排序模块,用于基于m个第一gpu线程组中的gpu线程对全局内存中存储的n个候选框进行排序,其中,所述排序模块还具体用于一gpu线程组的数量,其中,m为各排序轮次所使用第一gpu线程组数量的加和;在第i排序轮次中,所使用的各第一gpu线程组中的各gpu线程从第i-1排序轮次的排序结果中选择2i个候选框进行排序,其中,i为正整数;统计模块,用于基于k个第二gpu线程组中的gpu线程对排序后的候选框进行统计,其中,k根据n和第二目标并行度确定;确定模块,用于根据统计结果对排序后的候选框进行分组,并分别针对每组候选框计算交并比iou矩阵,以及根据iou矩阵从n个候选框中确定出目标检测框。
13.本发明还提供了一种电子设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现上述非极大值抑制算法的优化方法的步骤。
14.本技术还提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述非极大值抑制算法的优化方法的步骤。
15.根据本发明实施例的非极大值抑制算法的优化方法,可以将非极大值抑制算法的整个算法流程放到gpu上端到端执行,也就是除了数据的输入和数据的输出之外,其余操作全部在gpu上执行,可以在非极大值抑制算法在执行的过程中减少不必要的数据拷贝,缩短了目标检测框的筛选时长,进而提升了目标检测框的筛选效率。
16.本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
17.图1为一个实施例中非极大值抑制算法的整体架构框图;
图2为一个实施例中非极大值抑制算法的优化方法的流程示意图;图3为一个实施例中对8个候选框并行化执行分类排序的流程图;图4为一个实施例中一组第二gpu线程组对候选框并行化执行第一轮次统计的流程图;图5为一个实施例中非极大值抑制算法的优化装置的结构框图。
具体实施方式
18.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
19.在对本发明的实施例进行说明之前,首先对相关技术中的图像检测中使用的非极大值抑制算法进行相关说明。
20.非极大值抑制算法普遍用作为深度学习目标检测类算法中检测框的筛选方法,在实际应用中,存在缩短算法的训练时长和算法的运行时长的需求,而非极大值抑制算法的数据之间的强依赖性,导致需要对非极大值抑制算进行串行执行,从而影响了算法的训练效率和运行效率。
21.非极大值抑制算法可以分为三个执行阶段:分类、排序、筛框。具体地,非极大值抑制算法的执行流程为:首先对于类别0,步骤1),通过分类从输入候选框中取出所有属于类别0的候选框;步骤2),通过排序将从步骤1)得到的候选框按照置信度降序排序;步骤3),基于抑制非极大值的标准对步骤2)得到的排序结果进行筛选,得到最终结果;步骤4),对于其他类别分别执行上述步骤1)至3),从而可以筛选得到目标检测框。
22.在相关技术中,在开发场景下,通过采取cpu gpu的方式实现nms算法中耗时较多的交并比(iou,intersection over union)矩阵的计算过程并行化,也就是非极大值抑制算法中的iou矩阵的计算在gpu上执行,其余部分在cpu上执行,其中,iou矩阵是用于对候选框进行筛选,也就是,由gpu执行上述非极大值抑制算法中的步骤3),cpu执行上述非极大值抑制算法中的步骤1)与步骤2)。
23.而在部署场景下,通常存在多个计算机视觉任务组合的情况,例如,要完成一个数字表计读数任务,可能需要先使用目标检测找到电子屏幕的位置,再使用光学字符识别(ocr,optical character recognition)算法读取电子屏幕上的内容,这两个任务中间有可能包含一些复杂的操作。如果沿用开发场景下的并行化思路,只能采用cpu gpu联合执行的方式,其中,在gpu上执行核心算法,而在这种并行化方式下,难以避免cpu与gpu之间频繁的数据拷贝,当数据量比较大时,则数据拷贝需要占用较长的时间。
24.通过对非极大值抑制算法的执行流程经过梳理,发现分类步骤和排序步骤可以合并执行,基于此,在本发明中通过将整个非极大值抑制算法流程放到gpu上执行,从而在非极大值抑制算法执行过程中减少不必要的数据拷贝,缩短非极大值抑制算法的运行时长。如图1所示,图1示出了非极大值抑制算法的整体架构框图,包括排序模块、计数模块和筛框模块,其中,排序模块是将相关技术中的分类模块和排序模块合并,也就是排序模块可以实
现非极大值抑制算法中的分类和排序。计数模块是用于为筛框模块准备输入数据的。在筛框模块中,可以使用面向开发场景下的非极大值抑制算法并行化方法,例如,应用于通用并行计算架构(cuda,compute unified device architecture)的非极大值抑制算法。在图1中,排序模块、技术模块和筛框模块均在gpu上运行。
25.下面参考附图描述本发明实施例的技术方案的实现细节。
26.在一个实施例中,如图2所示,提供了一种非极大值抑制算法的优化方法,该非极大值抑制算法可包括以下步骤:步骤s201,基于m个第一gpu线程组的gpu线程对全局内存中存储的n个候选框进行排序。
27.这里,设置进行排序的第一目标并行度为p
sort
,根据候选框个数n和第一目标并行度p
sort
确定第一gpu线程组的个数m,也就是m=(n p
sort-1)/p
sort
,其中,设置每个第一gpu线程组的gpu线程个数与第一目标并行度p
sort
相同,从而可以利用m个第一gpu线程组对全局内存中存储的n个候选框进行并行处理,得到n个候选框的排序结果。
28.对步骤s201进行详细说明。
29.这里,需要对全局内存中存储的n个候选框进行多个排序轮次,得到n个候选框的排序结果,其中,排序轮次的数量t通过候选框个数n确定,具体地,t=log(n)。在实际应用中,在不同的排序轮次中,使用的第一gpu线程组的数量发生变化,其中,每个排序轮次所使用的第一gpu线程组的数量是根据候选框个数n和第一目标并行度p
sort
确定的,在实际应用中,各排序轮次所使用的第一gpu线程组数量之和为m。
30.在每个排序轮次中,第一gpu线程组处理的候选框数量是根据排序轮次确定的,在第i排序轮次中,所使用的各第一gpu线程组处理的候选框数量stride=2i,也就是在第一排序轮次中,所使用的各第一gpu线程组处理两个候选框,在第二排序轮次中,所使用的各第一gpu线程组处理四个候选框,依次类推。其中,所使用的各个第一gpu线程组中的各gpu线程是从第i-1排序轮次的排序结果中选择相应数量的候选框输入至第一gpu线程组中进行排序处理,其中,当i=1时,是从候选框的原始排序中选择输入至第一gpu线程组中的候选框。在每个排序轮次中,将两个候选框视为一组,每个排序轮次中按照预先使用的排序方法进行排序,例如,可以选择归并排序方法、冒泡排序方法等,经过t个排序轮次之后,可以得到n个候选框的排序结果。在实际应用中,在排序轮次中是对候选框的类别和置信度进行排序。
31.在一个实施例中,为候选框的排序设置双条件,具体地,在第i排序轮次中,所使用的各第一gpu线程组中的各gpu线程会对2i个候选框的类别和置信度进行排序,首先所使用的各第一gpu线程组中的各gpu线程对2i个候选框的类别进行排序,如果类别不同,则按照类别取值升序排序,排序结束。如果属于同一个类别,则按照候选框的置信度从高到低排序。在排序的过程中,如果需要交换两个候选框的位置,则在原地进行交换。如此,只需经过t个排序轮次的排序处理之后,n个候选框可以按照类别取值从小到大排序,并且在同一个类别中的候选框还按照置信度从大到小排序。
32.图3中示出了对8个候选框并行化执行分类排序的流程图。结合图3具体示例对并行执行分类排序进行说明。
33.在图3中t=1、t=2和t=3表示不同的排序轮次,stride表示每个排序轮次中每个第
一gpu线程组中的gpu线程需要处理的候选框个数,线程索引值用于区分第一gpu线程组中的不同gpu线程,数据索引可以表示输入的候选框的排序,例如,数据索引0表示第一个候选框c1|0.2,c1|0.2中的c1表示候选框的类别取值,0.2表示候选框的置信度,也就是分类排序中需要比较的内容。
34.在图3中是对8个候选框进行排序,其中,需要3个排序轮次得到8个候选框的排序结果。在每个排序轮次中,每个第一gpu线程组中的各gpu线程对stride个候选框执行排序操作,每次取2个候选框进行比较,首先比较两个候选框的类别取值大小ci,如果两个候选框的ci不相同,则按照类别取值ci从小到大的顺序排序两个候选框,例如,在第一个排序轮次中,索引值为0的第一gpu线程组的gpu线程取第一个候选框和第二个候选框进行排序处理,其中,第一个候选框和第二个候选框的类别取值不相同,且第一个候选框的类别取值为c1,第二个候选框的类别取值为c2,那么在对应的排序结果为第一个候选框在先,第二个候选框在后,其中,可以表示为“c1|0.2,c2|0.3”,本个排序轮次结束。如果两个候选框的ci相同,则按照两个候选框的置信度从大到小的顺序对两个候选框进行排序,例如,在第一个排序轮次中,索引值为1的第一gpu线程组的gpu线程取第三个候选框和第四个候选框进行排序处理,其中,第三个候选框和第四个候选框的类别取值相同,且第三个候选框的置信度大小为0.5,第四个候选框的置信度大小为0.9,那么对应的排序结果为“c1|0.9,c1|0.5”,本个排序轮次结束。
35.在本实施例中,通过gpu上的多个第一gpu线程组的并行执行候选框的排序,与相关技术的cpu顺序执行方式相比,可显著降低整体时间复杂度。在传统的非极大值抑制算法中,若用t(n)
class
表示分类模块的时间复杂度,则t(n)
class
=o(n)。若用t(n)
sort
表示排序模块的时间复杂度,则不同的排序算法的时间复杂度不同,其中,归并排序的时间复杂度为t(n)
sort
=o(nlogn),冒泡排序的时间复杂度为t(n)
sort
=o(n2)。以归并排序为例,分类和排序整体的时间复杂度t(c,n)
total
为:t(c,n)
total
=c
×
(t(n)
class
t(n)
sort
)=o(c
×
nlogn) (1)在本实施例中,将分类模块和排序模块合并为图1中的排序模块,只需经过排序模块对多个候选框进行处理之后,所有输入的候选框将按照类别取值从小到大、同一类别置信度从大到小的顺序排列。以归并排序为例,分类和排序整体的时间复杂度为:t(c,n)
total
=(t(n)
sort
)=o(nlogn) (2)其中,在上式中n表示处理的候选框的数量,c表示类别个数且c≥1。通过上式(1)与上式(2)的比较,可以确定,在本实施例中的非极大值抑制算法的整体时间复杂度降低了一个数量级,从而可以显著降低算法的执行时延。
36.步骤s202,基于k个第二gpu线程组中的gpu线程对排序后的候选框进行统计。
37.图1中的筛框模块每次加载同一个类别的候选框作为输入,而计数模块是用于桥接分类排序模块和后续的筛框模块,为后续的筛框模块准备输入数据。
38.这里,设置第二目标并行度p
count
,根据第二目标并行度p
count
和候选框数量n,确定第二gpu线程组的数量k,其中,k=(n p
count-1)/p
count
1。基于k个第二gpu线程组中的gpu线程对排序后的候选框进行统计,可以得到排序后的候选框中每个类别的候选框的起始位置与终止位置,从而实现为后续的筛框模块准备输入数据。
39.以图3为例,[c1|0.9,c1|0.8,c1|0.5,c1|0.2,c2|0.5,c2|0.3,c3|0.4,c3|0.2]为
经过排序之后的候选框,第一个类别c1的起始位置和终止位置分别为0和4,第二个类别c2的起始位置和终止位置分别为4和6,如果没有设置计数模块,也就是将分类排序模块的输出直接作为筛框模块的输入,则筛框模块中需要计算8
×
8大小的iou矩阵,总共需要计算64次,而增加计数模块之后,筛框模块只需要计算一个4
×
4的iou矩阵和两个2
×
2的iou矩阵,总共需要计算24次,降低了数据计算量,也降低算法的执行时延。
[0040]
在一个实施例中,在基于k个第二gpu线程中的gpu线程对排序后的候选框进行统计的过程中,分为两个统计轮次,下面对两个统计轮次进行详细说明。
[0041]
在第一统计轮次中,第二gpu线程组数量为k-1个第二gpu线程组,其中,每个第二gpu线程组中包含p
count
个线程。为第一统计轮次中用到的k-1个第二gpu线程组设置k-1组共享内存块,也就是每个第二gpu线程组对应一组共享内存块,其中,每组共享内存块中包括第一共享内存块与第二共享内存块,每个第二gpu线程组中的每个线程分别对应第一共享内存块与第二共享内存块中的一个内存地址,第一共享内存块是用于存储输入的候选框,第二共享内存块是用于存储第二gpu线程组的输出结果,在实际应用中,第一内存块与第二内存块的大小均为p
count
。在统计过程中,使用共享内存能够降低频繁从全局内存中加载数据带来的时延。
[0042]
排序后的候选框当前剩余的候选框组成当前候选框序列,通过当前第二gpu线程组中的预设gpu线程(索引值为0的线程),将当前候选框序列中的前p
count
个候选框存储至对应的第一共享内存块,其中,每组第二gpu线程加载的p
count
个候选框存储至第一共享内存块中设定的存储地址,示例地,图3所示的分类排序模块得到的候选框序列可以表示为[c1|0.9,c1|0.8,c1|0.5,c1|0.2,c2|0.5,c2|0.3,c3|0.4,c3|0.2],将前p
count
个候选框存储至对应的第一共享内存块,其中,第一个候选框(也就是c1|0.9)存储至第一共享内存块中第二gpu线程组中的第一个gpu线程(也就是索引值为0的线程)对应的内存地址,依次类推。
[0043]
在第二gpu线程组中的预设gpu线程结束对候选框的拷贝之后,第二gpu线程中的gpu线程从第一共享内存块中加载候选框进行比较,从而可以降低频繁从全局内存中加载候选框带来的时延。
[0044]
第二gpu线程中的gpu线程将加载候选框进行比较后生成的比较结果存入到第二共享内存块中。在实际应用中,比较结果为对应第一共享内存块中各类别候选框在第一共享内存块中的位置区间,通过比较结果可以确定各类别候选框在第一共享内存块中的起始位置与终止位置。
[0045]
在一个实施例中,在通过当前第二gpu线程组中的gpu线程从第一共享内存块加载候选框进行比较时,各gpu线程按照自身的索引值对相邻两个候选框进行比较。具体地,各gpu线程处理相邻的两个候选框,分别为的第一共享内存块中当前gpu线程对应的内存地址存储的候选框,以及第一共享内存块中当前gpu线程的索引值加1的gpu线程对应的内存地址存储的候选框,示例地,对于第二gpu线程组中索引值为0的gpu线程,会从第一共享内存中索引值0的gpu线程对应的内存地址中获取候选框,以及从第一共享内存中索引值为1的gpu线程对应的内存地址中获取候选框,最终索引值为0的gpu线程将当前候选框序列的第一个候选框与第二个候选框进行比较。各gpu线程主要是对相邻两个候选框的类别进行比较,当gpu线程确定相邻两个候选框的类别不相同时,将两个候选框中前者的类别和所使用gpu线程的索引值加1后的取值存入对应的第二共享内存块中,从而可以确定该类别在第一
共享内存块中的终止位置。假设索引值为2的gpu线程比较候选框a和候选框b,当候选框a与候选框b的类别不相同的情况下,gpu线程将候选框a的类别c1和取值3存入第二共享内存块中索引值为2的gpu线程对应的内存地址,那么第二共享内存块中对应的内存地址存储有“c1|3”,表示类别为c1的候选框在第一共享内存块的终止位置为3,也就是第一共享内存块中存储的前4个候选框的类别为c1(位置0对应第一个候选框)。
[0046]
在第二统计轮次中,第二gpu线程组的个数为1,通过该第二gpu线程组,对第二共享内存块的存储数据进行统计,并将统计结果存储在全局内存中,其中,统计结果为经过排序后的候选框中各类别候选框在全局内存中的位置区间,从而根据统计结果可以提取相同类别的候选框作为筛框模块的输入候选框。可以理解的,排序后的候选框组成一个候选框序列,在第一统计轮次中,各第二gpu线程组将会从候选框序列中提取p
count
个候选框进行类别比较,从而比较结果实质上是各类别的候选框在输入至各第二gpu线程组的p
count
个候选框的终止位置,在第二统计轮次中将第一统计轮次得到的比较结果进行统计,从而统计结果实质上是各类别的候选框在排序后的候选框的终止位置。
[0047]
图4中示出了一组第二gpu线程组对候选框并行化执行第一轮次统计的流程图。在图4中第一共享内存块用于存储候选框,第二共享内存块用于存储比较结果,ci表示候选框的类别,其中,在最后一个线程的其中一个输入为空输入,从而可以确定c3类别的候选框在输入至该第二gpu线程组的8个候选框的终止位置。下面结合图4对统计候选框的过程进行详细说明。
[0048]
步骤1,第二gpu线程组中的索引值为0的线程从全局内存中加载p
count
个候选框到第一共享内存块中,其中,在加载过程中是按照候选框的数据索引值,将候选框加载至第一共享内存块对应的内存地址中,数据索引值可以为候选框的顺序,例如,在当前候选框序列中的第一个候选框的数据索引值为0,将数据索引值为0的候选框加载至第一共享内存块中线程为0对应的内存地址,依次类推,完成输入候选框的加载。
[0049]
步骤2,第二gpu线程组中的每个线程依次从第一共享内存块中取两个候选框,其中,索引值为0的线程在第一共享内存块中取内存地址位于0,1位置的第一共享内存块的两个候选框,索引值为1的线程在第一共享内存块中取内存地址位于1,2位置的两个候选框,依次类推。每个线程对两个候选框的类别执行比较操作,具体的操作过程为:在两个候选框的类别不相同的情况下,将当前线程的索引值 1的取值存入到当前线程对应的第二共享内存块中。
[0050]
步骤3,第二gpu线程组中的索引值为0的线程将第二共享内存块中存储的数据写入到全局内存中,其中,只将存有数据的第二共享内存块保存到全局内存中。在实际应用中,每个第二gpu线程组写入全局内存的位置是不相同的,第一个第二gpu线程组写入到全局内存的[0,p
count-1]区间对应的内存地址中,第二个第二gpu线程组写入到全局内存的[p
count-1,2
×
p
count-1]区间对应的内存地址中,依次类推。
[0051]
步骤4,执行第二统计轮次,第二统计轮次重复步骤1至步骤3,将第一轮次中每个第二gpu线程组的各个得到的比较结果合并到一起,得到统计结果。
[0052]
步骤s203,根据统计结果对排序后的候选框进行分组,并分别针对每组候选框计算iou矩阵,以及根据iou矩阵从n个候选框中确定出目标检测框。
[0053]
根据统计结果对排序后的候选框进行分组,其中,主要是按照类别将排序后的候
选框进行分组,每组的候选框为相同类型,从而可以依次将每组候选框输入至筛框模块中,进而可以分别计算每组候选框的iou矩阵,再根据iou矩阵从n个候选框中确定出目标检测框。
[0054]
在一个实施例中,对根据统计结果对排序后的候选框进行分组进行详细说明。
[0055]
这里,统计结果中含有不同类别的候选框在全局内存中的终止位置,在对排序后的候选框进行分组的时候,可以首先对排序后的候选框中的类别取值为c1的候选框进行分组,从统计结果中确定类别取值为c1的候选框在全局内存中的终止位置,并根据上一个类别的终止位置确定类别取值为c1的候选框在全局中的起始位置,从而组成了类别取值为c1在全局内存中的位置区间,并从排序后的候选框中按照该位置区间提取出类别取值为c1的候选框,依次类推,完成对排序后的候选框进行分组的操作。
[0056]
在本技术实施例中,将整个非极大值抑制算法的流程放到gpu上端到端执行,克服了cpu和gpu之间的数据拷贝而产生的时延,从而提高了运行效率。经过实验比较,本发明提出的gpu端到端非极大值抑制算法相较于面向开发场景下的部分并行化的非极大值抑制算法的运行效率提高了约1.2倍。
[0057]
非极大值抑制算法单独使用的场景并不多,目前更多是在深度学习目标检测类算法部署中作为模块使用,在这种场景下的整个算法处理流程成为:预处理-网络推理-后处理(包括非极大值抑制算法和其他算法),其中,预处理、网络推理、除非极大值抑制算法之外的其他后处理算法均在gpu上执行。经过实验比较,在实际的多网络串联的深度学习算法部署场景中,模型串联的深度越深,本发明提出的非极大值抑制算法的优化方法的效果越显著。
[0058]
在上述实施例中,通过基于m个第一gpu线程中的gpu线程对全局内存中存储的n个候选框进行排序,基于k个第二gpu线程组的gpu个对排序后的候选框进行统计,根据统计结果对排序后的候选框进行分组,并分别针对每组候选框计算iou矩阵,以及根据iou矩阵从n个候选框中确定出目标检测框,从而能够在gpu上实现非极大值抑制算法的整体流程,克服了cpu和gpu之间的数据拷贝,可以提高算法的运行效率和降低时延。
[0059]
在一个实施例中,提供一种非极大值抑制算法的优化装置,参考图5所示,该非极大值抑制算法的优化装置500可包括:排序模块501、统计模块502和确定模块503。
[0060]
其中,排序模块501用于基于m个第一gpu线程组中的gpu线程对全局内存中存储的n个候选框进行排序,其中,排序模块501具体用于根据n和第一目标并行度确定排序轮次的数量和每个排序轮次所使用的第一gpu线程组的数量,其中,m为各排序轮次所使用第一gpu线程组数量的加和;在第i排序轮次中,所使用的各第一gpu线程组中的各gpu线程从第i-1排序轮次的排序结果中选择2i个候选框进行排序,其中,i为正整数;统计模块502用于基于k个第二gpu线程组中的gpu线程对排序后的候选框进行统计,其中,k根据n和第二目标并行度确定;确定模块503用于根据统计结果对排序后的候选框进行分组,并分别针对每组候选框计算交并比iou矩阵,以及根据iou矩阵从n个候选框中确定出目标检测框。
[0061]
在一个实施例中,排序模块501在第i排序轮次中,对于按照置信度大小降序排序,对于类别不同的候选框,按照类别取值升序排序。
[0062]
在一个实施例中,统计模块502具体用于将统计过程分为两个统计轮次,并对应第一统计轮次用到的k-1个第二gpu线程组设置k-1组共享内存块,其中,每组共享内存块包括
第一共享内存块和第二共享内存块;在第一统计轮次中,执行多次候选框加载,每次加载时,通过当前第二gpu线程中的榆社县城将当前候选框序列中的前p
count
个存储至对应的第一共享内存块,并通过当前第二gpu线程组中的gpu线程从第一共享内存块加载候选框进行比较,以及将比较结果存入对应的第二共享内存块,其中,p
count
为第二目标并行度,当前候选框序列为排序后的候选框当前剩余的候选框组成的序列;在第二统计轮次中,通过剩余的一个第二gpu线程组中的gpu线程对各第二共享内存块的存储数据进行统计,并将统计结果存储在全局内存中。
[0063]
在一个实施例中,统计模块502中的比较结果为对应第一共享内存块中各类别候选框在对应第一共享内存块中的位置区间,统计结果为排序后的候选框中各类别候选框在全局内存中的位置区间。
[0064]
在一个实施例中,统计模块502还用于在通过当前第二gpu线程组中的gpu线程从第一共享内存块加载候选框进行比较时,各gpu线程按照自身的索引值对相邻两个候选框进行比较;其中,当进行比较的两候选框类别不同时,将两候选框中前者的类别和所使用gpu线程的索引值加1后的取值存入对应的第二共享内存块。
[0065]
在一个实施例中,确定模块503具体用于根据排序后的候选框中各类别候选框在全局内存中的位置区间,对排序后的候选框进行分组,每组中的候选框类别相同。
[0066]
在一个实施例中,p
sort
为第一目标并行度,p
count
为第二目标并行度,第一gpu线程组的数量m=(n p
sort-1)/p
sort
,第二gpu线程组的数量k=(n p
count-1)/p
count
1。
[0067]
在一个实施例中,提供了一种电子设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现一种非极大值抑制算法的优化方法。
[0068]
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时以实现一种非极大值抑制算法的优化方法。
[0069]
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
