1.本发明属于信息安全技术领域,具体是一种面向会话的网络流量存储及索引方法。
背景技术:
2.近年来,随着网络安全技术的发展,越来越多高级、复杂且隐蔽的攻击手法不断被开发出来,比如0day/nday漏洞利用攻击、供应链攻击、无文件攻击等,这些攻击手段尤其在apt(advanced persistent threat)攻击中应用的最为广泛。由于攻防的不对称,防御方往往无法在第一时间发现和防御这些攻击手段,因此,留存完整的原始网络流量是安全分析人员对网络攻击事件进行溯源和取证的重要技术手段,网络流量存储和溯源技术比较广泛的应用在政府、金融和科研等重要领域。
3.在现有技术方案中,已经有一些公开的软件来实现数据包留存,如tcpdump和wireshark,这两个软件都可以将网络流量保存为常见的数据包格式,如pcap格式,但由于实现技术以及磁盘io性能的限制,这两个软件都无法实现高性能的数据包索引。数据包存储和索引技术的主要瓶颈之一是磁盘io的速度限制,虽然目前raid5硬盘阵列的顺序读写入性能能够达到1gb/s以上,但随机读写的性能却很低,4kb大小的随机磁盘读取性能的iops仅有200左右,换算速率仅为1mb/s左右。为了优化磁盘io性能,目前常见的优化手段是将磁盘随机io转变为顺序io,同时通过压缩和去重等手段降低数据量以减少磁盘io数据量。
4.为了解决数据包存储和快速索引问题,专利cn103259737a提出了一种基于多队列并行写入磁盘的数据包存储方案,通过分块并行写入实现了比较高的写入性能,但仅对时间戳生成了索引,无法支持其他复杂条件的减少。专利cn109067711a提出了一种基于pcapng扩展格式文件的数据包快速回溯分析方法,主要思路是在文件尾部生成一个单独的数据块来记录每个数据包的时间戳和偏移索引数据,数据包依然是pcapng格式顺序存储,但为每个数据包抽取了单独的数据包元数据,包括数据包类型、应用层协议、l3偏移、l4偏移、会话id、四元组等,索引过程是通过时间戳定位数据包偏移,然后依次遍历数据包元数据和数据包内容。专利cn113590910a将每个会话的数据包作为一个集合并存储到一个连续区域中,同时生成了单独的索引文件分别存储每个会话数据包的存储位置位置向量,根据会话源ip、目的ip、源端口、目的端口、协议、mac地址等字段建立了索引文件,这些偏移向量和元数据索引文件按照时间顺序生成文件夹存放,并以此作为时间戳索引,根据这些索引文件并配合多种索引算法最终实现了时间、五元组、mac地址和其他自定义关键字字段的索引能力,但是与此同时,为了解决这些索引数据的io性能消耗和磁盘空间消耗,上述专利还使用了ssd磁盘、lz4压缩算法、内存缓存等多种技术来进行优化才能保证工作效率。
技术实现要素:
5.为解决现有技术存在的上述问题,本发明提出一种面向会话的网络流量存储及索
引方法。
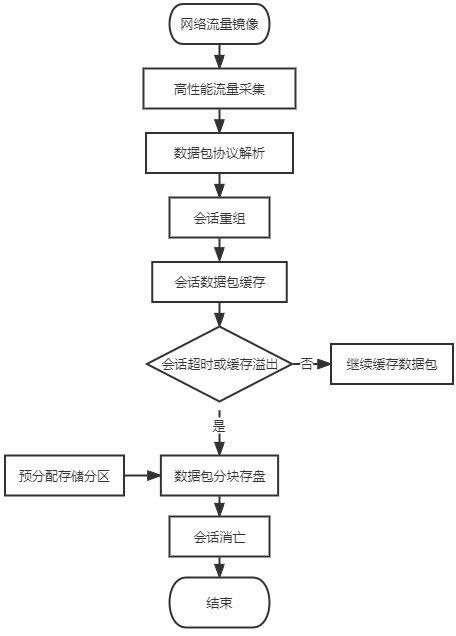
6.为实现上述技术效果,本发明的技术方案如下:一种面向会话的网络流量存储及索引方法,包括数据包存储和数据包索引,所述数据包存储步骤如下:步骤1:网络流量镜像通过交换机端口镜像和光纤分光等方式镜像网络数据包流量。
7.步骤2:高性能流量采集实现网络流量还原,从网络镜像设备中还原网络数据包,实现高性能流量采集。
8.步骤3:数据包协议解析识别数据包的网络层和传输层协议,识别数据包的二层协议和三层协议。
9.步骤4:会话重组根据数据包的协议、ip和端口信息生成相应的ip会话或者五元组会话,进行会话重组,对于没有端口的ip层协议生成ip对会话,对于有端口的tcp/udp协议生成五元组会话,跟踪所有会话完整的生命周期。
10.步骤5:会话数据包缓存在会话活动生命周期中,缓存会话数据包到相应的会话对象中。
11.步骤6:会话数据包缓存根据数据包缓存消耗阈值和会话的消亡时机来推动会话数据包的落盘,在内存空间足够的情况下,尽可能缓存更多的数据包。
12.进一步地,当整体会话数据包超过缓存限制时,以会话的最后活动时间进行遍历,将长时间未活动的会话数据包进行落盘,直到内存空间回到指定的空闲空间大小,缓存空间大小需要容纳30秒到120秒的网络流量;当每条会话单独缓存数据包容量超过4gb时以及会话消亡时也需要立即启动当前会话的数据包落盘;实际在千兆网络环境下,需要分配约20g的内存用作120秒数据包缓存空间。
13.步骤7:预分配存储分区在数据包落盘之前提前在磁盘预分配相应的存储空间,每次预分配大小为64g;进一步地,在磁盘上产生一个实体文件作为一个独立存储分区,分区存储文件以分区id为文件名,文件名形如:10.part,每个分区的总大小不超过1tb大小。
14.步骤8:数据包分块存盘根据每个会话当前落盘数据包集合,生成数据包分块存储的分块基本信息和分块数据包内容,每个分块的总体内容不超过4gb大小,超过4gb后会分割成多个分块,分块基本信息包括:当前分块数据包总数、当前分块数据包起始时间戳、前序分块总数、当前分块长度、分块头部校验和、前序分块偏移和分区id数组、前序分块长度数组、前序分块起始时间戳数组、前序分块数据包个数数组、当前分块数据包起始偏移数组;分块数据包内容包括每个数据包的时间戳和数据包原始内容。
15.整体存储结构如下:4b:当前分块数据包个数;4b:当前分块数据包起始时间戳;2b:前序分块总数,为0时前序分块相关的数组为空;
5b:当前分块长度;1b:分块头部校验和;[{5b:偏移,3b:分区id}]:前序分块偏移和分区id数组;[{4b:前序分块长度}]:前序分块长度数组;[{4b:前序分块起始时间戳}]:前序分块起始时间戳数组;[{4b:前序分块数据包个数}]:前序分块数据包个数数组;[5b:当前数据包偏移]:当前数据包起始偏移数组;[{8b:数据包1到n时间戳,*b:数据包1到n的数据内容}]:分块数据包内容;当会话存在多个数据包分块时,会话对象会将所有前序分块的基本信息保存到前序分块基本信息数组中,包括前序分块偏移和分区id数组、前序分块长度数组、前序分块起始时间戳数组、前序分块数据包个数数组,每次有新的数据包分块落盘都会更新前序分块的基本信息数组,并与当前分块一起存盘。
[0016]
步骤9:会话消亡当会话消亡时会生成一个24字节的会话快速索引数据,其原始内容包括:末尾块偏移、起始块偏移、首尾块分区id、首尾块长度4kb对齐长度、4kb对齐的起始块长度、4kb对齐的末尾块基本信息数据长度、扩展块标志和安全校验标志;快速索引主要保存了当前会话首尾分块的定位数据,如果会话数据包分块超过了2个,则扩展分块标志置1,同时除了首尾之外的分块信息额外保存在末尾分块的前序分块基本信息数组中。如果会话数据包分块仅有一个,则分块定位数据仅保存在末尾分块定位字段中,起始分块定位数据置0。安全校验标志置零。
[0017]
通过加密会话快速索引数据并通过编码后产生了一个32个字符的会话id,会话id与会话的源ip、目的ip、源端口、目的端口、协议、会话起始、会话结束时间、会话传输字节、会话数据包个数等会话元数据字段产生一条会话日志,最终将会话日志元数据与会话id发送到数据日志子系统进行存储和安全分析。
[0018]
进一步地,会话快速索引数据结构如下:5b:末尾块偏移;5b:起始块偏移;5b:首尾块分区id,其包含如下两个字段:20bit:末尾块分区id;20bit:起始块分区id;5b:首尾块长度,其包含如下两个字段:20bit:4kb对齐的末尾块长度;20bit:4kb对齐的起始块长度;2b: 4kb对齐的末尾块基本信息数据长度;1b:扩展块标志;1b:安全校验标志。
[0019]
数据包索引方法包括如下步骤:步骤1:输入会话id输入需要索引数据包的32个字符的会话id,根据会话id检索会话的pcap数据包。
[0020]
步骤2:会话id解密和解码通过base64解码和aes解密会话id,得到24字节的会话快速索引数据,其解码和解密的内容包括:末尾块偏移、起始块偏移、首尾块分区id、首尾块长度4kb对齐长度、4kb对齐的起始块长度、4kb对齐的末尾块基本信息数据长度、扩展块标志和安全校验标志。
[0021]
步骤3:校验快速索引合法性判断安全校验标志是否是0,如果是0则说明会话id是有效和合法的,否则是非法或无效。
[0022]
步骤4:定位存储分区通过首尾分块分区id确定数据包分块所在的分区文件,并打开相应的分区文件准备进行读取,如果分区id为0则忽略。
[0023]
步骤5:读取首尾分块数据包利用首尾块偏移和首尾块长度数据,将首尾块内的分块基本信息和数据包内容从分区文件中一次性加载到内存,如果起始分块的分区id为0则说明仅有一个分区,直接读取末尾分块数据,单个分块的数据内容只需要发起一次连续读取io即可完成数据包的读取。
[0024]
步骤6:读取扩展分块数据包判断扩展分块标志是否是1,如果扩展分块标志是1则说明会话数据包的分块个数超过2个,从步骤5中读取到的末尾分块的分块基本信息中获取前序分块基本信息数组,得到前序分块偏移及分区id数组和前序分块长度数组,并以此读取所有前序分块的基本信息和数据包内容。
[0025]
步骤7:数据包封装pcap格式内存后会对数据包内容进行重新组装,通过分块内的数据包起始偏移数组遍历每个数据包,获得数据包的时间戳和数据包内容,然后根据数据包长度、时间戳和数据包内容重新组织成pcap数据包格式。
[0026]
步骤8:输出pcap数据包。
[0027]
返回内存中组装好的pcap格式数据包。
[0028]
本发明的优点在于:本发明设计了一种32字节的会话id,其中承载了会话数据包在磁盘上的位置信息,通过会话id可以直接其数据包在磁盘上的绝对位置,另外尽可能的增大每个分块的存储的数据包数量,让短时间活动的网络会话只需要一到两个分块就能存储,这样在检索时也只需要发起一到两次顺序io就能完整读取数据包到内存,从而快速的会话数据包检索。
[0029]
本技术在数据包分块格式上,每个分块的数据包长度信息、时间戳和数据包内容等数据作为一块连续的存储结构,在一次顺序读取即可加载到内存,避免多次定位的随机io消耗。
[0030]
本发明利用高性能数据包采集框架、内存缓存和会话数据包预先聚合等技术,实现了一个高性能的数据包存储系统,能够实现tcpdump和wireshark等传统软件所不支持的大流量数据包实时存储。
[0031]
本发明设计了一种32位字符的会话id,在读取数据包时,通过会话id就能直接定位会话数据包在磁盘上的绝对位置,避免了传统存储引擎在检索数据包时需要反复读取索引和数据包遍历的操作,省去了额外的磁盘访问和存储开销,实现了pcap和pcapng等格式
所不支持的会话数据包的快速定位和索引。
[0032]
通过缓存的方式将每个会话一段时间内的数据包在内存中合并成一个连续数据包的分块,然后达到落盘时机时再将分块批量写入磁盘,这种方式充分利用了机械硬盘的高性能顺序io性能,使用普通的机械硬盘磁盘阵列就能实现高性能的数据包写入。
[0033]
通过在内存中缓存更多的数据包来减少数据包的分块个数,让每个会话的数据包尽可能的在磁盘的一片连续的区域中,这样在读取数据包时仅发起一次连续io就能读取会话全部数据包,彻底避免了传统存储引擎按照数据包原始顺序直接存储时所造成的存取随机io,能够最大的发挥机械硬盘的顺序io性能,实现高性能的数据包读取。
[0034]
本发明通过简化会话数据包索引方式,极大的降低了数据包索引的cpu运算开销、io存取开销和空间存储开销,使用普通商用服务器硬件就能实现大流量的数据包实时保存和数据包索引服务。
附图说明
[0035]
图1为本发明的数据包存储流程示意图。
[0036]
图2为本发明的数据包索引流程示意图。
具体实施方式
[0037]
为了更好的理解上述技术方案,下面将结合附图通过具体实施例进行进一步的说明,需要注意的是本发明技术方案包括但不限于一下实施例。
[0038]
实施例1一种面向会话的网络流量存储及索引方法,包括数据包存储和数据包索引,如图1所示,所述数据包存储步骤如下:步骤1:网络流量镜像通过交换机端口镜像和光纤分光等方式镜像网络数据包流量。
[0039]
步骤2:高性能流量采集基于pf_ring和dpdk等开源流量采集框架实现网络流量还原,从网络镜像设备中还原网络数据包,实现高性能流量采集。
[0040]
步骤3:数据包协议解析识别数据包的网络层和传输层协议,识别数据包的二层协议和三层协议。
[0041]
步骤4:会话重组根据数据包的协议、ip和端口信息生成相应的ip会话或者五元组会话,进行会话重组,对于没有端口的ip层协议生成ip对会话,对于有端口的tcp/udp协议生成五元组会话,跟踪所有会话完整的生命周期。
[0042]
步骤5:会话数据包缓存在会话活动生命周期中,缓存会话数据包到相应的会话对象中。
[0043]
步骤6:会话数据包缓存根据数据包缓存消耗阈值和会话的消亡时机来推动会话数据包的落盘,在内存空间足够的情况下,尽可能缓存更多的数据包。
[0044]
当整体会话数据包超过缓存限制时,以会话的最后活动时间进行遍历,将长时间
未活动的会话数据包进行落盘,直到内存空间回到指定的空闲空间大小,缓存空间大小需要容纳30秒到120秒的网络流量;当每条会话单独缓存数据包容量超过4gb时以及会话消亡时也需要立即启动当前会话的数据包落盘;实际在千兆网络环境下,需要分配约20g的内存用作120秒数据包缓存空间。
[0045]
步骤7:预分配存储分区在数据包落盘之前提前在磁盘预分配相应的存储空间,每次预分配大小为64g。
[0046]
在磁盘上产生一个实体文件作为一个独立存储分区,分区存储文件以分区id为文件名,文件名形如:10.part,每个分区的总大小不超过1tb大小,超过1t后会生成新的分区文件。
[0047]
步骤8:数据包分块存盘根据每个会话当前落盘数据包集合,生成数据包分块存储的分块基本信息和分块数据包内容,每个分块的总体内容不超过4gb大小,超过4gb后会分割成多个分块,分块基本信息包括:当前分块数据包总数、当前分块数据包起始时间戳、前序分块总数、当前分块长度、分块头部校验和、前序分块偏移和分区id数组、前序分块长度数组、前序分块起始时间戳数组、前序分块数据包个数数组、当前分块数据包起始偏移数组;分块数据包内容包括每个数据包的时间戳和数据包原始内容。
[0048]
整体存储结构如下:4b:当前分块数据包个数;4b:当前分块数据包起始时间戳;2b:前序分块总数,为0时前序分块相关的数组为空;5b:当前分块长度;1b:分块头部校验和;[{5b:偏移,3b:分区id}]:前序分块偏移和分区id数组;[{4b:前序分块长度}]:前序分块长度数组;[{4b:前序分块起始时间戳}]:前序分块起始时间戳数组;[{4b:前序分块数据包个数}]:前序分块数据包个数数组;[5b:当前数据包偏移]:当前数据包起始偏移数组;[{8b:数据包1到n时间戳,*b:数据包1到n的数据内容}]:分块数据包内容;分块数据包内容表示整个分块内所有数据包及其时间戳按顺序依次存储,如:时间戳1、数据包内容1、时间戳2、数据包内容2、时间戳3、数据包内容3
……
;其中b表示字节(byte),数据长度单位,一个字节包含8个二进制位,bit表示二进制位,8bit等于1b,40bit等于5b。
[0049]
当会话存在多个数据包分块时,会话对象会将所有前序分块的基本信息保存到前序分块基本信息数组中,包括前序分块偏移和分区id数组、前序分块长度数组、前序分块起始时间戳数组、前序分块数据包个数数组,每次有新的数据包分块落盘都会更新前序分块的基本信息数组,并与当前分块一起存盘。
[0050]
步骤9:会话消亡当会话消亡时会生成一个24字节的会话快速索引数据,其原始内容包括:末尾块偏移、起始块偏移、首尾块分区id、首尾块长度4kb对齐长度、4kb对齐的起始块长度、4kb对
齐的末尾块基本信息数据长度、扩展块标志和安全校验标志;快速索引主要保存了当前会话首尾分块的定位数据,如果会话数据包分块超过了2个,则扩展分块标志置1,同时除了首尾之外的分块信息额外保存在末尾分块的前序分块基本信息数组中。如果会话数据包分块仅有一个,则分块定位数据仅保存在末尾分块定位字段中,起始分块定位数据置0。安全校验标志置零。
[0051]
通过aes加密会话快速索引数据并通过base64编码后产生了一个32个字符的会话id,会话id与会话的源ip、目的ip、源端口、目的端口、协议、会话起始、会话结束时间、会话传输字节、会话数据包个数等会话元数据字段产生一条会话日志,最终将会话日志元数据与会话id发送到数据日志子系统进行存储和安全分析。
[0052]
会话快速索引数据结构如下:5b:末尾块偏移;5b:起始块偏移;5b:首尾块分区id,其包含如下两个字段:20bit:末尾块分区id;20bit:起始块分区id;5b:首尾块长度,其包含如下两个字段:20bit:4kb对齐的末尾块长度;20bit:4kb对齐的起始块长度;2b: 4kb对齐的末尾块基本信息数据长度;1b:扩展块标志;1b:安全校验标志;其数据结构的代码定义如下:#pragma pack(1)struct uint40{
ꢀꢀꢀꢀ
uint8_t m_dummy[5]={ 0 };
ꢀꢀꢀꢀ
uint64_t load()
ꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀ
uint64_t offset = *(uint32_t*)(m_dummy);
ꢀꢀꢀꢀꢀꢀꢀ
offset = offset 《《 8;
ꢀꢀꢀꢀꢀꢀꢀ
offset |= m_dummy[4];
ꢀꢀꢀꢀꢀꢀꢀ
return offset;
ꢀꢀꢀꢀ
}
ꢀꢀꢀꢀ
void write(uint64_t offset)
ꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀ
*(uint32_t*)(m_dummy) = (uint32_t)(offset 》》 8);
ꢀꢀꢀꢀꢀꢀꢀ
m_dummy[4] = offset & 0xff;
ꢀꢀꢀꢀ
}};
struct uint20tuple{
ꢀꢀꢀꢀ
uint8_t m_dummy[5] = {0};
ꢀꢀꢀꢀ
uint64_t load_first()
ꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀ
uint32_t uint20_first = *(uint16_t*)(m_dummy);
ꢀꢀꢀꢀꢀꢀꢀ
uint20_first = uint20_first 《《 4;
ꢀꢀꢀꢀꢀꢀꢀ
uint20_first |= m_dummy[2] 》 4;
ꢀꢀꢀꢀꢀꢀꢀ
return uint20_first;
ꢀꢀꢀꢀ
}
ꢀꢀꢀꢀ
uint64_t load_last()
ꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀ
uint32_t uint20_last;
ꢀꢀꢀꢀꢀꢀꢀ
uint20_last = m_dummy[2] & 0xf;
ꢀꢀꢀꢀꢀꢀꢀ
uint20_last = uint20_last 《《 16;
ꢀꢀꢀꢀꢀꢀꢀ
uint20_last |= *(uint16_t*)(&m_dummy[3]);
ꢀꢀꢀꢀꢀꢀꢀ
return uint20_last;
ꢀꢀꢀꢀ
}
ꢀꢀꢀꢀ
void write_first(uint32_t uint20_first)
ꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀ
*(uint16_t*)(m_dummy) = (uint20_first 》》 4);
ꢀꢀꢀꢀꢀꢀꢀ
m_dummy[2] = ((uint20_first & 0xf) 《《 4) | (m_dummy[2] & 0xf);
ꢀꢀꢀꢀ
}
ꢀꢀꢀꢀ
void write_last(uint32_t uint20_last)
ꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀ
m_dummy[2] = (uint20_last 》》 16) | (m_dummy[2] & 0xf0); ;
ꢀꢀꢀꢀꢀꢀꢀ
*(uint16_t*)(&m_dummy[3]) = (uint20_last & 0xffff);
ꢀꢀꢀꢀ
}};struct fileidindex{
ꢀꢀꢀꢀ
uint40 m_first_offset;
ꢀꢀꢀꢀ
uint40 m_last_offset;
ꢀꢀꢀꢀ
uint20tuple m_part_id;
ꢀꢀꢀꢀ
uint20tuple m_chunk_size;
ꢀꢀꢀꢀ
uint16_t m_last_chunk_base_size;
ꢀꢀꢀꢀ
uint8_t m_has_ext_chunk;
ꢀꢀꢀꢀ
uint8_t m_check_tag;};
#pragma pack()如图2所示,数据包索引方法包括如下步骤:步骤1:输入会话id;输入需要索引数据包的32个字符的会话id,根据会话id检索会话的pcap数据包。
[0053]
步骤2:会话id解密和解码;通过base64解码和aes解密会话id,得到24字节的会话快速索引数据,其解码和解密的内容包括:末尾块偏移、起始块偏移、首尾块分区id、首尾块长度4kb对齐长度、4kb对齐的起始块长度、4kb对齐的末尾块基本信息数据长度、扩展块标志和安全校验标志。
[0054]
步骤3:校验快速索引合法性;判断安全校验标志是否是0,如果是0则说明会话id是有效和合法的,否则是非法或无效。
[0055]
步骤4:定位存储分区;通过首尾分块分区id确定数据包分块所在的分区文件,并打开相应的分区文件准备进行读取,如果分区id为0则忽略。
[0056]
步骤5:读取首尾分块数据包;利用首尾块偏移和首尾块长度数据,将首尾块内的分块基本信息和数据包内容从分区文件中一次性加载到内存,如果起始分块的分区id为0则说明仅有一个分区,直接读取末尾分块数据,单个分块的数据内容只需要发起一次连续读取io即可完成数据包的读取。
[0057]
步骤6:读取扩展分块数据包;判断扩展分块标志是否是1,如果扩展分块标志是1则说明会话数据包的分块个数超过2个,从步骤5中读取到的末尾分块的分块基本信息中获取前序分块基本信息数组,得到前序分块偏移及分区id数组和前序分块长度数组,并以此读取所有前序分块的基本信息和数据包内容。
[0058]
步骤7:数据包封装pcap格式;内存后会对数据包内容进行重新组装,通过分块内的数据包起始偏移数组遍历每个数据包,获得数据包的时间戳和数据包内容,然后根据数据包长度、时间戳和数据包内容重新组织成pcap数据包格式。
[0059]
其中pcap格式定义如下:pcap文件头的格式struct pcap_file_header {
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_u_int32 magic;
ꢀꢀꢀꢀꢀꢀꢀꢀ
u_short version_major;
ꢀꢀꢀꢀꢀꢀꢀꢀ
u_short version_minor;
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_int32 thiszone;
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_u_int32 sigfigs;
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_u_int32 snaplen;
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_u_int32 linktype;};数据报头的格式
struct pcap_pkthdr {
ꢀꢀꢀꢀꢀꢀꢀꢀ
struct timeval ts;
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_u_int32 caplen;
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_u_int32 len;};struct timeval {
ꢀꢀꢀꢀꢀꢀꢀꢀ
long tv_sec;
ꢀꢀꢀꢀꢀꢀꢀꢀ
suseconds_t tv_usec;};步骤8:输出pcap数据包。
[0060]
返回内存中组装好的pcap格式数据包。
[0061]
实施例2参见图1和图2,一种面向会话的网络流量存储及索引方法和系统,包括如下步骤:数据包存储流程如下:步骤1:通过交换机端口镜像和光纤分光等方式镜像网络数据包流量。
[0062]
步骤2:基于pf_ring和dpdk等开源流量采集框架实现网络流量还原,从网络镜像设备中还原网络数据包,实现高性能流量采集。
[0063]
步骤3:识别数据包的网络层和传输层协议,识别数据包的二层协议和三层协议。
[0064]
步骤4:根据数据包的协议、ip和端口信息生成相应的ip会话或者五元组会话,进行会话重组,对于没有端口的ip层协议生成ip对会话,对于有端口的tcp/udp协议生成五元组会话,跟踪所有会话完整的生命周期。
[0065]
步骤5:在会话活动生命周期中,缓存会话数据包到相应的会话对象中。
[0066]
步骤6:根据数据包缓存消耗阈值和会话的消亡时机来推动会话数据包的落盘,在内存空间足够的情况下,尽可能缓存更多的数据包。
[0067]
当整体会话数据包超过缓存限制时,以会话的最后活动时间进行遍历,将长时间未活动的会话数据包进行落盘,直到内存空间回到指定的空闲空间大小,缓存空间大小需要容纳30秒到120秒的网络流量;当每条会话单独缓存数据包容量超过4gb时以及会话消亡时也需要立即启动当前会话的数据包落盘;实际在千兆网络环境下,需要分配约20g的内存用作120秒数据包缓存空间;步骤7:在数据包落盘之前提前在磁盘预分配相应的存储空间,每次预分配大小为64g。
[0068]
在磁盘上产生一个实体文件作为一个独立存储分区,分区存储文件以分区id为文件名,文件名形如:10.part,每个分区的总大小不超过1tb大小,超过1t后会生成新的分区文件。
[0069]
步骤8:根据每个会话当前落盘数据包集合,生成数据包分块存储的分块基本信息和分块数据包内容,每个分块的总体内容不超过4gb大小,超过4gb后会分割成多个分块,分块基本信息包括:当前分块数据包总数、当前分块数据包起始时间戳、前序分块总数、当前分块长度、分块头部校验和、前序分块偏移和分区id数组、前序分块长度数组、前序分块起始时间戳数组、前序分块数据包个数数组、当前分块数据包起始偏移数组;分块数据包内容
包括每个数据包的时间戳和数据包原始内容。
[0070]
整体存储结构如下:4b:当前分块数据包个数;4b:当前分块数据包起始时间戳;2b:前序分块总数,为0时前序分块相关的数组为空;5b:当前分块长度;1b:分块头部校验和;[{5b:偏移,3b:分区id}]:前序分块偏移和分区id数组;[{4b:前序分块长度}]:前序分块长度数组;[{4b:前序分块起始时间戳}]:前序分块起始时间戳数组;[{4b:前序分块数据包个数}]:前序分块数据包个数数组;[5b:当前数据包偏移]:当前数据包起始偏移数组;[{8b:数据包1到n时间戳,*b:数据包1到n的数据内容}]:分块数据包内容;分块数据包内容表示整个分块内所有数据包及其时间戳按顺序依次存储,如:时间戳1、数据包内容1、时间戳2、数据包内容2、时间戳3、数据包内容3
……
;其中b表示字节(byte),数据长度单位,一个字节包含8个二进制位,bit表示二进制位,8bit等于1b,40bit等于5b。
[0071]
当会话存在多个数据包分块时,会话对象会将所有前序分块的基本信息保存到前序分块基本信息数组中,包括前序分块偏移和分区id数组、前序分块长度数组、前序分块起始时间戳数组、前序分块数据包个数数组,每次有新的数据包分块落盘都会更新前序分块的基本信息数组,并与当前分块一起存盘。
[0072]
一个含有1456个数据包,并且数据包总大小为2mb的数据包分块,同时没有前序分块时,其真实数据存储形式如下:当前分块数据包个数:1456当前分块数据包起始时间戳:1661083538前序分块总数:0当前分块长度:2108816分块头部校验和:173当前数据包起始偏移数组:[数据包1偏移:16,数据包2偏移:1464,数据包3偏移:2912
……
]分块数据包内容:[数据包1时间戳:7134299471633975049,数据包1内容
…
,数据包2时间戳:7134299471633975050,数据包2内容
…
,数据包3时间戳:7134299471633975050,数据包3内容
……
]步骤9:当会话消亡时会生成一个24字节的会话快速索引数据,其原始内容包括:末尾块偏移、起始块偏移、首尾块分区id、首尾块长度4kb对齐长度、4kb对齐的起始块长度、4kb对齐的末尾块基本信息数据长度、扩展块标志和安全校验标志;快速索引主要保存了当前会话首尾分块的定位数据,如果会话数据包分块超过了2个,则扩展分块标志置1,同时除了首尾之外的分块信息额外保存在末尾分块的前序分块基本信息数组中。如果会话数据包分块仅有一个,则分块定位数据仅保存在末尾分块定位字段中,起始分块定位数据置0。安
全校验标志置零。
[0073]
通过aes加密会话快速索引数据并通过base64编码后产生了一个32个字符的会话id,会话id与会话的源ip、目的ip、源端口、目的端口、协议、会话起始、会话结束时间、会话传输字节、会话数据包个数等会话元数据字段产生一条会话日志,最终将会话日志元数据与会话id发送到数据日志子系统进行存储和安全分析。
[0074]
会话快速索引数据结构如下:5b:末尾块偏移;5b:起始块偏移;5b:首尾块分区id,其包含如下两个字段:20bit:末尾块分区id;20bit:起始块分区id;5b:首尾块长度,其包含如下两个字段:20bit:4kb对齐的末尾块长度;20bit:4kb对齐的起始块长度;2b: 4kb对齐的末尾块基本信息数据长度;1b:扩展块标志;1b:安全校验标志;其数据结构的代码定义如下:#pragma pack(1)struct uint40{
ꢀꢀꢀꢀ
uint8_t m_dummy[5]={ 0 };
ꢀꢀꢀꢀ
uint64_t load()
ꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀ
uint64_t offset = *(uint32_t*)(m_dummy);
ꢀꢀꢀꢀꢀꢀꢀ
offset = offset 《《 8;
ꢀꢀꢀꢀꢀꢀꢀ
offset |= m_dummy[4];
ꢀꢀꢀꢀꢀꢀꢀ
return offset;
ꢀꢀꢀꢀ
}
ꢀꢀꢀꢀ
void write(uint64_t offset)
ꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀ
*(uint32_t*)(m_dummy) = (uint32_t)(offset 》》 8);
ꢀꢀꢀꢀꢀꢀꢀ
m_dummy[4] = offset & 0xff;
ꢀꢀꢀꢀ
}};struct uint20tuple{
ꢀꢀꢀꢀ
uint8_t m_dummy[5] = {0};
ꢀꢀꢀꢀ
uint64_t load_first()
ꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀ
uint32_t uint20_first = *(uint16_t*)(m_dummy);
ꢀꢀꢀꢀꢀꢀꢀ
uint20_first = uint20_first 《《 4;
ꢀꢀꢀꢀꢀꢀꢀ
uint20_first |= m_dummy[2] 》 4;
ꢀꢀꢀꢀꢀꢀꢀ
return uint20_first;
ꢀꢀꢀꢀ
}
ꢀꢀꢀꢀ
uint64_t load_last()
ꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀ
uint32_t uint20_last;
ꢀꢀꢀꢀꢀꢀꢀ
uint20_last = m_dummy[2] & 0xf;
ꢀꢀꢀꢀꢀꢀꢀ
uint20_last = uint20_last 《《 16;
ꢀꢀꢀꢀꢀꢀꢀ
uint20_last |= *(uint16_t*)(&m_dummy[3]);
ꢀꢀꢀꢀꢀꢀꢀ
return uint20_last;
ꢀꢀꢀꢀ
}
ꢀꢀꢀꢀ
void write_first(uint32_t uint20_first)
ꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀ
*(uint16_t*)(m_dummy) = (uint20_first 》》 4);
ꢀꢀꢀꢀꢀꢀꢀ
m_dummy[2] = ((uint20_first & 0xf) 《《 4) | (m_dummy[2] & 0xf);
ꢀꢀꢀꢀ
}
ꢀꢀꢀꢀ
void write_last(uint32_t uint20_last)
ꢀꢀꢀꢀ
{
ꢀꢀꢀꢀꢀꢀꢀ
m_dummy[2] = (uint20_last 》》 16) | (m_dummy[2] & 0xf0); ;
ꢀꢀꢀꢀꢀꢀꢀ
*(uint16_t*)(&m_dummy[3]) = (uint20_last & 0xffff);
ꢀꢀꢀꢀ
}};struct fileidindex{
ꢀꢀꢀꢀ
uint40 m_first_offset;
ꢀꢀꢀꢀ
uint40 m_last_offset;
ꢀꢀꢀꢀ
uint20tuple m_part_id;
ꢀꢀꢀꢀ
uint20tuple m_chunk_size;
ꢀꢀꢀꢀ
uint16_t m_last_chunk_base_size;
ꢀꢀꢀꢀ
uint8_t m_has_ext_chunk;
ꢀꢀꢀꢀ
uint8_t m_check_tag;};#pragma pack()一个含有1456个数据包,并且数据包总大小为2mb的数据包分块,同时分块个数为1时,其文件快速索引数据形式如下:末尾块偏移:14096;
起始块偏移:0;末尾块分区id:10;起始块分区id:0;4kb对齐的末尾块长度:515;4kb对齐的起始块长度:0;4kb对齐的末尾块基本信息数据长度:1;扩展块标志:0;安全校验标志:0;对这个24字节的快速索引数据进行aes加密,加密方式是24字节分块的ecb加密,使用24字节密钥加密“abcdabcdabcdabcdabcdabcd”,将加密后的数据进行base64编码后得到如下文件id:kz9degwg2qkcfpzo37h03dv42jn7kux1数据包索引包括:步骤1:输入需要索引数据包的32个字符的会话id,根据会话id检索会话的pcap数据包;步骤2:通过base64解码和aes解密会话id,得到24字节的会话快速索引数据,其解码和解密的内容包括:末尾块偏移、起始块偏移、首尾块分区id、首尾块长度4kb对齐长度、4kb对齐的起始块长度、4kb对齐的末尾块基本信息数据长度、扩展块标志和安全校验标志;输入文件id:kz9degwg2qkcfpzo37h03dv42jn7kux1,使用密钥“abcdabcdabcdabcdabcdabcd”进行解密,并且base64解码,解密后在内存中得到快速索引数据:末尾块偏移:14096;起始块偏移:0;末尾块分区id:10;起始块分区id:0;4kb对齐的末尾块长度:515;4kb对齐的起始块长度:0;4kb对齐的末尾块基本信息数据长度:1;扩展块标志:0;安全校验标志:0;步骤3:判断安全校验标志是否是0,如果是0则说明会话id是有效和合法的,否则是非法或无效;步骤4:通过首尾分块分区id确定数据包分块所在的分区文件:10.part,并打开相应的分区文件准备进行读取,如果分区id为0则忽略;步骤5:利用首尾块偏移和首尾块长度数据,将首尾块内的分块基本信息和数据包内容从分区文件中一次性加载到内存,如果起始分块的分区id为0则说明仅有一个分区,直接读取末尾分块数据,单个分块的数据内容只需要发起一次连续读取io即可完成数据包的读取;步骤6:判断扩展分块标志是否是1,如果扩展分块标志是1则说明会话数据包的分
块个数超过2个,从步骤5中读取到的末尾分块的分块基本信息中获取前序分块基本信息数组,得到前序分块偏移及分区id数组和前序分块长度数组,并以此读取所有前序分块的基本信息和数据包内容;步骤7:内存后会对数据包内容进行重新组装,通过分块内的数据包起始偏移数组遍历每个数据包,获得数据包的时间戳和数据包内容,然后根据数据包长度、时间戳和数据包内容重新组织成pcap数据包格式;其中pcap格式定义如下:pcap文件头的格式struct pcap_file_header {
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_u_int32 magic;
ꢀꢀꢀꢀꢀꢀꢀꢀ
u_short version_major;
ꢀꢀꢀꢀꢀꢀꢀꢀ
u_short version_minor;
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_int32 thiszone;
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_u_int32 sigfigs;
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_u_int32 snaplen;
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_u_int32 linktype;};数据报头的格式struct pcap_pkthdr {
ꢀꢀꢀꢀꢀꢀꢀꢀ
struct timeval ts;
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_u_int32 caplen;
ꢀꢀꢀꢀꢀꢀꢀꢀ
bpf_u_int32 len;};struct timeval {
ꢀꢀꢀꢀꢀꢀꢀꢀ
long tv_sec;
ꢀꢀꢀꢀꢀꢀꢀꢀ
suseconds_t tv_usec;};步骤8:最后返回内存中组装好的pcap格式数据包。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。