:
1.本发明涉及伪造语音检测领域,特别涉及面向重编码和噪声干扰场景下的伪造语音检测领域,具体涉及一种基于主体滤波的伪造语音检测算法及系统。
技术背景:
2.伪造语音检测模型不鲁棒是指当训练检测模型的数据集和评估检测模型的数据集出现失配时,伪造语音检测模型的检测性能急剧下降。训练数据集和评估数据集的失配可以分为很多场景:包括说话人失配场景,伪造算法失配场景,重编码失配场景,噪声干扰失配场景等。说话人失配场景指评估数据集中存在训练数据集中不存在的说话人;伪造算法失配场景指评估数据集中的伪造语音在构造时使用了训练数据集中未使用的伪造语音合成算法;重编码失配场景指评估数据集中的语音数据可能经过了多种未知的编码算法处理,而训练数据集中的语音数据没有经过编码处理或者涉及的处理算法有限;噪声干扰失配场景指的是评估数据集中的语音包含各种噪声干扰,而训练数据集只有纯净的无噪声语音。上述的失配场景可以共同存在,例如asvspoof2019的la评估数据集与训练数据集既存在说话人失配情况,也存在伪造语音算法失配的情况。
3.提升伪造语音检测模型的鲁棒性是一个循序渐进的过程。早期的伪造语音检测研究工作关注说话人失配场景和伪造算法失配场景下伪造语音检测模型的鲁棒性,提出了许多针对性的检测模型和新颖的损失函数。这些伪造语音检测方法在说话人失配场景和伪造算法失配场景下的检测准确率较高。但是,现有方法对重编码失配场景以及噪声失配场景下伪造语音检测模型的鲁棒性的关注不足。编码是数字音频常见的处理方式,而音频在采集、传输、播放的过程中也不可避免地会遇到各种噪声干扰。因此,面向实用场景的伪造语音检测模型应该考虑重编码失配场景以及噪声失配场景下的性能表现。
4.实验表明,现有伪造语音检测模型在重编码失配场景和噪声失配场景下的鲁棒性较差。asvspoof2021的la评估数据集和asvspoof2019的la训练数据集之间主要存在的分布失配场景是重编码失配场景。现有的伪造语音检测模型在asvspoof2019的la训练数据集训练,训练好的检测模型使用asvspoof2019的la评估数据集进行评估时eer大约在4%-7%之间,使用asvspoof2021的la评估数据集对其进行评估时的eer普遍接近20%。add的lf数据集模拟了真实环境的噪声失配场景,现有伪造语音检测模型在add数据集训练时的eer接近10%,评估时的eer大约30%,模型在噪声失配场景的判决能力弱。因此,现有算法在重编码失配场景以及噪声失配场景下的性能表现还有待提升。
技术实现要素:
5.本发明的上述技术问题主要是通过下述技术方案得以解决的:
6.一种基于主体滤波的伪造语音检测算法,包括
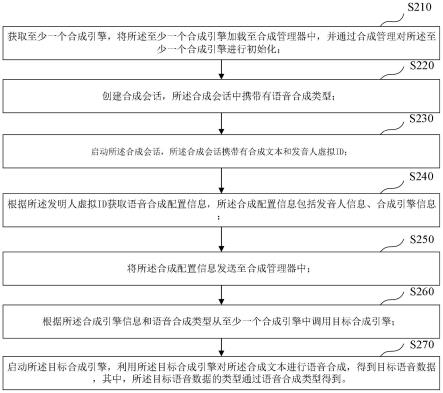
7.采集语音数据并对进行特征提取后,将其分为训练集和测试集;
8.对训练集和测试集分别进行掩蔽滤波主体提取和幅值滤波主体提取,剔除语谱图
中由于重编码以及噪声对语音数据的干扰数据,得到提取后的训练集和测试集;
9.用训练集对检测模型进行训练后得到训练好的检测模型;
10.利用训练好的检测模型对伪造语音检测进行实时检测。
11.在上述的一种基于主体滤波的伪造语音检测算法,特征提取是以通用特征提取算法提取待测语音的语谱图特征。
12.在上述的一种基于主体滤波的伪造语音检测算法,掩蔽滤波主体提取时:
13.对语谱图特征进行掩蔽度量,计算出语谱图特征掩蔽曲线;
14.依据掩蔽曲线剔除原始语谱特征中被掩蔽的频率成分,得到非掩蔽功率谱图。
15.在上述的一种基于主体滤波的伪造语音检测算法,幅值滤波主体提取时:
16.对非掩蔽功率谱图进行频带划分,按照人类发声以及听声的特性分为多个频带部分;
17.对各个频带部分采用自适应的幅值滤波算法进行噪声信号的剔除得到主体信号功率谱图。
18.在上述的一种基于主体滤波的伪造语音检测算法,根据语音功率谱图分别计算出巴克(bark)域谱图、语谱图幅度的声压级spl以及频率曲线的局部峰值点;
19.将bark频带、语谱图幅度的声压级spl和局部峰值点带入到掩蔽传递函数中计算出掩蔽曲线;
20.剔除幅度低于掩蔽曲线的频率分量得到非掩蔽语音功率谱图。
21.在上述的一种基于主体滤波的伪造语音检测算法,将非掩蔽功率谱图进行频带的划分,分为高、中、低三个频带;
22.对于不同的频带按照频带区域内部的自适应能量高低进行幅值滤波。
23.在上述的一种基于主体滤波的伪造语音检测算法,计算出巴克(bark)域谱图,即频域转bark域计算如式1所示,
[0024][0025]
其中f
hz
表示频率值,f
bark
表示巴克尺度的频域值。
[0026]
在上述的一种基于主体滤波的伪造语音检测算法,自适应滤波的核心如式2所示:
[0027][0028]fabs
表示幅值的绝对值,top
10%
表示频带内所有频率成分的幅值按照从高到低的顺序排序,fh存在两个参数,第一个参数是该频带的所有频率成分,第二个参数是top
10%
计算出来的幅值点,fh将所有幅值低于第二个参数的频率成分的幅值置为奇异值。
[0029]
一种基于主体滤波的伪造语音检测系统,包括
[0030]
第一模块:被配置为用于采集语音数据并对进行特征提取后,将其分为训练集和测试集;
[0031]
第二模块:被配置为用于对训练集和测试集分别进行掩蔽滤波主体提取和幅值滤波主体提取,剔除语谱图中由于重编码以及噪声对语音数据的干扰数据,得到提取后的训练集和测试集;
[0032]
第三模块:被配置为用训练集对检测模型进行训练后得到训练好的检测模型;
[0033]
第四模块:被配置为利用训练好的检测模型对伪造语音检测进行实时检测。
[0034]
因此,本发明具有如下优点:1、针对伪造语音检测领域常见的数据分布失配问题,主体提取模块剔除语音信号中容易变化的非主体部分,有效提升了现有伪造语音检测模型在重编码、噪声干扰场景下的鲁棒性。2、主体提取模块利用了听觉掩蔽效应,过滤掉语音内容的非主体部分的同时,也保留了语音的主体部分,可以保持原语音的语义和自然度。当训练数据集和评估数据集不失配的情况下,主体提取模块不会明显降低现有伪造语音检测模型的检测准确率。
附图说明
[0035]
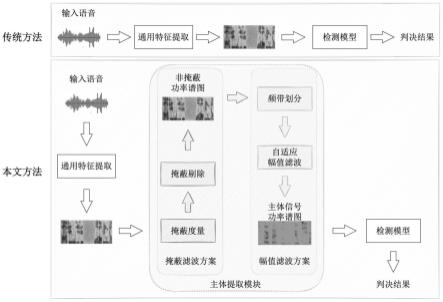
图1是主体提取方案对比一般方法的示意图。
[0036]
图2是基于听觉掩蔽效应的主体提取计算流程。
[0037]
图3是基于语谱图幅值滤波主体提取方案的具体计算流程。
具体实施方式
[0038]
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
[0039]
实施例:
[0040]
本发明通过深入分析语音的编码流程和语谱图中信号与噪声的特性,基于人耳听觉掩蔽效应和信噪高能量差异的特性分别提出了掩蔽滤波主体提取方案和幅值滤波主体提取方案,剔除语谱图中由于重编码以及噪声对声音信号带来的干扰成分,保留语谱图中发声的主体部分,从而实现更鲁棒的伪造语音检测。具体包括:
[0041]
1、利用stft算法,提取待测语音样本的原始语谱图特征。
[0042]
2、用主体滤波模块处理原始语谱图特征,包括:
[0043]
2.1根据掩蔽效应的计算公式,计算原始语谱图特征的掩蔽曲线。
[0044]
2.2根据掩蔽曲线,剔除原始语谱图特征中被掩蔽的频率成分,得到非掩蔽功率谱图。
[0045]
2.3根据人类听觉特性,对非掩蔽功率谱图中的不同频带应用自适应幅值滤波,剔除噪声信号,得到主体信号。
[0046]
3、将主体信号作为输入,训练伪造语音检测模型(有许多深度神经网络都可以用于伪造语音检测,这里可以选择任意一个网络,并非本发明的覆盖范围)。
[0047]
4、训练完毕的模型,即可以用于伪造语音检测。但在检测前,仍然要通过步骤2中描述的主体滤波方式提取主体信号。
[0048]
本方法的核心在于主体特征提取模块,总体结构如图1所示,其工作流程如下。首先,以通用特征提取算法提取待测语音的语谱图特征。其次,对语谱图特征进行掩蔽度量,目的是计算出其掩蔽曲线。然后,掩蔽剔除模块依据掩蔽曲线剔除原始语谱特征中被掩蔽的频率成分,得到非掩蔽功率谱图。最后,对非掩蔽功率谱图进行频带划分,按照人类发声以及听声的特性分为多个频带部分,对各个频带部分采用自适应的幅值滤波算法进行噪声信号的剔除。主体提取模块对训练数据和评估数据的语谱特征均进行处理,特征之间由于重编码以及噪声信号带来的干扰信息被剔除,避免伪造语音检测模型在训练和评估的时依
赖不稳定的干扰信息,从而提升其鲁棒性。
[0049]
主体提取模块首先基于掩蔽效应剔除人耳不可感知的干扰信号,其次根据噪声与主体信号的幅值关系进行幅值滤波操作。这样的处理顺序是因为,掩蔽曲线的计算需要保持原始语音信号的完整性,如果先进行幅值滤波处理,信号之间的关系被破坏,计算出来的掩蔽曲线将失去原本的意义。掩蔽滤波仅仅剔除了人耳不可感知的部分,这对后续按照幅值进行噪声的剔除没有影响,所以主体提取模块的处理顺序为先掩蔽滤波再幅值滤波。
[0050]
主体提取模块包括基于听觉掩蔽效应的主体提取方案和基于幅值滤波的主体提取方案,以下对其分别进行介绍。
[0051]
1、基于听觉掩蔽效应的主体提取方案(掩蔽滤波主体提取)。
[0052]
基于掩蔽效应的主体提取方案的具体处理流程如图2所示。首先根据语音功率谱图分别计算出巴克(bark)域谱图,语谱图幅度的声压级(spl)以及频率曲线的局部峰值点。频域转bark域计算如式1所示,其中f
hz
表示频率值,f
bark
表示巴克尺度的频域值,将频域转换到bark域是因为bark区域更加符合人耳听觉系统,存在24个bark子带分别对应人耳中的24个区域,掩蔽效应的生理基础就是人耳24个区域中各个区域内部语音频率成分的互相干扰;spl值的单位是db,其代表该点声音与标准的声压的比值,频率转spl的公式如式2所示,其中表示功率的绝对值平方,其代表该频率成分的能量,n
fft
表示傅立叶变换使用的级数,一般其稍大于语音分帧窗长且为2的幂,这是为了方便使用快速傅立叶变换算法;局部峰值点即为频率曲线中频率成分高于其周围频率成分的频率点,寻找序列中局部峰值点的算法非常成熟,本文使用scipy库的find_peak函数进行峰值点的定位。在计算掩蔽曲线的过程中,将每个峰值点视为非噪音部分。计算峰值点的原因是在听觉掩蔽效应中,非噪声部分对噪声部分的掩蔽效应与噪声部分对噪声部分的掩蔽效应是不同的,一般只需要统计非噪声部分对噪声部分的掩蔽效应。
[0053]
将bark频带、spl和局部峰值点带入到掩蔽传递函数中即可计算出掩蔽曲线。掩蔽传递函数是一个循环迭代的过程,通过迭代计算每个非噪声点对周围信号的掩蔽效应并累加,最终得到整个频率曲线的掩蔽曲线。掩蔽传递函数中计算每个非噪声点对全局的掩蔽效应的公式如式3。spli表示当前迭代的峰值点的spl值,只有非噪声部分的spl大于40才能够产生掩蔽效应。sfj用来暂存第i个峰值对全局的第j个频率分量的掩蔽效应。dz是第i个频率的bark尺度值与第j个频率的bark尺度值之间的差异,在使用的时候取其绝对值。θ取决于dz的值,若dz为正则取1,否则取0。这意味着若局部峰值点i的能量大于j的能量才存在掩蔽效应。掩蔽剔除模块剔除幅度低于掩蔽曲线的频率分量得到非掩蔽语音功率谱图。
[0054][0055][0056]
sfj=abs(dz)
·
(-27 0.37
·
max(spl
i-40,0)
·
θ)
ꢀꢀꢀ
(3)
[0057]
2、基于幅值滤波的主体提取方案(幅值滤波主体提取)。
[0058]
基于语谱图幅值滤波的主体提取方案的具体流程如图3所示。非掩蔽功率谱图首先进行频带的划分,分为高、中、低三个频带。对于不同的频带按照频带区域内部的自适应
能量高低进行幅值滤波。自适应滤波的核心如式4所示。f
abs
表示幅值的绝对值,top
10%
表示频带内所有频率成分的幅值按照从高到低的顺序排序,选择恰巧落在10百分位点的幅值,top
30%
和top
5%
与其类似。fh存在两个参数,第一个参数是该频带的所有频率成分,第二个参数是top
10%
计算出来的幅值点,fh将所有幅值低于第二个参数的频率成分的幅值置为奇异值。
[0059]
在不同的频带成分,按照每个语音自身的幅值分布保留不同的百分比。低频是人发声的主要成分,只需要保留足够能量的频率。中频是人耳区分不同声音的重要依据,所以需要保留较多的频率分量。高频多是辅音、噪音等,所以只需要保留最少信息。
[0060][0061]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。