1.本发明属于医疗信息数据处理技术领域,公开了一种面向中文冠心病诊断报告的命名实体消歧方法。
背景技术:
2.近年来,随着人工智能技术的发展,信息数据处理技术领域进入到了一个新的时代,尤其在自然语言处理方面,各种模型和方法的出现,使得各行各业都有了新的突破。医疗领域同样受到人工智能的影响,冠心病作为一种慢性病,多见于中老年人,基于医疗诊断报告,利用自然语言处理技术,构建出的冠心病诊断报告知识图谱能够有利于分析和总结冠心病人的相关信息,提高医院冠心病治疗水平。实体消歧作为自然语言处理技术中的一种处理任务,是构建知识图谱不可或缺的一环,在医疗诊断报告中,基于命名实体识别后的实体提及名称,在不同的语段中有着不同的含义,并且很多疾病、病因和症状实体具有多个别名,将实体提及名称进行消歧,找到实体提及名称在语段中的正确含义和标准名称,显得尤为重要。
3.目前,所提出的实体消歧技术中大多采用双编码器的结构,将实体提及和候选实体分别编码,然后计算两者之间的语义相似度,来进行排序选择。这种方法需要计算大量的候选实体与实体提及之间的余弦相似度,缺乏对上下文特征信息的关注,导致准确度不高。而在中文医疗文本消歧方面,也缺少对医疗术语中英文简体名称的消歧方法。
技术实现要素:
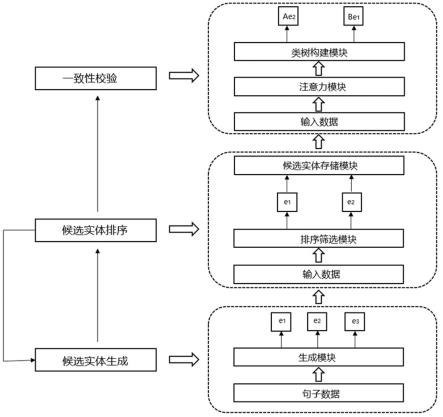
4.针对上述所提出的问题,本发明提出了一种面向中文冠心病诊断报告的命名实体消歧方法,基于冠心病诊断报告中文命名实体数据集,包括三个阶段:候选实体生成阶段、候选实体排序阶段和一致性校验阶段。其中候选实体生成阶段根据冠心病诊断报告中文命名实体数据集,由生成模块生成相关候选实体集;候选实体排序阶段将冠心病诊断报告中文命名实体数据集和候选实体生成阶段生成的候选实体集进行拼接,由排序筛选模块对候选实体集进行筛选,得到新的候选实体集,并保存在候选实体存储模块中;一致性校验阶段根据候选实体存储模块中保存的两个相邻实体提及的候选实体集,通过注意力模块和类树构建模块,得到段落文本所有每个实体提及的最终目标候选实体,提高整个段落文本的消歧准确率。
5.所述基于冠心病诊断报告中文命名实体数据集,由段落文本构成,并将段落文本拆分成句子文本,每条句子文本需包括:待消歧句子实体提及m、待消歧实体上文信息cx_o、待消歧实体下文信息cx_u、待消歧实体提及类型ty,数据集中句子内容为:{m,cx_o,cx_u,ty}。
6.待消歧实体提及类型可分为6类,分别为:疾病、病因、症状、人体结构、观测操作和药品。
7.本发明中:候选实体生成阶段包括冠心病诊断报告中文命名实体数据集中句子内
容、实体别名表、候选实体知识库和中文gpt2预训练模型,具体包括如下步骤:步骤1-1:数据集中句子内容先通过所述实体别名表,根据待消歧句子实体提及m和待消歧实体提及类型ty从所述实体别名表中找到待消歧句子实体提及m对应的别名名称集{ma1,ma2
…
},将实体提及的别名名称添加到数据集中,则数据集中的句子内容为:{m,ma1,ma2,cx_o,cx_u,ty};步骤1-2:数据集中的句子内容根据中文gpt2预训练模型输入数据st格式调整为:《s》输出待消歧句子实体提及m的候选实体[e]m[e]ma1[e]ma2[e]cx_o[e]m[e]cx_u[e]ty[sep],其中《s》为输入数据的起始标识符,[sep]为终止标识符,字符串“输出待消歧句子实体提及m的候选实体”用来微调生成任务,训练中文gpt2预训练模型输出候选实体,[e]为分割字段标识符;步骤1-3:在训练中文gpt2预训练模型之前,将所述候选实体知识库内容嵌入到所述中文gpt2预训练模型中,根据输入数据st进行输入编码,训练中文gpt2预训练模型从嵌入矩阵中查找汉字对应的嵌入向量,根据《s》起始标识符和各汉字在st中的位置,得到各汉字的位置编码向量:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)其中:st表示输入数据st中的汉字,token表示定义的嵌入矩阵表,定义了各汉字对应的嵌入向量,x表示嵌入向量,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)其中:pos表示当前字在句子中的位置,i表示向量中每个值的index,model表示模型自定义参数,偶数位置,使用正弦编码,奇数位置,使用余弦编码,pe表示位置编码向量;步骤1-4:各汉字的嵌入向量x和位置编码向量pe相加后构成表示向量:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)将表示向量输入到所述中文gpt2预训练模型中的decoder模块中,所述decoder模块根据自注意力机制为每个汉字都赋予一个相关度得分,经过向量表征求和,得到各字词之间的关联概率:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)p表示各字词关联概率,为模型内置向量,自定义数值,向量维数,与表示向量保持一致,softmax()为归一化概率函数;步骤1-5:经过步骤1-4微调后的中文gpt2预训练模块,能够根据st中的待消歧句子实体提及m和对应的别名名称,结合待消歧实体下文信息cx_u和待消歧实体提及类型ty信息,与候选实体知识库中的候选实体信息之间,计算相似值,设置相似值阈值,选择大于相似值阈值的候选实体:
(6)e表示所有候选实体集,ei表示候选实体,sorce()表示计算候选实体与st之间的相似值函数,p:自定义的相似值阈值。
[0008]
本发明中:所述候选实体排序阶段由中文longformer层、linear layer层、start softmax层、end softmax层、联合概率层、阈值选择层和候选实体存储模块构成,中文longformer层改进了transformer中的注意力机制更利于处理长文本数据,更好的学习到各字词之间的关联信息。linear layer层是一种全连接网络层,能够整合中文longformer层提取的关联信息,start softmax层计算各候选实体的起始位置概率,end softmax层计算各候选实体的终止位置概率,联合概率层依据加权值联合计算各候选实体的起始位置概率与终止位置概率,得到最终各候选实体的概率值,阈值选择层,预先定义概率阈值,选出联合概率大于概率阈值的候选实体,候选实体存储模块存储阈值选择层选择出的候选实体。
[0009]
具体包括如下步骤:步骤2-1:将候选实体生成阶段生成的候选实体集与冠心病诊断报告中文命名实体数据集中的句子内容进行拼接,新的句子内容为{m,ma1,ma2,cx_o,cx_u,ty,e1,e2
…
},新的句子内容中的别名名称ma1、ma2与候选实体中的e1、e2的名称对应,当新的句子内容输入到所述中文longformer层中时,需要根据所述中文longformer层要求将输入数据格式修改为:[cls]cx_o《t》m《/t》cx_u[sep][e](ma1|m)e1[sep][e](ma2|m)e2[sep],其中[cls]为起始标识符,《t》《/t》为实体提及标识符,(ma1|m)表示若别名名称ma与候选实体e对应则选择mae1为一个候选字段me,若没有别名名称ma与候选实体e对应,则将待消歧句子实体提及m与候选实体组成一个候选字段me;步骤2-2:中文 longformer层将待消歧句子实体提及m和各候选字段me设置为全局注意力,其他字段设置为局部注意力,提高对候选字段的筛选能力;步骤2-3:输入数据经过中文longformer层处理后,将得到各字词之间的关联向量,将所述各字词之间的关联向量输入到所述linear layer层后,linear layer层将整合句子中各字词之间的关联向量,得到各字段之间的关联向量,交由start softmax层和end softmax层处理:(7)表示不同字词之间的关联向量,longformer()为模型函数,x为嵌入向量,pe为位置向量:(8)为不同字段之间的关联向量,linear()为linear layer层函数;步骤2-4:start softmax层根据步骤2-3整合后的各字段之间的关联向量计算出各候选字段起始位置与待消歧句子实体提及m的关联概率,end softmax层根据整合后的各字段之间的关联向量计算各候选字段终止位置与待消歧句子实体提及m的关联概率:(9)
表示候选字段起始位置与待消歧句子实体提及m的关联概率,softmax()为start softmax层概率函数;(10)表示候选字段终止位置与待消歧句子实体提及m的关联概率;步骤2-5:所述联合概率层根据步骤2-4得到的各候选字段起始位置关联概率与终止位置关联概率,进行加权计算,得到最终各候选字段的关联概率:(11)表示候选字段与实体提及的联合概率;表示关联概率权重,;步骤2-6:所述阈值选择层根据各候选字段的关联概率选择出大于概率阈值的候选字段
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)e2为候选字段集;为自定义概率阈值;步骤2-7:将选择出的候选字段中的候选实体e存储到候选实体存储模块中,候选实体存储模块采用mysql数据库对候选实体进行存储,存储格式为{实体提及名m:候选实体e1,候选实体e2
…
};步骤2-8:将当前待消歧句子实体提及m的候选实体集存储后,返回到所述候选实体生成阶段,对下一个待消歧句子实体提及m执行候选实体生成和候选实体排序,直到所有的待消歧句子实体提及m都执行完前两个阶段。
[0010]
本发明中:所述一致性校验阶段由self attention层、全连接层、残差网络、softmax层、类树结构构建层和最大子树计算层构成,所述self attention层、全连接层和残差网络构成encoder模块,用来提取不同待消歧句子实体提及m的候选实体之间的关联信息,softmax层用来计算不同待消歧句子实体提及m的候选实体之间的关联概率,类树结构构建层用来根据各候选实体和关联概率构建类树结构,最大子树计算层用来计算类树结构中各子树节点的概率总分,寻找到最高的子树概率总分。
[0011]
具体包括如下步骤:步骤3-1:将候选实体存储模块中存储的相邻两个实体提及的候选实体集拼接,作为一致性校验阶段中self attention层的输入数据,拼接后的数据格式为:[cls]ae1[e]ae2[e]be1[e]be2[sep],其中ae1、ae2表示实体提及a的候选实体,be1、be2表示实体提及b的候选实体,且候选实体a和b为相邻实体提及;步骤3-2:所述self attention层通过计算得到输入数据的嵌入向量和位置向量,根据嵌入向量和位置向量信息,结合多头注意力机制得到各字词之间的关联向量;
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)表示候选实体中各字词关联向量,sf()为self attention关联向量计算函数;步骤3-3:全连接层整合步骤3-2多头注意力机制得到的各字词之间的关联向量,
形成一个整体关联向量,残差网络层对关联向量进行归一化处理,防止网络退化:
ꢀꢀꢀꢀꢀꢀꢀ
(14)表示候选实体中各字段整体关联向量,fd表示全连接层计算函数,(15)为归一化关联向量,an为残差网络处理函数;步骤3-4:将经过步骤3-3归一化处理后的关联向量再经过一次encoder模块计算,得到最终各字段之间的关联向量:(16)为各候选实体字段之间的关联向量,encoder()为encoder模块整体计算函数;步骤3-5:softmax层根据步骤3-4最终各字段之间的关联向量,计算出相邻实体提及的候选实体之间的关联概率:
ꢀꢀ
(17)p(a,b)表示相邻两个实体提及的候选实体关联概率,softmax()表示计算相邻两个实体提及的候选实体关联概率;步骤3-6:类树结构构建层首先创建一个虚拟根节点,再将步骤3-5计算的相邻实体提及的候选实体作为类树节点,虚拟根节点与候选实体生成阶段中第一个待消歧句子实体提及的候选实体之间存在单向关系,由虚拟根节点指向候选实体节点,关系边值为1,第一个待消歧句子实体提及之后出现的相邻的待消歧句子实体提及的候选实体之间存在双向关系,关系边值为softmax层计算出的相邻实体提及的候选实体之间的关联概率,建立完此次两个相邻的类树节点后,返回步骤3-1,循环执行,直到所有相邻实体提及的候选实体都已被作为类树节点;步骤3-7:最大子树计算层根据类树结构中的节点与边值数据,每次计算将虚拟根节点到最后一个候选实体节点的边值总和,作为一个子树边值总和,保证计算每个子树时,需要从每层实体提及中选择一个候选实体对象,并且所构建的所有子树不能相同,最终比较各子树边值总和,输出边值总和最高的子树:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(18)sum表示候选实体节点子树边值和,i=0时,表示虚拟根节点与第一候选节点的边值,n表示一条子树的深度,表示相邻两个实体提及的候选实体关联概率,即子树节点边值;
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(19)e3表示最终输出节点,max ()为计算所有子树边值和的最大值;
步骤3-8:最后边值总和最高的子树上的节点,即为各实体提及消歧的目标候选实体。
[0012]
最终由一致性校验过程得到的目标候选实体,能够对冠心病诊断报告中的歧义名称,实现消除歧义的作用,使自然语言处理技术在处理相关术语时,能够明确该术语含义,提高后续处理任务的准确率。
[0013]
本发明的有益效果是:(1)本发明采用别名表和嵌入标准医学术语的知识库,提高冠心病诊断报告中医学实体别名识别和英文简称名的消歧效果,(2)本发明采用中文gpt2预训练模型,和注意力机制能利用实体提及的上下信息和实体提及类型信息,从嵌入标准医学术语的知识库中生成关联度较高的候选实体集,提高候选实体的选择效果,减少无关候选实体数量。
[0014]
(3)本发明采用中文longformer注意力机制和两个位置概率softmax函数模型,将候选实体筛选转变为一种文本提取式任务,中文longformer注意力机制能够更多的关注到候选实体与实体提及之间的关系,提高目标候选实体的筛选准确率。
[0015]
(4)本发明采用类树结构构建和最大子树计算方式,能够计算相邻候选实体的关联概率,提高整个段落文本的消歧一致性和消歧结果准确率。
附图说明
[0016]
图1是本发明命名实体消歧方法的整体流程图。
[0017]
图2是本发明命名实体消歧方法的候选实体生成阶段流程图。
[0018]
图3是本发明命名实体消歧方法的候选实体排序阶段流程图。
[0019]
图4是本发明命名实体消歧方法的一致性校验阶段流程图。
[0020]
图5是本发明命名实体消歧方法的一致性校验阶段的候选实体类树结构图。
具体实施方式
[0021]
以下将以图式揭露本发明的实施方式,为明确说明起见,许多实务上的细节将在以下叙述中一并说明。然而,应了解到,这些实务上的细节不应用以限制本发明。也就是说,在本发明的部分实施方式中,这些实务上的细节是非必要的。此外,为简化图式起见,一些习知惯用的结构与组件在图式中将以简单的示意的方式绘示之。
[0022]
如图1所示,本发明是一种面向中文冠心病诊断报告的命名实体消歧方法,主要包括三个阶段:候选实体生成阶段、候选实体排序阶段和一致性校验阶段。
[0023]
其中候选实体生成阶段根据冠心病诊断报告中文命名实体数据集,由生成模块生成相关候选实体集;候选实体排序阶段将冠心病诊断报告中文命名实体数据集和候选实体生成阶段生成的候选实体集进行拼接,由排序筛选模块对候选实体集进行筛选,得到新的候选实体集,并保存在候选实体存储模块中,当处理实体提及的候选实体集存储后,返回第一阶段对下一个实体提及执行候选实体生成和候选实体排序,直到所有的实体提及都执行完前两个阶段;一致性校验阶段根据候选实体存储模块中保存的两个相邻实体提及的候选实体集,通过注意力模块和类树构建模块,得到段落文本所有每个实体提及的最终目标候选实体,提高整个段落文本的消歧准确率。
[0024]
下面结合实施例具体说明本发明的命名实体消歧方法。
[0025]
本发明摘取一段中文冠心病诊断报告内容如:“心前区无隆起,未触及震颤,无抬举性搏动,心浊音界无扩大,心率80次/分,律齐,a2》p2,心尖部可闻及sm3/6级吹风样杂音。”将“抬举性搏动”和英文简称名“sm”作为待消歧实体提及。消歧目标是找到“抬举性搏动”的标准医学术语,找到“sm”对应的的中文含义。“抬举性搏动”的类型定义为症状,“sm”的类型定义为观测操作。
[0026]
第一次待消歧的句子内容为{“抬举性搏动”,“心前区无隆起,未触及震颤,无”,“,心浊音界无扩大,心率80次/分,律齐,a2》p2,心尖部可闻及sm3/6级吹风样杂音。”,“症状”}。第二次待消歧的句子内容为{“sm”,“心前区无隆起,未触及震颤,无抬举性搏动,心浊音界无扩大,心率80次/分,律齐,a2》p2,心尖部可闻及”,“3/6级吹风样杂音。”,“观测操作”}。
[0027]
实体别名表中定义有{1:“抬举性搏动”,“心尖搏动”,“心尖抬举性搏动”}。候选实体知识库中定义有{1:名称:“抬举性搏动”,类型:“症状”,描述:“指心脏徐缓的、有力的搏动”;2:名称“心尖抬举性搏动”,类型:“症状”,描述:“是一个医学名词,指心尖区徐缓的、有力的搏动。”;3:名称:“心尖搏动”,类型:“症状”,描述:“心尖撞击心前区胸壁,使相应部位肋间组织向外搏动”;4:名称:“收缩期杂音(systolic murmur)”,类型:“观测操作”,描述:“是临床最常见的杂音,是心脏杂音中的一种”;5:名称:“链霉素(streptomycin)”,类型:“药物”,描述:“是一种从灰链霉菌的培养液中提取的抗菌素”;6:名称:“脊髓空洞症(syringomyelia)”,类型:“症状”,描述:“是脊髓的一种慢性、进行性的病变”;7,名称:“抗sm抗体”,类型:“观测操作”,描述:“属于抗核抗体的其中一种,其在系统性红斑狼疮病人血清中可被发现”};如图2所示,执行第一步候选实体生成阶段。
[0028]
s11,由第一次待消歧句子数据,根据实体提及和实体类型从实体别名表,找到“抬举性搏动”的别名名称,“心尖抬举性搏动”和“心尖搏动”,将实体提及的别名名称添加到数据集的句子内容中,则数据集中的句子内容为:{“抬举性搏动”,“心尖抬举性搏动”,“心尖搏动”,“心前区无隆起,未触及震颤,无”,“,心浊音界无扩大,心率80次/分,律齐,a2》p2,心尖部可闻及sm3/6级吹风样杂音。”,“症状”}。
[0029]
s12,数据集中的句子内容需要根据中文gpt2预训练模型输入数据st格式调整为:《s》输出待消歧句子实体提及m的候选实体[e]抬举性搏动[e]心尖抬举性搏动[e]心尖搏动[e]心前区无隆起,未触及震颤,无[e]抬举性搏动[e],心浊音界无扩大,心率80次/分,律齐,a2》p2,心尖部可闻及sm3/6级吹风样杂音。[e]症状[sep]。
[0030]
s13,根据输入数据st进行输入编码,gpt2从嵌入矩阵中查找各汉字对应的嵌入向量,根据《s》起始标识符和各汉字在st中的位置,得到各汉字的位置编码向量。
[0031]
s14,各汉字的嵌入向量和位置编码向量相加后构成表示向量,将表示向量输入到中文gpt2预训练模型中的decoder模块中,decoder模块根据自注意力机制为每个汉字都赋予一个相关度得分,经过向量表征求和,得到各字词之间的关联概率。
[0032]
s15,微调后的中文gpt2预训练模块,能够根据st中的实体提及和别名名称,结合实体上下文信息和实体类型信息,与候选实体知识库中的候选实体信息之间,计算相似值,假设相似值阈值p=0.6,sorce(e1,st)=0.78,sorce(e2,st)=0.8,sorce(e3,st)=0.7。则“抬
举性搏动”,“症状”,“指心脏徐缓的、有力的搏动”;“心尖抬举性搏动”,“症状”,“是一个医学名词,指心尖区徐缓的、有力的搏动。”;“心尖搏动”,“症状”,“心尖撞击心前区胸壁,使相应部位肋间组织向外搏动”都符合条件,为候选实体生成阶段的输出候选实体集。
[0033]
如图3所示,执行第二阶段候选实体排序阶段。
[0034]
s21,将候选实体生成阶段生成的候选实体集与数据集中的句子内容进行拼接,新的句子内容为{“抬举性搏动”,“心尖抬举性搏动”,“心尖搏动”,“心前区无隆起,未触及震颤,无”,“,心浊音界无扩大,心率80次/分,律齐,a2》p2,心尖部可闻及sm3/6级吹风样杂音。”,“症状”。“抬举性搏动”,“症状”,“指心脏徐缓的、有力的搏动”;“心尖抬举性搏动”,“症状”,“是一个医学名词,指心尖区徐缓的、有力的搏动。”;“心尖搏动”,“症状”,“心尖撞击心前区胸壁,使相应部位肋间组织向外搏动”;}。当句子内容输入到中文longformer层中时,需要根据模型要求将输入数据格式修改为:[cls] 心前区无隆起,未触及震颤,无《t》抬举性搏动《/t》,心浊音界无扩大,心率80次/分,律齐,a2》p2,心尖部可闻及sm3/6级吹风样杂音。[sep][e]
ꢀ“
抬举性搏动”,“症状”,“指心脏徐缓的、有力的搏动”[sep][e]
ꢀ“
心尖抬举性搏动”,“症状”,“是一个医学名词,指心尖区徐缓的、有力的搏动。”[e]
ꢀ“
心尖搏动”,“症状”,“心尖撞击心前区胸壁,使相应部位肋间组织向外搏动”[sep]。
[0035]
s22,中文 longformer层将实体提及和各候选字段设置为全局注意力,其他字段设置为局部注意力。
[0036]
s23,输入数据经过中文longformer层处理后,将得到的各字词之间的关联向量输入到linear layer层后,linear layer层计算得到各字段之间的关联向量,交由start softmax和end softmax处理。
[0037]
s24,start softmax计算出各候选字段起始位置与实体提及的关联概率,end softmax计算各候选字段终止位置与实体提及的关联概率。
[0038]
s25,联合概率层根据各候选字段起始位置关联概率与终止位置关联概率,设置权重信息,得到最终各候选字段的关联概率。假设jp(me1,m)=0.7,jp(me2,m)=0.8,jp(me3,m)=0.55。
[0039]
s26,设置阈值选择层阈值p=0.6,则“抬举性搏动”,“症状”,“指心脏徐缓的、有力的搏动”;“心尖抬举性搏动”,“症状”,“是一个医学名词,指心尖区徐缓的、有力的搏动。”符合要求,为候选实体排序阶段的输出候选实体集。
[0040]
s27,将选择出的候选字段中的候选实体存储到候选实体存储模块中。
[0041]
s28,将当前“抬举性搏动”的候选实体集存储后,返回第一阶段对下一个“sm”实体提及执行候选实体生成和候选实体排序,直到所有的实体提及都执行完前两个阶段。
[0042]
对第二次待消歧句子执行前两步阶段,对“sm”实体提及进行处理,假设经过第二步候选实体排序阶段输出的候选实体集为e1:“收缩期杂音(systolic murmur)”,“观测操作”,“是临床最常见的杂音,是心脏杂音中的一种”;e2:“抗sm抗体”,“观测操作”,“属于抗核抗体的其中一种,其在系统性红斑狼疮病人血清中可被发现”。将选择出的候选字段中的候选实体存储到候选实体存储模块中。
[0043]
如图4所示,执行第三步一致性校验阶段。
[0044]
s31,将候选实体存储模块中存储的相邻两个实体提及的候选实体集拼接,作为一致性校验阶段中self attention层的输入数据,拼接后的数据格式为:[cls]“抬举性搏
动”,“症状”,“指心脏徐缓的、有力的搏动”[e]“心尖抬举性搏动”,“症状”,“是一个医学名词,指心尖区徐缓的、有力的搏动。”[e]“收缩期杂音(systolic murmur)”,“观测操作”,“是临床最常见的杂音,是心脏杂音中的一种”[e]“抗sm抗体”,“观测操作”,“属于抗核抗体的其中一种,其在系统性红斑狼疮病人血清中可被发现”[sep]。假设候选实体标号按句子顺序内容ae1, ae1,be1,be2。
[0045]
s32,self attention层,结合多头注意力机制得到各字词之间的关联向量。
[0046]
s33,全连接层整合多头注意力机制得到的各字词之间的关联向量,形成一个整体关联向量。残差网络层对关联向量进行归一化处理。
[0047]
s34,将经过归一化处理后的关联向量再经过一次encoder模块计算,得到最终各字段之间的关联向量。
[0048]
s35,softmax层根据最终各字段之间的关联向量,计算出“抬举性搏动”和“sm”的候选实体之间的关联概率。假设p(ae1,be1)=0.8,p(ae1,be2)=0.2,p(ae2,be1)=0.9,p(ae2,be2)=0.1,p(be1,ae1)=0.4,p(be1,ae2)=0.6,p(be2,ae1)=0.5,p(be2,ae2)=0.5。
[0049]
s36,构建类树结构如图5所示,其中wa1=0.8,wa2=0.2,wa3=0.9,wa4=0.1,wb1=0.4,wb2=0.6,wb3=0.5,wb4=0.5。
[0050]
s37,根据最大子树计算层得到最大子树值和sum=1 0.9 0.6=root ae2 be1。
[0051]
s38,所以“抬举性搏动”的目标候选实体是“心尖抬举性搏动”,“症状”,“是一个医学名词,指心尖区徐缓的、有力的搏动。”;“sm”的目标候选实体是“收缩期杂音(systolic murmur)”,“观测操作”,“是临床最常见的杂音,是心脏杂音中的一种”。
[0052]
由一致性校验过程得到的目标候选实体,能够对冠心病诊断报告中的歧义名称,实现消除歧义的作用,使自然语言处理技术在处理相关术语时,能够明确该术语含义,提高后续处理任务的准确率。
[0053]
以上所述仅为本发明的实施方式而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原理的内所作的任何修改、等同替换、改进等,均应包括在本发明的权利要求范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。