一种提升deepfake视频检测精度的方法
技术领域
1.本发明涉及人脸视频伪造检测技术领域,特别是涉及一种提升deepfake视频检测精度的方法。
背景技术:
2.换脸技术deepfake是由“deep machine learning”(深度机器学习)和“fake photo”(假照片)组合而成,该技术出现后,给大众带来欢乐的同时,也在被不少人滥用,对社会造成危害。因此就需要相应的视频检测以识别检测其真伪,即对视频流中的伪造人脸进行伪造检测以识别其中的人脸的真伪,以满足用户对人脸伪造视频甄别的要求。然而现有人脸伪造检测技术在视频检测精度、检测时间以及运行速度上均有待进一步提升。
技术实现要素:
3.本发明的目的是针对现有技术中存在的技术缺陷,而提供一种提升deepfake视频检测精度的方法。
4.为实现本发明的目的所采用的技术方案是:
5.一种提升deepfake视频检测精度的方法,包括步骤如下:
6.对真实人脸视频及基于该真实人脸视频形成的伪造人脸视频分别解码,并按帧存储为不同的图像序列;
7.对输入的伪造人脸图像序列逐个进行人脸检测;
8.利用跟踪方法对人脸检测中提取的人脸检测框位置修正,保存修正后人脸检测框的位置;
9.利用关键点检测算法提取修正后人脸检测框内人脸区域的关键点信息;
10.利用修正后人脸检测框位置裁剪真实人脸图像序列中真实人脸视频中对应的真实人脸,构建soft label扩增数据;
11.利用所述关键点信息,根据人脸对齐算法对裁剪的真实视频中的人脸进行人脸姿态矫正;
12.图像序列遍历完成后,将真实人脸视频与伪造人脸视频中不同id人脸与soft label扩增后人脸分别存储,用于后续深度伪造鉴别模型训练。
13.本发明通过对伪造人脸序列进行检测跟踪,保存人脸检测框,然后直接在对应到真实人脸序列中提取直实人脸位置,可以大幅缩减检测时间。
14.本发明通过利用soft label(软标签)进行数据扩增,可以让标签更为平滑,训练更容易收敛,同时通过设置不同的权重参数weight可以对训练数据扩增,进行高效增广,最终提升模型性能。
附图说明
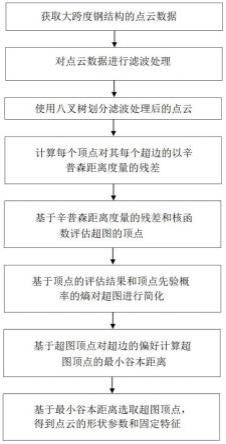
15.图1是本发明实施例的提升deepfake视频检测精度的方法的整体流程示意图。
16.图2为本发明实施例的提升deepfake视频检测精度的方法处理过程的示意图。
17.图3为本发明实施例的通过soft label形成的多个融合图像的示意图。
具体实施方式
18.以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
19.如图1所示,本发明实施例的提升deepfake视频检测精度的方法,包括步骤:
20.对真实人脸视频及基于该真实人脸视频形成的伪造人脸视频分别解码,并按帧存储为不同的图像序列;
21.对输入的伪造人脸图像序列逐个进行人脸检测;
22.利用跟踪方法对人脸检测中提取的人脸检测框位置修正,保存修正后人脸检测框的位置;
23.利用关键点检测算法提取修正后人脸检测框内人脸区域的关键点信息;
24.利用修正后人脸检测框位置裁剪真实人脸图像序列中真实人脸视频中对应的真实人脸,构建soft label扩增数据;
25.利用所述关键点信息,根据人脸对齐算法对裁剪的真实视频中的人脸进行人脸姿态矫正;
26.图像序列遍历完成后,将真实人脸视频与伪造人脸视频中不同id人脸与soft label扩增后人脸分别存储,用于后续深度伪造鉴别模型训练。
27.由于在公开测试集及自主生成的deepfake伪造数据集中,大多包含伪造视频及其对应到真实视频,由于存在多种不同生成方法,故一种真实视频可生成多个伪造视频,利用这些视频中对应帧人脸位置一致的关系,可以在一个真实或伪造视频中检测出人脸位置后,直接用该位置裁剪其他视频中的人脸区域。
28.本发明实施例通过对伪造人脸序列进行检测跟踪,保存检测框,然后直接在对应到真实人脸序列中提取人脸位置,可以大幅缩减检测时间。
29.现有deepfake检测方法中,均采用hard label,即将真实视频的标签定为0,伪造视频的标签定为1,本发明从伪造人脸与真实人脸存在对应关系的角度出发,将真实人脸与伪造人脸进行不同比例的融合,从而获得不同的label,形成获得融合图像的不同soft label。
30.如设权重参数weight为0.1,代表伪造人脸(fake)权重为0.1,真实人脸(real)权重为0.9,此时融合后图像的soft label为0.1,融合后的图像表达如下:
31.f
merge
=weight*f
fake
(1-weight)*f
real
32.f
merge
代表融合后的图像,f
fake
代表伪造人脸图像,f
real
代表真实人脸图像。
33.通过上述的利用soft label,可以让标签更为平滑,训练更容易收敛,同时通过设置不同的权重参数weight∈(0,1)可以对训练数据扩增,进行高效增广,最终提升模型性能,形成的不同的融合图像,请参见图3所示。
34.另外,本发明实施例中引入跟踪及识别算法,可处理一帧图像中出现多个人脸的情况,利用识别算法,可以将不同id的人脸存储于不同的序列,为后续鉴伪方法提供便利,使其具备评价视频真伪能力的同时,可以准确判别视频中具体的伪造人物。
35.参见图2所示,通过黑色质心的波动对比可以看到,在检测过程中引入跟踪技术或方法后,波动减小,更为稳定、平滑的人脸裁剪框可以减少抖动噪声,可以让基于时序的鉴伪模型更关注帧间的时序信息。
36.对人脸跟踪时,主要是通过预测下一时刻的人脸检测框来实现的:已知t-1时刻下人脸检测框位置为x
t-1
,y
t-1
,w
t-1
,h
t-1
,分别代表t-1时刻检测框左上角坐标点和检测框的宽度与高度,设视频序列中,人脸匀速运动,即为常数,t时刻下人脸检测框的位置由于检测过程中,检测框位置存在抖动,因此需要预测t时刻下检测框的最优位置。
37.为提升运行速度,本发明实施例将跟踪算法中的参数矩阵改为上三角矩阵,如跟踪过程中的系统状态用x
[x,y,w,h,δx,δy,δw,δh]
表示,其元素分别代表人脸检测框的左上角顶点坐标、检测框的长度、宽度以及它们的变化量;
[0038]
其中,系统状态方程a表示如下:
[0039][0040]
视频中人脸运动中不存在控制变量b,即b=0,w为高斯白噪声,设置为0,则系统状态可表示为:x`(t)=ax(t-1),
[0041]
人脸检测先验协方差为:p`(t)=ap(t-1)a` q,
[0042]
当t=1时:
[0043][0044]
q是人脸检测系统协方差,恒定为:
[0045][0046]
则此时人脸检测增益表示如下:
[0047][0048]
则得到新的
[0049]
相比于直接基于卡尔曼滤波跟踪的方法,优化系统状态方程、先验协方差、系统协方差矩阵,均设置为上三角矩阵,在略微损失精度的情况下,能有效提升运行速度,同时便于后续编程与计算,从实验结果来看,结果精度损失较小。
[0050]
下表为本发明的方法与同类检测方法的比较效果。
[0051][0052]
上表中,uadfv、deeperforensics-1.0、celeb-df均为伪造鉴别常用测试集;resnet18、resnet50为现有残差网络的18、50层结构;最后一栏inference为对应的算法处理每帧输入图像的耗时ms(毫秒)
[0053]
resnet50代表直接将检测结果输入残差网络中进行判别;
[0054]
res50 tracking代表将检测结果用现有跟踪方法优化后,输入残差网络进行判别;
[0055]
res50 our_tracking代表将检测结果用本发明实施例的上三角优化后的跟踪方法平滑处理,输入残差网络进行判别;
[0056]
res50 our_tracking soft_label代表在res50 our_tracking的基础上,利用soft_label对输入数据进行增广。
[0057]
从实验结果来看,计算优化后的跟踪方法可以提升一部分的前传速度,同时精度
的降低较小,加入soft label后,模型的性能有较大的提升
[0058]
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。