技术特征:
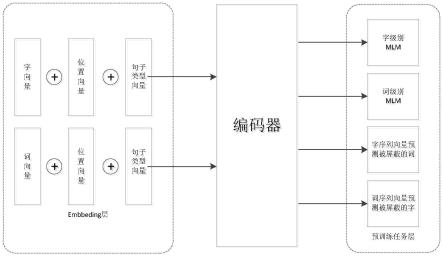
1.一种字词多粒度混合的中文语言模型预训练方法,其特征在于,包括以下步骤:步骤1,对输入的文本text进行字粒度切分,得到字序列seq_char_1;其中,字序列seq_char_1包括n个按序排列的字,分别表示为:字char1,字char2,
…
,字char
n
;对输入的文本text进行词粒度切分,得到词序列seq_word_1;其中,词序列seq_word_1包括m个按序排列的词,分别表示为:词word1,词word2,
…
,词word
m
;步骤2,在词序列seq_word_1中,随机选择词word
i
进行屏蔽,其中,i=1,2,
…
,m,得到屏蔽后的词序列,表示为:词序列seq_word_2;假设词word
i
一共包括k个字;在字序列seq_char_1中,将词word
i
分字后对应的k个字进行屏蔽,得到屏蔽后的字序列,表示为:字序列seq_char_2;步骤3,将字序列seq_char_2中每个字进行向量化,得到字向量embbeding_char;字序列seq_char_2中各个字的字向量embbeding_char,组成字序列seq_char_2的字向量组合;将词序列seq_word_2中每个词进行向量化,得到词向量embbeding_word;词序列seq_word_2中各个词的词向量embbeding_word,组成词序列seq_word_2的词向量组合;步骤4,采用编码器,对字向量组合的每个字向量embbeding_char进行编码,得到字编码向量v
char
;字向量组合的所有字编码向量v
char
,组成字编码向量矩阵v
char
;采用编码器,对词向量组合的每个词向量embbeding_word进行编码,得到词编码向量v
word
;词向量组合的所有词编码向量v
word
,组成词编码向量矩阵v
word
;步骤5,将字编码向量矩阵v
char
和词编码向量矩阵v
word
输入到预训练任务层,采用以下方法,计算得到总损失函数loss
总
:步骤5.1,预训练任务层包括字级别任务、词级别任务、字序列向量预测被屏蔽的词任务和词序列向量预测被屏蔽的字任务;步骤5.2,通过字级别任务,采用以下公式,得到第一损失函数loss1(x,θ):其中:p(x
a
|v
char
)含义为:在字编码向量矩阵v
char
中,读出某个被预测的屏蔽字x
a
的向量,使读出的屏蔽字x
a
的向量与字典矩阵作乘法,得到概率矩阵;在该概率矩阵中,得到概率值最大值,即为p(x
a
|v
char
);其中,字典矩阵为字典中每个字的字向量emb_char形成的矩阵;-log p(x
a
|v
char
):代表交叉熵计算,即:使用标准的交叉熵对p(x
a
|v
char
)进行计算,得到屏蔽字x
a
的损失值;e():代表求平均计算;具体含义为:对于k个屏蔽字,每个屏蔽字预测得到一个损失值;然后,对k个屏蔽字的损失值求和,再除以k,得到平均损失值;步骤5.3,通过词级别任务,采用以下公式,得到第二损失函数loss2(x,θ):其中:
p(x
b
|v
word
)含义为:在词编码向量矩阵v
word
中,读出某个被预测的屏蔽词x
b
的向量,使读出的屏蔽词x
b
的向量与词典矩阵作乘法,得到概率矩阵;在该概率矩阵中,得到概率值最大值,即为p(x
b
|v
word
);其中,词典矩阵为词典中每个词的向量emb_word形成的矩阵;g为词序列中被屏蔽的词的数量;-log p(x
b
|v
word
):代表交叉熵计算,即:使用标准的交叉熵对p(x
b
|v
word
)进行计算,得到屏蔽词x
b
的损失值;步骤5.4,通过字序列向量预测被屏蔽的词任务,采用以下公式,得到第三损失函数loss3(x,θ):其含义为:在词序列中具有g个屏蔽词;对于每个被预测的屏蔽词x
b
,采用以下方法,得到其上下文向量:假设屏蔽词x
b
包括r个屏蔽字;在字编码向量矩阵v
char
中,定位到连续的屏蔽词x
b
包括的r个屏蔽字,表示为:字char
m1
,字char
m2
,
…
字char
mr
;字char
m1
前面最近的字记为c
b0
,字char
mr
后面最近的字记为c
b1
;字c
b0
的字向量和字c
b1
的字向量进行concat拼接操作,得到屏蔽词x
b
的上下文向量,即:即:含义为:使屏蔽词x
b
的上下文向量与词典矩阵作乘法,得到概率矩阵;在该概率矩阵中,得到概率值最大值,即为即为使用标准的交叉熵对进行计算,得到屏蔽词x
b
的损失值;步骤5.5,通过词序列向量预测被屏蔽的字任务,采用以下公式,得到第四损失函数loss4(x,θ):其含义为:在词序列中具有g个屏蔽词;每个屏蔽词对应字序列中的g组连续的屏蔽字;对于字序列中第c组连续的屏蔽字x
c
,采用以下方法,得到其上下文向量:在词编码向量矩阵v
word
中,定位到第c组连续的屏蔽字x
c
对应的1个屏蔽词,该屏蔽词前面最近的词的词向量为该屏蔽词后面最近的词的词向量为将词向量和词向量进行concat拼接操作,得到第c组连续的屏蔽字x
c
的上下文向量,即:
含义为:对进行线性变换,得到线性变换后的向量;含义为:使用序列到序列seq2seq模型,包括编码端和解码端;在编码端输入线性变换后的向量;在解码端输出预测到的第c组连续的屏蔽字x
c
以及第c组连续的屏蔽字x
c
的预测概率值;使用标准的交叉熵对进行计算,得到第c组连续的屏蔽字x
c
的损失值;对第一损失函数loss1、第二损失函数loss2、第三损失函数loss3和第四损失函数loss4进行加权平均,得到总损失函数loss
总
;步骤6,判断训练是否达到最大迭代次数,如果否,则根据总损失函数loss
总
得到梯度,对模型参数θ进行反传和参数更新,返回步骤4;如果是,则停止训练,得到预训练完成的语言模型。2.根据权利要求1所述的一种字词多粒度混合的中文语言模型预训练方法,其特征在于,步骤2中,词word
i
进行屏蔽,具体方法为:在词序列seq_word_1中,使用屏蔽符号[mask]替换词word
i
,得到屏蔽后的词序列seq_word_2。3.根据权利要求1所述的一种字词多粒度混合的中文语言模型预训练方法,其特征在于,步骤2中,对k个字进行屏蔽,具体方法为:在字序列seq_char_1中,对于k个字中的每一个字,均使用屏蔽符号[mask]替换,得到屏蔽后的字序列seq_char_2。4.根据权利要求1所述的一种字词多粒度混合的中文语言模型预训练方法,其特征在于,步骤3中,将字序列seq_char_2中每个字进行向量化,得到字向量embbeding_char,具体为:对于字序列seq_char_2中每个字,其字向量embbeding_char包括三个部分,分别为:字向量emb_char、字位置向量emb_pos_char和字所在的文本text的类型向量emb_type;其中:字向量emb_char:字典记录每个字以及该字的字向量,通过查询字典,得到字向量emb_char;字位置向量emb_pos_char:指字在字序列seq_char_2中的位置所对应的向量,通过查询位置信息向量表emb_pos获得;字所在的文本text的类型向量emb_type:指文本text的类型所对应的向量。5.根据权利要求1所述的一种字词多粒度混合的中文语言模型预训练方法,其特征在于,步骤3中,将词序列seq_word_2中每个词进行向量化,得到词向量embbeding_word,具体为:对于词序列seq_word_2中每个词,其词向量embbeding_word包括三个部分,分别为:词向量emb_word、词位置向量emb_pos_word和词所在的文本text的类型向量emb_type;其中:词向量emb_word:词典记录每个词以及该词的词向量,通过查询词典,得到词向量emb_
word;词位置向量emb_pos_word:指词在词序列seq_word_2中的位置所对应的向量,通过查询位置信息向量表emb_pos获得;词所在的文本text的类型向量emb_type:指文本text的类型所对应的向量。6.根据权利要求1所述的一种字词多粒度混合的中文语言模型预训练方法,其特征在于,步骤3中,在对字序列seq_char_2中每个字进行向量化时,对于字序列seq_char_2中的每个屏蔽字,同样进行向量化;在对词序列seq_word_2中每个词进行向量化时,对于词序列seq_word_2中的每个屏蔽词,同样进行向量化。
技术总结
本发明提供一种字词多粒度混合的中文语言模型预训练方法,包括以下步骤:对输入的文本text进行字粒度切分和词粒度切分,分别得到字序列和词序列;对词序列中的某个词进行屏蔽,对字序列中对应字进行屏蔽;经向量化和编码后,采用四种预训练任务,计算总损失函数。本发明结合字和词两种粒度,提出包含字和词的新的中文语言模型预训练任务,通过将二者融合提升预训练模型效果。升预训练模型效果。升预训练模型效果。
技术研发人员:庞帅 战科宇 曹延森 王华英 王礼鑫 张欢
受保护的技术使用者:中国搜索信息科技股份有限公司
技术研发日:2022.08.09
技术公布日:2023/1/13
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。