1.本发明涉及文本处理技术领域,特别是涉及一种获取目标文本的数据处理系统。
背景技术:
2.随着互联网的普及和发展,文本数据呈现爆发式增长,面对海量文本数据,如何从其中提取出有意义的信息是自然语言处理的研究热点,文本分类技术是自然语言处理领域和文本识别领域的一大课题,近年来文本分类技术已经应用到信息检索、信息推送、信息过滤等多个领域,通过对文本准确分类能够减少获取文本重要信息的时间。
3.目前,现有技术中,获取目标文本的方法为:获取文本的字向量,根据文本中的字对应的字体书写的特征、字根和拼音获取对应的特征向量,将字向量和特征向量结合生成文本向量,对文本向量进行分类获取异常文本。
4.综上所述对文本进行分类的方法存在的问题:一方面,文本中的字符局限于中文字符,在进行文本分类时增加了对文本的选择的局限性;另一方面,未考虑文本中文字的图像特征和字符特征信息,遗漏了文本字符的特征,使得自然语言处理的准确度较低,降低了文本分类的准确度,进而使得获取到的目标文本的准确度较低。
技术实现要素:
5.本发明提供了一种获取目标文本的数据处理系统,包括:初始文本集、初始文本集中每一初始文本对应的初始图像、处理器和存储有计算机程序的存储器,当计算机程序被处理器执行时,实现以下步骤:s100,根据所述初始文本集中任一初始文本,获取初始文本对应的初始文本字符串a={a1,a2,
……
,ai,
……
,am},ai为初始文本对应的初始字符串中第i个初始文本字符,i=1,2,
……
,m,m为初始文本对应的初始字符串中初始文本字符的数量。
6.s200,根据a,获取a对应的初始字向量集b={b1,b2,
……
,bi,
……
,bm},bi为ai对应的初始字向量。
7.s300,根据a对应的初始图像,获取a对应的关键特征向量集d={d1,d2,
……
,di,
……
,dm},di为ai对应的关键特征向量。
8.s400,根据b和d,获取a对应的目标字向量集u={u1,u2,
……
,ui,
……
,um},ui={bi,di}。
9.s500,根据u,获取到a对应的目标文本。
10.本发明与现有技术相比具有明显的有益效果,借由上述技术方案,本发明提供的一种获取目标文本的数据处理系统可达到相当的技术进步性及实用性,并具有产业上的广泛利用价值,其至少具有以下有益效果:本发明提供了一种获取目标文本的数据处理系统,系统包括:处理器和存储有计算机程序的存储器,当计算机程序被处理器执行时,实现以下步骤:根据所述初始文本集中任一初始文本,获取初始文本对应的初始文本字符串,其中,初始文本字符至少包括中文字
符、英文字符和标点字符,根据初始文本字符串获取初始文本字符串对应的初始字向量集,根据初始文本字符串对应的初始图像,获取初始文本字符串对应的关键特征向量,其中,关键特征向量包括初始文本的图像特征和字符特征信息,其中图像特征包括文本字符的位置,字号和颜色,字符特征信息包括下划线、斜体等,根据初始字向量集和关键特征向量,获取初始文本字符串对应的目标字向量集,根据目标字向量集获取初始文本字符串对应的目标文本。上述,一方面,文本中的字符不局限于中文字符,在进行文本分类时减少了对文本的选择的局限性;另一方面,考虑了文本中文字的图像特征和字符特征信息,避免了文本字符特征的遗漏,使得自然语言处理的准确度较高,提高了文本分类的准确度,使得获取到的目标文本的准确度较高。
附图说明
11.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
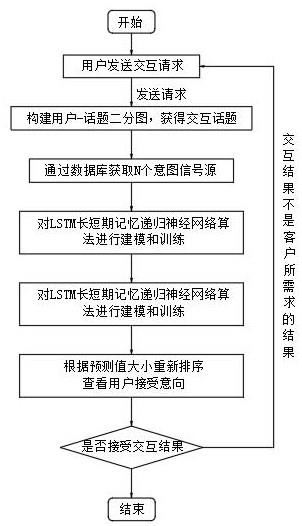
12.图1为本发明实施例提供的一种获取目标文本的数据处理系统的执行计算机程序的流程图。
具体实施方式
13.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
14.需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包括,例如,包括了一系列步骤或单元的过程、方法、系统、产品或服务器不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
15.本实施例提供了一种获取目标文本的数据处理系统,所述系统包括:初始文本集、初始文本集中每一初始文本对应的初始图像、处理器和存储有计算机程序的存储器,当所述计算机程序被处理器执行时,实现以下步骤,如图1所示:具体的,所述初始文本集包括若干个初始文本,其中,所述初始文本为包括异常文本字符的文本,例如,异常文本字符为具有广告性质的文本字符。
16.具体的,所述初始图像为对初始文本进行处理得到的图像,其中,本领域技术人员知晓,现有技术中任一基于文本生成图像的方法,均属于本发明的保护范围,在此不再赘述。
17.s100,根据所述初始文本集中任一初始文本,获取初始文本对应的初始文本字符
串a={a1,a2,
……
,ai,
……
,am},ai为初始文本对应的初始字符串中第i个初始文本字符,i=1,2,
……
,m,m为初始文本对应的初始字符串中初始文本字符的数量。
18.具体的,所述初始文本字符至少包括中文字符、英文字符和标点字符。
19.上述,文本中的字符不局限于中文字符,在进行文本分类时减少了对文本的选择的局限性。
20.s200,根据a,获取a对应的初始字向量集b={b1,b2,
……
,bi,
……
,bm},bi为ai对应的初始字向量。
21.具体的,每一初始字向量为通过将所述初始文本输入至预设的语言模型中获取到的,本领域技术人员知晓,现有技术中任一通过语言模型获取字向量的方法,均属于本发明的保护范围,在此不再赘述。
22.优选的,预设的语言模型为bert模型。
23.s300,根据a对应的初始图像,获取a对应的关键特征向量集d={d1,d2,
……
,di,
……
,dm},di为ai对应的关键特征向量。
24.具体的,所述关键特征向量包括第一关键特征向量或第二关键特征向量。
25.在一个具体的实施例中,所述关键特征向量为第一关键特征向量时,在s300步骤中还通过如下步骤获取di:s301,将a对应的初始图像输入至预设的ocr模型中,获取a对应的第一待选特征向量集g={g1,g2,
……
,gi,
……
,gm},gi={g
i1
,g
i2
,g
i3
,g
i4
,g
i5
},g
i1
为ai对应的字符检测框高度,g
i2
为ai对应的字符检测框宽度,g
i3
为ai对应的字符检测框的第一顶点坐标值,g
i4
为ai对应的字符检测框的第二顶点坐标值,g
i5
为ai的字符检测框颜色。
26.具体的,所述第一顶点坐标值对应的第一顶点和所述第二顶点坐标值对应的第二顶点为对角顶点。
27.s303,根据g
i1
和g
i2
,获取第一特征d
i1
。
28.具体的,在s303步骤中还包括如下步骤:s3031,获取第一预设字号的字号优先级和第二预设字号列表h={h1,h2,
……
,h
x
,
……
,h
p
},h
x
为第x个第二预设字号对应的字号优先级和第二预设字号对应的字号尺寸信息,x=1,2,
……
,p,p为预设字号的数量。
29.具体的,当h按照第二预设字号对应的字号优先级由大至小进行排序,表征了字号优先级对应的字号尺寸信息也由大至小进行排序;即预设字号对应的字号优先级大时,所述字号优先级对应的字号尺寸信息也大。
30.进一步的,所述字号尺寸信息包括字号宽度和字号高度。
31.进一步的,所述第一预设字号为预设的非正常字号。
32.进一步的,所述第二预设字号为预设的正常字号,本领域技术知晓,现有技术中任一字号,均属于本发明的保护范围,在此不再赘述。
33.s3033,当|(g
i1
/g
i2
)-β|≤β0,获取ai对应的字号尺寸差δgi={δg
i1
,δg
i2
,
……
,δg
ix
,
……
,δg
ip
},δg
ix
为ai与h
x
之间的字号尺寸差,其中,β为预设的尺寸比,β0为预设的尺寸比阈值。
34.具体的,δg
ix
符合如下条件:δg
ix
=|(g
i1
g
i2
)-(h
x1
h
x2
)|,其中,h
x1
为h
x
对应的字号尺寸信息中字号宽度,h
x2
对
应的字号尺寸信息中字号高度。
35.进一步的,所述尺寸比为字号高度和字号高度之间的比值。
36.s3035,遍历δgi且将δgi中最小的字号尺寸差对应的字号优先级作为d
i1
。
37.s3037,当|(g
i1
/g
i2
)-β|>β0时,将第一预设字号的字号优先级作为d
i1
。
38.上述,通过判断字符字号的尺寸比对文本字符进行分类,将文本字符的字号分为两种类型,一种为第一预设字号的字号优先级,另一种为第二预设字号,能够筛选出一部分非正常文本字符,为文本分类提供了一种判断条件,提高了文本分类的准确度,进而使得目标文本的准确度较高。
39.s305,根据g
i3
和g
i4
,获取第二特征d
i2
。
40.s3051,获取g
i3
=(g
1i3
,g
2i3
)和g
i4
=(g
1i4
,g
2i4
),其中,g
1i3
为g
i3
对应的像素点x轴坐标值,g
2i3
为g
i3
对应的像素点y轴坐标值,g
1i4
为g
i4
对应的像素点x轴坐标值,g
2i4
为g
i4
对应的像素点y轴坐标值。
41.s3053,根据g
i3
和g
i4
,确定出d
i2
=((g
1i3
g
1i4
)/2,(g
2i3
g
2i4
)/2)。
42.s307,对g
i5
进行处理,生成第三特征d
i3
,可以理解为:对g
i5
去除掉背景色后,生成的前景色作为第三特征,本领域技术人员知晓,现有技术中任一去掉背景色的方法,均属于本发的保护范围,在此不再赘述。
43.s309,根据d
i1
,d
i2
和d
i3
,确定出di={d
i1
,d
i2
,d
i3
}。
44.上述,基于初始文本对应的初始图像,能够获取到初始文本中初始文本字符的位置和大小等特征信息,通过文本对应的图像特征能够对文本进行筛选,更加快速获取初始文本对应的图像特征发生变化的文本字符,使得自然语言处理的准确度较高,提高了文本分类的准确度。
45.在另一个具体的实施例中,所述关键特征向量为第二关键特征向量时,在s300步骤中还通过如下步骤获取di:s301,将a对应的初始图像输入至预设的ocr模型中,获取a对应的第二待选特征向量集g0={g
01
,g
02
,
……
,g
0i
,
……
,g
0m
},g
0i
={g
0i1
,g
0i2
},g
0i1
为第一子特征向量,g
0i2
为第二子特征向量。
46.s303,根据g
0i1
,获取g
0i1
对应的第一中间特征向量q
0i1
。
47.具体的,g
0i1
的特征维度与上一实施例中gi的特征维度一致,在此不再赘述。
48.进一步的,根据g
0i1
获取q
0i1
的方法可以参照获取第一关键特征向量的方法,在此不再赘述。
49.s305,将g
0i2
={g
01i2
,g
02i2
,
……
,g
0yi2
,
……
,g
0qi2
},g
0yi2
为字符检测框对应的第y个字符信息,y=1,2,
……
,q,q为字符信息的数量,本领域技术人员知晓,现有技术中字符检测框对应的字符信息,均属于本发明的保护范围,在此不再赘述,例如,字符信息包括字符的斜体、下划线、加粗等。
50.s307,将g
0yi2
输入至g
0yi2
对应的分类器中,g
0yi2
对应的第二中间特征值q
0yi2
,以使得根据所有的q
0yi2
,构建成第二中间特征向量q
0i2
={q
01i2
,q
02i2
,
……
,q
0yi2
,
……
,q
0qi2
},本领域技术人员知晓,现有技术中根据分类器获取特征值的方法,均属于本发明的保护范围在此不再赘述。
51.进一步的,在s307步骤中还包括如下步骤:
当q
0yi2
=0时,确定g
0yi2
对应的字符检测框中存在字符信息。
52.当q
0yi2
=1时,确定g
0yi2
对应的字符检测框中未存在字符信息。
53.s309,根据q
0i1
和q
0i2
,确定出di={q
0i1
,q
0i2
}。
54.上述,在该实施例中,将初始文本对应的图像特征与初始文本对应的字符信息相结合作为初始文本对应的关键特征向量,丰富了文本对应的字向量的维度,避免了文本字符特征的遗漏,使得自然语言处理的准确度较高,提高了文本分类的准确度,进而使得获取到的目标文本的准确度较高。
55.s400,根据b和d,获取a对应的目标字向量集u={u1,u2,
……
,ui,
……
,um},ui={bi,di}。
56.s500,根据u,获取到a对应的目标文本。
57.具体的,在s500步骤中还包括如下步骤:s501,将u输入至预设的标注模型中,获取a对应的目标标签列表f={f1,f2,
……
,fi,
……
,fm},fi为ai对应的目标标签;本领域技术人员知晓,现有技术中任一通过标注模型获取标签的方法,均属于本发明的保护范围,在此不再赘述。
58.s503,当fi=1时,确定ai为异常字符且从a对应的初始文本中删除异常字符,生成a对应的目标文本。
59.上述,通过将初始文本对应的初始字向量和关键特征向量相结合,不再局限于文本编码模型获取到的每个字符对应的字向量,考虑了文字的图像特征和字符特征,丰富了文本目标字向量的维度,使得获取到文字的向量具有丰富的文本特征信息,提高了文本分类的准确性,使得获取的目标文本的准确度较高。
60.本发明提供了一种获取目标文本的数据处理系统,系统包括:处理器和存储有计算机程序的存储器,当计算机程序被处理器执行时,实现以下步骤:根据所述初始文本集中任一初始文本,获取初始文本对应的初始文本字符串,其中,初始文本字符至少包括中文字符、英文字符和标点字符,根据初始文本字符串获取初始文本字符串对应的初始字向量集,根据初始文本字符串对应的初始图像,获取初始文本字符串对应的关键特征向量,其中,关键特征向量包括初始文本的图像特征和字符特征信息,其中图像特征包括文本字符的位置,字号和颜色,字符特征信息包括下划线、斜体等,根据初始字向量集和关键特征向量,获取初始文本字符串对应的目标字向量集,根据目标字向量集获取初始文本字符串对应的目标文本。上述,一方面,文本中的字符不局限于中文字符,在进行文本分类时减少了对文本的选择的局限性;另一方面,考虑了文本中文字的图像特征和字符特征信息,避免了文本字符特征的遗漏,使得自然语言处理的准确度较高,提高了文本分类的准确度,使得获取到的目标文本的准确度较高。
61.虽然已经通过示例对本发明的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上示例仅是为了进行说明,而不是为了限制本发明的范围。本领域的技术人员还应理解,可以对实施例进行多种修改而不脱离本发明的范围和精神。本发明开的范围由所附权利要求来限定。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。