技术特征:
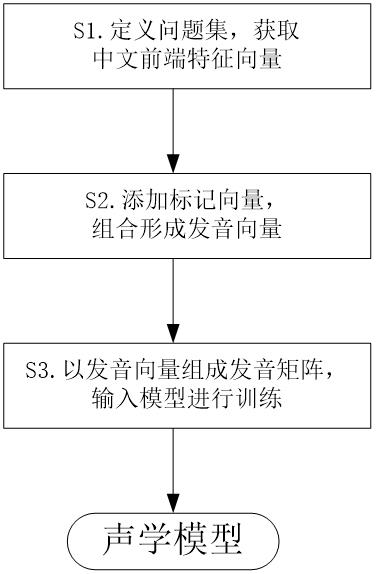
1.一种语音合成用声学模型训练方法,其特征在于,包括以下步骤:s1. 根据汉语发音规则,制定问题集,以问题集定义文本中每个汉字的中文前端特征向量,以m维发音向量表示;s2.对字母的发音,以汉语语言发音规则定义,并以步骤s1制定的问题集,对文本中出现的字母,赋予该字母的中文前端特征向量;在文本中每个文字的中文前端特征向量后添加n维标记向量,所述文字包括汉字和字母,添加的n维标记向量用于区分文字是汉字还是英文字母,所述n远小于m;添加后的(m n)维向量,表示该文字的发音向量;s3.将文本中各个文字的发音向量组合形成文本的发音矩阵,作为声学模型的输入,进行声学模型的训练,训练得到的声学模型用于语音合成。2.如权利要求1所述语音合成用声学模型训练方法,其特征在于,所述问题集均为判断类问题,所述中文前端特征向量的元素只有0,1两种。3.如权利要求1所述语音合成用声学模型训练方法,其特征在于,所述问题集包括原始读音子集和所处文本环境子集,所述原始读音子集以遍历方式对汉语发音的全部声母和韵母进行提问。4.如权利要求1所述语音合成用声学模型训练方法,其特征在于,所述n维标记向量的所有元素均相同。5.如权利要求1所述语音合成用声学模型训练方法,其特征在于,n:m=1:50-100。6.如权利要求1所述语音合成用声学模型训练方法,其特征在于,所述步骤s3中,训练时以梅尔频谱声学特征作为声学模型的输出。7.如权利要求3所述语音合成用声学模型训练方法,其特征在于,所述声学模型使用隐马尔可夫或dnn模型框架。
技术总结
一种语音合成用声学模型训练方法,包括以下步骤:S1.根据汉语发音规则,制定问题集,以问题集定义文本中每个汉字的中文前端特征向量,以m维发音向量表示;S2.对字母的发音,以汉语语言发音规则定义,并以步骤S1制定的问题集,对文本中出现的字母,赋予该字母的中文前端特征向量;在文本中每个文字的中文前端特征向量后添加n维标记向量,所述文字包括汉字和字母;S3.将文本中各个文字的发音向量组合形成文本的发音矩阵,作为声学模型的输入,进行声学模型的训练,训练得到的声学模型。采用本发明所述语音合成用声学模型训练方法,可以在增加少量特征维度的情况下,提升中文语音合成系统中字母的发音效果,节约算力和存储消耗。节约算力和存储消耗。节约算力和存储消耗。
技术研发人员:曹艳艳 陈佩云
受保护的技术使用者:成都启英泰伦科技有限公司
技术研发日:2022.11.28
技术公布日:2022/12/30
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。