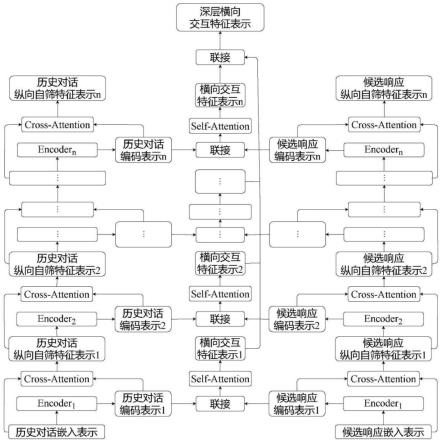
基于zed立体相机的行人空间信息感知方法及装置
技术领域
1.本发明涉及机器视觉领域,尤其是涉及了基于zed立体相机的行人空间信息感知方法及装置。
背景技术:
2.展厅、博物馆等公共场所中采用智能导览机器人代替人工讲解员可以有效的节省人力。导览机器人需要对所处环境进行智能感知,而行人作为场景中的动态目标具有不确定性,对行人的空间位置及移动速度等空间信息进行智能感知具有重要意义。
3.视觉是机器人获取外部信息的重要方式。根据2d图像首先获取行人检测框,然后再根据坐标系转换关系及深度信息或者点云信息获取行人空间位置信息,这种方法依赖于行人检测框的精准度,而行人具有柔性及身体姿态不断变化的特性,传统的行人检测包围框在行人肢体变化时会存在大量背景噪声,导致后续的基于此包围框进行2d到3d空间转换也存在较大误差,从而进一步影响行人空间位置及移动速度的估计。
技术实现要素:
4.为解决现有技术的不足,实现提高识别行人空间位置及行人移动速度的精度的目的,本发明采用如下的技术方案:一种基于立体相机的行人空间信息感知方法,包括如下步骤:步骤s1:获取立体相机实时图像数据,包括rgb图像数据和点云数据;步骤s2:通过rgb图像检测人体关键点,得到行人的二维关键点信息,根据行人动态特性确定行人上半身主干区域,结合行人上半身主干区域的二维关键点信息,生成行人包围框,将行人包围框作为行人检测框;对生成的行人包围框按比例进行扩展,将扩展的行人包围框作为行人检测框。由于生成的行人包围框为行人最小的包围框,考虑最小行人包围框仅仅只是行人骨架的最小包围框,需要对最小行人包围框进行扩展;扩展的行人包围框与最小行人包围框的面积比值为1.2;步骤s3:根据二维关键点相似度特征和行人检测框,对连续多帧图像下的行人进行多目标跟踪;步骤s4:对于持续跟踪到的行人,根据其二维关键点信息结合点云数据,获取行人三维关键点信息,计算当前帧下,行人相对于立体相机坐标系的空间位置坐标,并结合帧间隔计算行人移动速度,生成行人相对于立体相机的实时空间信息。
5.进一步地,所述步骤s2中,获取rgb图像数据,采用人体关键点检测网络进行前向推理,输出关键点热力图和部分关联域,根据关键点热力图和部分关联域提取二维关键点并进行分组,将属于同一行人的二维关键点匹配到当前行人上,得到当前图像中每个行人的二维关键点坐标。
6.进一步地,所述步骤s3包括如下步骤:
步骤s3.1:根据行人检测框,获取行人运动特征;根据二维关键点相似度特征,获取行人的外观特征;步骤s3.2:根据行人运动特征和行人的外观特征,得到当前t时刻下的行人实测状态信息;步骤s3.3:将历史轨迹与t时刻下的行人实测状态信息进行数据关联,得到t时刻下每个行人的id;数据关联的目的是将当前时刻的检测结果与历史轨迹通过外观、几何等特征进行匹配,以此确定当前帧检测出的每个人的id;步骤s3.4:通过t时刻下每个行人的id,更新历史轨迹,从而对行人进行持续跟踪。
7.进一步地,所述步骤s3.1中的二维关键点相似度特征,采用目标关键点相似性评价指标oks进行相似度计算,并通过预设阈值判断二维关键点是否关联。
8.进一步地,所述步骤s3.3中的数据关联,是对各帧进行运动特征和外观特征两种关联,进行线性加权,得到最终的关联矩阵,根据此关联矩阵采用匈牙利匹配算法得到各帧间行人匹配结果。
9.进一步地,所述步骤s4包括如下步骤:步骤s4.1:根据所述行人上半身主干区域,结合二维关键点置信度进行筛选,根据筛选后的二维关键点,获取点云数据,得到行人关键点的三维坐标集合;步骤s4.2:对于每一个行人目标,根据其关键点的三维坐标集合,计算三维坐标均值作为行人目标的空间位置坐标;并根据欧式距离计算行人相对于立体相机的实际距离,根据当前时刻的行人空间位置坐标及上一时刻的行人空间位置坐标,计算在当前时刻与上一时刻的时间间隔下,行人相对于立体相机的移动距离,再结合所用时间,得到当前时刻下的行人移动速度。
10.进一步地,所述步骤s4.2中行人移动速度公式如下:其中,x、y、z分别为行人的三维空间位置坐标,i表示当前跟踪到的行人id,t表示当前帧的时间,、、表示行人在当前帧下相对于立体相机的空间位置坐标,、、分别表示在时刻下相对立体相机的空间位置坐标,, m表示帧间隔数,f为立体相机帧率。
11.一种基于立体相机的行人空间信息感知装置,包括实时图像数据获取模块、行人检测框获取模块、多目标跟踪模块、实时空间信息生成模块;所述实时图像数据获取模块,通过立体相机获取rgb图像数据和点云数据;所述行人检测框获取模块,通过rgb图像检测人体关键点,得到行人的二维关键点信息,根据行人动态特性确定行人上半身主干区域,结合行人上半身主干区域的二维关键点信息,生成行人包围框,将行人包围框作为行人检测框;所述多目标跟踪模块,根据二维关键点相似度特征和行人检测框,对连续多帧图像下的行人进行多目标跟踪;所述实时空间信息生成模块,对于持续跟踪到的行人,根据其二维关键点信息结合点云数据,获取行人三维关键点信息,计算当前帧下,行人相对于立体相机坐标系的空间
位置坐标,并结合帧间隔计算行人移动速度,生成行人相对于立体相机的实时空间信息。
12.一种基于zed相机的行人空间信息感知方法,根据所述的基于立体相机的行人空间信息感知方法,采用设置在导览机器人上的zed双目视觉相机采集实时图像数据,并传输至云端服务器进行行人检测框获取、多目标跟踪和生成实时空间信息,其中对rgb图像进行预处理,包括调整图像尺寸resize及编码,以提高后续的数据传输效率,预处理后的数据通过消息中间件传输至云端服务器,zed双目视觉相机的视域范围与行人上半身主干区域配合设置,根据行人动态特性以及与导览机器人上zed双目视觉相机的视域范围,确定行人上半身主干区域,云端服务器将行人相对于zed双目视觉相机的实时空间信息传输至导览机器人,导览机器人根据所述实时空间信息进行本体的移动控制,完成导览任务。
13.一种基于zed相机的行人空间信息感知装置,包括云端服务器和设置在导览机器人上的zed双目视觉相机,所述云端服务器包括行人检测框获取模块、多目标跟踪模块、实时空间信息生成模块;所述zed双目视觉相机实时获取rgb图像数据和点云数据,并传输至云端服务器;所述行人检测框获取模块,通过rgb图像检测人体关键点,得到行人的二维关键点信息,根据行人动态特性确定行人上半身主干区域,结合行人上半身主干区域的二维关键点信息,生成行人包围框,将行人包围框作为行人检测框;其中zed双目视觉相机的视域范围与行人上半身主干区域配合设置,根据行人动态特性以及与导览机器人上zed双目视觉相机的视域范围,确定行人上半身主干区域;所述多目标跟踪模块,根据二维关键点相似度特征和行人检测框,对连续多帧图像下的行人进行多目标跟踪;所述实时空间信息生成模块,对于持续跟踪到的行人,根据其二维关键点信息结合点云数据,获取行人三维关键点信息,计算当前帧下,行人相对于立体相机坐标系的空间位置坐标,并结合帧间隔计算行人移动速度,生成行人相对于立体相机的实时空间信息;所述导览机器人,从云端服务器获取行人相对于zed双目视觉相机的实时空间信息,进行本体的移动控制,完成导览任务。
14.本发明的优势和有益效果在于:本发明采用无接触式的安装在导览机器人头部的zed双目视觉相机对场景内的行人进行智能感知;采用云端部署的轻量化人体关键点检测网络获取二维关键点信息,可以充分利用云端服务器强大的计算资源及存储资源从而有效的解决机器人本体算力不足的问题;考虑人体运动特性及导览机器人视域范围,确定人体上半身主干区域的关键点作为目标区域,此区域不包含手臂等变化较大的人体关键点,根据此区域生成的行人检测框更加稳定,与此区域的行人关键点三维坐标计算的行人空间位置及行人移动速度的精度也更高。
附图说明
15.图1是本发明的基于立体相机视觉的行人空间信息感知方法流程图。
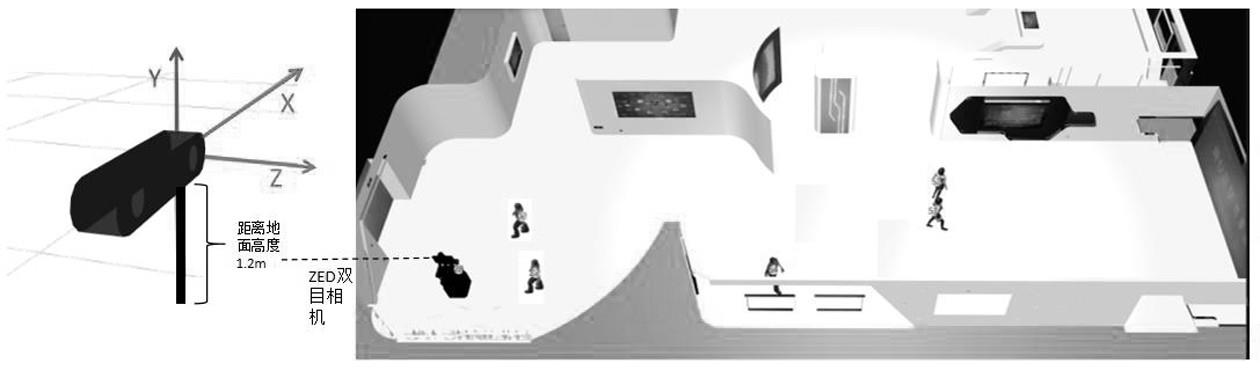
16.图2是本发明实施例中面向导览机器人的基于zed视觉的行人空间信息感知场景化应用示意图。
17.图3a是本发明实施例中人体关键点参数图。
18.图3b是本发明实施例中基于行人上半身二维关键点生成行人包围框的示意图。
19.图3c是本发明实施例中三维关键点示意图。
20.图4是本发明实施例中实测场景下基于zed视觉的行人空间信息感知的可视化流程图。
21.图5是本发明实施例中基于人体关键点与传统基于人体检测框的行人测距误差对比图。
22.图6是本发明的基于zed相机的行人空间信息感知方法流程图。
23.图7是本发明实施例中基于立体相机的行人空间信息感知设备的结构示意图。
具体实施方式
24.以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
25.如图1所示,基于立体相机视觉的行人空间信息感知方法,包括如下步骤:步骤s1:获取立体相机实时图像数据,包括rgb图像数据和点云数据;本发明实施例中,如图2所示,zed双目视觉相机安装于轮式机器人的头部,距离地面水平高度约1.2米。获取zed相机(左目)的rgb数据和点云数据,帧率为30hz,rgb彩色图像的分辨率为1280
×
720。对rgb图像进行预处理,包括resize及编码,以提高后续的数据传输效率,resize的尺寸为456
×
256,与后续人体关键点检测网络的输入相一致,预处理后的数据通过消息中间件传输至云端服务器。
26.步骤s2:通过rgb图像检测人体关键点,得到行人的二维关键点信息,根据行人动态特性确定行人上半身主干区域,结合行人上半身主干区域的二维关键点信息,生成行人包围框,将行人包围框作为行人检测框;获取rgb图像数据,采用人体关键点检测网络进行前向推理,输出关键点热力图和部分关联域,根据关键点热力图和部分关联域提取二维关键点并进行分组,将属于同一行人的二维关键点匹配到当前行人上,得到当前图像中每个行人的二维关键点坐标。
27.本发明实施例中,云端服务器接收来自机器人端采集的zed相机的实时数据,输入到部署好的人体关键点检测网络进行前向推理,人体关键点检测网络采用lightweight openpose,其主干网络采用的是改进后的moblienet,可满足实时性要求,通过此框架获取行人在图像中的二维关键点信息。网络的输入是解码后的rgb数据,大小为 [1,3,256,456],前向推理网络的输出分别为关键点热力图(heatmaps)和部分关联域(part affinity field, pafs),大小分别为[1, 19, 32, 57]、[1, 38, 32, 57],根据heatmaps和pafs提取所有关键点并进行分组,将属于同一个行人的关键点匹配到当前行人上,得到当前图像中每个行人的关键点坐标,假设当前图像检测的行人数为n,则输出为n
×
[18,3],其中18表示每个行人的关键点个数为18,3表示关键点在图像坐标系下的横轴x、纵轴y及置信度,置信度范围为0-1;由于行人具有姿态变化的特性,尤其是人体的四肢随着人的运动变换较大,并且当人距离机器人较近时,机器人的视域只能看到人体的上半部分,综合考虑这两个因素的影响,根据行人动态特性及导览机器人的视域范围,确定行人上半身主干区域为我们人体目标区域;此区域内包含的人体关键点为:{0:nose, 1:neck, 2:right_shoulder, 5:
left_shoulder, 8:rtght_hip, 11:left_hip, 14:right_eye, 15:left_eye, 16:right_ear, 17:left_ear},根据上述二维关键点生成行人包围框,如图3a中“人体关键点”所示;根据此区域的二维关键点,采用opencv的boundingrect函数生成最小包围框,如图3b中2d关键点示意图中的p1所示,用虚线表;考虑此包围框仅仅只是行人骨架的最小包围框,需要进行适当的扩充,扩充后的包围框如p2所示,用实线表示,p2与p1的面积比值为1.2,将此包围框作为后续的行人跟踪算法中的行人检测框。
[0028]
步骤s3:根据二维关键点相似度特征和行人检测框,对连续多帧图像下的行人进行多目标跟踪,包括如下步骤:步骤s3.1:根据行人检测框,获取行人运动特征;根据二维关键点相似度特征,获取行人的外观特征;二维关键点相似度特征,采用目标关键点相似性评价指标oks进行相似度计算,并通过预设阈值判断二维关键点是否关联;步骤s3.2:根据行人运动特征和行人的外观特征,得到当前t时刻下的行人实测状态信息;步骤s3.3:将历史轨迹与t时刻下的行人实测状态信息进行数据关联,得到t时刻下每个行人的id;数据关联是对各帧进行运动特征和外观特征两种关联,进行线性加权,得到最终的关联矩阵,根据此关联矩阵采用匈牙利匹配算法得到各帧间行人匹配结果;步骤s3.4:通过t时刻下每个行人的id,更新历史轨迹。
[0029]
本发明实施例中,对传输至云端的各帧rgb图像中的行人目标,我们通过多目标跟踪方法为其分配唯一的身份信息(id)来进行帧间持续跟踪。所述多目标行人跟踪方法采用deepsort算法原理。根据步骤s2中生成的行人检测框获取行人运动特征,根据二维关键点相似度特征获取行人的外观特征,采用oks(object keypoint similarity)进行相似度计算,并通过设置的阈值进行关联成功与否的判断,融合这两种特征信息可以获取当前t时刻下的行人实测状态信息;再将历史轨迹与t时刻的状态结果进行数据关联,结合运动特征和外观特征两种关联进行线性加权作为最终的关联矩阵,根据此关联矩阵采用匈牙利匹配算法得到匹配结果,即可得到t时刻每个行人目标的id,最后用t时刻的结果更新历史轨迹,从而获取行人的身份id。
[0030]
数据关联的目的是将当前时刻的检测结果与历史轨迹通过外观、几何等特征进行匹配,以此确定当前帧检测出的每个人的id,采用运动特征和外观特征两种关联进行线性加权作为最终的关联矩阵,根据此关联矩阵采用匈牙利匹配算法得到匹配结果。
[0031]
步骤s4:对于持续跟踪到的行人,根据其二维关键点信息结合点云数据,获取行人三维关键点信息,计算当前帧下,行人相对于立体相机坐标系的空间位置坐标,并结合帧间隔计算行人移动速度,生成行人相对于立体相机的实时空间信息,包括如下步骤:步骤s4.1:根据所述行人上半身主干区域,结合二维关键点置信度进行筛选,根据筛选后的二维关键点,获取点云数据,得到行人关键点的三维坐标集合;本发明实施例中,根据步骤2中所确定的行人上半身主干区域,结合关键点置信度进行筛选,置信度大于0.6的关键点参与接下来的计算,再根据获取的zed点云数据检索相应的三维关键点,获取相应的行人关键点的三维坐标集合;人体关键点检测网络输出行人在图像坐标系下的2d关键点坐标集合为)},
其中k为关键点个数,取值为k=0,1,2,5,8,11,14,15,16,17,为相应的置信度,如图3b中“2d关键点示意图”实心原点所示。结合zed相机采集的点云信息进行检索,我们根据行人主干区域并结合二维关键点置信度可以获取行人相应的三维坐标,行人所有二维关键点对应的三维坐标如图3c中“3d关键点示意图”所示,包含主干区域的人体关键点的三维坐标集合为)},如图3c中三角形图标所示,该坐标系是以zed相机左目摄像头为基准,通过相机参数coordinate_system.left_handed_y_up 进行设置,坐标系及xyz轴的方向如图2所示;步骤s4.2:对于每一个行人目标,根据其关键点的三维坐标集合,计算三维坐标均值作为行人目标的空间位置坐标;并根据欧式距离计算行人相对于立体相机的实际距离,根据当前时刻的行人空间位置坐标及上一时刻的行人空间位置坐标,计算在当前时刻与上一时刻的时间间隔下,行人相对于立体相机的移动距离,再结合所用时间,得到当前时刻下的行人移动速度;本发明实施例中,根据获取的行人人体关键点三维坐标集合,计算其均值作为该目标行人的空间三维坐标位置,即,其中n=10,表示每一个行人上半身区域的关键点的数量; i表示当前跟踪到的行人id,设当前帧的时间为t,则行人在当前帧下相对于机器人的空间位置为 ,在时刻相对机器人的空间位置为,则行人的移动速度为,其中,, f为zed相机帧率,m表示帧间隔数,综合考虑算法总耗时,m的取值为;如图4所示,zed相机获取rbg数据及点云数据,然后根据人体关键点检测算法获取的人体关键点二维坐标,最后结合二维关键点信息及相应的点云信息获取的人体关键点的三维坐标。为了验证本发明方法的有效性,采集了约1000帧图像,采用基于yolov3的人体检测框结合点云信息计算行人到相机的距离以及本发明的基于人体主干区域的关键点计算行人到相机的距离,分别进行了对比测试与统计,行人到相机的距离采用欧式距离公式进行计算:,其中(x,y,z)为行人的三维空间坐标,如图5所示,深色线表示本发明的方法,浅色线表示对比方法,可以看出,在行人运动过程中,基于人体检测框的方法会随着人体姿态的变化引入较大噪声,而我们的方法抗干扰性更好,能够获取更精准的行人定位信息。
[0032]
一种基于立体相机的行人空间信息感知装置,用于实现所述的基于立体相机的行人空间信息感知方法,包括实时图像数据获取模块、行人检测框获取模块、多目标跟踪模块、实时空间信息生成模块;所述实时图像数据获取模块,通过立体相机获取rgb图像数据和点云数据;所述行人检测框获取模块,通过rgb图像检测人体关键点,得到行人的二维关键点信息,根据行人动态特性确定行人上半身主干区域,结合行人上半身主干区域的二维关键
点信息,生成行人包围框,将行人包围框作为行人检测框;所述多目标跟踪模块,根据二维关键点相似度特征和行人检测框,对连续多帧图像下的行人进行多目标跟踪;所述实时空间信息生成模块,对于持续跟踪到的行人,根据其二维关键点信息结合点云数据,获取行人三维关键点信息,计算当前帧下,行人相对于立体相机坐标系的空间位置坐标,并结合帧间隔计算行人移动速度,生成行人相对于立体相机的实时空间信息。
[0033]
这部分内容实施方式与上述方法实施例的实施方式类似,此处不再赘述。
[0034]
如图6所示,一种基于zed相机的行人空间信息感知方法,根据所述的基于立体相机的行人空间信息感知方法,采用设置在导览机器人上的zed双目视觉相机采集实时图像数据,并传输至云端服务器进行行人检测框获取、多目标跟踪和生成实时空间信息,其中,zed双目视觉相机的视域范围与行人上半身主干区域配合设置,根据行人动态特性以及与导览机器人上zed双目视觉相机的视域范围,确定行人上半身主干区域,云端服务器将行人相对于zed双目视觉相机的实时空间信息传输至导览机器人,导览机器人根据所述实时空间信息进行本体的移动控制,完成自主跟随和避障等导览任务。
[0035]
具体地,包括如下步骤:步骤s101:获取导览机器人上的zed双目视觉相机实时图像数据,包括rgb图像数据和点云数据,并传输至云端服务器;步骤s102:云端服务器通过rgb图像检测人体关键点,得到行人的二维关键点信息,根据行人动态特性确定行人上半身主干区域,结合行人上半身主干区域的二维关键点信息,生成行人包围框,将行人包围框作为行人检测框;其中,zed双目视觉相机的视域范围与行人上半身主干区域配合设置,根据行人动态特性以及与导览机器人上zed双目视觉相机的视域范围,确定行人上半身主干区域;步骤s103:云端服务器根据二维关键点相似度特征和行人检测框,对连续多帧图像下的行人进行多目标跟踪;步骤s104:云端服务器对于持续跟踪到的行人,根据其二维关键点信息结合点云数据,获取行人三维关键点信息,计算当前帧下,行人相对于zed双目视觉相机坐标系的空间位置坐标,并结合帧间隔计算行人移动速度,生成行人相对于zed双目视觉相机的实时空间信息;步骤s105:云端服务器将行人相对于zed双目视觉相机的实时空间信息传输至导览机器人,导览机器人根据所述实时空间信息进行本体的移动控制,完成导览任务。
[0036]
本发明实施例中,云端将当前时刻的行人id、行人空间位置以及行人移动速度,存储于云端服务器的数据库中,以消息队列的方式进行存储,基本格式为data= {
‘
key1’:
ꢀ‘
value1’,
ꢀ‘
key2’:
ꢀ‘
value2’,
ꢀ‘
key3’:
ꢀ‘
value3’},其中key1、key2、key3分别为
‘
p_id’、
ꢀ‘
p_pos3d’、
ꢀ‘
p_speed’,表示行人id、行人三维空间坐标、行人移动速度,对应的value值即为计算出的具体的行人i的身份id、行人三维空间坐标和行移动速度。根据机器人端的请求指令,云端通过rocketmq消息中间件将数据实时发送到机器人端,机器人根据预先设定的指令进行本体移动控制,根据行人的实时位置信息进行自身移动速度的调整,并且当行人到机器人的距离小于安全距离时,机器人停止运动以免发生碰撞,并且根据行人的实时运动速度进行自身移动速度的调整,从而实现自主跟随及避障等智能导览任务。
[0037]
一种基于zed相机的行人空间信息感知装置,用于实现基于zed相机的行人空间信息感知方法,包括云端服务器和设置在导览机器人上的zed双目视觉相机,所述云端服务器包括行人检测框获取模块、多目标跟踪模块、实时空间信息生成模块;所述zed双目视觉相机实时获取rgb图像数据和点云数据,并传输至云端服务器;所述行人检测框获取模块,通过rgb图像检测人体关键点,得到行人的二维关键点信息,根据行人动态特性确定行人上半身主干区域,结合行人上半身主干区域的二维关键点信息,生成行人包围框,将行人包围框作为行人检测框;其中zed双目视觉相机的视域范围与行人上半身主干区域配合设置,根据行人动态特性以及与导览机器人上zed双目视觉相机的视域范围,确定行人上半身主干区域;所述多目标跟踪模块,根据二维关键点相似度特征和行人检测框,对连续多帧图像下的行人进行多目标跟踪;所述实时空间信息生成模块,对于持续跟踪到的行人,根据其二维关键点信息结合点云数据,获取行人三维关键点信息,计算当前帧下,行人相对于立体相机坐标系的空间位置坐标,并结合帧间隔计算行人移动速度,生成行人相对于立体相机的实时空间信息;所述导览机器人,从云端服务器获取行人相对于zed双目视觉相机的实时空间信息,进行本体的移动控制,完成导览任务。
[0038]
这部分内容实施方式与上述方法实施例的实施方式类似,此处不再赘述。
[0039]
与前述基于立体相机视觉的行人空间信息感知方法的实施例相对应,本发明还提供了基于立体相机视觉的行人空间信息感知设备的实施例。
[0040]
参见图7,本发明实施例提供的基于立体相机视觉的行人空间信息感知设备,包括存储器和一个或多个处理器,存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现上述实施例中的基于立体相机视觉的行人空间信息感知方法。
[0041]
本发明基于立体相机视觉的行人空间信息感知设备的实施例可以应用在任意具备数据处理能力的设备上,该任意具备数据处理能力的设备可以为诸如计算机等设备或装置。装置实施例可以通过软件实现,也可以通过硬件或者软硬件结合的方式实现。以软件实现为例,作为一个逻辑意义上的装置,是通过其所在任意具备数据处理能力的设备的处理器将非易失性存储器中对应的计算机程序指令读取到内存中运行形成的。从硬件层面而言,如图7所示,为本发明基于立体相机视觉的行人空间信息感知设备所在任意具备数据处理能力的设备的一种硬件结构图,除了图7所示的处理器、内存、网络接口、以及非易失性存储器之外,实施例中装置所在的任意具备数据处理能力的设备通常根据该任意具备数据处理能力的设备的实际功能,还可以包括其他硬件,对此不再赘述。
[0042]
上述装置中各个单元的功能和作用的实现过程具体详见上述方法中对应步骤的实现过程,在此不再赘述。
[0043]
对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本发明方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
[0044]
本发明实施例还提供一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述实施例中的基于立体相机视觉的行人空间信息感知方法。
[0045]
所述计算机可读存储介质可以是前述任一实施例所述的任意具备数据处理能力的设备的内部存储单元,例如硬盘或内存。所述计算机可读存储介质也可以是任意具备数据处理能力的设备的外部存储设备,例如所述设备上配备的插接式硬盘、智能存储卡(smart media card,smc)、sd卡、闪存卡(flash card)等。进一步的,所述计算机可读存储介质还可以既包括任意具备数据处理能力的设备的内部存储单元也包括外部存储设备。所述计算机可读存储介质用于存储所述计算机程序以及所述任意具备数据处理能力的设备所需的其他程序和数据,还可以用于暂时地存储已经输出或者将要输出的数据。
[0046]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。