技术特征:
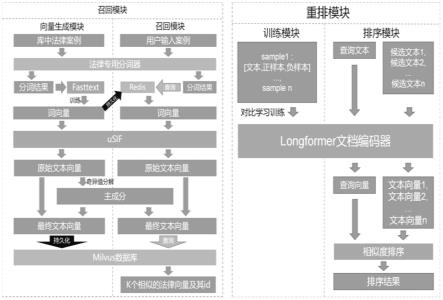
1.一种基于深度学习的文献检索系统,包括:召回模块:用于针对用户输入的查询文本,基于预存储的词向量和文本向量,生成多个候选文本;重排模块:用于将用户输入的查询文本和所述多个候选文本输入到经训练的长文本编码器,获得查询向量以及候选文本向量,并计算查询向量与候选文本向量之间的相似度,获得排序的检索结果。2.根据权利要求1所述的系统,其特征在于,所述召回模块根据以下步骤生成所述多个候选文本:针对用户输入的查询文本,使用法律领域专用分词器进行分词,并在预存储的第一数据库中查找每个分词所对应的词向量,输入到usif算法中得到查询文本原始向量;从查询文本原始向量中减去预存储的主成分,得到最终查询文本向量;利用预存储的第二数据库检索出与所述最终查询文本向量在语义上最相似的k个向量及其对应的文本标识,作为召回的所述多个候选文本,其中k是设定的整数。3.根据权利要求2所述的系统,其特征在于,第一数据库和第二数据库根据以下步骤获得:随机抽取已有的案例数据,使用法律领域专用分词器进行分词,并将分词的文本输入到文本分类器训练词向量,将训练的词向量存入第一数据库中进行持久化操作;对于选定的全部案例数据,使用法律领域专用分词器进行分词后在第一数据库中获取每个词的向量,组成词向量矩阵输入到usif算法生成样本案例的原始文本向量,并对样本案例的原始文本向量进行奇异值分解得到设定数目的多个主成分,将所述样本案例的原始文本向量减去所述多个主成分,得到样本案例的最终文本向量,并将该样本案例的最终文本向量存入到第二数据库中进行持久化操作。4.根据权利要求1所述的系统,其特征在于,所述长文本编码器的训练过程包括:从案例样本标注数据集中构造训练数据,对于一个查询文本,将与其相关的案例作为正样本而不相关案例作为负样本,进而将每条查询文本与其正负样本构成一个三元组对于一批训练数据,x
i
的正样本仅为而负样本除外还包含其他文本的正负样本,每条查询文本通过长文本编码器编码后,经平均池化层得向量表示,经余弦相似度计算构建相似度矩阵,矩阵每一行代表x
i
与同批训练数据的所有和的相似度得分;以设定的损失函数为优化目标进行训练。5.根据权利要求4所述的系统,其特征在于,所述损失函数设置为:其中,表示第i个文本产生的损失;e是自然常数;sim()是余弦相似度函数;h
i
是x
i
的向量表示,是的向量表示,是的向量表示,τ表示温度超参数。6.根据权利要求3所述的系统,其特征在于,第一数据库是redis数据库,第二数据库是milvus向量数据库,所述文本分类器是fasttext文本分类器。
7.根据权利要求1所述的系统,其特征在于,所述查询向量与所述候选文本向量之间的相似度基于余弦相似度计算。8.根据权利要求1所述的系统,其特征在于,所述召回模块根据以下方式将文本转化为文本向量:对于得到的词向量序列,结合领域内词汇的平滑逆频率对词向量进行加权,生成原始文本向量,其中所述领域内词汇的平滑倒频率反映词语在领域文献中的出现次数。9.一种基于深度学习的文献检索方法,包括以下步骤:针对用户输入的查询文本,基于预存储的词向量和文本向量,生成多个候选文本;将用户输入的查询文本和所述多个候选文本输入到经训练的长文本编码器,获得查询向量以及候选文本向量,并计算查询向量与候选文本向量之间的相似度,获得排序的检索结果。10.一种计算机可读存储介质,其上存储有计算机程序,其中,该计算机程序被处理器执行时实现根据权利要求9所述的方法的步骤。
技术总结
本发明公开了一种基于深度学习的文献检索方法和系统。该系统包括:召回模块,其用于针对用户输入的查询文本,基于预存储的词向量和文本向量,生成多个候选文本;重排模块,其用于将用户输入的查询文本和所述多个候选文本输入到经训练的长文本编码器,获得查询向量以及候选文本向量,并计算查询向量与候选文本向量之间的相似度,获得排序的检索结果。本发明有效解决了文本检索中无监督模型排序效果不理想、有监督文本检索模型无法在大量文书中直接检索的问题,显著提升了检索速度和准确度,尤其适用于涉及以长文本检索长文本的领域。其适用于涉及以长文本检索长文本的领域。其适用于涉及以长文本检索长文本的领域。
技术研发人员:温嘉宝 杨敏 贺倩明
受保护的技术使用者:深圳得理科技有限公司
技术研发日:2022.09.26
技术公布日:2022/12/19
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。