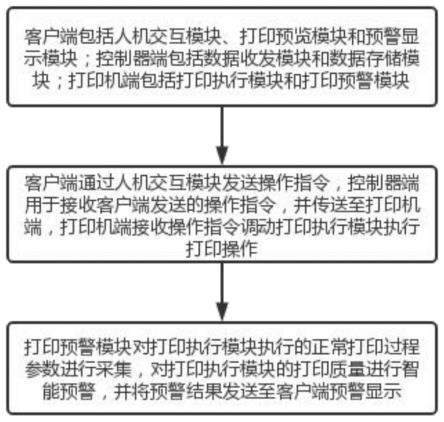
1.本发明涉及立体视频转制领域,特别涉及一种基于神经辐射场的立体视频视差控制与编辑方法。
背景技术:
2.3d立体显示技术发展至今已经有非常长的时间,随着立体显示设备的普及和发展,立体内容的需求不断攀升,而立体转制是3d内容生成的重要手段之一。
3.现有的立体转制方法可以分为手动转制、传统转制和基于学习的转制三种。其中,手动转制的可操控性最强,但该流程需要的耗费大量时间与人力,同时对操作的艺术家有一定经验要求。传统立体转制需要从图像线索中提取深度,或人为绘制深度图,存在深度图估计不准确的问题。基于深度学习的方法是目前的研究热点,具体可分为双阶段法与单阶段法。双阶段法需要单目深度估计与缺失像素补绘两个阶段,训练步骤繁琐,且转制依赖于从单目视频中估计的深度图,难以实现精准的视差控制;而图像补绘阶段还不能很好地利用3d信息,使其合成纹理不能够符合真实物理规律,在构建立体效果时,会因为左右视图存在差异而产生3d眩晕等视疲劳现象。单阶段自动立体转制是立体转制最理想的解决方案,但其过程中的可操控性不足,且获取大量3d影片数据的难度较大,限制了该研究的进一步发展。
4.视差控制存在以下三个挑战,一是视差计算不精确,为了能够控制视差匹配不同的显示器尺寸与观看距离,以应对3d显示设备多样性,视差自适应控制问题迫切需要解决,这需要立体转制流程具备较强的视差精准控制能力。二是视疲劳现象,转制电影在舒适度方面常为人所诟病,为了减少视觉疲劳,需要在视差控制中添加舒适区范围约束。三是局部视差编辑,为了迎合艺术效果,转制方法应能够具备局部视差编辑的能力,例如显著对象带来的强烈立体冲击感,生成效果上舒适而非物理上正确的立体视频。直接对深度图处理来实现深度控制的方法,通常会产生对象形变和孔洞的现象,一类方法在扭曲过程中通过添加多种约束保持所选对象结构,但该类方法依赖于深度图。
技术实现要素:
5.本发明针对以上问题,提出了一种基于神经辐射场的立体视频视差控制与编辑方法,充分利用了神经辐射场的属性可编辑特性,实现了视差可精准控制的高质量视角合成;同时该方法能够根据观看条件和场景属性,自适应地生成具有高视觉舒适度的立体视频;最后,该方法还实现了局部视差的重新编辑,能够获得更优的局部视差艺术效果。
6.该方法将输入视频视为左视图,首先利用输入视频的连续多帧视图构建动态神经辐射场,同时根据观看条件计算自适应视差,从而控制神经辐射场中虚拟相机渲染指定新视角,经过体积渲染得到右视图渲染结果。为了能够适应视频视差编辑的需求,该方法采用分层立体渲染的方式,实现了神经辐射场中指定对象的分离,进而实现了对视频局部对象的视差控制。
7.为达到上述目的,本发明采用如下技术方案:
8.一种基于神经辐射场的立体视频视差控制与编辑方法,操作步骤如下:
9.步骤1:利用输入视图的序列帧,构建4d时空动态神经辐射场,对场景中的静动态对象分别处理后合成;
10.步骤2:在步骤1构建的4d神经辐射场中,自适应精准控制视差,通过立体渲染生成新视图;
11.步骤3:在步骤1构建的4d神经辐射场中,分离局部对象并修改该对象视差,经过立体渲染后实现局部视差编辑后的新视图。
12.进一步地,所述步骤1的具体操作步骤如下:
13.1-1:对于视频中每一帧图像将屏蔽运动区域的静态部分的3d位置坐标与观察方向作为输入,经过两个级联的多层感知机mlp预测,得到一个在三维空间中颜色与密度均连续的场态作为该场景的隐式表达;对连续场态分为等距的多个层取值,在给定的相机模型下计算来自每个像素位置的模拟光线,并在该场态模拟光线跟踪,与分层辐射场的交点经过数值积分方式得到渲染图中的像素颜色值与累积透明度,从而得到当前帧k的重建颜色值,渲染得到该视点下的新颖视图;
14.1-2:在对静态场景训练时通过最小化当前帧每个像素的重建颜色值与真实值之间的差异不断优化结果,得到mlp的最终权重;
15.1-3:在表达动态场景时,采用了双向场景流计算每个像素位置在当前时刻的前后时刻的偏移量,用于表示时域上场景的扭曲程度,从而利用包含当前帧及其前后时刻图像在内的3个视角共同训练模型;同时还利用模型预测当前时刻的混合权重,用于表示动静态场景在某一像素位置的组合权重分配。
16.进一步地,所述步骤2的具体操作步骤如下:
17.2-1:首先基于视觉显著性确定需要调整视差的对象,并为其添加蒙版;
18.2-2:继而在神经辐射场中指定深度间距进行分层渲染,并在计算累积颜色与透明度的同时对深度值逐层积分,当显著蒙版内深度不断累加趋于稳定时,则认为该渲染层所在深度为最佳零视差平面所在深度;
19.2-3:得到零视差平面的深度值后,基于离轴平行式模型能够进一步确定光轴平移程度和相机基线a的关系函数;
20.2-4:基于shibata舒适区理论,根据当前视距、瞳距与屏幕分辨率等观看条件,通过控制正负视差最大值在合理范围,进一步确定具体相机基线与镜头平移量,实现自适应的视差控制模型。
21.进一步地,所述步骤3的具体操作步骤如下:
22.3-1:对场景内容进行分析,根据观看者的视觉注意点为局部对象添加蒙版,根据该蒙版确定了目标在图像中的2d边界盒;
23.3-2:在分层神经辐射场中对深度值累计积分,当蒙版区域内深度值开始累积时与区域稳定并达到阈值时,认为该层所在深度为局部编辑对象的3d包围盒的近远深度,由此确定目标对象的3d包围盒,实现神经辐射场中的局部对象提取;
24.3-3:在体积渲染阶段,对全场景进行光线追踪时,对包围盒内部光线沿着水平方向扭曲,从而实现对局部对象与剔除局部对象的背景分别进行视差控制,局部对象水平视
差放大或缩小的效果,从而强化场景中显著对象的立体感。
25.本发明与现有技术相比较,具有如下显著的特点与优势:
26.1、本发明提出了一种新颖的自动立体转制方法,首次将神经辐射场技术用于完整的立体转制,能够生成具有可操控性的高质量立体视频;
27.2、本发明提出了一种自适应视差控制的方法,能够根据观看条件和场景属性精准控制视频中视差的大小与正负视差的比例,生成具有高视觉舒适度的立体视频;
28.3、本发明提出了一种基于神经辐射场的局部视差编辑的方法,能够在神经辐射场中对局部目标进行分离,并在立体渲染中实现了局部视差放大或缩小的艺术效果。
附图说明
29.图1为本发明的整体框架流程图。
30.图2为4d时空动态神经辐射场网络架构。
31.图3为离轴平行式模型视差控制方法示意图。
32.图4为局部视差编辑流程图。
33.图5为本发明与先进的3种立体转制方法及一种真实值的转制效果对比。
34.图6为不同零视差平面深度值下的角度视差图。
35.图7为多个场景在不同零视差平面模型下的视疲劳指标。
36.图8为不同观看条件下自适应最优视差的红青立体效果图。
37.图9为局部视差编辑前后的效果图。
具体实施方式
38.下面结合附图,对本发明的具体实施例做进一步的说明。
39.如图1所示,一种基于神经辐射场的立体视频视差控制与编辑方法,操作步骤如下:
40.步骤1:利用输入视图的序列帧,构建4d时空动态神经辐射场,对场景中的静动态对象分别处理后合成,如图2所示;
41.1-1:对于视频中每一帧图像将屏蔽运动区域的静态部分的3d位置坐标γ(x,y,z)与观察方向υ(φ,θ)作为输入,经过两个级联的多层感知机(mlp)预测,得到一个在三维空间中颜色与密度均连续的场态作为该场景的隐式表达。进而对连续场态分为等距的m层取值,在给定的相机模型下计算来自每个像素位置(i,j)的模拟光线,并在该场态模拟光线跟踪,与分层辐射场的交点经过数值积分方式得到渲染图中的像素颜色值与累积透明度t
p
,从而得到当前帧k的重建颜色值渲染得到该视点下的新颖视图;
[0042][0043][0044]
其中,表示由一组参数θ定义的静态多层感知机;γ表示3d位置坐标;v表示观察方向;c表示rgb颜色值;σ表示体积密度;对于视频中的每一帧图像k∈(0,...,n-1),
表示重构的rgba颜色,δ
p
表示相邻样本之间的距离;
[0045]
1-2:在对静态场景训练时通过最小化当前帧每个像素的重建颜色值与真实值之间的差异不断优化结果,得到mlp的最终权重;
[0046]
1-3:在表达动态场景时,采用了双向场景流计算每个像素位置在当前时刻的前后时刻的偏移量,用于表示时域上场景的扭曲程度,从而利用包含当前帧及其前后时刻图像在内的3个视角共同训练模型。同时还模型预测当前时刻的混合权重,用于表示动静态场景在某一像素位置的组合权重分配。
[0047]
步骤2:在步骤1构建的4d神经辐射场中,自适应精准控制视差,通过立体渲染生成新视图,如图3所示;
[0048]
2-1:基于视觉显著性的最佳零视差平面计算:本发明中定义了最佳零视差平面深度为前后景深度的交界值,因为该深度能够区分前后景,从而使前景产生具有出屏感的负视差效果,背景产生具有延伸感的正视差效果。首先基于视觉显著性确定需要调整视差的对象,并为其添加蒙版。
[0049]
2-2:继而在神经辐射场中指定深度间距进行分层渲染,并在计算累积颜色与透明度的同时对深度值逐层积分。当显著蒙版内深度不断累加趋于稳定时,则认为该渲染层所在深度为最佳零视差平面所在深度.
[0050]
2-3:得到零视差平面的深度值后,能够进一步确定光轴平移程度δl和相机基线a的关系函数如(3)所示。基于离轴平行式模型,根据得到的零视差平面,能够获得相机基线a与镜头平移量δl的关系表达,其中z为图3所示的场景最大深度,z
zero
为零视差平面深度;
[0051]
(z-z
zero
)a-2z
zero
δl=0
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0052]
2-4:基于如(4)所示的shibata舒适区理论,根据当前视距、瞳距与屏幕分辨率等观看条件,通过控制正负视差最大值在合理范围,进一步确定具体相机基线a与镜头平移量δl如(5)所示,实现自适应的视差控制模型,其中z
near
为图3所示的场景最小深度。该步骤能够在获得最佳立体感的同时,具备更高的视觉舒适度;
[0053][0054][0055]
其中,d
near
表示舒适区近平面深度;d
far
表示舒适区远平面深度;di表示眼睛到屏幕的距离;e表示瞳孔间距;shibata舒适区理论用函数定义了观看距离与汇聚距离之间的关系,并通过大量实验得到了舒适区远近边界的估计值,用参数t
near
,m
near
,t
far
,m
far
表示;m近似表示显像时像素的等比缩放;
[0056]
步骤3:在步骤1构建的4d神经辐射场中,分离局部对象并修改该对象视差,经过立体渲染后实现局部视差编辑后的新视图,如图4所示。
[0057]
3-1:对场景内容进行分析,根据观看者的视觉注意点为局部对象添加蒙版,根据该蒙版确定了目标在图像中的2d边界盒;
[0058]
3-2:在分层神经辐射场中对深度值累计积分,当蒙版区域内深度值开始累积时与区域稳定并达到阈值时,认为该层所在深度为局部编辑对象的3d包围盒的近远深度,由此
可以确定目标对象的3d包围盒,实现神经辐射场中的局部对象提取;
[0059]
3-3:在体积渲染阶段,对全场景进行光线追踪时,对包围盒内部光线沿着水平方向扭曲,从而实现对局部对象与剔除局部对象的背景分别进行视差控制,局部对象水平视差放大或缩小的效果,从而强化场景中显著对象的立体感。
[0060]
从网络上下获取了10段立体视频,包括左右格式的3d电影,或者由专业剪辑师手动转制的左右格式3d视频,从每个电影或视频中选取2~3s的视频片段,将其左视角视频作为立体转制的对象场景,通过算法生成其右视角视频,最终效果可以通过htc vive在vr环境下观看,或处理成红青立体效果演示。实施例中设定了观看条件为23英寸的led桌面显示器作为显示,并设置视距为1m。附图中展示的该发明生成的红绿立体图均以此观看条件为前提。实施例中预先使用了colmap预测相机姿态,并使用python编程语言pytorch1.6.0和cuda10.0测试代码。所有实验均在配备inter(r)xeon(r)e5-2620 cpu、2.10ghz处理器、64gb ram和nvidia titan xp gpu的机器上完成。以下从自适应视差控制与局部视差编辑两个方面,对本发明的优选实施例进行详细的说明。
[0061]
实施例1
[0062]
基于神经辐射场的自适应视差控制方法,具体包含以下操作步骤:
[0063]
步骤一:输入解帧的2d视频到如图2所示的神经辐射场网络结构,利用具有时间相关性的动态神经辐射场对输入视频进行场景的隐式表达;
[0064]
步骤二:添加瞳距、视距的约束条件,在隐式场态中构建虚拟相机模型,根据视差舒适区与立体感的约束,实现自适应视差的计算和控制;
[0065]
步骤三:经过立体渲染合成得到高质量新颖视图,输出左右格式3d序列帧,或红青格式3d序列帧,以便于在vr眼镜或红绿眼镜下观看。
[0066]
结合附图,对实施例1的结果进行进一步分析:
[0067]
1、图5展示了该发明相比于现有先进方法生成结果在图像质量的细节上的进步。先前的方法在出现了一些显著问题,例如像素的抖动和扭曲、仅利用了前景像素补绘后景孔洞而导致的模糊与伪影、孔洞区域的颜色值预测错误等。相比之下,本发明利用了nerf强大的深度还原能力,同时能够充分利用连续帧信息,更准确地还原被遮挡区域场景。在这几种对比方法中,生成的结果更接近真实值。
[0068]
2、图6、图7展示了该发明的自适应视差在视觉舒适度上的优势。图6是由视差图恢复成的角度视差图,其中z0为该发明中自适应计算零视差平面深度的角度视差图。该方法将显著图体现的图像视觉注意力区域作为权值,用角度视差值来计算视疲劳指标,并将结果展示在图7中,可以看出利用我们的方法得到的零视差平面构建的视差控制模型,相较于邻近深度的零视差平面的视疲劳指标更低,印证了该方法能够获得较优的视觉舒适度。
[0069]
3、图8展示了4个电影片段在不同瞳距与视距下自适应生成的视差不同的红青立体图。实际的视差值随着瞳距dp与视距dv的增大而增大,表现了观看距离与瞳距对视差结果的影响作用。同时abc点表现出不同的视差类型(正视差、零视差和负视差),也证明了我们的流程能够很好地利用零视差平面分割出前景与背景,并同时体现出视觉舒适的正负视差。
[0070]
实施例2
[0071]
基于神经辐射场的局部视差重编辑方法,是对实施例1中的补充操作,其中具体包
含以下操作步骤:
[0072]
步骤一、二:同实施例1;
[0073]
步骤三:利用显著区域分析算法得到图像的视觉注意力区域作为蒙版,根据该蒙版确定了目标在图像中的2d边界盒;该发明在分层神经辐射场中对深度值累计积分,进一步确定该显著对象的3d包围盒,从而实现神经辐射场中的局部对象提取;
[0074]
步骤四:追加输入局部视差偏移量,在立体渲染阶段,算法在对隐式场态模拟光线跟踪的过程中,对3d包围盒内部光线沿着水平方向扭曲一个偏移值,从而实现局部对象水平视差放大或缩小的效果。利用扭曲后的光线追踪路径进行立体渲染,输出左右格式3d序列帧,或红青格式3d序列帧,以便于在vr眼镜或红绿眼镜下观看。
[0075]
结合附图,对实施例2的结果进行进一步分析:
[0076]
图9展示了该电影片段按照艺术家的指导对显着区域进行视差放大前后的效果。相比于在后期制作的软件中进行,该发明节省了大量人工抠图分层的成本。而且通过深度得到的前景具有比较高的质量,也能为于后期制作人员的roto操作提供判断依据和辅助作用。
[0077]
上述实施例基于神经辐射场的立体视频视差控制与编辑方法。首先,引入具有时域双向流的神经辐射场,生成新视角的动态视频场。其次,能够根据观看条件与视频场景特性,自适应精准计算理想视差,生成立体效果显著且视觉舒适的立体视频。最后,在基于神经辐射场的立体渲染过程中实现了对单个对象视差的重编辑。与现有技术对比,在图像重建质量指标上该方法获得了综合性能最高。同时,该框架获得了较低的视疲劳指数,和包含有正负两种视差的立体感。上述实施例实验采集了10位非专业观众和10位专业影视工作者对该方法的结果的反馈,分别从立体感、舒适度和局部视差编辑效果三个角度,证明了我们的框架在3d电影制作中优化视觉体验和艺术性表达的价值。
[0078]
上面对本发明实施例结合附图进行了说明,但本发明不限于上述实施例,还可以根据本发明的发明创造的目的做出多种变化,凡依据本发明技术方案的精神实质和原理下做的改变、修饰、替代、组合或简化,均应为等效的置换方式,只要符合本发明的发明目的,只要不背离本发明的技术原理和发明构思,都属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。