技术特征:
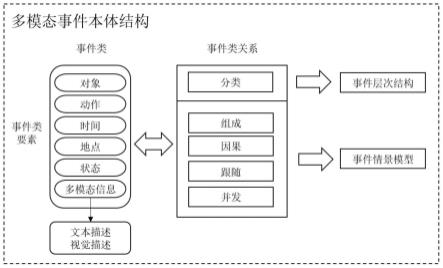
1.一种多模态事件本体半自动构建方法,其特征在于,包括以下步骤:s1:基于现有的事件本体构建流程和文本事件信息自动抽取技术,提出半自动构建多模态事件本体的方法;s2:面向事件本体视觉模态融合的图像场景分类以及目标检测;s3:图像要素相关性评估以及代表性选取;s4:事件类多模态信息补充与归纳。2.根据权利要求1所述的多模态事件本体半自动构建方法,其特征在于,所述基于现有的事件本体构建流程和文本事件信息自动抽取技术,提出半自动构建多模态事件本体的方法具体包括:s101:确定事件本体的领域和范畴,根据领域特点采集领域文本数据;s102:复用现有事件本体模式,利用事件本体模式快速生成领域内事件类和事件关系,作为领域事件本体构建的候选事件类和事件关系,如没有可复用的本体模式,则进入第三步;s103:通过对文本分词后,利用现有的基于注意力机制和bi-gru的事件触发词抽取模型抽取出事件的类型,再利用现有的基于bert和注意力机制的事件元素抽取模型抽取出事件要素,再采用bi-lstm对两个事件的信息进行编码并分类,实现事件关系抽取,最终获得候选事件类和事件关系;s104:由领域专家对步骤s102和s103获得的事件和事件关系进行人工筛选和补充,获得领域核心事件类和事件关系;s105:按照事件六元组模型,结合s102获得的事件要素,定义核心事件类的主要要素,如事件类的动作、对象、时间、地点、前置状态和后置状态等;s106:通过定义候选事件类之间的层次关系,形成领域事件类层次结构,领域专家根据领域常识对事件类层次进行上下位扩充,最终形成较完整的领域事件类层次模型;s107:基于步骤s104获得的领域事件类和事件关系,基于领域常识针对领域核心事件类构建其事件情景模型,事件情景模型由事件类和事件逻辑关系构成,如组成、因果、跟随、并发等;s108:根据事件文本数据的来源采集图片,并根据事件及其要素制定多关键字搜索图片,关键字由事件名、对象、地点、动作组成,以空格分隔,最终将图片集l={p1,p2,
…
,p
n
}补充到事件的多模态信息中,等待后续融合。3.根据权利要求2所述的多模态事件本体半自动构建方法,其特征在于,所述采用bi-lstm对两个事件的信息进行编码并分类,实现事件关系抽取,具体表示如下:将事件信息输入bi-lstm进行编码,具体表示为:bi-lstm(x)=x
c
={x0,x1,
…
x
n
}其中x表示输入字向量,可以通过word2vec预训练模型向量化,x
c
表示模型输出的具有上下文信息的中间向量,最后经过输出维度为4的全连接层和以softmax作为激活函数的输出层,得到分类结果,具体表示为:
其中,w为待学习的权重矩阵,b为偏置项,为softmax输出的概率,分别表示组成、因果、跟随和并发关系的分类概率。4.根据权利要求1所述的多模态事件本体半自动构建方法,其特征在于,所述面向事件本体视觉模态融合的图像场景分类以及目标检测,具体包括:s201:采用现有的在places365数据集预训练的vgg16-places365模型,对事件的每张图片做场景识别标注,取分数前n的场景标签p
sce
={s1,s2,
…
,s
n
},补充到事件中的多模态信息中;s202:采用现有的yolov5模型,对事件的每张图片做目标检测标注,得到n个实体标签p
obj
={o1,o2,
…
,o
n
},补充到事件的多模态信息中。5.根据权利要求1所述的多模态事件本体半自动构建方法,其特征在于,所述图像要素相关性评估以及代表性评估,具体包括:s301:对于每个事件类的所有事件,采用词向量预训练模型计算事件中每张图片的n个场景标签和所属事件类地点要素的向量表示,计算n个场景标签和事件地点要素的余弦相似度取相似度平均值作为该张图片的图像场景要素匹配度score1,补充到事件的多模态信息中;s302:对于每个事件类的所有事件,采用词向量预训练模型计算事件中每张图片的n个图片实体标签和所属事件类对象要素的向量表示,计算事件类对象要素中每个对象与n个图片实体标签的余弦相似度取相似度平均值作为该对象的匹配度,最终取事件对象要素中所有对象的匹配度平均分,作为该张图片的图像对象要素匹配度score2,补充到事件的多模态信息中;s303:结合图像场景要素匹配度score1和图像对象要素匹配度score2,计算图片的综合要素匹配度score,从每个事件类的所有事件中取分数前m的图片作为事件类的候选图片集l={p1,p2,
…
,p
m
},将图片的综合要素匹配度和候选图像集补充到事件的多模态信息中;s304:采用代表性图像选取技术筛选候选图片集中的代表性图片。6.根据权利要求5所述的多模态事件本体半自动构建方法,其特征在于,所述计算n个场景标签和事件地点要素的余弦相似度,取相似度平均值作为该张图片的图像场景要素匹配度,具体满足以下公式:配度,具体满足以下公式:其中,p
i
表示第i个场景标签的嵌入表示,a表示事件地点要素的嵌入表示,表示第i个场景标签与事件地点要素的相似度,n表示场景标签的个数,score1表示图像场景要素匹配度。7.根据权利要求6所述的多模态事件本体半自动构建方法,其特征在于,所述计算事件
对象要素中每个对象与n个图片实体标签的余弦相似度,取相似度平均值作为该对象的匹配度,最终取事件对象要素中所有对象的匹配度平均分,作为该张图片的图像对象要素匹配度,具体满足以下公式:配度,具体满足以下公式:其中,o
i
表示第i个图片实体标签的嵌入表示,b
j
表示事件对象要素中第j个对象的嵌入表示,表示第i个图片实体标签与事件对象要素中第j个对象的相似度,m表示事件对象要素中对象的个数,n表示图片实体标签的个数,score2表示图像实体要素匹配度。8.根据权利要求5所述的多模态事件本体半自动构建方法,其特征在于,所述结合图像场景要素匹配度和图像对象要素匹配度,计算图片的综合要素匹配度,取分数前m的图片作为候选图片集,具体满足以下公式:score=α
×
score1 β
×
score2(α β=1)其中,α表示图片场景要素匹配度的权重,β表示图片实体要素匹配度的权重。9.根据权利要求5所述的多模态事件本体半自动构建方法,其特征在于,所述采用代表性图像选取技术筛选候选图片集中的代表性图片,具体包括:对于事件类中候选图像集中的每张图像,提取图像的sift特征t
i
,采用余弦相似度计算图像间的相似度,得到图像相似度特征矩阵h
n
×
n
;基于特征矩阵使用ap算法进行图像聚类;计算每个簇的视觉特征重合率v
j
=match_avg(p
j
),其中match_avg(
·
)表示计算簇内图像之间的sift特征匹配点数的平均值,p
j
表示第j个簇的图像特征集合;最后从排名第一的簇的聚类中心作为代表性图像p
rep
。10.根据权利要求1所述的多模态事件本体半自动构建方法,其特征在于,所述事件类多模态信息补充与归纳,具体包括:将候选图片集,代表性图片、图片实体集合、图片场景标签、图片场景匹配度、图片实体匹配度、图片综合匹配度补充到事件类的多模态信息要素的视觉描述中,即m
visual
={l,p
rep
,p
obj
,p
sce
,score1,score2,score}。
技术总结
本发明涉及技术领域,具体为一种多模态事件本体半自动构建方法,包括以下步骤,S1:基于现有的事件本体构建流程和文本事件信息自动抽取技术,提出半自动构建多模态事件本体的方法;S2:面向事件本体视觉模态融合的图像场景分类以及目标检测;S3:图像要素相关性评估以及代表性选取;S4:事件类多模态信息补充与归纳。本发明中,在现有事件本体构建方法的基础上加以改进,结合事件信息抽取技术形成事件本体半自动构建技术,进一步融合视觉描述信息,提高本体中多模态的表达能力,解决单模态事件本体表达能力不足的问题,通过提出图片场景要素匹配度和图片实体要素匹配度来提高图片与事件要素的相似性。事件要素的相似性。事件要素的相似性。
技术研发人员:刘炜 闫科宇 彭艳 谢少荣 徐辉 李卫民
受保护的技术使用者:上海大学
技术研发日:2022.09.20
技术公布日:2022/12/16
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。