1.本发明涉及文字识别技术领域,特别涉及一种通用场景文字识别数据的自动生成方法及系统。
背景技术:
2.随着人工智能技术不断发展的今天,ocr识别在银行、物流以及无人驾驶等众多领域场景中被广泛应用。文字识别方法主要包括:基于字符切分再进行字符分类完成识别、基于 attention的字符对齐识别、基于ctc的概率最大路径识别方法,以及基于transformer的multi-head-attention编解码识别方法,但是由于ctc更快的训练、预测速度,在长短文本、尤其是中文识别上有较优的表现被工业界广泛使用。目前公开的学术论文暂无基于ctc的字符定位方法,但是字符的位置在合同比对、图片质检等问题中十分重要。
3.基于深度学习的文字识别方法依赖大量的数据训练,然而在真实的开发场景中往往很难获取足够多且真实的标注数据,这是因为人工标注的成本十分昂贵且标注速度不尽人意,文字识别往往依赖于数据增强方法用于丰富数据集,因此行而有效的数据增强方法是应对丰富多样的识别需求的关键。
4.机打文字可以通过不同字体生成各种各样的文本,通过简单的深度估计甚至能产生近似背景的图片。但是对于手写文字识别,由于手写文字连笔、更加多样,同时缺乏多样的字体、公开的数据集,手写识别很难取得如同机打字体同样的令人惊艳的效果。因此希望通过图像增强、语义理解、生成对抗网络等技术生成高质量且分布均衡的数据。
技术实现要素:
5.文字识别技术中常用的数据生成方法可分为三类:gan(对抗生成网络)生成法、基于特征变换的图像增强、以及基于深度学习的图像增强。本发明在此基础上提出一种基于ctc 的字符精准定位的图像增强方法丰富了数据生成方法。并创新性提出了对于通用场景文字识别可以通过上述四类数据生成方法的交叉运用获得更为丰富均衡的数据集,进而展开模型训练提高模型的泛化能力。
6.本发明的目的是至少克服现有技术的不足之一,提供了一种通用场景文字识别数据的自动生成方法及系统。
7.本发明的技术思想如下:
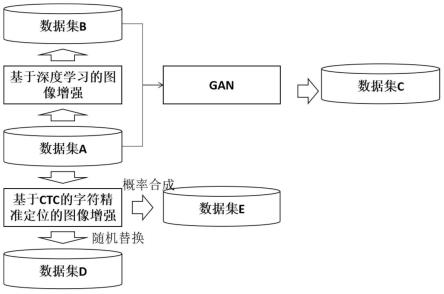
8.假设已有基础文字识别数据集a,利用基于深度学习的图像增强方法生成印刷体数据集b;使用gan把a的风格迁移到b上,扩充数据集得到c;利用数据集a使用基于ctc精准定位获取各个字符的样本集s,通过对a中字符的随机替换生成d,根据具有语义信息的文本组合或者随机组合字符集s获得e,最终可通过对a,b,c,d,e按比例混合训练,训练过程中可采用基于特征的数据增强方法丰富样本多样性。
9.其中,基于ctc的字符精准定位的图像增强方法思想如下:通过ctc方法在有限的训练集a上完成训练,预测准确的为a_,通过获取在特征层的各个字符起始位置和终止位
置,然后获取感受野可以得到字符在模型输入图片上的起点和终点,进而可以获取各个字符,初步完成基本字符收集s,通过人工的切图的方式可以增强多样性进而获取字符集合s
。然后在s
用生成各种各样的字符组合或者用s
替换a_,进而获取更大规模以及更平衡数据分布的数据集,完成数据增强。
10.本发明采用如下技术方案:
11.一方面,本发明一种通用场景文字识别数据的自动生成方法,包括:
12.s1、收集建立部分文字识别数据集a,数据集a为已存在的数据集;
13.s2、在数据集a的基础上,利用基于深度学习的图像增强方法生成印刷体数据集b;
14.s3、使用对抗生成网络gan把数据集a的风格迁移到数据集b上,扩充数据集得到数据集c;
15.s4、在数据集a的基础上,使用基于ctc的字符精准定位的图像增强方法获得数据集 d和数据集e;
16.s5、数据集a、数据集b、数据集c、数据集d和数据集e按比例混合训练,混合训练中采用基于特征的数据增强方法丰富样本多样性,得到最终数据集,即通用场景文字识别数据集。
17.如上所述的任一可能的实现方式,进一步提供一种实现方式,步骤s2中,所述基于深度学习的图像增强方法,采用合成自然场景文本的方法生成数据集b,文本生成方法包括:
18.s2.1字体渲染:随机选择字体,将文本沿水平方向或随机曲线方式呈现到图像前景层中;
19.s2.2描边、加阴影:对图像前景层渲染随机宽度的边缘或阴影;
20.s2.3基础着色:三个图像层中的每一层均填充从已有数据集a中采集的不同均匀色,均匀色通过k-means算法将数据集a中的每个图像中的三个通道颜色(r、g、b)聚类为三类(分别对应三个图像层);所述三个图像层为图像前景层、图像背景层和边缘阴影层;
21.s2.4仿射投影扭曲:对图像前景层和边缘阴影层进行随机的投影变换扭曲,模拟3d环境:
22.s2.5自然数据混合:每个图像层与来自icdar 2003和svt的训练数据集的随机采样的图像混合,得到数据集b。
23.如上所述的任一可能的实现方式,进一步提供一种实现方式,步骤s3中,利用生成模型用有限渠道获取的特定场景的图像数据生成均衡、适用各种场景的图像,生成模型通过与判别模型的博弈来迭代获取;扩充数据集得到数据集c的方法具体为:
24.s3.1生成模型生成一批图像;
25.s3.2判别模型学习区分生成图像和真实图像;
26.s3.3生成模型根据判别模型反馈结果来改进生成模型,迭代生成新图像;
27.s3.4判别模型继续学习区分生成图像和真实图像;
28.s3.5收敛完成后,利用生成模型生成图像数据。
29.如上所述的任一可能的实现方式,进一步提供一种实现方式,步骤s4中,使用基于ctc 的字符精准定位的图像增强方法获得数据集d和数据集e,具体方法为:
30.s4.1对有限的数据集a,采用基于ctc的文字识别模型进行训练;
31.s4.2待步骤s4.1训练完成后,对比数据集a的预测结果与真实标签,将对比结果相同的数据集记作a_;
32.s4.3通过对基于ctc的文字识别模型输出张量的分组聚合,得到数据集a_图像中每个字符在基于ctc的文字识别模型输出特征层中的起始位置si和结束位置ei,i》0;
33.s4.4计算数据集a_图像中每个字符在输入图像中的起始位置si和结束位置ei;
34.s4.5根据步骤s4.4获得的数据集a_图像中单字符的坐标值,获得单字符碎片图像数据集,记为s;
35.s4.6统计s中各字符的出现频率,辅以人工切分方式,平衡字符分布,获得字符集s
;
36.s4.7扩充数据集a_,扩充方式有以下三种方式:
37.1)先制作具有语义的标签,根据标签内容拼接字符集组合生成图像;
38.2)基于已获取的单字符坐标和已获得的字符集s
,替换数据集a_图像中的字符,具体为将单字符图像粘贴到被替换字符的坐标位置上;
39.3)随机生成;
40.利用2)形成数据集d,利用1)和3)生成数据集e。
41.如上所述的任一可能的实现方式,进一步提供一种实现方式,步骤s4.4中,每个字符在输入图像中的起始位置si和结束位置ei的计算方法为:
42.x1、通过如下公式迭代计算出卷积神经网络输出特征层感受野相关参数取值:
43.jump:j
out
=j
in
*s
[0044][0045]
其中,jump(j)表示两个连续特征点间的距离,下标in,out表示输入状态、输出状态, start表示第一个特征点的中心坐标,s表示卷积操作的补偿,k表示卷积核的大小,p表示卷积padding大小;
[0046]
x2、通过如下公式计算起始位置si和结束位置ei:
[0047]
si=start si*jump
[0048]ei
=start ei*jump。
[0049]
如上所述的任一可能的实现方式,进一步提供一种实现方式,步骤s5中,混合训练中采用基于特征的数据增强方法,基于特征变换的图像增强法是对现有的数据进行特征变换进而扩充数据量,特征变换方式包括:模糊、对比度变化、拉伸、旋转和随机剪裁。
[0050]
如上所述的任一可能的实现方式,进一步提供一种实现方式,步骤s5中,按比例混合训练,各数据集的比例根据实验或实际需求确定。
[0051]
另一方面,本发明还提供了一种通用场景文字识别数据的自动生成系统,包括:
[0052]
基于深度学习的图像增强模块,用于在数据集a的基础上,利用基于深度学习的图像增强方法生成印刷体数据集b;
[0053]
对抗生成网络gan模块,用于使用对抗生成网络gan把数据集a的风格迁移到数据集b上,扩充数据集得到数据集c;
[0054]
基于ctc的字符精准定位的图像增强模块,用于在数据集a的基础上,使用基于ctc 的字符精准定位的图像增强方法获得数据集d和数据集e;
[0055]
混合训练模块,用于数据集a、数据集b、数据集c、数据集d和数据集e按比例混合训练,混合训练中采用基于特征的数据增强方法丰富样本多样性,得到最终数据集;
[0056]
所述系统采用上述的通用场景文字识别数据的自动生成方法。
[0057]
另一方面,本发明还提供了一种终端,包括:处理器及存储器;所述存储器用于存储计算机程序;所述处理器用于执行所述存储器存储的计算机程序,以使所述终端执行上述的通用场景文字识别数据的自动生成方法。
[0058]
另一方面,本发明还提供了一种计算机存储介质,所述介质上存储有计算机程序,所述计算机程序被处理器执行实现权利要求1-7任一项所述的通用场景文字识别数据的自动生成方法。
[0059]
本发明的有益效果为:
[0060]
1、gan生成法、基于特征变换的图像增强、基于深度学习的图像增强以及基于ctc的字符精准定位的图像增强方法的交叉运用实现文字识别数据的多样生成。
[0061]
2、应对不同识别场景,文字识别数据生成方法的交叉运用。
[0062]
3、基于ctc和感受野的字符精准定位方法。
[0063]
4、基于字符精准定位的训练集单字符切分。
[0064]
5、数据增强方法:基于字符精准定位和部分语义的随机字符替换方法。
附图说明
[0065]
图1所示为本发明实施例一种通用场景文字识别数据的自动生成方法的实现逻辑图。
具体实施方式
[0066]
下文将结合具体附图详细描述本发明具体实施例。应当注意的是,下述实施例中描述的技术特征或者技术特征的组合不应当被认为是孤立的,它们可以被相互组合从而达到更好的技术效果。在下述实施例的附图中,各附图所出现的相同标号代表相同的特征或者部件,可应用于不同实施例中。
[0067]
整体实现逻辑图如图1所示,本发明实施例一种通用场景文字识别数据的自动生成方法,包括:
[0068]
s1、收集建立部分文字识别数据集a;
[0069]
s2、在数据集a的基础上,利用基于深度学习的图像增强方法生成印刷体数据集b;
[0070]
作为一个具体实施例,采用合成自然场景文本的方法生成数据集b,文本生成方法包括:
[0071]
s2.1字体渲染:随机选择字体,将文本沿水平方向或随机曲线方式呈现到图像前景层中;
[0072]
s2.2描边、加阴影、着色;
[0073]
s2.3基础着色:三个图像层中的每一层均填充从已有数据集a中采集的不同均匀色,均匀色通过k-means算法将数据集a中的每个图像中的三个通道颜色聚类为三类;所述三个图像层为图像前景层、图像背景层和边缘阴影层;
[0074]
s2.4仿射投影扭曲:对图像前景层和边缘阴影层进行随机的投影变换扭曲,模拟
3d环境:
[0075]
s2.5自然数据混合:每个图像层与来自icdar 2003和svt的训练数据集的随机采样的图像混合,得到数据集b。
[0076]
s3、使用对抗生成网络gan把数据集a的风格迁移到数据集b上,扩充数据集得到数据集c;
[0077]
在一个具体实施例中,利用生成模型用有限渠道获取的特定场景的图像数据生成均衡、适用各种场景的图像,生成模型通过与判别模型的博弈来迭代获取;扩充数据集得到数据集 c的方法具体为:
[0078]
s3.1生成模型生成一批图像;
[0079]
s3.2判别模型学习区分生成图像和真实图像;
[0080]
s3.3生成模型根据判别模型反馈结果来改进生成模型,迭代生成新图像;
[0081]
s3.4判别模型继续学习区分生成图像和真实图像;
[0082]
s3.5收敛完成后,利用生成模型生成图像数据。
[0083]
s4、在数据集a的基础上,使用基于ctc的字符精准定位的图像增强方法获得数据集 d和数据集e;
[0084]
在一个具体实施例中,具体方法为:
[0085]
s4.1对有限的数据集a,采用基于ctc的文字识别模型进行训练;
[0086]
s 4.2待步骤s4.1训练完成后(也可采用开源的预训练模型),对比数据集a的预测结果与真实标签,将对比结果相同的数据集记作a_;
[0087]
s4.3通过对模型输出张量的分组聚合,得到数据集a_图像中每个字符在模型输出特征层中的起始位置si和结束位置ei,i》0;
[0088]
s4.4计算数据集a_图像中每个字符在输入图像中的起始位置si和结束位置ei;
[0089]
在一个具体实施例中,每个字符在输入图像中的起始位置si和结束位置ei的计算方法为:
[0090]
x1、通过如下公式迭代计算出卷积神经网络输出特征层感受野相关参数取值:
[0091]
jump:j
out
=j
in
*s
[0092][0093]
其中,jump表示两个连续特征点间的距离,start表示第一个特征点的中心坐标,s表示卷积操作的补偿,k表示卷积核的大小,p表示卷积padding大小;
[0094]
x2、通过如下公式计算起始位置si和结束位置ei:
[0095]
si=start si*jump
[0096]ei
=start ei*jump。
[0097]
s4.5根据步骤s4.4获得的数据集a_图像中单字符的坐标值,获得单字符碎片图像数据集,记为s;
[0098]
s4.6统计s中各字符的出现频率,辅以人工切分方式,平衡字符分布,获得字符集s
;
[0099]
s4.7扩充数据集a_,扩充方式有以下三种方式:
[0100]
1)先制作具有语义的标签,根据标签内容拼接字符集组合生成图像;
[0101]
2)基于步骤4获取得单字符坐标和已获得的字符集s
,替换数据集a_图像中的字符,具体为将单字符图像粘贴到被替换字符的坐标位置上;
[0102]
3)随机生成;
[0103]
利用2)形成数据集d,利用1)和3)生成数据集e。
[0104]
s5、数据集a、数据集b、数据集c、数据集d和数据集e按比例混合训练,混合训练中采用基于特征的数据增强方法丰富样本多样性,得到最终数据集。
[0105]
在一个具体实施例中,基于特征变换的图像增强法是对现有的数据进行特征变换进而扩充数据量,特征变换方式主要包括:模糊、对比度变化、拉伸、旋转和随机剪裁。
[0106]
上述步骤给出了通用场景文字识别数据的自动生成方法,以印刷手写混合日期识别为例,在日期识别场景下,已有的数据集都是当前时间以前的数据,无法获得未来时间的数据集,比如2050年1月1日的日期数据严格意义来说是不存在的,但识别模型得具有识别未来时间的能力,因此需要通过数据生成获取未来的日期数据。日期识别采取的策略是通过数据生成方法生成随机日期数据用于训练,原始真实数据当做测试集,下表反映的是对于相同的原始数据集,相同的识别模型(ctc crnn),不同的数据生成方式对应的识别准确率。
[0107][0108]
通过上表可以看出,使用本发明所创新的基于ctc的字符精准定位的图像增强方法获得数据集的方法,识别准确率可大幅提高(从56-62%大幅提高到92%),如果四种识别方法进行组合,可进一步提高识别准确率(95%)。其他实验也得出了类似结果。
[0109]
在不同的识别需求下,可以灵活组合使用四种生成方式丰富数据集。
[0110]
本发明能够解决“手写文字识别,由于手写文字连笔、更加多样,同时缺乏多样的字体、公开的数据集,手写识别很难取得如同机打字体同样的令人惊艳的效果”的问题,通过图像增强、语义理解、gan等技术生成高质量且分布均衡的数据。
[0111]
本文虽然已经给出了本发明的几个实施例,但是本领域的技术人员应当理解,在不脱离本发明精神的情况下,可以对本文的实施例进行改变。上述实施例只是示例性的,不应以本文的实施例作为本发明权利范围的限定。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。