可从不可校正的存储器错误恢复的虚拟机
1.相关申请的交叉引用
2.本技术是于2020年11月17日提交的美国专利申请第16/950,212号的继续,该专利申请的公开内容通过引用并入本文。
背景技术:
3.云计算已经影响了企业管理计算需求的方式。它以成本有效的方式提供了可靠性、灵活性、可扩展性和冗余性。它使企业能够管理其信息技术需求,而无需例如传统的资本投资和维护考虑。随着越来越多的计算转移到云系统,这些系统现在以多年前难以想象的规模存储、处理和输出数据。这种转移的影响是,如果不被遏制和/或从中恢复,云中发生的存储器错误可能会以与企业在云上的占用相对应的规模影响顾客或用户体验。例如,并不罕见的是,在主机上检测到不可校正的存储器错误会导致主机关闭,从而导致所有托管虚拟机(vm)突然终止。由于存储器大小达到千兆字节或万亿字节规模,这可能会影响需要较长时间段才能重新建立的数千个vm或应用。
技术实现要素:
4.所公开技术的各个方面可以包括在云计算环境中实施的方法或系统,所述方法或系统允许遏制不可校正的存储器错误(例如保护dma访问不受损坏数据的影响)和从不可校正的存储器错误恢复。
5.公开技术的各个方面可以包括一种方法。例如,该方法可以是用于云计算环境中的不可校正的存储器错误恢复的方法。该方法可以包括:在虚拟机管理管理器处接收由主机机器检测到的不可校正的存储器错误的信令;在虚拟机管理管理器处,基于接收到的信令确定与损坏的存储器元件相关联的一个或多个虚拟机;基于不可校正的存储器错误仿真与损坏的存储器元件相关联的存储器错误;以及由虚拟机管理管理器,将仿真的存储器错误引入一个或多个虚拟机中的至少一个的操作环境中。
6.该方法的附加方面可以包括:引入仿真的存储器错误,包括虚拟机管理管理器注入中断,该中断由一个或多个虚拟机中的每个虚拟机的虚拟中央处理单元(vcpu)接受。进一步地,仿真的存储器错误可以包括使一个或多个虚拟机中的至少一个向客人用户空间发信号通知不可校正的存储器错误的通知。仿真的存储器错误还可以包括使一个或多个虚拟机中的至少一个被重启或终止的通知。仿真的存储器错误可以包括与不可校正的存储器错误相关联的上下文信息,包括位置、类型或严重性中的一个或多个。虚拟机管理管理器可以包括管理程序。
7.根据该方法,发信号通知可以包括主机机器的bios将与不可校正的存储器错误相关联的信息转发给主机机器的操作系统。更进一步地,该方法可以包括主机机器的操作系统将与不可校正的存储器错误相关联的信息转发给虚拟机管理器。
8.附加地,根据该方法,引入可以包括虚拟机管理器将仿真的存储器错误注入至少一个虚拟机的虚拟中央处理单元的过程中。更进一步地,确定与损坏的存储器元件相关联
的一个或多个虚拟机可以包括识别与损坏的存储器元件相关联的至少一个存储器页面。
9.所公开技术的各个方面还可以包括一种云计算系统。该系统可以包括能够支持一个或多个虚拟机的主机机器以及被耦合至包含指令的存储器的一个或多个处理设备。该指令可以使一个或多个处理器:从主机机器接收信令,该信令指示不可校正的存储器错误;基于接收到的信令,从一个或多个虚拟机中确定与损坏的存储器元件相关联的虚拟机;以及基于不可校正的存储器错误,仿真与损坏的存储器元件相关联的存储器错误。指令还可以使一个或多个处理设备将仿真的存储器错误注入到与损坏的存储器元件相关联的虚拟机的操作环境中。
10.该指令还可以使一个或多个处理设备注入仿真的存储器错误,使一个或多个处理设备注入中断,该中断由与损坏的存储器元件相关联的虚拟机的虚拟中央处理单元(vcpu)接受。
11.进一步地,仿真的存储器错误可以包括使与损坏的存储器元件相关联的虚拟机向客人用户空间发信号通知不可校正的存储器错误的通知。仿真的存储器错误可以包括使与损坏的存储器元件相关联的虚拟机被重启或终止的通知。另外,主机机器的bios可以被配置为将与不可校正的存储器错误相关联的信息转发给主机机器的操作系统。主机机器的操作系统可以将与不可校正的存储器错误相关联的信息转发给一个或多个处理设备。
12.系统的其他方面可以包括包含与不可校正的存储器错误相关联的上下文信息的仿真的存储器错误,包括位置、类型或严重性中的一个或多个。此外,主机机器的操作系统可以将与不可校正的存储器错误相关联的信息转发给一个或多个处理设备。一个或多个处理设备可以包括管理程序。另外,指令可以包括,为了确定指示不可校正的存储器错误的信令,包括识别与损坏的存储器元件相关联的至少一个存储器页面。
13.所公开技术的附加方面可以包括在其上存储有指令的一个或多个非瞬态计算机可读介质,该指令使一个或多个处理设备执行用于云计算环境中的不可校正的存储器错误恢复的过程或方法,包括:在虚拟机管理管理器处接收由主机机器检测到的不可校正的存储器错误的信令;在虚拟机管理管理器处,基于接收到的信令确定与损坏的存储器元件相关联的一个或多个虚拟机;基于不可校正的存储器错误仿真与损坏的存储器元件相关联的存储器错误;以及由虚拟机管理管理器,将仿真的存储器错误引入一个或多个虚拟机中的至少一个的操作环境中。该指令可以包括权利要求中列举的所公开技术的一种或多种其他方法或过程步骤。
附图说明
14.图1说明性地描绘了根据所公开技术的各个方面的示例系统或环境的框图。
15.图2说明性地描绘了根据所公开技术的各个方面的示例系统或环境的框图。
16.图3说明性地描绘了根据所公开技术的各个方面的示例过程或方法的流程图或游图。
17.图4描绘了根据所公开技术的各个方面的示例过程或方法的流程图。
具体实施方式
18.概述
19.存储器错误通常被分类为可校正的和不可校正的。可校正的错误通常不会影响云环境中的主机机器的正常操作,因此也不会影响主机计算系统。不可校正的错误通常对整个主机计算系统都是致命的,例如会导致主机机器崩溃或关闭。在基于云的虚拟机环境中,这意味着由主机机器支持的所有虚拟机(vm)都将与主机一起崩溃或关闭,不给vm/用户留下任何线索或留下很少的恢复机会。现代云计算系统中的不可校正的存储器错误的影响通常是显著的,因为这些系统通常会在每个主机上使用相对较大大小的存储器,例如云计算引擎可以使单个vm能够具有多达12万亿字节的存储器。这些较大的主机通常比较小的主机遭遇更高的不可校正存储器错误率,例如更多存储器转变为更多存储器错误。由于存储器错误导致的停机时间通常损失非常严重。
20.所公开技术的一个方面包括云计算基础设施,该云计算基础设施允许主机及其关联vm保持在线和/或从存储器错误(包括不可校正的存储器错误)中恢复,以及本地化和遏制存储器错误,使得它们不会影响系统的其他部分,诸如客人vm工作负载。例如,所公开的技术包括配置主机机器bios(包括关联的存储器元件)以启用在操作系统(os)上可恢复的错误信令,从而在检测到存储器页面上的存储器错误时增强和启用os的恢复路径。所公开技术的示例包括中央处理单元(cpu)能力,它可以向操作系统(os)发信号通知与存储器错误相关联的上下文信息(例如地址、严重性、是否孤立地发信号通知使得错误可恢复等)。例如,这种机制可能包括英特尔的x86机器检查架构,其中cpu向os报告硬件错误。os内核中的机器检查异常(mce)处置器(诸如经由例如linux提供的)然后可以使用诸如posix的应用编程接口(api),向触发mce的用户空间软件应用发信号通知错误存在。用户空间应用可以通过以下来使mce能复原:提供数据冗余性(例如分层缓存模型,诸如持久存储,然后是存储器);本地工作数据集的本机分片以最小化损失的工作量;或者使用户应用尽可能无状态使得它可以重启而不损失工作。
21.所公开技术的一个方面包括云计算系统或架构,其中提供了一种机制,使得虚拟机管理器或管理程序包括通过主机机器警告存储器错误的能力,特别是不可校正的存储器错误。在被警告后,管理程序会处理从主机机器接收到的存储器错误信息,以确定从警告中所包括的存储器错误消息中识别的可能正在访问可损坏存储器元件的vm。在识别出受影响的vm后,管理程序例如通过提供存储器页面来经由所述受影响的vm的相应的客人os向所述受影响的vm通知存储器错误,所述存储器页面标记被映射到损坏存储器元件的物理存储器位置或物理地址的虚拟存储器位置或逻辑地址。然后,客人os和vm可以通过将vm上运行的实例移动到其他vm来避免使用受影响的逻辑地址,包括用户关闭这些vm并且发出更换vm的命令/请求。进一步地,管理程序现在可以避免用于可能被指派给受影响主机机器的新vm请求的该损坏的存储器元件。另外,针对不可校正的存储器错误,管理程序可能会发起过程来故障切换受影响主机机器上运行的vm,使得主机机器最终可以被修复。
22.可以了解,根据前述机制实施的云计算系统或架构可以遏制不可校正的存储器错误和允许从不可校正的存储器错误中进行柔性恢复。具体地,通过识别受影响的存储器,管理程序可以前瞻性地限制或消除这种存储器的使用(例如读取或访问)。另外,管理程序可以将影响仅限于受影响的vm。另外,管理程序可以发起受影响vm的故障切换,然后管理将由损坏主机支持的未受影响的vm移动到另一主机,以允许损坏主机被修复。通过这种方式,顾客或用户对不可校正的存储器错误的影响的暴露可能仅被限于其虚拟存储器被链接至损
坏的物理存储器元件或地址的受影响vm,而未关联的vm不知道该错误并且不会受到任何影响。
23.例如,在重启应用或vm不够的应用中,例如大型数据库应用,损坏的数据可能会被隔离并且换出。在webservice类型的应用中,所公开技术的各个方面允许所有未受影响的vm保持活动并且继续运行,而只有受影响的vm才被重启。在gpu或tpu集群中,类似的优点可以被实现,因为仅受存储器错误影响的vm或应用才需要被重启。
24.当不可校正的错误被发信号通知时,通常存储器中已经发生永久性数据损坏。在某些情况下,仍然可以从这些错误中恢复。例如,如果损坏的缓存线/页面落在特定条件内,则可以进行恢复。具体地,在受影响存储器页面的内容可以从持久存储(例如sap hana存储器中数据库)重构的情况下,可以进行恢复。如果受影响的过程是非关键用户空间过程,也可以进行恢复,在这种情况下,可以毒化和丢弃损坏的页面并且重启过程,而不影响vm上的主要作业。作为另一示例,在vm上的主要服务作业可以在重启后继续运行的情况下,可以进行恢复。这可能适用于许多用例。在这方面,用户通常更喜欢重启,而不是突然丢失vm主机,例如在分布式训练工作负载中,从上次保存的检查点继续训练的工人重启比完全丢失机器达延长时间段从而使用于训练工作负载的整个机架不可用的干扰更小。另一方面,在受影响的vm无法进行恢复的实例中,将主机上的其余vm保持活动可以显著减小存储器错误的爆炸半径。所公开技术的各个方面可以使得恢复和遏制不可校正的存储器错误成为可能。
25.示例系统
26.图1是根据本公开的各个方面的示例系统100。系统100包括一个或多个计算设备110(可以包括计算设备1101至110k)、网络140和一个或多个云计算系统150(可以包括云计算系统1501至150m)。计算设备110可以包括位于顾客位置处的计算设备,这些计算设备使用云计算服务,诸如基础设施即服务(iaas)、平台即服务(paas)和/或软件即服务(saas)。例如,如果计算设备110位于商业企业处,则计算设备110可以使用云系统150作为向操作企业系统中使用的计算设备110提供软件应用(例如会计、字处理、库存追踪等应用)的服务。作为替代示例,计算设备110可以以虚拟机的形式出租基础设施,软件应用在虚拟机上运行以支持企业操作。
27.如图1所示,计算设备110中的每个计算设备110可以包括一个或多个处理器112、存储数据(d)和指令(i)的存储器116、显示器120、通信接口124和输入系统128,它们被示出为经由网络130互连。计算设备110也可以被耦合或连接至存储136,该存储136可以包括存储作为顾客操作的一部分累积的数据的例如存储区域网络(san)上的本地或远程存储。计算设备110可以包括独立计算机(例如台式计算机或膝上型计算机)或与顾客相关联的服务器。给定的顾客还可以将多个计算设备作为服务器实施为其商业的一部分。如果是独立计算机,则网络130可以包括计算机内部的数据总线等;如果是服务器,则网络130可以包括局域网、虚拟私有网络、广域网或下面关于网络140描述的其他类型的网络中的一个或多个。存储器116存储由一个或多个处理器112可访问的信息,包括可以由处理器112执行或以其他方式使用的指令132和数据134。存储器116可以是能够存储由处理器可访问的信息的任何类型,包括计算设备可读介质或者存储可以借助于电子设备(诸如硬盘驱动器、存储卡、rom、ram、dvd或其他光盘以及其他可写和只读存储器)读取的数据的其他介质。系统和方法可以包括前述的不同组合,由此指令和数据的不同部分被存储在不同类型的介质上。
28.指令132可以是通过处理器直接地执行的任何指令集(诸如机器代码)或者间接地执行的任何指令集(诸如脚本)。例如,指令可以作为计算设备代码被存储在计算设备可读介质上。在这方面,术语“指令”和“程序”在本文中可以互换使用。指令可以为了通过处理器直接处理而以目标代码格式存储,或者以任何其他计算设备语言存储,该任何其他计算设备语言包括根据需要进行解译或者提前编译的脚本或者独立源代码模块的集合。指令的过程、功能、方法和例程在下面更详细地解释。
29.数据134可以由处理器112根据指令132检索、存储或修改。作为示例,与存储器116相关联的数据134可以包括用于支持一个或多个客人端设备、应用等的服务的数据。这种数据可以包括支持托管基于web的应用、文件共享服务、通信服务、游戏、共享视频或音频文件或者任何其他基于网络的服务的数据。
30.一个或多个处理器112可以是任何常规处理器,诸如可商购的cpu。备选地,一个或多个处理器可以是专用设备,诸如asic或者其他基于硬件的处理器。尽管图1在同一块内在功能上图示了处理器、存储器以及计算设备110的其他元件,但是本领域的普通技术人员要理解,处理器、计算设备或者存储器实际上可以包括多个处理器、计算设备或者存储器,它可以或可以不位于同一物理外壳内或者被存储在同一物理外壳内。在一个示例中,一个或多个计算设备110可以包括一个或多个服务器计算设备,该服务器计算设备具有与网络的不同节点交换信息以便作为顾客商业操作的一部分向其他计算设备接收、处理和传输数据以及从其他计算设备接收、处理和传输数据的多个计算设备,例如负载平衡服务器农场。
31.计算设备110还可以包括提供用户界面的显示器120(例如具有屏幕、触摸屏、投影仪、电视或可操作以显示信息的其他设备的监测器),所述用户界面允许控制计算设备110并且访问一个或多个云系统150中支持的用户空间应用和/或数据关联vm,例如在云系统150中的主机上。这种控制可以包括例如使用计算设备使数据通过输入系统128被上传到云系统150进行处理,使数据在存储136上累积,或者更一般地,管理顾客计算系统的不同方面。在一些示例中,计算设备110还可以访问api,该api允许它指定在云中的vm上运行的工作负载或作业作为iaas或saas的一部分。虽然输入系统128可以被用于上传数据,例如usb端口,但计算设备110还可以包括可以被用于接收命令和/或数据的鼠标、键盘、触摸屏或麦克风。
32.网络140可以包括各种配置以及协议,包括诸如bluetooth
tm
、bluetooth
tm le的短程通信协议、互联网、万维网、内联网、虚拟私有网络、广域网、本地网络、一个或多个公司专有的使用通信协议的私有网络、以太网、wifi、http等以及前述的各种组合。这种通信可以通过能够向或从其他计算设备(诸如调制解调器以及无线接口)传输数据的任何设备促进。计算设备通过通信接口124与网络140接口连接,该通信接口124可以包括支持给定通信协议所需的硬件、驱动器和软件。
33.云计算系统150可以包括一个或多个数据中心,这些数据中心可以经由高速通信或计算网络链接。系统150内的给定数据中心可以包括建筑物内的专用空间,它容纳计算系统及其关联组件,例如存储系统和通信系统。通常,数据中心将包括通信设备的机架、服务器/主机和磁盘。服务器/主机和磁盘包括被用于提供虚拟计算资源(诸如vm)的物理计算资源。在给定的云计算系统包含多于一个数据中心的程度上,这些数据中心可能位于彼此相对接近的不同地理位置处,这些数据中心被选择来以及时且经济高效的方式递送服务,也
提供冗余性并且维持高可用性。类似地,不同的云计算系统通常在不同的地理位置处提供。
34.如图1所示,计算系统150可以被图示为包括主机机器152、存储154和基础设施160。主机机器152、存储154和基础设施160可以包括云计算系统150内的数据中心。基础设施160可以包括交换机、物理链路(例如光纤)以及用于将数据中心内的主机机器与存储154互连的其他设备。存储154可以包括磁盘或其他存储设备,该磁盘或其他设备可分区以向在数据中心内的处理设备上运行的虚拟机提供物理或虚拟存储。存储154可以作为san在托管由存储154支持的虚拟机的数据中心内提供,或者可以在不同的数据中心中提供,该数据中心不与它支持的虚拟机共享物理位置。给定数据中心内的一个或多个主机机器或其他计算机系统可以被配置为在创建和管理与给定数据中心中的一个或多个主机机器相关联的虚拟机时充当监督代理或管理程序。通常,被配置为用作管理程序的主机或计算机系统将包含必要的指令,以例如管理由于源自例如计算设备110的服务请求向顾客或用户提供iaas、paas或saas而导致的操作。
35.在图2所示的示例中,分布式系统200(诸如关于图1的云系统150示出的)包括支持或执行虚拟计算环境300的主机机器210(例如硬件资源210)的集合204。虚拟计算环境300包括虚拟机管理器(vmm)320和运行一个或多个虚拟机(vm)350a-n的虚拟机(vm)层340,该一个或多个虚拟机350a-n被配置为执行一个或多个软件应用360的实例362a、362a-n。每个主机机器210可以包括一个或多个物理中央处理单元(pcpu)212(“数据处理硬件212”)和关联的存储器硬件216。虽然每个硬件资源或主机210被示出为具有单个物理处理器212,但任何硬件资源210可以包括多个物理处理器211。主机210还包括物理存储器216,它可以由主机操作系统(os)220分区为虚拟存储器,并且被指派以由vm层340中的vm 350甚或vmm 320或主机os 220使用。物理存储器216可以包括随机存取存储器(ram)和/或磁盘存储(包括经由基础设施160可访问的存储154,如图1所示)。
36.主机操作系统(os)220可以在给定的一个主机机器210上执行,或者可以被配置为跨包括多个主机机器210的集合操作。为了方便起见,图2示出了主机os 220跨机器2101至210m的集合操作。进一步地,虽然主机os 220被图示为虚拟计算环境300的一部分,但每个主机机器210都被配备有自己的os 218。然而,从虚拟环境的角度来看,每个机器上的os看起来像集合os 220,并且作为vmm 320和vm层340的集合os 220进行管理。
37.在一些示例中,vmm 320对应于管理程序320(例如计算引擎),该管理程序包括被配置为创建、实例化/部署和执行vm 350的软件、固件或硬件中的至少一个。与执行一个或多个vm 350的vmm 320相关联的计算机(诸如数据处理硬件212等)通常被称为主机机器210(如上面使用的),而每个vm 350可以被称为客人机器。此处,vmm 320或管理程序被配置为向每个vm 350提供具有虚拟操作平台并且管理vm350上的对应客人os 354的执行的对应的客人操作系统(os)354,例如354a-n。如本文使用的,每个vm 350可以被称为“实例”或“vm实例”。在一些示例中,各种操作系统的多个实例可以共享虚拟化资源。例如,操作系统的第一vm 350、操作系统的第二vm350和os操作系统的第三vm 350都可以在单个物理x86机器上运行。
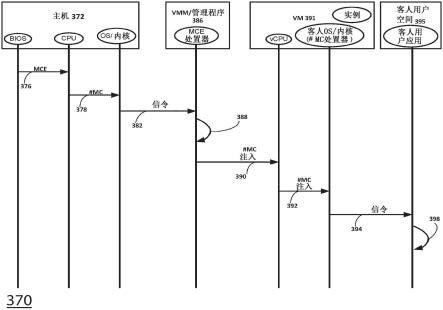
38.vm层340包括一个或多个虚拟机350。分布式系统200使得用户(通过一个或多个计算设备110)根据需要启动vm 350,即,通过经由网络140向分布式系统200(包括云系统150)发送命令或请求170(图1)。例如,命令/请求170可以包括与对应的操作系统220相关联的图
像或快照,并且分布式系统200可以使用该图像或快照为对应的vm 350创建根资源210。此处,命令/请求170内的图像或快照可以包括引导加载程序、对应的操作系统220和根文件系统。响应于接收到命令/请求170,分布式系统200可以实例化对应的vm 350,并且在实例化时自动启动vm 350。
39.vm 350仿真真实计算机系统(例如主机机器210),并且基于真实计算机系统或假设计算机系统的计算机架构和功能进行操作,这可能涉及专用硬件、软件或其组合。在一些示例中,分布式系统200在启动一个或多个vm 350之前对用户设备110进行授权和认证。软件应用360的实例362或简单的实例是指托管在分布式系统200的数据处理硬件212上(在其上执行)的vm 350。
40.主机os 220虚拟化底层主机机器硬件,并且管理一个或多个vm实例350的并发执行。例如,主机os 220可以管理vm实例350a-n,并且每个vm实例350可以包括底层主机机器硬件的模拟版本或不同的计算机架构。与每个vm实例350、350a-n相关联的硬件的模拟版本被称为虚拟硬件352、352a-n。虚拟硬件352可以包括仿真主机机器210的一个或多个物理处理器212的一个或多个虚拟中央处理单元(vcpu)(“虚拟处理器”)。虚拟处理器可以被互换地称为与vm实例350相关联的“计算资源”。计算资源可以包括执行对应的单个服务实例362所需的目标计算资源级别。
41.虚拟硬件352还可以包括与虚拟处理器通信并且存储由虚拟处理器可执行的客人指令(例如客人软件)以执行操作的虚拟存储器。例如,虚拟处理器可以执行来自虚拟存储器的指令,所述指令使虚拟处理器执行软件应用360的对应的单独服务实例362。此处,单独服务实例362可以被称为无法确定它是由虚拟硬件352还是物理数据处理硬件212执行的客人实例。主机机器的微处理器可以包括处理器级别机制,以通过允许客人软件指令在主机机器的微处理器上直接执行而不需要代码重写、重新编译或指令仿真来使虚拟硬件351能够高效地执行应用360的软件实例362。虚拟存储器可以被互换地称为与vm实例350相关联的“存储器资源”。存储器资源可以包括执行对应的单独服务实例362所需的目标存储器资源级别。
42.虚拟硬件352还可以包括至少一个虚拟存储设备,它为物理存储器硬件212上的服务提供运行时容量。至少一个虚拟存储设备可以被称为与vm实例350相关联的存储资源。存储资源可以包括执行对应的单独服务实例362所需的目标存储资源级别。在每个vm实例350上执行的客人软件还可以指派网络边界(例如分配网络地址),通过该网络边界,相应的客人软件可以与通过内部网络160(图1)、外部网络140(图1)或两者可达到的其他过程通信。网络边界可以被称为与vm实例350相关联的网络资源。
43.在每个vm 350上执行的客人os 354包括控制对应的单独服务实例362的执行的软件,例如由vm实例350执行的应用360的362a-n中的一个或多个。在vm实例350、350a-n上执行的客人os 354、354a-n可以与在其他vm实例350上执行的其他客人os 354相同或不同。在一些实施方式中,vm实例350不需要客人os 354来执行单独服务实例362。主机os 220还可以包括为主机os 220的内核226保留的虚拟存储器。内核226可以包括内核扩展和设备驱动器,并且可以执行某些特权操作,这些操作不受主机os 220的用户过程空间中运行的过程的限制。特权操作的示例包括访问不同的地址空间,访问主机机器210中的特殊功能处理器单元(诸如存储器管理单元)等。在主机os 220上运行的通信过程224可以提供vm网络通信
功能性的一部分,并且可以在用户过程空间或与内核226相关联的内核过程空间中执行。
44.根据所公开技术的各个方面,在实施mce的主机机器210上发生的不可恢复的存储器错误(例如位翻转)可以在管理程序层处进行管理,以减轻和/或避免受影响的客人vm崩溃,并且遏制不可恢复的存储器错误对仅受影响的客人vm的影响。例如,与给定主机机器210相关联的bios被配置为使得由主机上的pcpu 212生成的mce被发送给内核226。mce包括关于错误的上下文信息,包括例如物理存储器地址、错误的严重性、错误是否为孤立错误、错误从其发信号通知的pcpu内的组件等。内核226将错误中继到管理程序320。然后,管理系统320处理该信息,以识别与错误相关联的虚拟存储器,并且识别任何受影响的存储器页面以及关联的vm。由于vm通常不共享虚拟存储器,给定的存储器错误可能针对给定的vm隔离。因此,除了受影响的vm之外,几乎没有传播错误的风险。管理程序320然后隔离损坏的存储器页面,以避免客人os访问它。接下来,管理程序通过仿真错误来向受影响的客人os告知错误。具体地,管理程序向客人os注入中断,例如中断80,它将错误告知给客人os。例如,通过这种方式,只有受错误影响的vm才会接收到错误通知,并且只有vm或与该vm相关联的应用才可以被重启。
45.另外,在被通知损坏的虚拟存储器地址或包含这种地址的存储器页面后,受影响的vm可能会避免读取或访问这些存储器位置,从而导致错误的遏制。例如,损坏的存储器元件的每个存储器读取或访问生成mce。所公开技术的一个方面在主机级别检测到损坏的存储器元件并且vmm和/或客人os被通知错误后,减轻和/或避免导致对所述损坏的存储器元件的多个读取或访问。
46.在其他示例中,用户应用可能跨多个虚拟机运行,并且与单个vm相关联的存储器错误可能会影响多个vm(例如机器学习训练作业)。在这种示例中,错误的影响可能需要将错误通知多于一个vm。例如,如果管理程序在多于一个vm之间分发了一个或多个给定作业,那么管理系统可能会将错误广播到所有受影响的vm。在该实例中,用户可能会决定关闭和重启受影响的应用是可行的选项。相反,如果涉及单个vm,则通过例如向它提供新的存储器页面或重启它来保持vm活动可能是可行的选项。
47.示例过程或方法
48.根据所公开技术的各个方面的处理流程或方法370的示例如图3所示。主机372包括bios、cpu和内核(作为其os的一部分)。主机被配置为检测不可校正的存储器错误,并且响应于这种检测发出机器检查异常(mce)。另外,还提供了对检测到的不可校正的存储器错误进行分类的能力。例如,分类可能包括发现错误的位置、错误是否可恢复以及什么类型的恢复是允许或必要的。例如,一些硬件架构中继上下文信息,这些上下文信息向软件发信号通知恢复是不可能的,因此内核需要进入应急模式。发生这种情况的典型示例是当执行上下文被损坏时(例如在执行某些指令的cpu中间发生错误)。当不可校正的存储器错误在主机372中被检测到时,bios会向cpu发送mce,行376。
49.然后,cpu将mce信息(描绘为#mc)中继到主机372的内核,行378。#mc和mce或mce信息可以包括相同的上下文信息或相同类型的上下文信息。内核内的处置器(例如mce或#mc处置器)接收包括上下文信息的关于不可校正的存储器事件的mce信息(#mc),并且发信号通知在管理程序386中的mce信号处置器,行382行。发信号通知可能经由总线错误信号(例如sigbus)发生。管理程序386对mce信息进行解码,并且将其映射到与由受影响主机支持的
vm相关联的虚拟存储器空间,行388。在这样做时,管理程序386确定与损坏的存储器元件相关联的虚拟存储器和存储器页面。另外,管理程序386仿真mce事件,行388。即,管理程序386将与物理存储器错误相关联的上下文信息转变为与虚拟存储器位置相关联的上下文信息。然后,管理程序通过将mce信息(#mc注入)注入受影响的vm环境中来提供错误仿真,行390。具体地,管理程序发起对vcpu的中断,并且向vcpu提供#mc注入。
50.vcpu然后将#mc注入转发给在vm 391上运行的客人os,行392。例如,响应于接收到#mc注入,客人os的客人内核内的处置器向客人用户空间(例如客人用户空间应用)发出总线错误信号,行394。将#mc或mce信息注入客人os中和/或客人内核中的#mc处置器发信号通知客人用户空间395可以具有保持vm实例活动的效果。然后,客人用户应用可以决定通过从发信号通知的存储器错误中恢复、关闭受影响的vm或重启vm实例来继续运行,行398。可能的恢复动作包括重新映射和重新加载受影响的存储器页面或重启客人用户空间程序。例如,如果损坏的存储器元件的内容可以从存储中重构,则新的存储器页面可以被重新映射和重新加载,并且实例或应用可以继续运行或保持活动。备选地,如果应用可以在重启后继续运行,那么该动作过程可以被采取。在一些情况下,取决于错误,对驻留在主机上的vm的实时迁移可能是必要的,但即使在此处,与突然关闭主机相比,这种迁移也可以更柔性地处置。
51.如从前述内容指示的,所公开技术的各个方面包括使主机内核的mce处置器将所有相关mce细节发信号通知给虚拟机管理器或管理程序。利用管理程序,mce sigbus处置器在例如vmevents表中记录存储器错误事件。事件表可以包括记录以下细节的字段:常规vm元数据(例如vm id、项目id;mce细节:来自所有相关存储体的dimm、等级、存储体、mca寄存器)。可选地,邻居信息也可以被记录,例如主机上、同一套接字上有哪些其他vm等。邻居信息在分析潜在安全攻击(诸如例如行锤攻击)时可能很重要。在这种示例中,所公开的技术可能会将所有受影响的vm通知给客人用户空间,并且导致发起到另一主机的更柔性的故障切换。
52.存储器错误遏制和存储器错误恢复以及iio停止和尖叫在bios中启用。经由具体的新msi/nmi处置器发信号通知的错误被添加到主机内核,其行为只是对主机应急。主机内核被配置为知道mce错误属于哪个地址空间以及该过程是否是vm。
53.图4图示了根据所公开技术的各个方面的方法或过程400。如所示,该方法包括检测与不可校正的存储器错误相关的mce,并且将其转发给虚拟机管理器或管理程序,框410。mce信息由虚拟机管理器或管理程序解码和映射到受影响的存储器页面,从而到受影响的vm,框420。然后,虚拟机管理器或管理程序通知客人os,它继而通知客人空间,框430。在客人用户空间处,可以确定保持受影响的vm实例或应用活动、终止应用或重启应用,框440。关于这些操作的其他细节已在上面描述。
54.除非另有规定,否则前述替代示例不是互斥的,而是可以以各种组合实施以实现唯一的优点。由于上面讨论的特征的这些和其他变化以及组合可以在不脱离由权利要求定义的主题的情况下利用,因此,实施例的前述描述应该通过图示而不是通过限制由权利要求定义的主题来进行。另外,本文描述的示例的提供以及用短语表达为“诸如”、“包括”等的条款不应被解释为将权利要求的主题限制于具体示例;相反,示例旨在仅图示许多可能实施例中的一个实施例。进一步地,不同附图中的相同附图标记可以标识相同或类似的元件。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
