一种针对risc-v矢量与浮点寄存器的物理寄存器堆分配装置
技术领域
1.本发明涉及risc-v处理器(cpu)乱序架构矢量与浮点寄存器的物理寄存器堆分配装置。
背景技术:
2.在高性能处理器的微架构设计中,乱序(out-of-order,简称ooo)执行是一种常用的提升性能的方式,其根据数据可用性来决定指令执行的顺序,而非程序本身的指令顺序,从而减少由于指令等待数据而导致处理器停滞所带来的延迟。以下面的指令序列为例,当按序执行时,指令1需要等待指令0的结果,而指令0为除法指令,通常需要较长的执行延时,从而导致处理器停顿等待结果。而在乱序架构中,可以通过检测发现指令2~指令4的操作数不依赖于指令0或者指令1的结果,因此通过提前执行指令2~指令4来减少处理器停顿的延时。
3.指令0:div x2, x1, x0指令1:sub x4, x2, x3指令2:add x3, x5, x6指令3:add x2, x7, x8指令4:sub x5, x2, x3......然而乱序执行可能会导致处理器的运行出错,例如上述的指令序列,由于指令1无法执行而指令2~指令4提前执行了,若指令3的结果提前直接回写x2寄存器,而指令1可能会错误获取到被指令3更新的x2结果从而导致运行出错。因此在乱序架构的设计中,需要引入额外的机制来避免执行顺序改变带来的问题。
4.上述例子中的x0~x8,即为指令集架构(isa)所使用的寄存器。isa通过引入一定数量的寄存器来保存指令的操作数和结果,而处理器则负责执行isa所定义的指令功能。不同的isa可能有不同数量的寄存器,例如x86指令集有8/16个整型寄存器,arm指令集有32个整型寄存器,risc-v指令集有32个整型寄存器。这类由指令集架构决定的寄存器称为体系架构寄存器。
5.而处理器往往需要将体系架构寄存器映射到硬件上的物理寄存器,来实现寄存器数据的写入和读取。在简单的按序架构中,由于指令执行的顺序与程序顺序保持一致,通常只需要和体系架构寄存器相同数量的物理寄存器来做一一映射即可,每条指令根据操作数的索引从相应的物理寄存器读取对应的操作数,并且在指令完成后回写对应的目的寄存器。
6.而在乱序架构中,通常会通过引入寄存器重命名技术来解决乱序读取和回写寄存器的问题。处理器会引入一张重命名表,每个体系架构寄存器所对应的物理寄存器由重命名表来记录。当一条指令回写一个寄存器时,就为这个寄存器重新映射到一个空闲的物理寄存器,即这条指令的结果将回写被重新映射的物理寄存器上,而后续的指令若需要用到
该指令的结果寄存器作为源操作数,则可以通过查找重命名表来获取对应的物理寄存器的信息,并读取相应的数据。
7.我们还是以上述的指令序列作为例子来阐述重命名表的工作机制,如图1所示,假设有x0~x15共16个体系架构寄存器,有p0~p31共32个物理寄存器。在指令0执行之前,重命名表上记录的映射关系为x0~x8分别映射到p0~p8。
8.指令0的操作数x0和x1对应着p0和p1,且指令回写x2,则为x2分配新的映射关系p27;指令1看到的映射表关系发生变化,操作数x2和x3分别对应着p27和p3,且指令回写x4,则为x4分配新的映射关系p28;指令2看到的映射表关系发生变化,操作数x5和x6分别对应着p5和p6,且指令回写x3,则为x3分配新的映射关系p29;指令3看到的映射表关系发生变化,操作数x7和x8分别对应着p7和p8,且指令回写x2,则为x2分配新的映射关系p30。
9.可以看到,通过上述的重命名机制,哪怕指令3提前发射执行并回写x2,也不会影响指令1获取正确的x2数据,因为两条不同指令的x2映射到了不同的物理寄存器表项。而指令1所对应的p2表项则可以在指令0回写且指令1读取到数据并发射后进行释放给后续的指令使用。由于一个体系架构寄存器在同一时间可能需要占用若干个物理寄存器,因此这种机制往往需要物理寄存器的数量大于体系架构寄存器的数量,否则指令也会因为无法分配到空闲的物理寄存器而被停滞,等待物理寄存器释放。具体的原理可以参考约翰
•
l.亨尼斯和戴维
•
a.帕特森著的《计算机体系结构:量化研究方法》。
10.除了整型寄存器以外,大部分处理器的isa还包括浮点寄存器或者矢量寄存器,用于浮点指令和矢量指令,例如x86的avx以及arm的neon指令集。类似于整型寄存器,重命名技术也适用于浮点和矢量的乱序执行。
11.本发明基于开源架构risc-v的浮点扩展指令集和矢量扩展指令集vector extension,具体的指令集架构spec文档可以参考网址:https://github.com/risc-v/risc-v-isa-manual/releases/download/ratified-imafdqc/risc-v-spec-20191213.pdf;https://github.com/risc-v/risc-v-v-spec/releases/tag/v1.0。
12.浮点扩展指令集包括32个浮点寄存器f0~f31,每个寄存器的位宽为flen(flen=32/64)。矢量扩展指令集包括32个矢量寄存器v0~v31,每个寄存器的位宽为vlen(vlen=64/128/256...2048)。
13.通常来说,不同类型的体系架构寄存器都拥有各种的物理寄存器堆,例如intel的skylake架构有180个独立的整型物理寄存器和168个矢量物理寄存器;amd的zen 2有180个独立的整型物理寄存器和160个浮点物理寄存器(参考https://www.hardwaretimes.com/intel-sunny-cove-vs-amd-zen-2-core-architectures-10th-gen-ice-lake-vs-ryzen-3000/);开源risc-v架构boom有独立的128个整型物理寄存器和128个浮点物理寄存器堆(参考https://readthedocs.org/projects/risc-v-boom/downloads/pdf/latest/);开源risc-v架构香山处理器有独立的192个整型物理寄存器和192个浮点物理寄存器堆(参考https://xiangshan-doc.readthedocs.io/zh_cn/latest/arch/)。
14.risc-v架构由于同时存在独立的浮点寄存器和矢量寄存器,在架构设计中需要同时提供对应的物理寄存器堆资源对各自的数据进行保存。而如果需要支持乱序的矢量和浮点架构,则对应的物理寄存器堆资源也需要增加。
15.现有技术中,通常不同类型的架构寄存器有各自的物理寄存器堆,而高性能处理器往往需要采用较深的乱序发射和较大的并行发射宽度来满足性能需求,因此需要比架构寄存器数量更多的物理寄存器来支撑,具体可参考上述各例子。因此,处理器若要支持高性能的浮点和矢量处理,为浮点寄存器和矢量寄存器各自提供远超其架构寄存器数量的物理寄存器来提供尽可能强大的乱序处理能力,是一种常用的方式。然而,由于浮点指令和矢量指令应用场景的区别,处理器往往会存在同时处理大量的浮点指令或者同时处理大量的矢量指令的情况,但不太会出现大量浮点指令和矢量指令混合的情况。因此,则可能存在当浮点物理寄存器堆被大量的浮点指令填满占用时,矢量寄存器堆此时处于闲置或者利用不充分的状态,反之亦然。
16.尽管这种架构通过大量的物理寄存器堆资源来提升了处理器性能,但大量的物理寄存器堆资源常常会处于利用不充分的状态。
17.相关现有技术可以参见专利文献:cn1160622c、cn1983164a、cn100561461c、cn101290567a、cn102262525a、cn108845826a、cn109508206a、cn112346783a、cn112506468a、cn114020328a、wo2022120722a1。
技术实现要素:
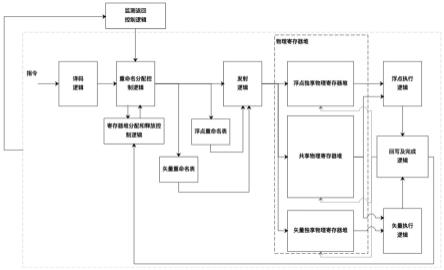
18.为了解决上述技术问题,本发明提供一种针对risc-v矢量与浮点寄存器的物理寄存器堆分配装置,采用浮点寄存器和矢量寄存器共享物理寄存器堆的方式,同时通过一个监测返回控制逻辑将表项数据从共享物理寄存器堆中搬运到独享物理寄存器堆中,解决现有大量物理寄存器堆资源利用不充分的问题,其采用如下技术方案:一种针对risc-v矢量与浮点寄存器的物理寄存器堆分配装置,包括:译码逻辑,对输入指令进行译码获得指令信息,至少包括指令类型、源操作数索引和目的寄存器索引;重命名表,记录架构寄存器和物理寄存器堆之间的映射关系;物理寄存器堆,至少分为三组,一组为浮点独享物理寄存器堆,一组为矢量独享物理寄存器堆,一组为共享物理寄存器堆;其中浮点独享物理寄存器堆只分配给浮点架构寄存器使用,其中矢量独享物理寄存器堆只分配给矢量架构寄存器使用,其中共享物理寄存器可以分配给浮点架构寄存器和矢量架构寄存器使用;寄存器堆分配和释放控制逻辑,负责物理寄存器堆的表项分配和释放;监测返回控制逻辑,监测共享物理寄存器堆是否有不需要被使用到的有效表项,以及监测浮点独享物理寄存器堆和矢量独享物理寄存器堆是否有空闲表项,将对应的表项数据以及搬运请求发送给重命名分配控制逻辑;重命名分配控制逻辑,根据译码逻辑获得的指令信息,判断是否需要分配物理寄存器堆的表项用于存放指令结果,以及判断所需要分配的对应的物理寄存器堆,并根据寄存器堆分配和释放控制逻辑分配的表项,更新重命名表;并且根据监测返回控制逻辑的反馈,确定是否需要将共享物理寄存器堆的表项数据搬运到独享物理寄存器堆表项中;
重命名分配控制逻辑根据源操作数索引访问重命名表,获取源操作数对应的物理寄存器堆索引,并传递给发射逻辑。
19.本发明具有以下有益技术效果:独享物理寄存器堆为浮点寄存器和矢量寄存器各自提供了必要的寄存器堆资源存储数据,而共享物理寄存器堆则可以灵活地分配给浮点寄存器和矢量寄存器使用;同时通过监测返回控制逻辑,能够及时将共享物理寄存器堆不需要的信息返回给对应的独享物理寄存器堆,及时释放共享表项给后续指令使用,有效提高共享物理寄存器的利用效率。此外,当处理器长时间不使用某一组架构寄存器(浮点或矢量)时,通过搬运的方式可以将存放于共享物理寄存器堆的该类寄存器搬运到对应的独享物理寄存器中,并采用时钟关断等低功耗方式降低该组寄存器的功耗。
附图说明
20.以下结合附图对本发明作进一步说明:图1为重命名表工作机制的示意图;图2为本发明针对risc-v矢量与浮点寄存器的物理寄存器堆分配装置的示意图;图3为本发明flen=vlen=dplen时搬运表项的示意图;图4为本发明2*flen=vlen=dplen时搬运表项的示意图;图5为本发明4*flen=2*dplen=vlen时搬运表项的示意图。
具体实施方式
21.本发明具体实施方式有以下参数设定和条件设定:本发明针对risc-v矢量扩展指令集(vector extension)和risc-v浮点指令集的处理器乱序发射架构进行;本发明中中使用的物理寄存器堆资源为:浮点独享物理寄存器堆表项nfp个,位宽为浮点寄存器的位宽flen,即资源为nfp*flen-bit;矢量独享物理寄存器堆表项nvec个(nfp≥矢量寄存器个数),位宽为矢量寄存器的位宽vlen(也可以看做k个dplen的bank,k*dplen=vlen,dplen为矢量指令实际每次的访问位宽和执行位宽),即资源为nvec*vlen-bit;共享物理寄存器堆的表项为nshare个,位宽为dplen*k,即资源为nshare*dplen*k-bit。本实施方案仅以dplen=vlen,k=1为例;本发明可以同时处理m(m≥1)条指令,同时处理的指令条数并不阻碍本发明的可行性。
22.如图2所示,为本发明一种针对risc-v矢量与浮点寄存器的物理寄存器堆分配装置,包括:(一)译码逻辑对接收到的指令进行译码,获得必要的关键指令信息,至少包括:是否为矢量指令;是否为浮点指令;矢量指令的源操作数和目的寄存器有效信息及索引;浮点指令的源操作数和目的寄存器有效信息及索引。
23.(二)重命名分配控制逻辑、重命名表和物理寄存器堆重命名表记录着架构寄存器和物理寄存器堆之间的映射关系。
24.重命名表包括浮点重命名表和矢量重命名表,浮点重命名表记录浮点架构寄存器与浮点独享物理寄存器堆以及共享物理寄存器堆之间的映射关系,矢量重命名表记录矢量架构寄存器与矢量独享物理寄存器堆以及共享物理寄存器堆之间的映射关系。
25.物理寄存器堆,至少分为三组,一组为浮点独享物理寄存器堆,一组为矢量独享物理寄存器堆,一组为共享物理寄存器堆;其中浮点独享物理寄存器堆只分配给浮点架构寄存器使用,其中矢量独享物理寄存器堆只分配给矢量架构寄存器使用,其中共享物理寄存器可以分配给浮点架构寄存器和矢量架构寄存器使用。
26.重命名分配控制逻辑,根据译码逻辑获得的指令信息,判断是否需要分配物理寄存器堆的表项用于存放指令结果,以及判断所需要分配的对应的物理寄存器堆,并根据寄存器堆分配和释放控制逻辑分配的表项,更新重命名表;并且根据监测返回控制逻辑的反馈,确定是否需要将共享物理寄存器堆的表项数据搬运到独享物理寄存器堆表项中;重命名分配控制逻辑根据源操作数索引访问重命名表,获取源操作数对应的物理寄存器堆索引,并传递给发射逻辑。
27.重命名分配控制逻辑根据指令信息,以及监测返回控制逻辑,做出如下操作:(1)根据源操作数的类型和索引去对应的浮点或者矢量重命名表中获取对应的物理寄存器索引。
28.(2)根据目的寄存器的类型和寄存器堆分配和释放控制逻辑提供的物理寄存器状态信息,决定物理寄存器堆的分配:(2.1)若需要回写浮点寄存器,并且有空闲的浮点独享物理寄存器堆表项,则分配对应的表项,并更新浮点重命名表;(2.2)若需要回写矢量寄存器,并且有空闲的矢量独享物理寄存器堆表项,则分配对应的表项,并更新矢量重命名表;(2.3)若需要回写浮点寄存器,而没有空闲的浮点独享物理寄存器堆表项,或者需要回写矢量寄存器,而没有空闲的矢量独享物理寄存器堆表项,则分配共享物理寄存器堆表项,并更新对应的重命名表。
29.(3)根据监测返回控制逻辑的反馈,确定是否需要将特定的共享物理寄存器堆的表项搬运到特定的独享物理寄存器堆表项中,若同时满足共享物理寄存器堆有不需要被使用到的有效表项,并且独享物理寄存器堆有空闲表项,则根据重命名分配控制逻辑当前状态确定搬运时机:(3.1)搬运时机为若重命名分配控制逻辑当前没有待处理的指令,则直接根据监测返回控制逻辑的反馈分配对应的表项,更新对应的重命名表,并通过指令的形式更新表项;(3.2)搬运时机为若重命名分配控制逻辑当前正在处理矢量指令,而要搬运的为浮点寄存器,则利用空闲的浮点独享物理寄存器堆分配对应的表项,更新浮点重命名表,并通过指令的形式更新表项;(3.3)搬运时机为若重命名分配控制逻辑当前正在处理浮点指令,而要搬运的为矢量寄存器,则利用空闲的矢量独享物理寄存器堆分配对应的表项,更新矢量重命名表,并
通过指令的形式更新表项。
30.(三)发射逻辑根据指令类型和信息完成重命名表查找和更新后,将对应的指令信息和物理寄存器堆索引发送给发射逻辑进行指令的发射,指令发射后同时读取对应的物理寄存器堆表项。
31.(四)执行逻辑指令在发射并读取数据后,发射到执行逻辑执行完毕后,将完成信息和待回写数据反馈给完成和回写逻辑。
32.(五)回写及完成逻辑根据指令之前分配的物理寄存器堆索引信息,将数据回写到对应的物理寄存器堆。同时,将指令的完成信息反馈给寄存器堆分配和释放控制逻辑。
33.(六)寄存器堆分配和释放控制逻辑寄存器堆分配和释放控制逻辑维护着三组不同的物理寄存器堆的状态表,分别记录着每个物理寄存器表示是否被占用以及在哪条指令执行完成后可以释放。根据完成和回写逻辑反馈的指令完成情况,该控制逻辑将释放不再需要被占用的物理寄存器表项。此外,该控制逻辑根据重命名分配控制的分配请求,将空闲的表项进行分配,并更新对应的状态表。
34.(七)监测返回控制逻辑监测返回控制逻辑负责根据三组物理寄存器堆的状态表,以及当前处理器的指令流信息,判断出共享物理寄存器中是否有不再需要使用到的有效数据,以及对应的独享物理寄存器中是否有被释放的表项。若满足上述条件,则将需要搬运的共享物理寄存器表项信息及搬运请求发送给重命名分配控制逻辑。
35.本发明的工作流程如图2所示:译码逻辑接收到指令后,译码得到指令类型、操作数索引信息和目的寄存器索引信息。重命名分配控制逻辑接收到译码信息后,查找对应的浮点重命名表或者矢量重命名表,获取操作数的映射信息返回给发射逻辑,用于从三个物理寄存器堆中读取正确的操作数。同时,重命名分配控制逻辑根据指令类型和目的寄存器索引信息向寄存器堆分配和释放控制逻辑请求分配新的物理寄存器表项。寄存器堆分配和释放控制逻辑根据三组物理寄存器堆的状态表,判断是否有空闲的表项,若有,则将分配的表项信息返回给重命名分配控制逻辑;若无,则需要等待表项释放后进行分配。此时,指令将停留在重命名分配控制逻辑上等待分配完成。在完成分配后,重命名分配控制逻辑会将目的寄存器所分配到的物理寄存器表项信息更新到浮点重命名表或者矢量重命名表,并将该信息发送给发射逻辑。发射逻辑在从三个物理寄存器堆表项中获取操作数后,则根据指令类型发射到对应的浮点执行逻辑或者矢量执行逻辑进行执行。回写及完成逻辑会根据指令分配到的物理寄存器表项信息将执行结果回写到对应的物理寄存器表项中,并将指示指令完成执行的信息反馈给寄存器堆分配和释放控制逻辑,寄存器堆分配和释放逻辑则会更新对应的状态表,并将不需要再被使用到的表项进行释放。在整个过程中,监测返回控制逻辑会实时收集寄存器堆分配和释放控制逻辑中的三组物理寄存器堆的状态表,以及当前的指令流信息,判断是否可以将共享物理寄存器堆中某个有效的表项搬运到浮点或者矢量独享物理寄存器堆的空闲表项中。一旦监测到有可以搬运的表项,监测返回控制逻辑则将搬
运请求和搬运信息发送给重命名分配控制逻辑,重命名分配控制逻辑接收到请求和信息后将更新映射表关系,并指示发射逻辑从对应的物理寄存器堆表项中以读取操作数的形式将数据读出,并通过回写及完成逻辑回写到需要搬运到的独享物理寄存器堆中。
36.以图3所示的映射表为例,当处理器首先执行一段浮点程序时,每条浮点指令被译码逻辑译码出对应的浮点源操作数索引和浮点目的寄存器索引,重命名分配控制逻辑根据浮点源操作数索引访问重命名表,获取源操作数对应的物理寄存器堆索引并传递给发射逻辑进行后续的数据获取,并分配空闲的浮点独享物理寄存器堆表项给对应的浮点目的寄存器。随着指令的执行,越来越多的浮点独享物理寄存器堆表项被分配。当浮点独享物理寄存器堆表项有限且释放速度较慢时,则会出现浮点独享物理寄存器堆表项全部分配完而没有空闲表项。此时重命名分配控制逻辑监测到浮点独享寄存器堆表项已满,则会将新指令的所需要回写的浮点目的寄存器映射到共享物理寄存器堆上。因此,当一段程序的所有浮点指令执行完毕后,一部分浮点架构寄存器映射到了浮点独享物理寄存器堆表项(即图3中浮点独享物理寄存器表项中标斜线的方块),而一部分浮点架构寄存器映射到了共享寄存器堆表项(即图3中共享物理寄存器表项中标斜线的方块),而一部分释放较慢的浮点独享物理寄存器堆表项也因为浮点程序的执行完毕,而最终被释放(即图3中浮点独享物理寄存器表项中标全白色的方块)。
37.此时若处理器开始处理一段矢量程序,类似于浮点程序,经过一段时间的执行,越来越多的矢量独享物理寄存器堆表项被分配。当矢量独享物理寄存器堆表项有限且释放速度较慢时,则会出现矢量独享物理寄存器堆表项全部分配完而没有空闲表项(即图3中矢量独享物理寄存器表项中标灰色的方块)。因此随着矢量程序的继续执行,重命名分配控制逻辑会将译码逻辑所译出的矢量目的寄存器分配到共享物理寄存器堆表项中,并且可能会分配越来越多的共享物理寄存器堆来发挥乱序性能。此时若浮点架构寄存器仍然占据着共享物理寄存器堆(即图3中共享物理寄存器表项中标斜线的方块),则会导致矢量寄存器无法充分利用共享物理寄存器堆资源而影响性能。然而,由于处理器在执行大量的矢量程序,浮点架构寄存器处于静止状态(无新的分配和释放需求)。因此此时监测返回控制逻辑会监测共享物理寄存器堆的表项中是否有不需要被使用的有效表项(即图3中共享物理寄存器表项中标斜线的方块),若有的话,则判断表项中映射的是浮点架构寄存器或者矢量架构寄存器,若为浮点架构寄存器,则进一步监测判断浮点独享物理寄存器堆是否有空闲的表项,若有的话则将浮点架构寄存器的数据从共享物理寄存器堆表项搬运到浮点独享物理寄存器一个空闲的表项中(如图3中箭头所示),并将映射关系进行更改。同样的,若判断为矢量架构寄存器,则进一步监测判断矢量独享物理寄存器堆表项中是否有空闲的表项,若有则进行类似的搬运和映射关系更改。
38.通过这种检测搬运的方式,释放了共享物理寄存器资源,让正在执行的矢量(或者浮点)程序有更加充分的物理寄存器堆资源可以使用,从而提高了资源的利用效率,且由于浮点(或者矢量)专用寄存器堆写口的空闲,因此也不会与程序正在执行的指令产生回写口冲突而影响正常程序的运行。
39.需要注意的是,由于矢量寄存器的位宽和浮点寄存器的位宽均是可配的,因此其各自的独享物理寄存器堆的表项宽度也不一定相同,共享物理寄存器堆的表项也可以不和两者相同,下面列举了几种情况,均是可行的。
40.(1)flen=vlen=dplen,此时最简单的方案就是将三组物理寄存器堆设置成一样位宽,采用最直接的一一映射关系,如图3所示。此时矢量架构寄存器的长度和浮点架构寄存器的长度相等,因此三种类型的物理寄存器堆表项在映射时都是一个物理寄存器表项对应着一个架构寄存器。
41.(2)2*flen=vlen=dplen,此时可以按照flen来配置浮点独享物理寄存器堆位宽,按照vlen来配置矢量独享物理寄存器堆位宽和共享物理寄存器堆位宽,如图4所示。一个浮点架构寄存器可以映射到一个浮点独享物理寄存器表项中,也可以映射到一个共享物理寄存器堆表项的高半部分或者低半部分,如图中标斜线的方块所示;而一个矢量架构寄存器可以映射到一个矢量独享物理寄存器堆表项中,也可以映射到一个共享物理寄存器堆表项中,如图中标灰色的方块所示。这种方式的好处是,尽管矢量架构寄存器由于vlen较大,占据了更宽的共享物理寄存器堆资源,但是由于一个共享物理寄存器堆可以映射两个浮点架构寄存器堆,相当于在执行浮点程序时拥有了2倍的物理寄存器堆表项资源可以使用,相比于将该资源给矢量架构寄存器独享,共享的方式更好的提升了资源的利用效率。
42.(3)4*flen=2*dplen=vlen,此时矢量寄存器的位宽vlen较宽,但通常每个vlen位宽的矢量寄存器都会分成两个块(bank),bank0和bank1,每个bank的位宽为dplen。矢量指令也会拆分成两条微指令,分别访问bank0和bank1的dplen位宽的数据。重命名表也以bank为单位对矢量架构寄存器和物理寄存器堆进行映射,因此将矢量架构寄存器映射到矢量独享物理寄存器与共享物理寄存器均以bank的方式来进行,共享物理寄存器堆bank1和矢量独享物理寄存器bank1对应只分配给矢量架构寄存器的bank1进行映射,共享物理寄存器堆bank0和矢量独享物理寄存器bank0对应只分配给矢量架构寄存器的bank0进行映射。而共享物理寄存器堆可以充分分配给浮点寄存器使用,例如共享物理寄存器堆的bank0和bank1都可以映射到两个浮点架构寄存器,如图5所示。
43.此外,为了尽可能的充分利用共享物理寄存器,应推荐将浮点独享物理寄存器堆表项个数设置为32,以保证所有32个浮点寄存器均可放置于此,在处理大量矢量指令的时候能够使所有的浮点架构寄存器都映射到浮点独享物理寄存器堆上,使得矢量架构寄存器可以充分使用共享物理寄存器;将矢量独享物理寄存器堆表项个数设置为32,以保证所有32个矢量寄存器均可放置于此,在处理大浮点量指令的时候能够使其充分使用共享物理寄存器;共享物理寄存器的表项个数则可以根据处理器的性能需求进行设置。
44.以上仅为本发明较佳实施例,但本发明的保护范围并不局限于此。任何以本发明为基础,对本发明相应技术特征以基本相同的手段,实现基本相同的功能,达到基本相同的效果,并且本领域普通技术人员在被诉侵权行为发生时无需经过创造性劳动就能联想到的特征进行替换,皆涵盖于本发明的保护范围之中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。