1.本发明属于计算机科学的机器学习领域,尤其涉及一种基于特征形态和数据关系的数据特征构建系统和方法。
背景技术:
2.近年来,机器学习广泛应用于企业中业务的预测和辅助,利用机器学习中的特征构建可以给预测模型提供关键信息,提高模型泛化能力、解决模型解释能力不足的情况。在预测模型构建过程中,需要不断的构建不同的特征验证、提升模型的性能。数据特征的选择会直接影响预测模型的预测结果。面对复杂多变的业务场景,如果都需要业务经验丰富的业务专家人工设计特征,无论是时间成本还是设计难度,都很难得到保证,所以需要自动化的特征构造技术,进而降低开发运维人员的学习成本、降低业务专家的专业知识要求、降低模型构造的时间成本。
3.由此,出现了很多特征工程框架,有对原始数据不同类型的特征进行简单的处理的,有对原始特征进行筛选过滤的,也有基于单个特征的特性构建出新的特征,在这些框架中,新创造的特征会作为模型的训练数据,进行模型训练和评估。
4.但是,现有的技术中,特征构建方案大都采用基于单个实体数据表进行分析,对每个单独的特征进行预处理,业务专家根据业务在这个数据表中对特征进行加工,创造出全新的特征,这种特征构建方案没有考虑到特征之间的关联性和数据表之间的关联性,构建出来的特征信息浓度较低。再者,每次任务把不同的特征输入到训练算法进行模型的训练,然后根据评估指标评估特征的性能,如果不满足业务,业务专家需要重新去根据经验构建全新的特征,如此循环,直到模型的性能满足业务需求。通常这需要业务专家花费大量的时间去分析原始数据,思考问题的潜在形式和数据结构,根据已有的业务经验并基于自己对数据敏感性和机器学习实战经验进行特征构建。整个过程需要开发人员和业务专家的全程人工介入且耗时巨大,特征的多样性无法提取,适应的范围也不够灵活,只能适用特定领域,影响整个业务的发展。所以,现在需要一种能考虑到数据之间关联性和特征之间关联性,并且能根据关联关系快速自动地构建新特征的特征构建方法,来提高特征的信息浓度,满足业务的多样性。
技术实现要素:
5.鉴于上述的分析,本发明旨在提供一种基于特征形态和数据关系的数据特征构建系统和方法,基于数据之间的关联性构建dag执行聚合图,基于不同特征形态根据数据特征的统计值构建衍生的数据特征,然后根据dag执行聚合图对数据特征进行聚合操作,再进行过滤和降维处理,提高了特征的信息浓度,提升了数据特征构建的效率。
6.一方面,本发明提供了一种基于特征形态和数据关系的数据特征构建的系统,包括:
7.数据特征深度分析模块,用于分析待处理数据集中所有数据库表得到dag执行聚
合图、数据特征统计值和数据特征形态;
8.数据特征预处理模块,用于基于数据特征统计值和数据特征形态,对待处理数据集中的数据进行清洗和预处理,得到处理后数据集;
9.数据特征转换构建模块,用于基于数据特征形态,对处理后数据集中每个数据库表的原始特征进行特征转换构建得到相对应的的衍生特征,并整合每个数据库表的原始特征和衍生特征,得到转换后特征集;
10.数据特征深度聚合模块,用于基于所述dag执行聚合图对转换后特征集进行聚合操作,得到聚合后特征集;
11.数据特征过滤模块,用于过滤聚合后特征集得到优选特征组合;
12.数据特征降维模块,用于对所述优选特征组合进行降维处理,得到降维后的最优特征组合。
13.进一步的,所述分析待处理数据集中所有数据库表得到dag执行聚合图包括,基于所述数据库表的主键和外键得到用树结构表示的各数据库表间的关联关系,使用递归树算法从树的叶子结点开始进行递归遍历,得到所述dag执行聚合图,所述dag执行聚合图用于表示特征聚合的执行顺序、执行方向、能否并行执行以及特征的层级关系。
14.进一步的,所述基于所述dag执行聚合图对转换后特征集进行聚合操作包括,基于所述dag执行聚合图,从图的开始节点按照图所示的执行顺序、执行方向、能否并行执行以及特征的层级关系进行数据特征聚合,基于每个节点的下层节点的数据特征构建新特征聚合到该节点对应的特征集,对所有层级的节点对应的特征依次迭代聚合,得到聚合后特征集。
15.进一步的,所述数据特征形态包括文本特征、数值特征、时间特征。
16.进一步的,所述预处理包括对文本特征、数值特征、时间特征分别进行预处理,其中,
17.对文本特征预处理包括:对文本特征中的原始短文本进行编码操作得到第一文本编码;对长文本进行分词处理得到分词短文本,对长文本进行文本分析得到文本分析结果;基于文本分析结果选择需要保留的分词短文本,对其进行编码操作得到第二文本编码;将第一文本编码和第二文本编码汇总得到文本编码;
18.对数值特征预处理包括:对数值特征进行标准化处理,并进行编码得到数值特征编码;
19.对时间特征预处理包括:对时间特征进行统一时间格式处理,得到统一格式的时间特征。
20.进一步的,所述基于数据特征形态,对处理后数据集中每个数据库表的原始特征进行特征转换构建得到相对应的衍生特征包括:
21.对数据集中每个数据库表中的文本特征,统计文本中字符数量和单词数量分别作为新特征;
22.对数据集中每个数据库表中的数值特征进行数学计算,包括两两相加、两两相减、两两相乘、两两求模以及对数值特征取负数、对数值特征取绝对值,将计算结果分别作为新特征;
23.对数据集中每个数据库表中的时间特征按照时间单位拆分,得到对应的年、月、
周、日、小时、分钟、秒分别作为新的特征,计算时间特征和上一时间特征的时间差作为新的特征。
24.进一步的,所述数据特征过滤模块,用于执行下述流程过滤聚合后特征集得到优选特征组合:
25.使用排序法基于特征相关系数对特征排序,根据阈值过滤特征得到第一优选特征组;所述特征相关系数包括使用皮尔斯相关算法和方差分析算法计算特征间相关性得到的相关系数;
26.使用包装法基于预设的训练模型算法对第一优选特征组中不同的特征子集进行训练,选取训练准确率最优的特征子集作为第二优选特征组;
27.使用嵌入法对第二优选特征组进行过滤得到优选特征组,包括:使用决策树和/或随机森林模型,对第二优选特征组进行训练,得到训练好的模型和所有特征的权值系数,基于权值系数对特征进行排序,根据预设阈值选取排序靠前的特征的集合作为优选特征组。
28.进一步的,所述降维算法包括主成分分析法和/或线性判别式分析法。
29.进一步的,所述数据清洗包括基于所述数据特征统计值对所述待处理数据集中的数据的缺失值和异常值进行数据清洗。
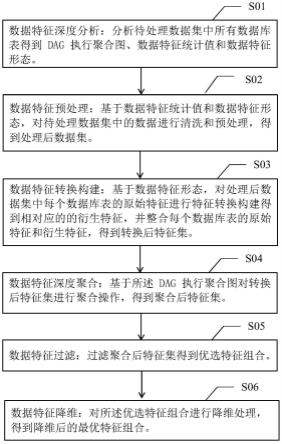
30.另一方面,本发明还提供了一种基于特征形态和数据关系的数据特征构建的方法,具体包括以下步骤:
31.数据特征深度分析,包括分析待处理数据集中所有数据库表得到dag执行聚合图、数据特征统计值和数据特征形态;
32.数据特征预处理,包括基于数据特征统计值和数据特征形态,对待处理数据集中的数据进行清洗和预处理,得到处理后数据集;
33.数据特征转换构建,包括基于数据特征形态,对处理后数据集中每个数据库表的原始特征进行特征转换构建得到相对应的的衍生特征,并整合每个数据库表的原始特征和衍生特征,得到转换后特征集;
34.数据特征深度聚合,包括基于所述dag执行聚合图对转换后特征集进行聚合操作,得到聚合后特征集;
35.数据特征过滤,包括过滤聚合后特征集得到优选特征组合;
36.数据特征降维,包括对所述优选特征组合进行降维处理,得到降维后的最优特征组合。
37.本发明至少可以实现下述之一的有益效果:
38.1、通过分析数据之间的关联性,基于关联性构建dag执行聚合图,根据dag执行聚合图对数据特征进行聚合操作,对聚合后特征集进行过滤处理和降维处理,提高了特征的信息浓度,提升了数据特征构建的效率。
39.2、通过对原始数据特征进行各种规则的统计,得到多种统计值,用所述统计值构建衍生的数据特征,满足数据对业务多样性的适应,降低了对业务专家的专业知识要求,进而降低开发运维人员的学习成本。
40.本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书、权利要求书以及附图中所特别指出的内容中来实现和获得。
附图说明
41.附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
42.图1为本发明方法实施例流程示意图;
43.图2为本发明系统实施例中对文本特征构建衍生特征的示意图;
44.图3为本发明系统实施例中对数值特征构建衍生特征的示意图;
45.图4为本发明系统实施例中对时间特征构建衍生特征的示意图。
具体实施方式
46.下面结合附图来具体描述本发明的优选实施例,其中,附图构成本技术一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
47.系统实施例
48.本发明的一个具体实施例,公开了一种基于特征形态和数据关系的数据特征构建系统,包括数据特征深度分析模块、数据特征预处理模块、数据特征转换构建模块、数据特征深度聚合模块、数据特征过滤模块、数据特征降维模块。
49.数据特征深度分析模块:用于分析待处理数据集中所有数据库表得到dag执行聚合图、数据特征统计值和数据特征形态。
50.具体的,数据特征深度分析模块通过连接需要进行特征分析的多个数据库读取对应的数据库表信息,所有数据库表的集合即待处理数据集。
51.具体的,所述分析待处理数据集中所有数据库表得到dag执行聚合图包括,基于所述数据库表的主键和外键得到用树结构表示的各数据库表间的关联关系,包括一对一、一对多、多对多,然后使用递归树算法从树的叶子结点开始进行递归遍历,得到所述dag执行聚合图,所述dag执行聚合图用于表示特征聚合的执行顺序、执行方向、能否并行执行以及特征的层级关系。
52.具体的,所述分析待处理数据集中所有数据库表得到数据特征统计值包括对数据库表进行遍历,得到数据库表每个特征列特征的众数、平均数。
53.具体的,所述数据特征形态包括文本特征、数值特征、时间特征。
54.数据特征预处理模块:用于基于数据特征统计值和数据特征形态,对待处理数据集中的数据进行清洗和预处理,得到处理后数据集。
55.具体的,所述数据清洗包括基于所述数据特征统计值对所述待处理数据集中的数据的缺失值和异常值进行数据清洗。
56.具体的,对于每个数据库表,检查文本特征和时间特征的缺失值,使用特征所在特征列的众数进行填充。
57.具体的,对于每个数据库表,检查数值特征中的缺失值和异常值:使用该特征所在特征列的平均值进行缺失值填充;使用0-1标准化算法判断数值特征是否存在异常值,对于存在的异常值,使用该特征坐在特征列的平均值进行替换。
58.具体的,所述数据预处理包括对文本特征、数值特征、时间特征分别进行预处理,其中,
59.对文本特征预处理包括:对文本特征中的原始短文本进行编码操作得到第一文本
编码;对于长文本进行分词处理得到分词短文本,对长文本进行文本分析得到文本分析结果;基于文本分析结果选择需要保留的分词短文本,并对其进行编码操作得到第二文本编码;将第一文本编码和第二文本编码汇总得到文本编码;其中的编码指将文本特征数字化;可选的,使用独热编码(one-hot编码)对文本特征进行编码。
60.对数值特征预处理包括:对数值特征进行标准化处理,并进行编码得到数值特征编码;标准化处理指将不同量纲或数量级的数据进处理后,得到统一数量级水平的数据以便于比较和分析;可选的,使用0-1标准化、min-max标准化对数值特征进行标准化处理。
61.对时间特征预处理包括:对时间特征进行统一时间格式处理,得到统一格式的时间特征。
62.数据特征转换构建模块:用于基于数据特征形态,对处理后数据集中每个数据库表的原始特征进行特征转换构建得到相对应的的衍生特征,并整合每个数据库表的原始特征和衍生特征,得到转换后特征集;
63.所述基于数据特征形态,对处理后数据集中每个数据库表的原始特征进行特征转换构建得到相对应的衍生特征,针对该数据库表构建出新的特征,得到转换后特征集包括:
64.对数据集中每个数据库表中的文本特征,统计文本中字符数量和单词数量构建新特征得到衍生特征;示例性的,如图2所示,对原始文本特征统计字符数量和单词数量,得到衍生特征;
65.对数据集中每个数据库表中的数值特征进行数学计算,包括两两相加、两两相减、两两相乘、两两求模以及对数值特征取负数、对数值特征取绝对值,将计算结果分别构建作为衍生特征;示例性的,如图3所示,对原始数值特征进行取绝对值、两两相乘、两两相除计算得到如图所示的衍生特征。
66.对数据集中每个数据库表中的时间特征进行时间按照时间单位拆分,得到对应的年、月、周、日、小时、分钟、秒分别作为新的特征,计算时间特征和上一时间特征的时间差并构建新特征,得到转换后特征集作为新的特征;示例性的,如图4所示,对原始时间特征按时间单位拆分、计算时间特征和上一时间特征实例的时间差得到如图所示的衍生特征。
67.数据特征深度聚合模块:用于基于所述dag执行聚合图对转换后特征集进行聚合操作,得到聚合后特征集。
68.具体的,所述基于所述dag执行聚合图对转换后特征集进行聚合操作包括,基于所述dag执行聚合图,从图的开始节点按照图所示的执行顺序、执行方向、能否并行执行以及特征的层级关系进行数据特征聚合;基于每个节点的下层节点的数据特征构建新特征聚合到该节点对应的特征集,对所有层级的节点对应的特征依次迭代聚合,直到dag图的尾端节点,得到聚合后特征集。
69.具体的,对于文本特征,基于每个节点的下层节点的数据特征构建新特征包括:将下层节点中每一特征列的特征数、众数值、条件全部满足、条件任一满足、首个特征值、末尾特征值、特征枚举值构建为新特征;所述特征数指下层节点中统一特征列中特征的总数,所述众数值指同一特征列中同一特征值重复出现的数量,所述条件同一特征列中全部满足指满足预设条件的特征数,所述条件任意满足指同一特征列中满足预设条件之一的特征数,所述首个特征值指同一特征列中的首个特征值,所述末尾特征值指同一特征列中的末个特征值,所述特征枚举值指同一特征列中出现的不同特征值。
70.具体的,对于数值特征,基于每个节点的下层节点的数据特征构建新特征包括:对下层节点中每一特征列的数值特征进行统计计算,包括每一特征列中数值特征的计数、总和、平均值、最大值、最小值、标准差、峰度、偏度、中值、众数、条件全部满足、条件任一满足和唯一值数量,将上述结算结果构建为新特征。
71.具体的,对于时间特征,基于每个节点的下层节点的数据特征构建新特征包括:对下层节点中每一特征列的时间特征进行统计计算,得到数值线性趋势、平均时间、自最早时间距离现在多久、自最迟时间距离现在多久,将上述结果构建为新的特征
72.数据特征过滤模块:用于过滤聚合后特征集得到优选特征组合。
73.具体的,执行下述流程过滤聚合后特征集得到优选特征组合:
74.使用排序法基于特征相关系数对特征排序,根据阈值过滤特征得到第一优选特征组;所述特征相关系数包括使用皮尔斯相关算法和方差分析算法计算特征间相关性得到的相关系数;其中的阈值指预设的特征相关系数阈值。
75.使用包装法基于预设的训练模型算法对第一优选特征组中不同的特征子集进行训练,选取训练准确率最优的特征子集作为第二优选特征组;所述预设的训练模型算法由用户从系统内置的模型算法中选择确定,可选的,算法包括逻辑回归、朴素贝叶斯、决策树、随机森林;进行训练是使用预设的算法对第一优选特征组所有可能的子集进行训练,并对训练结果进行准确率评分的过程。
76.使用嵌入法对第二优选特征组进行过滤得到优选特征组,包括:使用决策树和/或随机森林模型,对第二优选特征组进行训练,得到对预设的模型进行训练得到训练好的模型和所有特征的权值系数,基于权值系数对特征进行排序,排序后的特征组,根据预设阈值选取排序靠前的特征组的集合作为优选特征组。
77.数据特征降维模块:用于对所述优选特征组合进行降维处理,得到降维后的最优特征组合。
78.具体的,所述降维算法包括主成分分析法和/或线性判别式分析法。
79.所述主成分分析法(pca)包括:寻找所述优选特征组合的主轴方向,由主轴构成一个新的坐标系,新坐标系的维数低于所述优选特征组合的维数,将所述优选特征组合向新坐标系投影,得到降维后的最优特征组合。
80.所述线性判别式分析法(lda)包括:将所述优选特征组合投影到最佳鉴别矢量空间进行抽取分类信息和压缩特征空间维数,得到降维后的最优特征组合。
81.方法实施例
82.一种基于特征形态和数据关系的数据特征构建方法,其特征在于,包括如下步骤:
83.步骤s01、数据特征深度分析,包括分析待处理数据集中所有数据库表得到dag执行聚合图、数据特征统计值和数据特征形态;
84.步骤s02、数据特征预处理,包括基于数据特征统计值和数据特征形态,对待处理数据集中的数据进行清洗和预处理,得到处理后数据集;
85.步骤s03、数据特征转换构建,包括基于数据特征形态,对处理后数据集中每个数据库表的原始特征进行特征转换构建得到相对应的的衍生特征,并整合每个数据库表的原始特征和衍生特征,得到转换后特征集;
86.步骤s04、数据特征深度聚合,包括基于所述dag执行聚合图对转换后特征集进行
聚合操作,得到聚合后特征集;
87.步骤s05、数据特征过滤,包括过滤聚合后特征集得到优选特征组合;
88.步骤s06、数据特征降维,包括对所述优选特征组合进行降维处理,得到降维后的最优特征组合。
89.需要说明的是,上述实施例基于相同的发明构思,未重复描述之处,可相互借鉴。
90.相比于现有技术,本实施例提供的基于特征形态和数据关系的数据特征构建方法,有益效果与实施例基于特征形态和数据关系的数据特征构建系统提供的有益效果基本相同,在此不一一赘述。
91.以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。