技术特征:
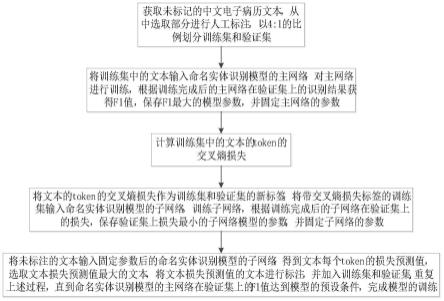
1.一种基于主动学习的中文电子病历命名实体识别方法,其特征在于,包括:将待识别的中文电子病历文本输入训练好的命名实体识别模型的主网络进行识别,并得到识别结果;所述命名实体识别模型包括:主网络和子网络;所述命名实体识别模型的训练过程包括:s1:获取未标记的中文电子病历文本,从中选取部分进行人工标注,以4:1的比例划分训练集和验证集;s2:将训练集中的文本输入命名实体识别模型的主网络,对主网络进行训练,根据训练完成后的主网络在验证集上的识别结果获得f1值,保存f1最大的模型参数,并固定主网络的参数;s3:计算训练集中的文本的token的交叉熵损失;s4:将文本的token的交叉熵损失作为训练集和验证集的新标签,将带交叉熵损失标签的训练集输入命名实体识别模型的子网络,训练子网络,根据训练完成后的子网络在验证集上的损失,保存验证集上损失最小的子网络模型的参数,并固定子网络的参数;s5:将未标注的文本输入固定参数后的命名实体识别模型的子网络,得到文本每个token的损失预测值,选取文本损失预测值最大的文本,将文本损失预测值的文本进行标注,并加入训练集和验证集,重复上述过程,直到命名实体识别模型的主网络在验证集上的f1值达到模型的预设条件,完成模型的训练。2.根据权利要求1所述的一种基于主动学习的中文电子病历命名实体识别方法,其特征在于,将待识别的中文电子病历文本输入训练好的命名实体识别模型进行识别,得到识别结果,具体包括:步骤一:将待识别的中文电子病历文本进行文本划分,得到文本长度小于等于256,若文本长度小于256的序列用padding的方式补齐;步骤二:将划分好的文本进行词编码(token embedding)、句子编码(sentence embedding)、位置编码(position embedding);步骤三:将编码后的文本输入到命名实体识别模型中,得到命名实体识别模型主网络的输出,进行维特比解码,得到最终识别结果。3.根据权利要求1所述的一种基于主动学习的中文电子病历命名实体识别方法,其特征在于,所述命名实体识别模型主网络结构为bert bilstm crf,所述子网络结构为bert bilstm linear,其中bert lstm的权重与主网络共享。4.根据权利要求1所述的一种基于主动学习的中文电子病历命名实体识别方法,其特征在于,对主网络进行训练,具体包括:将训练集中的文本输入主网络的bert层进行文本划分,将划分后的文本通过bilstm层进行编码处理,得到文本中每个单词的编码向量,将文本中每个单词的编码向量输入crf层,得到文本中所有单词对应的预测标签,并计算文本中所有单词的预测标签得分,根据预测标签得分采用softmax计算正确标签文本的概率,并最大化正确标签文本的概率,根据最大化后的正确标签文本的概率解码文本中每个单词的编码向量,得到最优的文本序列,将输出最优序列下的主网络作为训练得到的最优主网络。5.根据权利要求4所述的一种基于主动学习的中文电子病历命名实体识别方法,其特
征在于,计算文本中单词的预测标签得分,表示为:其中,s(x,y)表示文本中单词的预测标签得分,x表示文本序列,y表示预测的标签序列,n为序列长度,表示输入序列中第i个字符预测为第y
i
个标签得分,a表示转移矩阵。6.根据权利要求4所述的一种基于主动学习的中文电子病历命名实体识别方法,其特征在于,根据预测标签得分采用softmax计算正确标签文本的概率,并最大化正确标签文本的概率,表示为:其中,p(y|x)表示正确标签文本的概率,s(x,y)表示示文本中单词的预测标签得分,s(x,y
~
)表示正确标签得分,表示所有可能标签得分指数和,x表示文本序列,y表示预测的标签序列,y
x
表示所有可能的标签序列集合,y
~
表示所有可能的标签序列集合中的标签序列。7.根据权利要求1所述的一种基于主动学习的中文电子病历命名实体识别方法,其特征在于,根据训练完成后的主网络在验证集上的识别结果获得f1值,表示为:其中,c表示实体类别总数,f
1k
表示第k个实体的f1值。8.根据权利要求1所述的一种基于主动学习的中文电子病历命名实体识别方法,其特征在于,计算文本的token的交叉熵损失,表示为:其中,t
i
为一个样本中第i个token的交叉熵损失,y
ij
表示第i个token是否属于第j类,若是则为1,不是则等于0,q
ij
表示第i个token属于第j个类别的概率,p表示bilstm的输出矩阵,c为标签数量,p
i,j
表示bilstm在第i个token的第j个维度上的输出,e表示自然底数。9.根据权利要求1所述的一种基于主动学习的中文电子病历命名实体识别方法,其特征在于,子网络的训练,表示为:其中,l
sub
表示子网络的损失,s表示句子长度,b表示一个训练batch的大小,t
ij
表示一个batch中第j个样本中第i个token的交叉熵损失,表示子网络对一个batch中第j个样
本中第i个token损失的预测值。
技术总结
本发明属于文本标注领域,具体涉及一种基于主动学习的中文电子病历命名实体识别方法,包括:获取已标记实体的初始训练集和未标记实体的待打标数据;以该训练集,训练基于深度学习的命名实体识别模型,得到中间命名实体识别模型,该中间命名实体识别模型评估该未标记数据中每个实例的价值,将该未标记数据中价值最高的实例进行命名实体标注后加入该训练集;重复训练直到满足预设条件,将待命名实体识别的文本数据输入该最终命名实体识别模型,得到命名实体识别结果。本发明通过让模型预测自己的损失,从而找到能让自己改变最大的样本,满足了中文电子病历这一场景下对于句子级的命名实体识别准确率的高要求,提高了识别的准确率。率。率。
技术研发人员:雷大江 卢文糠 王烨 于洪 王国胤
受保护的技术使用者:重庆邮电大学
技术研发日:2022.09.09
技术公布日:2022/12/5
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。