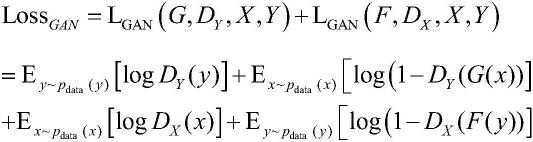
基于ct图像跨模态迁移学习的肾脏超声图像分割方法
技术领域
1.本发明属于医学影像处理技术领域,更具体地,涉及一种基于电子计算机断层扫描图像(ct图像)跨模态迁移学习的肾脏超声图像分割训练方法。
背景技术:
2.超声成像因其安全、实时、低廉的获取特点,已被广泛应用于各种急性和慢性肾病筛查、诊断和预后,包括肾结石、肾癌、慢性肾病、儿童先天性肾脏及尿路畸形等各种肾脏疾病。在临床各种肾病诊断与评估中,肾脏超声图像分割具有重要的意义,主要用于:1.评估肾脏参数,即其大小和体积,以诊断潜在的疾病;2.评估肾脏形态和功能;3.定位肾脏中存在的异常或病理区域;4.辅助治疗/介入计划的实施决策以及实施过程;5.肾癌等介入治疗后的术后随访。准确快速的肾脏区域分割是从超声图像中提取肾脏疾病诊断信息的保证,也是进行定量分析和实时监控中精确定位的重要环节。然而目前超声图像中的肾脏区域基本仍然通过专业超声科医生在图像采集过程中针对不同切面动态图像手动提取。手动提取特征需要耗费专业超声科医生大量时间和精力,并且需要观察者之间具有适度的可靠性。目前我国专业超声科医生缺口巨大,任务繁重。随着计算机技术尤其是人工智能(artificial intelligence,ai)的高速发展,通过ai辅助肾脏超声图像诊断已经成为必然趋势。肾脏超声图像分割算法是ai辅助肾病精准诊断与治疗中关键步骤,分割的输出结果可以辅助医生或者下一步的分类算法进行临床解剖特征提取与诊断评估。准确快速的肾脏超声图像分割算法不仅可以有效的降低肾脏疾病诊疗成本,还可以辅助筛查诊断提高各种肾脏疾病知晓率,尤其对于一些缺少高水平专家的基层医疗机构尤其具有重要意义。
3.近几年深度学习算法已成功应用到一系列超声图像自动分析任务中,例如病变/结节分类、器官分割和物体检测等,并取得了关键性突破。作为一种表示学习方法,深度学习可以直接从所获取的原始数据中自动学习中级和高级的抽象特征,为基于超声图像的肾脏疾病计算机辅助诊断技术研究提供了新思路。尤其是基于深度学习的语义分割网络在自然图像以及医学图像自动分割任务中取得了突破性进展,并在肾脏超声图像自动分割任务中显示出了巨大的潜力。然而,在任意视角各种尺度下的二维超声断面扫查策略要求训练的肾脏超声图像分割网络具有非常强的泛化能力。在训练分割网络的肾脏超声图像像素级标注工作中,医生通常只能手动标注几张代表性的断面图作为标签。现有工作主要是采用基于自然图像尤其是imagenet数据集上的迁移学习作为预训练策略,然而这种方法的问题均在于自然图像与真实超声图像扫描之间在成像方式上仍存在较大的差异性,使得训练的网络很难完全适应复杂多变的真实超声器官图像数据。或利用数据增强策略包括空间变换、加入随机噪声以及生成对抗网络等方式生成的模拟超声数据加入网络训练中防止过拟合,然而该方法仍需要大量的手工标注标签。
4.综上所述,小样本标注与泛化能力高要求的矛盾问题在肾脏超声图像分割任务中尤为突出。因此如何提高小样本标注下的肾脏超声图像分割网络的准确度与鲁棒性,成为研究中亟需解决的问题。
技术实现要素:
5.本发明通过充分挖掘并利用三维ct图像能够从不同方向切片出大量二维的ct图像,再通过风格迁移网络生成模拟超声图像,而后进行分割网络训练。本发明解决了分割网络训练过程中带标签的真实超声数据集较小所导致的有效信息不足问题,可以降低人工标注的成本;解决肾脏分割模型训练的过拟合问题,从而提高分割准确度。此外,本发明提供了一种分割网络训练策略,可以有效提高分割准确度和泛化性。
6.针对现有技术的以上缺陷或改进需求,本发明提供了一种基于ct图像跨模态迁移学习的肾脏超声图像分割方法,其目的在于使用风格迁移网络(例如cyclegan)充分利用已有的带标签的ct生成大量模拟超声图像,以解决现有技术分割质量不佳和模型缺乏迁移泛化性等问题,同时降低人工标注成本。
7.本发明为了解决上述技术问题采用以下技术方案:本发明设计了一种基于ct图像跨模态迁移学习的肾脏超声图像分割方法。本发明流程大致可以分为两个阶段,阶段一是由大量的三维ct数据集生成大量的模拟超声数据集,阶段二是语义分割模型训练策略流程。阶段一包括步骤1、2、3,阶段二包括步骤4。以下详细说明流程细节:
8.通过步骤1、2(ct图像预处理获得大量、多角度肾脏ct图(2d);通过步骤3,应用风格迁移网络,生成模拟肾脏超声图;通过步骤4应用语义分割模型训练,实现真实肾脏超声图像的风格。最后对分割结果进行测试,以验证本发明的有效性。
9.步骤1.每一张三维ct图都有一个对应三维标签图,通过标签图确定切割的点的坐标后以此坐标同时对ct图和标签图进行切割,能够保证切割完后的二维ct图和二维标签图一一对应。基于预设数量三维肾脏ct样本图像(原始图)、以及与各三维肾脏ct样本图像分别对应区分图像中肾脏区域的二值化三维肾脏ct样本图像(标签图),确定出旋转切割定点。由于三维肾脏ct原始图像与三维肾脏ct标签图像有相同的空间结构,该点同样可以作为三维肾脏ct原始图像的旋转切割定点,完成此步骤后进入步骤2。三维ct图及其标签出自kits19数据集。相较于常用的切割三维ct图像的方法:从轴向、冠状和矢状方向切割获取二维ct图像,旋转切割有以下优点:1.样本更加丰富,切割方向远大于3个方向;2尽量保留了原三维ct图像的形态,从轴向、冠状和矢状方向切割后导致肾脏从无到小再到大再到小。
10.步骤2.基于步骤1中的旋转切割定点,建立空间直角坐标系,分别将三个相互垂直的平面为切面并旋转得到ct断层图像,包括ct原始图和ct标签图。以此实现,大量二维ct数据集的获取,对二维ct数据集和肾脏us数据集进行预处理。进入步骤3。
11.步骤3.基于二维ct数据集和肾脏us数据集,采用风格迁移网络,采取适当的训练策略,训练二维ct数据集,即可实现大量模拟超声图(带标签)的获取。获取预计量的模拟超声数据集后,进入步骤4。步骤4.利用模拟肾脏超声图像和真实肾脏超声图像构建训练集,训练语义分割模型,利用训练好的语义分割模型对肾脏超声图像进行图像分割。
12.作为本发明的一种优选技术方案:步骤3中,实际应用的过程中,医生会采集同一个个体的肾脏ct图像和肾脏us图像,所得到的二维ct图像和us图像形态上具有相同的医学结构,将它们作为训练集,会有更好的训练效果。
13.作为本发明的一种优选技术方案:风格迁移网络训练之前对参与训练数据集进行预处理:对二维ct图像和真实超声图像进行roi处理,以提取出肾脏区域。二维ct图像roi处理是通过与之对应的标签确定肾脏的中心,再以肾脏的中心点作为一定大小矩形框的中心
点提取出肾脏区域。真实超声图像的roi处理是人工大致标注出肾脏区域,无须精确,可以是矩形区域,并以此确定中心点,采用矩形框提取出一定大小的肾脏区域。
14.作为本发明的一种优选技术方案:步骤3中,为了提高模拟超声图的生成效果,本发明在步骤3中采用了联合训练的方法。由于本发明的最终目的是提高肾脏us图像分割准确度,步骤3训练过程中将生成的模拟超声图像放入语义分割模型中进行分割训练,语义分割模型产生的损失函数传输到cyclegan模型生成器的总损失函数中,从而促进cyclegan生成器的优化。语义分割模型可采用u-net模型,以及其它更加高效的语义分割模型。风格迁移网络为cyclegan模型。
15.作为本发明的一种优选技术方案:步骤4中,为了提高训练效果,本发明在步骤4的训练过程中加载了imagenet预训练模型的初始参数,以此提高训练准确度和泛化性能。利用模拟肾脏超声图像构成的训练集对imagenet预训练模型进行预训练,预训练完成后的权重参数保留,再利用真实肾脏超声图像构建的训练集,训练加载了预训练所得的权重参数的语义分割网络,最后利用训练好的语义分割网络对肾脏超声图像进行图像分割。
16.总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有如下几点优势:
17.(1)本发明可以生成解剖特征更真实的模拟肾脏超声图像。本发明的方法通过风格迁移网络利用真实的肾脏ct图模拟肾脏超声图,相比其他模拟肾脏超声图像生成技术,本发明生成的模拟超声图像中的肾脏结构更具有真实性,并采用了联合分割网络训练的方法进一步提高生成模型和分割模型准确度。
18.(2)本发明提供的训练方法标注成本较低。本发明通过带标签的三维肾脏ct图生成了大量且多角度的带标签的肾脏模拟超声图。相较于其他技术,本发明不需要人工标注大量的肾脏真实超声图,从而节约了人工标注成本,具有更强的经济效益。
19.(3)本发明训练生成的模型具有强泛化性。本发明在采用真实标注的肾脏超声图像训练之前,首先利用三维肾脏ct模拟生成的大量多角度模拟肾脏超声图作为预训练,并在语义分割模型中使用了imagenet预训练参数初始化。因此,本发明具有强泛化性,各种形态(无论正常与否)真实肾脏超声图都有不错的分割结果。
附图说明
20.图1是本发明的总体流程图;
21.图2是本发明的预处理过程的流程图;
22.图3是本发明的风格迁移网络训练的流程图;
23.图4是本发明阶段一(包括图2、图3)的流程图;
24.图5是本发明阶段二的流程图;
25.图6是本发明实施例中一种基于ct图像跨模态迁移学习的肾脏超声图像分割方法的详细流程示意图;
26.图7是本发明实施例中利用的cyclegan模型示意图;
27.图8是本发明实施例中将3d ct图按多角度分割模型示意图。
具体实施方式
28.为了使本发明的创造性、技术方案及优点更加清晰,以下结合附图及实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
29.本发明技术方案的实施主要包括三维ct图像预处理、风格迁移网络生成模拟us图像、语义分割模型的训练等几个过程。
30.步骤i.在本发明技术方案中,首先将数据做预处理以便于为后续的训练过程做准备。本发明实施了三个预处理步骤。首先是窗位和窗宽调整,包括将ct图像的窗位和窗宽分别调整为30和300,这两个数值都是临床实践中的经验值,优化了ct图像的显示质量。然后是将三维数据可视化为2二维切片。先将ct标签图像的三维数组转换为一维,在数组中以像素为1的点确定具体肾脏区域的坐标,抽取其中坐标设为分割点,将包含分割点的三个互相垂直的平面作为分割面,以分割点为中心,通过旋转分割面切割出ct断层图像同时调整出合适的ct断层图像分辨率。在可视化过程中,为了与us图像保持一致。最后是以单肾mask的质心为中心提取64*64的roi,用于后续操作中生成us图像,使过渡数据集中的图像视野与超声数据集中的图像视野一致。同时我们对肾脏us图像做roi操作,roi大小随图像中肾脏大小的改变而改变。而后将肾脏ct图像和肾脏us图像均调整到256*256。
31.步骤ii.风格迁移网络训练
32.本实施例中,风格迁移网络采用cyclegan模型和u-net模型结合而成的联合网络,语义分割模型采用u-net模型。本发明采用不对称的数据集,分别为预处理后的肾脏ct图像和肾脏us图像。现在分别将肾脏ct图像和肾脏us图像存放在数据集x和y。本发明目的是训练出一个生成器g,向它输入一个x,能够输出一个y,即g(x)=y
′
,x∈x,输入真实ct图像可以生成模拟us图像。同时,本发明还希望训练出另一个生成器f,向它输入一个y,能够输出一个x,即f(y)=x
′
,y∈y,输入真实us图像得到模拟ct图像。为了达到这个目的,本发明还需要训练两个判别器d
x
和dy,分别判断两个生成器生成图片的好坏:如果生成器产生的图片y
′
与数据集y里的图片y相差较大,此时判别器dy应判断它为假(为0),反之如果图片y
′
与数据集y里的图片y相似,则此时判别器dy判断为真(为1)。此外,判别器dy应该永远判断真实图片y为真。对于判别器d
x
也是同理。
33.在训练过程中,判别器和生成器是分别训练的。当固定住生成器的参数训练判别器时,判别器便能学到更好的判别技巧;当固定住判别器参数训练生成器时,生成器为了骗过现在更厉害的判别器,被迫生成更好质量的图片。两者便在这迭代学习的过程中逐步进化,最终达到动态平衡。为了使生成器产生的图片y
′
跟数据集y中的图片风格一致和生成器产生的图片y
′
跟输入图片x内容一致,cyclegan使用了cycle consistency loss,即将图片y
′
再放入生成器f中,产生的新图片x
′
和最开始的图片x尽可能的相似,即f(g(x))=x。因此,cyclegan生成器的loss由两部分组成,即:
34.loss=loss
gan
λloss
cycle
35.loss
gan
保证生成器和判别器相互进化,进而保证生成器能产生更真实的图片,loss
cycle
保证生成器的输出图片与输入图片只是风格不同,而内容相同。
36.具体的:
[0037][0038][0039]
cyclegan有两个相对独立的循环,前向循环和后向循环,每个循环有两个方向相反的生成器和一个判别器。具有相同方向的判别器和生成器在训练时共享相同的权重。本发明为了获取预定数量的模拟us图像,更加关注前向循环(ct->us->ct)。
[0040]
同时为了提高生成模拟超声图的质量,提高肾脏us图像分割准确度,将通过cyclegan模型生成的模拟us图像和对应的标签图(标签图不是cyclegan模型生成的)放入u-net模型中,进行语义分割训练,其损失函数可以表示为loss
seg
。将loss
seg
送到总loss中。因此,cyclegan生成器的总loss为
[0041]
loss=loss
gan
λloss
cycle
μloss
seg
[0042]
训练过程中学习率在前100个epochs不变,在后面的epochs线性衰减至0。本发明目的是为了提高分割网络准确度,因此让语义分割模型参与到模拟us图像的生成,使生成的模拟us图像分割准确度更高。同时cyclegan模型和u-net模型结合的联合网络训练,在训练的过程中能显而易见地观察到模拟us图像的分割结果,从而判断出cyclegan是否训练完成。
[0043]
步骤iii.分割训练
[0044]
本发明采用开源的u-net网络作为分割网络。u-net是医疗领域最成功的网络结构图像分割。它使用经典的编码器解码器结构,由收缩路径和扩展路径组成。将通过cyclegan得到的模拟超声图像与真实超声图像的数量比例控制在20∶1附近。在预训练部分,基于通过cyclegan得到的模拟超声数据集,选取90%作为训练集、10%作为验证集,针对u-net网络使用imagenet预训练模型作为初始参数开始预训练。在最终训练部分,基于真实的超声图像数据集,同样选取90%作为训练集、10%作为验证集,完成的预训练模型将以真实肾脏超声图像作为训练集进行最终训练微调,从而获得最终分割网络模型。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
