基于aocfs-ap聚类的行车视频关键帧提取方法
技术领域
1.本发明涉及自动驾驶领域,特别涉及一种基于aocfs-ap聚类的行车视频关键帧提取方法。
背景技术:
2.数字孪生技术利用大量现实数据搭建虚拟空间,能够在交通场景中完成自动驾驶、交通预测等方面的测试。关键帧是反映视频主要内容的几个画面,在一定程度上可以代表整个视频。对关键帧的准确提取是数字孪生分析的重要环节,对交通视频的三维重建具有重要意义。目前,关于关键帧提取研究成果较多,但各有局限性。nagasaka等
1.利用镜头边界获取关键帧数据,直接将按照时间序列等差划分出的视频帧作为关键帧输出,算力和时间成本较低,但输出的关键帧数目固定,准确性差,结果有较大可能无法代表视频关键数据,在高速运动的画面中,缺点尤为明显。rachida等
2.提出了一种利用典型特征的关键帧提取算法,主要判断依据来自信息熵的变化,通过比较相邻两帧之间灰度直方图的差异来判断所属帧是否为关键帧数据,自适应性较好,但阈值设置会影响关键帧数据的提取结果,视频存在大量分镜时会造成提取到的关键帧数目过多,影响数据质量。worf等
3.提出了一种基于光流分析的关键帧提取算法,通过构建光流场来分析运动场,利用光流法计算场景中的运动量,将局部运动极小值作为视频关键帧数据。此算法相对于利用图像特征提取关键帧的方法有了一定的改进,但复杂度过高,应用场景受限。基于聚类的关键帧提取是目前的研究热点
[4-5]
。聚类可以将离散的数据点划分为不同的簇,在应用于视频帧提取时可以将具有相似特征的视频帧数据聚合到一类,并把距离簇心最近的视频帧数据作为关键帧数据输出。聚类不仅比较前后帧的数据,还可以在视频时间序列中直接比较首帧和尾帧的差异,并跨越视频数据时间轴进行关键帧搜索。文献[4]提出了一种基于统计模型的无监督聚类关键帧提取方法,文献[5]以模糊c均值聚类为基础,加入了特征权重,使关键帧提取更准确。frey等
[6]
在《science》上提出了一种近邻传播聚类算法(affinity propagation,ap),不需要事先确定聚类数目,且相对于以上聚类方法,处理速度更快,然而,ap聚类的迭代时间成本对于数据量较大的数据集表现出明显的提高,尤其是数据维度过高时尤为明显。
[0003]
[1]nagasaka a,tanaka y.automatic video indexing and full-video search for object appearances[c]∥proceedings of the ifip tc2/wg2.62nd working conference on visual database systems ii.1992:113-127.
[0004]
[2]rachida h,abdessamad e and karim a.mskvs:adaptive mean shift-based keyframe extraction for video summarization and a new objective verification approach,journal of visual communication and image representation,2018(55):179-200.
[0005]
[3]worf w.key frame selection by motion analysis[c]//proc.ieee international conference on acoustics,speech and signal processing.atlanta,usa:ieee computer society,1996:1228-1231.
[0006]
[4]yang shuping,lin xinggang.key frame extraction using unsupervised clustering based on a statistical model[j].tsinghua science and technology,2005(2):169-173.
[0007]
[5]hua m,jiang p.afeature weighed clustering based key-frames extraction method[c]//proc.the 2009international forum on information technology and applications.piscataway:ieee computer society,2009:69-72.
[0008]
[6]frey bj,dueck d.clustering by passing messages between data points[j].science,2007,315(5814):972-976.
技术实现要素:
[0009]
为了解决提取关键帧算法聚类精度不高且缺少自适应性的问题,本发明提供一种基于碰撞融合策略的阿基米德优化ap聚类方法(archimedes optimizer based on collision fusion strategy,aocfs-ap),改进了碰撞融合策略,提升了阿基米德算法的自适应性,应用于关键帧提取中,能够自适应确定视频关键帧的数量,具有较高的精度。
[0010]
为实现上述目的,本发明提供如下技术方案:
[0011]
基于aocfs-ap聚类的行车视频关键帧提取方法,包括以下步骤:
[0012]
步骤1:输入视频帧数据,通过mobilenet将视频帧数据矢量化,得到矢量数据;
[0013]
步骤2:利用ischmtp对矢量数据进行初始化,得到aocfs算法的初始解矩阵,即aocfs算法投放的初始浸没物体位姿状态,所述浸没物体为某一帧图像;初始化ap聚类算法的归属度矩阵和隶属度矩阵;
[0014]
步骤3:计算浸没物体适应度值,对适应度值进行排序得到局部最优解;
[0015]
步骤4:根据局部最优解更新ap聚类算法的归属度矩阵和隶属度矩阵;
[0016]
步骤5:根据aocfs更新机制对浸没物体运动状态进行更新;
[0017]
步骤6:若步骤5所得浸没物体位姿不再发生更新或达到最大迭代次数,则跳出循环,依据步骤4所得结果输出最优聚类结果,否则执行步骤3;
[0018]
步骤7:将最优聚类结果转换到数据帧序列,输出得到的关键帧数据。
[0019]
进一步地,步骤1中将视频帧数据转换为标准大小后输入mobilenet,通过共享层卷积和可分离卷积操作获得具有图像空间特征的矩阵数据,再利用平均池化对数据降维、去除冗余操作,通过全连接层建立特征向量和特征信息的连接,得到1
×
1000的特征向量,最后,通过softmax层对特征向量进行归一化操作;
[0020]
利用主成分分析对归一化后的数据降维处理,得到矢量数据。
[0021]
进一步地,步骤2中利用ischmtp对矢量数据进行初始化,具体为:
[0022]
步骤2.1:采用scipy.spatial库中的voronoi函数,分别在seed,cmc,iris,和wine数据集上利用中垂线构建法构建泰森多边形;
[0023]
步骤2.2:利用线扫描确定各个泰森多边形边界坐标,得到泰森多边形位姿;
[0024]
步骤2.3:投放原始种群,根据泰森多边形构建原理,每个泰森多边形仅包含一个离散点数据,利用求坐标均值,将浸没物体位姿映射到构建完成的泰森多边形内,得到初始映射备选解;
[0025]
步骤2.4:计算初始映射备选解适应度值,对初始备选解进行初次筛选,得到aocfs
算法的初始解矩阵。
[0026]
进一步地,步骤2.3中映射规则如下:
[0027]
1)对泰森多边形求坐标均值,得到泰森多边形的伪中心,如下式所示;
[0028][0029]
式中,d为多边形顶点个数,vpi表示多边形第i个顶点所在坐标的向量;c_polyi表示多边形伪中心所在坐标;
[0030]
2)以泰森多边形的伪中心为中心,通过logistic混沌映射在中心附近映射出多个初始备选解如下:
[0031][0032]
式中,表示第t次映射的logistic值;μ为logistic映射的分支参数,map表示映射到样本空间的初始备选解坐标。
[0033]
进一步地,步骤2.4中对初始备选解进行初次筛选,具体如下表示:
[0034]
e=σ*(gbestf-gworstf)
[0035][0036]
式中,σ表示种群密度控制量,gbestf和gworstf分别表示初始投放种群适应度最优个体和最劣个体,e为有效映射系数,f表示备选解的适应度值,高于有效映射系数则保留,低于则做删除处理,obnew表示最后得到保留的映射解;
[0037]
通过初次筛选,完成初始化映射,初始化ao后得到在d维空间内n个浸没物体的位置矩阵表示如下:
[0038][0039]
x表示浸没物体位姿矩阵,对浸没对象的体积和密度进行初始化,表示如下:
[0040][0041]
式中,deni和voli分别表示第i个浸没物体的密度和体积;
[0042]
最后,初始化第i个浸没对象的加速度acc,如下:
[0043]
acci=lbi rand*(ub
i-lbi)
[0044]
式中,acci表示第i个浸没物体的加速度,lb和ub分别表示数据向量化的下界和上界。
[0045]
进一步地,步骤3具体包括:
[0046]
步骤3.1:采用颜色聚合矢量描述图像特征,具体方法为:将图像转换到hsv空间,对色彩进行非均匀量化,将色调空间h分为8份,饱和度空间s和亮度空间v分为3份;
[0047]
步骤3.2:把颜色分量合成一维特征矢量,规则如下所示:
[0048]
w=9h 3s v
[0049]
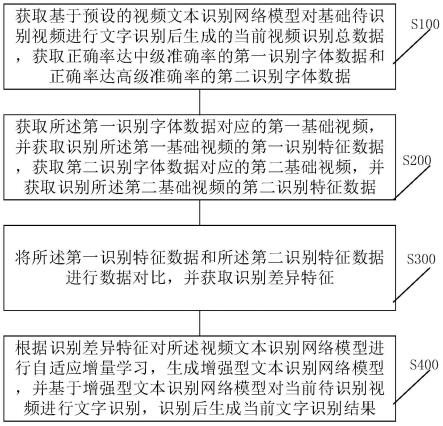
式中,w表示颜色量化级数,计算图像的量化级数矩阵,生成w的计数直方图,生成的72维特征向量即为视频帧的向量表示,提取到的关键帧有效代表整个视频内容,信息熵处于同一水平时,越少的关键帧数据对于后期视频处理更为有效,因此,在欧式空间相似性衡量的基础上提出一种针对视频数据聚类的适应度衡量算法,其代表性机制的适应度函数计算如下:
[0050][0051]
式中,fitness表示适应度值;m是提取到的关键帧数目;m表示视频帧数据的帧数;u表示各个簇内离散点数据到簇心距离之和;w表示各个离散点数据距离非簇心距离之和;md表示第l类图像包含的帧数,θ
li
表示第l个簇内第i个离散点数据,x
l
表示第l个簇的簇心数据。
[0052]
进一步地,步骤5中根据aocfs更新机制对浸没物体运动状态进行更新,具体为:
[0053]
以局部最优解作为中心,其余浸没物体以螺旋靠近方式对自身位姿进行更新,在ao中,考虑到碰撞造成的影响,浸没物体的密度和体积并不是固定的,而是随着时间产生变化的,体积和密度的更新策略如下:
[0054][0055]
式中,den
best
和vol
best
分别表示最优个体的密度和体积,den
it
和volit分别表示第i个体在第t次的密度和体积,ao寻优过程分为探索阶段和开发阶段,由转移算子tf实现探索到开发的过程,公式如下:
[0056][0057]
式中,式中,t为当前迭代次数,t
max
为最大迭代次数,密度因子e在全局搜索过渡到局部搜索的过程中控制着浸没物体转移的步长,公式如下:
[0058][0059]
浸没物体在探索阶段转向开发阶段的过程中,加速度逐渐减小,最后趋于稳定状态,tf为搜索状态转换参数,tf≤0.5时,算法处于探索阶段,加速度与浸没物体位置更新迭代规则如下所示:
[0060][0061]
[0062]
其中,x
it
为浸没第i个物体在第t次迭代的空间位姿,acc
it
为浸没物体i第t次迭代的加速度值,acc
best
表示局部最优解个体的加速度值,x
it
为第i个浸没物体在第t次迭代时的位姿向量,c为步长参数;
[0063]
tf》0.5时,算法处于开发阶段,加速度与浸没物体位置更新迭代规则如下所示:
[0064][0065][0066]
进一步地,所述依据步骤4所得结果输出最优聚类结果,具体步骤如下:
[0067]
通过归属度与隶属度矩阵求和,得到矩阵t,聚类中心判断规则如下:
[0068]
p=max(t)
[0069][0070]
式中,t为归属度矩阵与隶属度矩阵之和,p为矩阵t的最大值,v为浸没物体在矩阵t的值。
[0071]
与现有技术相比,本发明具有以下有益效果:
[0072]
本发明提供基于aocfs-ap聚类的行车视频关键帧提取方法,改善了传统方法在视频帧提取过程中受初始化中心点的影响较大导致聚类精度低,鲁棒性差,以及在迭代过程中求取均值选择聚类中心受离群点影响大的问题。
[0073]
首先,通过mobilenet神经网络提取图像特征,并进行pca降维,降低时间成本。同时,利用ischmtp初始化原始数据,通过aocfs与ap聚类混合迭代,提高了聚类精度、收敛速度和自适应性,应用价值明显。实际中的场景多种多样,处理的视频可能分辨率更低,色彩变化不够明显,干扰因素更多。因此,提高泛化能力和对低质量视频的特征提取效果是本算法未来重要的研究方向。
[0074]
本发明基于aocfs-ap聚类的行车视频关键帧提取方法可以应用在视频关键帧提取中,在行车视频关键帧数据处理过程中,aocfs-ap可以高效聚类生成视频关键帧数据,作为视频检索和行车环境检测,应用价值明显。
附图说明
[0075]
图1是mobilenet网络结构;
[0076]
图2为mobilenet输出特征向量,其中(a)为环境变化前采集到的图像,(b)为环境变化前提取到的特征向量,(c)为环境变化后采集到的图像,(d)为环境变化后提取到的特征向量;
[0077]
图3为采用scipy.spatial库中的voronoi函数,分别在seed,cmc,iris,和wine数据集上利用中垂线构建法构建的泰森多边形,其中(a)为seed,(b)为cmc,(c)为iris,(d)为wine;
[0078]
图4为初始化改进流程图;
[0079]
图5为本发明流程图;
[0080]
图6为不同方法初始化的种群与离散点数据分布结果图,其中(a)为cmc,(b)为
iris,(c)为seed,(d)为wine;
[0081]
图7高速路段关键帧输出结果图,其中(a)为进入隧道前的场景,(b)为场景发生显著变化的场景,(c)为隧道中场景,(d)为驶出隧道的场景;
[0082]
图8不同聚类数目适应度曲线图;
[0083]
图9为复杂公路场景关键帧输出结果图,其中(a)为输出结果1,(b)为输出结果2,(c)为输出结果3,(d)为输出结果4,(e)为输出结果5,(f)为输出结果6,(g)为输出结果7,(h)为输出结果8,(i)为输出结果9,(j)为输出结果10,(k)为输出结果11,(l)为输出结果12(m)为输出结果13,(n)为输出结果14。
具体实施方式
[0084]
下面结合说明书附图及具体的实施例对本发明做进一步的详细说明,所述是对本发明的解释而不是限定。
[0085]
本发明一种基于aocfs-ap聚类的行车视频关键帧提取方法,能准确的查找出视频的关键帧数据,提高各类行车视频数据的聚类精度,增强泛化能力和自适应能力。
[0086]
具体地,参见图1,首先,通过卷积神经网络mobilenet的特征提取层提取视频中每一帧的图像特征,输出一维特征向量,同时,为避免后期维度灾难,减少ap聚类花费的时间成本,利用主成分分析对数据进行降维预处理,得到保留85%以上数据特征的低维度数据;其次,改进阿基米德随机初始化方法,提出了一种基于泰森多边形的凸包映射初始化策略,使初始浸没物体能够更合理的分布在原始离散点所属的高维空间,减少后期迭代次数;然后,为了改进ap聚类偏向度系数初始化问题,模拟磁性物体随机碰撞的过程,为初始化得到的浸没物体赋予磁性,提出了一种碰撞融合策略,使得聚类中心的数目能够自适应离散点的空间分布;最后,依据自适应阿基米德优化定义的浸没物体对ap聚类的归属度矩阵和隶属度矩阵进行更新。
[0087]
包括以下步骤:
[0088]
步骤1:输入行车视频数据集,通过mobilenet将视频帧数据转化为特征向量数据;
[0089]
具体地,将视频帧数据转换为标准大小后输入mobilenet,通过共享层卷积和可分离卷积操作获得具有图像空间特征的矩阵数据,再利用平均池化对数据降维、去除冗余操作。通过全连接层建立特征向量和特征信息的连接,得到1
×
1000的特征向量。最后,通过softmax层对特征向量进行归一化操作。
[0090]
提取到的维度越高,特征向量包含的细节特征越多,但也会出现数据冗余,高维度的数据在后期ap迭代过程中也会产生较高的时间成本。因此,需要在神经网络提取到高维度数据特征的基础上,利用主成分分析(pca)对数据降维处理,能降低数据的冗余,滤除噪声数据,同时也能降低后期迭代过程中的时间成本。图3为保留原始数据85%的特征的pca降维在坐标轴上的可视化结果。可以看出,在经过数据去冗余化后,不影响算法精度的情况下,数据维度下降了95.3%,数据噪声得到了大幅度抑制,可以有效降低后期高维数据迭代的时间成本。
[0091]
步骤2:对步骤1所述特征向量利用ischmtp初始化得到初始种群(aocfs算法的初始解矩阵),即aocfs算法投放的初始浸没物体位姿状态,初始化ap聚类算法的归属度矩阵和隶属度矩阵;
[0092]
步骤2中aocfs将步骤1中得到的矢量化数据进行初始种群投放,群体智能需要维护一组解,并利用启发式规则搜索最优解。初始种群则为后续的演化过程提供一组初始猜想,决定了演化算法寻找全局最优的起点,影响种群收敛速度和最终解的精度。目前,群体智能算法大都采用伪随机数生成器(prngs)生成初始种群,其原理是通过prngs生成一组服从均匀分布的随机数,进而覆盖到搜索空间中可能的区域。prngs优点是算法简单,适用范围广。但生成种群不够均匀,尤其是在高维空间中更明显。混沌数生成器(cngs)[6]是基于混沌技术的随机数生成器,研究对初始状态特别敏感的动力系统行为,主要属性包括遍历性、随机性和规律性,利用一维混沌映射,并指定一个随机初值不断迭代,生成一系列连续的点,产生一个混乱的种群。与prngs相比,cngs能够在种群多样性、成功率以及收敛性等方面提高群体智能的性能。然而,混沌序列的行为对初值和参数过于敏感,针对不同问题需要选择不同的初值和参数。同时,由于吸引子的存在,混沌序列可能被吸引到几个固定的点,这会影响算法效果。
[0093]
因此,针对视频帧数据样本量大和数据维度高的特点,本发明设计了一种新的基于泰森多边形的凸包映射初始化策略(initialization strategy of convex hull mapping based on tyson polygon,ischmtp)应用于高维空间大数据集的初始化,具体步骤如下:
[0094]
采用scipy.spatial库中的voronoi函数,分别在seed,cmc,iris,和wine数据集上利用中垂线构建法构建泰森多边形。
[0095]
利用线扫描确定各个泰森多边形边界坐标,得到泰森多边形位姿。
[0096]
投放原始种群,根据泰森多边形构建原理,每个泰森多边形仅包含一个离散点数据,因此,单位面积内多边形的数量可以直接反映该区域数据点的稠密。为保证算法运行速度,本发明利用求坐标均值,得到泰森多边形几何中心,将浸没物体位姿映射到构建完成的泰森多边形内,映射规则如下所示:
[0097]
对一个高维空间超平面上的多边形求坐标均值,得到多边形的伪中心,如公式所示。这里通过中垂线法构建的多边形均为凸多边形,不考虑凹多边形的情况。
[0098][0099]
式中,d为多边形顶点个数,vpi表示多边形第i个顶点所在坐标的向量;c_polyi表示多边形伪中心所在坐标。
[0100]
以泰森多边形的伪中心为中心,通过logistic混沌映射在中心附近映射出多个初始备选解如下:
[0101][0102]
式中,表示第t次映射的logistic值,初值取为0.1;μ为logistic映射的分支参数,取值为(0,4),与映射得到数据点离散程度成正比,为保证初始化得到更多样化的候选解,这里取值为3.999;map表示映射到样本空间的初始备选解坐标。
[0103]
计算初始映射备选解适应度值,对初始备选解进行初次筛选,规则如下所示:
[0104]
e=σ*(gbestf-gworstf)
[0105][0106]
式中,σ表示种群密度控制量,取值范围为(0.25,0.75),gbestf和gworstf分别表示初始投放种群适应度最优个体和最劣个体,e为有效映射系数,f表示备选解的适应度值,高于有效映射系数则保留,低于则做删除处理,obnew表示最后得到保留的映射解。通过初次筛选,完成初始化映射。初始化ao(阿基米德优化器)后得到在d维空间内n个浸没物体的位置矩阵表示如下:
[0107][0108]
x表示浸没物体位姿矩阵,对浸没对象的体积(vol)和密度(den)进行初始化,如下:
[0109][0110]
式中,deni和voli分别表示第i个浸没物体的密度和体积。
[0111]
最后,初始化第i个对象的加速度acc,方式如下:。
[0112]
acci=lbi rand*(ub
i-lbi)
[0113]
式中,acci表示第i个浸没物体的加速度,lb和ub分别表示数据向量化的下界和上界。
[0114]
这样计算得到的中心大概率不会落在同一个簇中,ischmtp初始化算法可以有效减小视频帧数据之间相互影响和密集程度。
[0115]
步骤3:计算浸没物体适应度值,对适应度值进行排序得到局部最优解;
[0116]
具体地:
[0117]
采用颜色聚合矢量描述图像特征,具体方法为:将图像转换到hsv空间,对色彩进行非均匀量化,将色调空间h分为8份,饱和度空间s和亮度空间v分为3份;把颜色分量合成一维特征矢量,规则如下所示:
[0118]
w=9h 3s v
[0119]
式中,w表示颜色量化级数,计算图像的量化级数矩阵,生成w的计数直方图,生成的72维特征向量即为视频帧的向量表示,提取到的关键帧有效代表整个视频内容,信息熵处于同一水平时,越少的关键帧数据对于后期视频处理更为有效,因此,在欧式空间相似性衡量的基础上提出一种针对视频数据聚类的适应度衡量算法,其代表性机制的适应度函数计算如下:
[0120]
[0121]
式中,fitness表示适应度值;m是提取到的关键帧数目;m表示视频帧数据的帧数;u表示各个簇内离散点数据到簇心距离之和;w表示各个离散点数据距离非簇心距离之和;md表示第l类图像包含的帧数,θ
li
表示第l个簇内第i个离散点数据,x
l
表示第l个簇的簇心数据。
[0122]
步骤4:根据局部最优解更新ap聚类算法的归属度矩阵和隶属度矩阵;
[0123]
步骤5:根据aocfs更新机制对浸没物体运动状态进行更新;
[0124]
步骤4、5中根据局部最优解更新ap聚类算法的归属度矩阵和隶属度矩阵;并根据aocfs更新机制对浸没物体运动状态进行更新;包括步骤如下:
[0125]
将步骤3获得的最优适应度个体定义为局部最优解;
[0126]
利用局部最优解对ap的隶属度矩阵和归属度矩阵进行更新;
[0127]
利用aocfs更新机制对浸没物体位姿状态进行更新,在ao中,考虑到碰撞造成的影响,浸没物体的密度和体积并不是固定的,而是随着时间产生变化的,体积和密度的更新策略如下:
[0128][0129]
式中,den
best
和vol
best
分别表示最优个体的密度和体积,den
it
和vol
it
分别表示第i个体在第t次的密度和体积。ao寻优过程分为探索阶段和开发阶段,由转移算子tf实现探索到开发的过程,公式如下:
[0130][0131]
式中,t为当前迭代次数,t
max
为最大迭代次数。密度因子d在全局搜索过渡到局部搜索的过程中控制着浸没物体转移的步长,公式如下:
[0132][0133]
浸没物体在探索阶段转向开发阶段的过程中,加速度逐渐减小,最后趋于稳定状态,tf为搜索状态转换参数,tf≤0.5时,算法处于探索阶段,加速度与浸没物体位置更新迭代规则如下所示:
[0134][0135][0136]
其中,x
it
为浸没第i个物体在第t次迭代的空间位姿,acc
it
为浸没物体i第t次迭代的加速度值,acc
best
表示局部最优解个体的加速度值,x
it
为第i个浸没物体在第t次迭代时的位姿向量,c为步长参数;
[0137]
tf》0.5时,算法处于开发阶段,加速度与浸没物体位置更新迭代规则如下所示:
[0138][0139]
[0140]
c2的取值会改变更新步长,可依据数据集特点调整,初始时tf较小,使得最优个体和当前个体之间存在较大位置差异,所以随机游动的步长较高。随着迭代的进行,tf逐渐增加,逐渐减小最优个体和当前个体之间的位置差异,在勘探和开发之间实现平衡。
[0141]
根据贪婪原则决定是否替换原种群个体,判断最优适应度是否小于上次最优适应度,小于则替换最优个体,否则继续。
[0142]
步骤6:判断是否满足迭代次数达到最大迭代次数或局部最优解不再更新,若不满足,执行步骤3;若满足,则跳出循环,输出最优聚类结果,步骤如下:
[0143]
通过归属度与隶属度矩阵求和,得到矩阵t,聚类中心判断规则如下:
[0144]
p=max(t)
[0145][0146]
式中,t为归属度矩阵与隶属度矩阵之和,p为矩阵t的最大值,v为浸没物体在矩阵t的值。
[0147]
步骤7:将最优聚类结果转换到数据帧序列,输出得到的关键帧数据。
[0148]
结合附图对本发明带来的效果作进一步地解释说明:
[0149]
如图1所示为mobilenet网络结构,高质量的特征信息提取,是确保能够准确提取关键帧的关键。卷积神经网络相对于传统的颜色直方图法能够提取到更多细节特征,对不同环境有更好的适应性。通过预训练模型mobilenet的特征提取层网络提取图像特征。作为轻量级网络模型,mobilenet采用深度可分离卷积设计,在提取特征不丢失细节的基础上保证实时性;
[0150]
图4为利用aocfs的优化路径强化ap的优化路径实现流程,利用aocfs的优化路径强化ap的优化路径,实现两者混合迭代,不仅扩大了寻优范围,避免陷入局部最优,提高了搜索精度,而且解决了ap在处理高维数据过程中时间成本过高的问题,提升了优化效率。
[0151]
图6为不同算法初始化的种群与离散点数据分布结果。可以看出,不同于其它两种算法的初始化效果,ischmtp得到的初始种群是吸附于离散点数据存在的,离散点数据与周围初始种群的稀疏度成正比,使得后期迭代过程中的初始种群包含最优解的可能性大大提高,在高维、数据更离散的情况下,后期迭代节省的时间成本将明显降低。
[0152]
图7为利用aocfs-ap提取真实场景的视频数据关键帧输出结果。试验数据采集自某段高速公路车辆的行车记录仪,时长67秒左右,帧率为30fps,合计2015帧。图8为10次试验后不同聚类数目对应的最终适应度。可以看出,提取的关键帧代表了行车记录仪一段时间内主要经过的目标场景,分别为进入隧道前,场景发生显著变化,隧道中以及驶出隧道四种场景。由图8还可知,聚类数目为4时,得到的适应度值最小,说明聚类输出的关键帧结果符合适应度的梯度下降方向。高速路段数据特征相似度较高,因此最终输出的聚类结果会在相邻某几帧内振荡,导致适应度值表现出一定程度的不稳定;为测试aocfs-ap在复杂场景中的聚类性能,采集包含城市路段、郊区路段和高速路段等的视频数据,视频时长3210秒,帧率为30fps,数据总计96300帧。关键帧输出结果如图9所示。
[0153]
本发明提供的方法用于解决传统方法在视频帧提取过程中受初始化中心点的影响较大导致聚类精度低,鲁棒性差,以及在迭代过程中求取均值选择聚类中心受离群点影响大的问题。首先,通过mobilenet神经网络提取图像特征,利并进行pca降维,降低时间成
本。同时,利用ischmtp初始化原始数据,通过aocfs与ap聚类混合迭代,提高了聚类精度、收敛速度和自适应性,能够精确的提取出视频关键帧数据,应用价值明显。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。