技术特征:
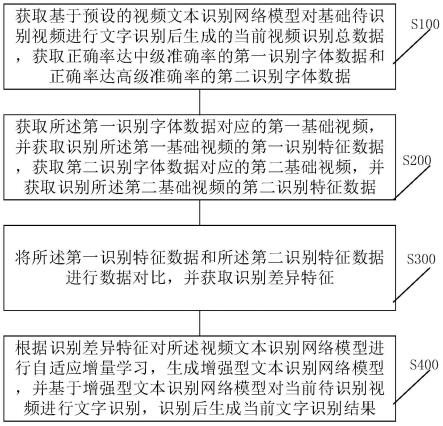
1.一种视频识别文字自适应调整方法,其特征在于,所述方法包括:获取基于预设的视频文本识别网络模型在预设特定时间段内对基础待识别视频进行文字识别后生成的当前视频识别总数据,并对所述当前视频识别总数据进行数据拆分并获取正确率达中级准确率的第一识别字体数据和正确率达高级准确率的第二识别字体数据,其中,所述中级准确率低于所述高级准确率;获取所述第一识别字体数据对应的第一基础视频,并获取识别所述第一基础视频的第一识别特征数据,获取所述第二识别字体数据对应的第二基础视频,并获取识别所述第二基础视频的第二识别特征数据;将所述第一识别特征数据和所述第二识别特征数据进行数据对比,并获取识别差异特征;根据所述识别差异特征对所述视频文本识别网络模型进行自适应增量学习,在自适应增量学习后生成增强型文本识别网络模型,并基于所述增强型文本识别网络模型对当前待识别视频进行文字识别,识别后生成当前文字识别结果,并将所述当前文字识别结果展示。2.根据权利要求1所述的视频识别文字自适应调整方法,其特征在于,获取所述第一识别字体数据对应的第一基础视频,并获取识别所述第一基础视频的第一识别特征数据,获取所述第二识别字体数据对应的第二基础视频,并获取识别所述第二基础视频的第二识别特征数据;具体包括:获取所述第一识别字体数据对应的时间进度数据;基于所述时间进度数据从所述基础待识别视频中提取与所述时间进度数据相匹配的第一基础视频;获取基于所述视频文本识别网络模型识别所述第一基础视频时的初始识别数据;获取文字识别审核人员对所述第初始识别数据进行纠正时的当前纠正数据,其中,所述当前纠正数据用于表征所述初始识别数据中的错误数据;根据所述当前纠正数据生成第一识别特征数据;获取所述第二识别字体数据对应的第二基础视频,并获取识别所述第二基础视频的第二识别特征数据。3.根据权利要求1所述的视频识别文字自适应调整方法,其特征在于,获取基于预设的视频文本识别网络模型在预设特定时间段内对基础待识别视频进行文字识别后生成的当前视频识别总数据,并对所述当前视频识别总数据进行数据拆分并获取正确率达中级准确率的第一识别字体数据和正确率达高级准确率的第二识别字体数据;具体包括:获取基于预设的视频文本识别网络模型在预设特定时间段内对基础待识别视频进行文字识别后生成的初始识别数据;根据所述初始识别数据进行筛选,并从所述初始识别数据中剔除空白文字数据,生成第一阶段识别数据,其中,所述空白文字数据为无文字的识别数据;对所述无文字的识别数据进行错误筛选,并剔除错误字段数据,并对所述错误字段数据进行修正,生成第二阶段识别数据;获取实验浏览用户对所述第二阶段识别数据的实时浏览反馈,并根据所述实时浏览反馈对所述第二阶段数据进行纠正,生成第三阶段识别数据;将所述第三阶段识别数据与所述第一阶段识别数据按照预设的特定长度段进行对比,并获取实际对比结果,其中,所述第三阶段识别数据按照预设的特定程度拆分后包括多个后期数据段,所述第一阶段识别数据按照预设的特定程度拆分后包括多个初始数据段,每个实际对比结果均包括后期数据段、初始数据段和实际正确值;根据所述实际对比结果筛选出正确率达中级准确率的第一识别字体数据和正确率达高级准确率的第二识别字体数据。4.根据权利要求3所述的视频识别文字自适应调整方法,其特征在于,根据所述实际对比结果筛选出正确率达中级准确率的第一识别字体数据和正确率达高级准确率的第二识
别字体数据,之后还包括:根据所述实际对比结果筛选出正确率低于所述中级准确率的初始数据段,并设定为问题数据段;基于所述问题数据段的实际正确值生成与所述中级准确率之间的实际差异值,其中,所述实际差异值为所述实际正确值与所述中级准确率的差值;根据所述实际差异值筛选出与所述实际差异值相匹配的文字识别监管人员;获取所述文字识别监管人员对所述问题数据段的问题分析反馈;将所述问题分析反馈发送至文字识别审核人员。5.根据权利要求1-4任一项所述的视频识别文字自适应调整方法,其特征在于,所述方法还包括:获取初始审核员对所述当前文字识别结果的初始识别反馈结果;获取与所述初始审核员处于同组的其他审核人员对所述当前文字识别结果的同级别反馈结果;获取所述初始审核员和所述其他审核人员的主管审核人员,并获取所述主管审核人员的主管审核结果;根据所述初始识别反馈结果、所述同级别反馈结果和所述主管审核结果生成当前识别综合反馈结果;根据所述当前识别综合反馈结果判断所述当前文字识别结果是否大于等于预设的标准合理值;若判断所述当前文字识别结果大于等于所述标准合理值,则持续对所述当前文字识别结果进行展示,并将所述当前文字识别结果发送至预设的目标用户群体;若判断所述当前文字识别结果小于所述标准合理值,则根据所述当前识别综合反馈结果对当前文字识别结果进行复核,在复核完成后生成带展示识别文字数据。6.一种视频识别文字自适应调整系统,其特征在于,所述系统包括:字体数据获取模块,用于获取基于预设的视频文本识别网络模型在预设特定时间段内对基础待识别视频进行文字识别后生成的当前视频识别总数据,并对所述当前视频识别总数据进行数据拆分并获取正确率达中级准确率的第一识别字体数据和正确率达高级准确率的第二识别字体数据,其中,所述中级准确率低于所述高级准确率;特征数据生成模块,用于获取所述第一识别字体数据对应的第一基础视频,并获取识别所述第一基础视频的第一识别特征数据,获取所述第二识别字体数据对应的第二基础视频,并获取识别所述第二基础视频的第二识别特征数据;差异特征生成模块,用于将所述第一识别特征数据和所述第二识别特征数据进行数据对比,并获取识别差异特征;模型增量展示模块,用于根据所述识别差异特征对所述视频文本识别网络模型进行自适应增量学习,在自适应增量学习后生成增强型文本识别网络模型,并基于所述增强型文本识别网络模型对当前待识别视频进行文字识别,识别后生成当前文字识别结果,并将所述当前文字识别结果展示。7.根据权利要求6所述的视频识别文字自适应调整系统,其特征在于,所述特征数据生成模块还用于:获取所述第一识别字体数据对应的时间进度数据;基于所述时间进度数据从所述基础待识别视频中提取与所述时间进度数据相匹配的第一基础视频;获取基于所述视频文本识别网络模型识别所述第一基础视频时的初始识别数据;获取文字识别审核人员对所述第初始识别数据进行纠正时的当前纠正数据,其中,所述当前纠正数据用于表征所述初始识别数据中的错误数据;根据所述当前纠正数据生成第一识别特征数据;获取所述第二识别字体数据对应的第二基础视频,并获取识别所述第二基础视频的第二识别特征数据。
8.根据权利要求6所述的视频识别文字自适应调整系统,其特征在于,所述字体数据获取模块还用于:模块获取基于预设的视频文本识别网络模型在预设特定时间段内对基础待识别视频进行文字识别后生成的初始识别数据;根据所述初始识别数据进行筛选,并从所述初始识别数据中剔除空白文字数据,生成第一阶段识别数据,其中,所述空白文字数据为无文字的识别数据;对所述无文字的识别数据进行错误筛选,并剔除错误字段数据,并对所述错误字段数据进行修正,生成第二阶段识别数据;获取实验浏览用户对所述第二阶段识别数据的实时浏览反馈,并根据所述实时浏览反馈对所述第二阶段数据进行纠正,生成第三阶段识别数据;将所述第三阶段识别数据与所述第一阶段识别数据按照预设的特定长度段进行对比,并获取实际对比结果,其中,所述第三阶段识别数据按照预设的特定程度拆分后包括多个后期数据段,所述第一阶段识别数据按照预设的特定程度拆分后包括多个初始数据段,每个实际对比结果均包括后期数据段、初始数据段和实际正确值;根据所述实际对比结果筛选出正确率达中级准确率的第一识别字体数据和正确率达高级准确率的第二识别字体数据;所述字体数据获取模块还用于:根据所述实际对比结果筛选出正确率低于所述中级准确率的初始数据段,并设定为问题数据段;基于所述问题数据段的实际正确值生成与所述中级准确率之间的实际差异值,其中,所述实际差异值为所述实际正确值与所述中级准确率的差值;根据所述实际差异值筛选出与所述实际差异值相匹配的文字识别监管人员;获取所述文字识别监管人员对所述问题数据段的问题分析反馈;将所述问题分析反馈发送至文字识别审核人员;所述模型增量展示模块还用于:获取初始审核员对所述当前文字识别结果的初始识别反馈结果;获取与所述初始审核员处于同组的其他审核人员对所述当前文字识别结果的同级别反馈结果;获取所述初始审核员和所述其他审核人员的主管审核人员,并获取所述主管审核人员的主管审核结果;根据所述初始识别反馈结果、所述同级别反馈结果和所述主管审核结果生成当前识别综合反馈结果;根据所述当前识别综合反馈结果判断所述当前文字识别结果是否大于等于预设的标准合理值;若判断所述当前文字识别结果大于等于所述标准合理值,则持续对所述当前文字识别结果进行展示,并将所述当前文字识别结果发送至预设的目标用户群体;若判断所述当前文字识别结果小于所述标准合理值,则根据所述当前识别综合反馈结果对当前文字识别结果进行复核,在复核完成后生成带展示识别文字数据。9.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至5中任一项所述方法的步骤。10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至5中任一项所述的方法的步骤。
技术总结
本申请涉及一种视频识别文字自适应调整方法及系统,依次通过获取当前视频识别总数据,获取正确率达中级准确率的第一识别字体数据和正确率达高级准确率的第二识别字体数据;获取第一识别特征数据,获取第二识别特征数据;获取识别差异特征;根据所述识别差异特征对所述视频文本识别网络模型进行自适应增量学习,在自适应增量学习后生成增强型文本识别网络模型,并基于所述增强型文本识别网络模型对当前待识别视频进行文字识别,识别后生成当前文字识别结果,并将所述当前文字识别结果展示。本发明使识别后生成的当前文字识别结果准确且高效,同时,为了实现更利用用户观看,进而将所述当前文字识别结果展示。将所述当前文字识别结果展示。将所述当前文字识别结果展示。
技术研发人员:王新华
受保护的技术使用者:武汉言平科技有限公司
技术研发日:2022.09.05
技术公布日:2022/11/29
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。