技术特征:
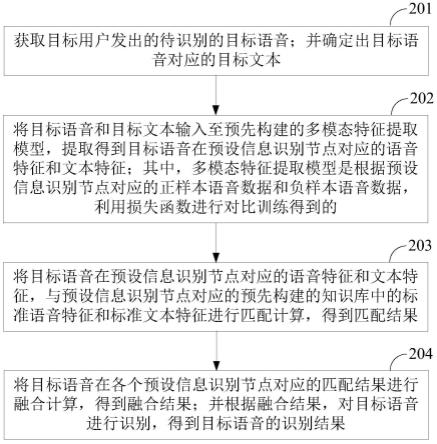
1.一种语音识别方法,其特征在于,包括:获取目标用户发出的待识别的目标语音;并确定出所述目标语音对应的目标文本;将所述目标语音和所述目标文本输入至预先构建的多模态特征提取模型,提取得到所述目标语音在预设信息识别节点对应的语音特征和文本特征;所述多模态特征提取模型是根据所述预设信息识别节点对应的正样本语音数据和负样本语音数据,利用损失函数进行对比训练得到的;将所述目标语音在预设信息识别节点对应的语音特征和文本特征,与所述预设信息识别节点对应的预先构建的知识库中的标准语音特征和标准文本特征进行匹配计算,得到匹配结果;将所述目标语音在各个预设信息识别节点对应的匹配结果进行融合计算,得到融合结果;并根据所述融合结果,对所述目标语音进行识别,得到所述目标语音的识别结果。2.根据权利要求1所述的方法,其特征在于,所述多模态特征提取模型的构建方式如下:获取样本语音数据,所述样本语音数据包括所述预设信息识别节点对应的正样本语音数据和负样本语音数据;将训练样本语音数据、所述正样本语音数据和负样本语音数据输入初始多模态特征提取模型,通过调整损失函数,训练得到所述多模态特征提取模型;其中,所述初始多模态特征提取模型包括vggish编码器、bert编码器、机器阅读理解模型mrc、多层感知机mlp。3.根据权利要求2所述的方法,其特征在于,所述损失函数为合页损失函数;所述损失函数用于拉近正样本语音数据表征之间的距离、且用于拉远负样本语音数据表征之间的距离。4.根据权利要求1-3任一项所述的方法,其特征在于,所述将所述目标语音和所述目标文本输入至预先构建的多模态特征提取模型,提取得到所述目标语音在预设信息识别节点对应的语音特征和文本特征,包括:将所述目标语音和所述目标文本分别输入至预先构建的多模态特征提取模型的vggish编码器和bert编码器,进行编码处理,得到初始语音表征和初始文本表征;利用多模态特征提取模型中的机器阅读理解模型mrc,将所述bert编码器输出的整句表征cls,与所述初始语音表征进行复杂注意力机制co-attention编码,得到融合后的语音表征;并利用所述融合后的语音表征,预测得到与所述目标用户的用户信息相关的语音区间的起点和终点;利用多模态特征提取模型中的多层感知机mlp,对所述与所述目标用户的用户信息相关的语音区间对应的语音表征进行池化pooling操作,得到所述目标语音在预设信息识别节点对应的语音特征;将所述与所述目标用户的用户信息相关的语音区间对应的语音表征,与所述初始文本表征进行co-attention编码,得到融合后的文本表征;并利用所述mlp对所述融合后的文本表征进行pooling操作,得到池化后的文本表征;按照预设文本分类的方式,对所述初始文本表征进行token标签类别的分类,得到分类后的文本表征,并将所述分类后的文本表征与所述池化后的文本表征进行拼接,得到拼接
后的文本表征,作为所述目标语音在预设信息识别节点对应的文本特征。5.根据权利要求4所述的方法,其特征在于,所述方法还包括:获取验证用户发出的验证语音;并确定出所述验证语音对应的验证文本;将所述验证语音和所述验证文本输入至所述多模态特征提取模型,获得与所述验证用户的用户信息相关的语音区间的起点和终点,以及所述验证文本对应的分类后的文本表征;当与所述验证用户的用户信息相关的语音区间的起点和终点与所述验证语音对应的人工标注的起点和终点不一致,且所述验证文本对应的分类后的文本表征与所述验证文本对应的人工标注的token标签类别结果不一致时,将所述验证语音重新作为所述样本语音,对所述多模态特征提取模型进行更新。6.根据权利要求1所述的方法,其特征在于,所述将所述目标语音在预设信息识别节点对应的语音特征和文本特征,与所述预设信息识别节点对应的预先构建的知识库中的标准语音特征和标准文本特征进行匹配计算,得到匹配结果,包括:将所述目标语音在预设信息识别节点对应的语音特征和文本特征,与所述预设信息识别节点对应的预先构建的知识库中的所有标准语音特征和标准文本特征进行相似度计算,并将得到的最高相似度作为匹配结果。7.根据权利要求6所述的方法,其特征在于,所述将所述目标语音在各个预设信息识别节点对应的匹配结果进行融合计算,得到融合结果;并根据所述融合结果,对所述目标语音进行识别,得到所述目标语音的识别结果,包括:将所述目标语音在各个预设信息识别节点对应的最高相似度进行求和计算,得到求和结果;判断所述求和结果是否高于预设阈值;若是,则确定所述目标语音的识别结果为所述目标用户是待推荐用户;若否,则确定所述目标语音的识别结果为所述目标用户不是待推荐用户。8.根据权利要求7所述的方法,其特征在于,所述预设阈值为4。9.一种语音识别装置,其特征在于,包括:第一获取单元,用于获取目标用户发出的待识别的目标语音;并确定出所述目标语音对应的目标文本;提取单元,用于将所述目标语音和所述目标文本输入至预先构建的多模态特征提取模型,提取得到所述目标语音在预设信息识别节点对应的语音特征和文本特征;所述多模态特征提取模型是根据所述预设信息识别节点对应的正样本语音数据和负样本语音数据,利用损失函数进行对比训练得到的;匹配单元,用于将所述目标语音在预设信息识别节点对应的语音特征和文本特征,与所述预设信息识别节点对应的预先构建的知识库中的标准语音特征和标准文本特征进行匹配计算,得到匹配结果;识别单元,用于将所述目标语音在各个预设信息识别节点对应的匹配结果进行融合计算,得到融合结果;并根据所述融合结果,对所述目标语音进行识别,得到所述目标语音的识别结果。10.一种语音识别设备,其特征在于,包括:处理器、存储器、系统总线;
所述处理器以及所述存储器通过所述系统总线相连;所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行权利要求1-8任一项所述的方法。11.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备执行权利要求1-8任一项所述的方法。
技术总结
本申请公开了一种语音识别方法、装置、存储介质及设备,该方法包括:首先获取目标语音,并确定出其对应的目标文本,然后将二者输入至预先构建的多模态特征提取模型,提取目标语音在预设信息识别节点对应的语音特征和文本特征;其中,多模态特征提取模型是根据预设信息识别节点对应的正样本语音数据和负样本语音数据,利用损失函数进行对比训练得到的;接着,将目标语音在预设信息识别节点对应的语音特征和文本特征,与知识库中的标准语音特征和标准文本特征进行匹配计算,得到匹配结果;进而将各个预设信息识别节点对应的匹配结果进行融合计算,并根据融合结果对目标语音进行识别。从而能够在对用户进行语音识别时,有效提高识别效率和准确率。高识别效率和准确率。高识别效率和准确率。
技术研发人员:李繁 段纪丁 汤建飞 吴晓妍 葛稳
受保护的技术使用者:科大讯飞股份有限公司
技术研发日:2022.08.29
技术公布日:2022/11/29
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。