技术特征:
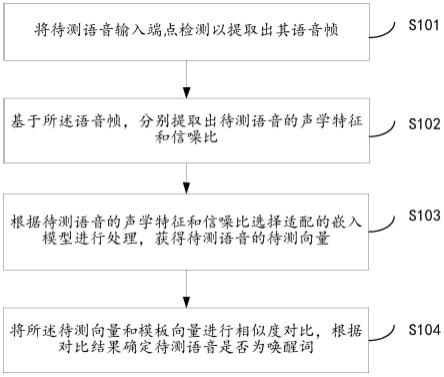
1.一种基于相似对对比学习用户自定义关键词识别方法,其特征在于,包括以下步骤:将待测语音输入端点检测以提取出其语音帧;基于所述语音帧,分别提取出待测语音的声学特征和信噪比;根据待测语音的声学特征和信噪比选择适配的嵌入模型进行处理,获得待测语音的待测向量;将所述待测向量和模板向量进行相似度对比,根据对比结果确定待测语音是否为唤醒词。2.根据权利要求1所述基于相似对对比学习用户自定义关键词识别方法,其特征在于,所述将待测语音输入端点检测以提取出其语音帧,包括:判断所述待测语音的起始发音位置和终止发音位置;根据所述起始发音位置和终止发音位置提取出待测语音的发音段;对所述发音段进行分帧处理,获取所述发音段对应的多帧语音;提取每帧语音的第一信号幅度和第一能量值,根据每帧语音的第一信号幅度和第一能量值与标准语音帧的第二信号幅度和第二能量值的比较情况确定该帧语音是否为语音帧。3.根据权利要求1所述基于相似对对比学习用户自定义关键词识别方法,其特征在于,基于所述语音帧,提取出待测语音的信噪比,具体为:根据所述语音帧确定待测语音的语音信号频率;基于所述语音信号频率对所述待测语音进行扩频处理,获取扩频后的待测语音;提取待测语音每个扩频后的语音帧对应的信号能量和噪声能量;计算每个扩频后的语音帧对应的信号能量和噪声能量的比值,取所有语音帧的比值的平均值作为待测语音的信噪比。4.根据权利要求1所述基于相似对对比学习用户自定义关键词识别方法,其特征在于,提取待测语音的声学特征的方式为mfcc特征提取,其具体包括:对待测语音进行预加重、分帧、加窗、傅里叶变换、取平方、mel滤波、取对数、离散傅里叶变换。5.根据权利要求1所述基于相似对对比学习用户自定义关键词识别方法,其特征在于,在根据待测语音的声学特征和信噪比选择适配的嵌入模型进行处理,获得待测语音的待测向量之前,所述方法还包括:获取两个标签相同的训练语音信号;将所述两个训练语音信号进行增强以获得模型训练样本;将两个模型训练样本同时输入到待训练嵌入模型中获取模型输出的两个嵌入向量;构建两个嵌入向量之间的互相关矩阵,通过预设训练算法使得互相关矩阵的值趋向于期望互相关矩阵。6.根据权利要求5所述基于相似对对比学习用户自定义关键词识别方法,其特征在于,所述构建两个嵌入向量之间的互相关矩阵,通过预设训练算法使得互相关矩阵的值趋向于期望互相关矩阵,包括:获取模型训练的样本的样本大小;根据所述样本大小构建两个嵌入向量之间的互相关矩阵:
其中,c
ij
表示为嵌入向量a和b之间的互相关矩阵i、j表示网络输出的向量维数,b表示为模型训练的样本的样本大小,z
a
表示为嵌入向量a,z
b
表示为嵌入向量b;通过预设训练算法l
bt
使得互相关矩阵的值趋向于期望互相关矩阵,其中,损失函数表示为:其中,λ表示为一个正数,是相似项和冗余项的权衡值。7.根据权利要求1所述基于相似对对比学习用户自定义关键词识别方法,其特征在于,所述根据待测语音的声学特征和信噪比选择适配的嵌入模型进行处理,获得待测语音的待测向量,包括:确认所述信噪比对应的目标值是否大于等于第一预设阈值,若是,确认其为高信噪比,若否,确认其为低信噪比;若所述信噪比为低信噪比,为待测语音选择简单嵌入模型;若所述信噪比为高信噪比,为待测语音选择复杂嵌入模型;通过所述简单嵌入模型或复杂嵌入模型对待测语音的声学特征进行处理,获得待测语音的待测向量。8.根据权利要求1所述基于相似对对比学习用户自定义关键词识别方法,其特征在于,在将所述待测向量和模板向量进行相似度对比,根据对比结果确定待测语音是否为唤醒词之前,所述方法还包括:获取三段模板语音依次输入到每个嵌入模型中,获取每个嵌入模型输出的三个第一向量;计算每个嵌入模型输出的三个第一向量的平均值,获得第二向量;将每个嵌入模型的第二向量作为该嵌入模型的模板向量。9.根据权利要求1所述基于相似对对比学习用户自定义关键词识别方法,其特征在于,所述将所述待测向量和模板向量进行相似度对比,根据对比结果确定待测语音是否为唤醒词,包括:分别获取所述待测向量和模板向量各自对应的向量值并根据其计算出待测向量和模板向量的相似度:其中,t(x,y)表示为待测向量和模板向量的相似度,x表示为待测向量,y表示为模板向量,x
i
表示为待测向量的向量值在第i个维度的向量子值,y
i
表示为模板向量的向量值在第i
个维度的向量子值;确认二者的相似度是否大于等于第二预设阈值,若是,确定待测语音为唤醒词,若否,确定待测语音非唤醒词。10.一种基于相似对对比学习用户自定义关键词识别系统,其特征在于,该系统包括:第一提取模块,用于将待测语音输入端点检测以提取出其语音帧;第二提取模块,用于基于所述语音帧,分别提取出待测语音的声学特征和信噪比;处理模块,用于根据待测语音的声学特征和信噪比选择适配的嵌入模型进行处理,获得待测语音的待测向量;对比模块,用于将所述待测向量和模板向量进行相似度对比,根据对比结果确定待测语音是否为唤醒词。
技术总结
本发明公开了一种基于相似对对比学习用户自定义关键词识别方法及系统,其方法包括:将待测语音输入端点检测以提取出其语音帧,基于所述语音帧,分别提取出待测语音的声学特征和信噪比,根据待测语音的声学特征和信噪比选择适配的嵌入模型进行处理,获得待测语音的待测向量,将所述待测向量和模板向量进行相似度对比,根据对比结果确定待测语音是否为唤醒词。通过根据待测语音的声学特征和信噪比选择适配的嵌入模型进行处理可以根据待测语音的信噪比提供不同的神经网络模型来实现对于待测语音中噪音的鲁棒性,从而最大化地克服噪音信号的影响,保证了后续进行语音关键词识别的识别精度。识别精度。识别精度。
技术研发人员:雷蕾 袁国顺
受保护的技术使用者:苏州漠陀半导体科技有限公司
技术研发日:2022.08.17
技术公布日:2022/11/29
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。