1.本发明属于机器人计算机系统技术领域,具体涉及一种客服机器人学习系统及学习方法。
背景技术:
2.客服机器人作为一套自动对话系统,已逐渐成为很多企业售后环节的标配产品,它能够在一定程度上减轻客服人员的接待压力。对于客服机器人而言, 如何正确识别用户意图并给出合适的答案,始终是摆在面前的核心任务。而机器人识别率,正是其中最重要的衡量指标之一。当前工业界的机器人系统,需要依赖大量提前准备好的知识图谱(包括领域特定的知识), 实际接待中不可避免地会遇到识别不准/无法识别的问题。
3.因此,一个完善的客服机器人,需要一个对应的学习系统,以对一些识别不准/无法识别的常见问题进行学习。目前市面上常见的客服机器人,采用的学习机制比较原始: 收集用户反馈上来的未识别/识别不准(不满意)的问题, 管理员进行归类并调整后将其再次添加到知识图谱。 对于此类系统而言,其应对识别率低情形时存在诸多问题:(1)不能及时发现未识别/识别不准的情况,常常依赖于客户反馈;(2)对未识别问题的学习不够及时,通常依赖于管理员后台手动配置/调整;(3)管理员后台手动配置的方式难以应对大量的待学习任务;通过以上问题不难发现: 现有的系统存在许多需要人为介入的操作, 严重缺乏自动化。 也难以实现对大量待学习问题的持续迭代学习, 随着后续业务的持续增长, 这些问题会进一步放大。
技术实现要素:
4.本发明的目的在于:为解决现有技术中的难以对大量问题进行持续迭代学习的问题,提供一种客服机器人学习系统及学习方法。
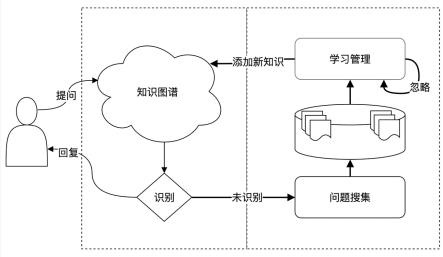
5.本发明采用的技术方案如下:一种客服机器人学习系统,包括:问题收集模块:用于知识图谱产生未识别问题时或者访客对识别不准或不符合期望的问题进行上报时, 将问题自动添加到未识别问题库;自动聚类模块:用于以后台的形式提供服务,自动对未识别问题做机器学习自动分类, 形成分类整理后的结果;学习管理模块:用于进行人机交互操作,人机交互操作包括搜索问题、查看问题列表、查看问题详情、忽略问题、批量操作和查看问题关联的历史对话。
6.一种客服机器人学习系统学习方法,包括如下步骤:a、问题收集:通过问题收集模块的收集,当知识图谱产生未识别问题时或者访客对识别不准或不符合期望的问题进行上报时,将问题自动添加到未识别问题库;
b、问题自动聚类:问题收集模块以后台服务的形式,采用聚类single-pass 算法,自动对未识别问题做机器学习自动分类,将一个问题的多个相似问法分为一类,将零散的问题经过分类后呈现为较分类前更少的分类结果;c、系统学习管理:通过管理员操作学习管理模块,对学习系统进行包括搜索问题、查看问题列表、查看问题详情、忽略问题、批量操作和查看问题关联的历史对话的操作,将无效问题忽略,将有效问题重新添加至知识图谱,实现对知识图谱的知识补充。
7.进一步地,所述步骤b中的聚类single-pass 算法包括如下步骤:(1)以第一篇文档为种子,建立一个分类;(2)将文档 d 向量化;(3)将文档 d 与已有的所有分类均以single-link 策略做相似度计算,采用欧氏距离或余弦距离作为距离度量方法;(4)找出与文档 d 具有最大相似度的已有分类;(5)根据聚类的需求设置相似度阈值θ,阈值θ在[0,1]之间,阈值θ设置得越高,得到的簇粒度越小,簇内文本数量越少,簇的个数越多;相反地,阈值θ设置得越低,簇粒度越大,则簇内文本数量越多,簇的个数越少;(6)若相似度值大于阈值θ,则把文档d加入到有最大相似度的分类中,跳转至步骤(8);(7)若相似度值小于阈值θ,则文档d不属于任一已有分类,需创建新的分类,同时将当前文本归属到新创建的分类中;(8)聚类结束,等待下一篇文档进入。
[0008]
综上所述,由于采用了上述技术方案,本发明的有益效果是:1.通过机器学习自动聚类,对大量未识别问题进行分类,极大地提高了学习系统的自动化程度和学习效率。
[0009]
2.自动聚类模块支持多算法架构,可以对不同行业的 saas 企业使用不同的分类算法。
[0010]
3.学习管理模块功能丰富、界面友好,同时提供了生命周期管理,实现了更加智能的学习管理操作。
附图说明
[0011]
图1为本发明学习系统结构图;图2为本发明自动聚类流程图。
[0012]
其中,cn为第n个已存在分类;sn为问题文本与分类cn中心文本相似度。
具体实施方式
[0013]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0014]
一种客服机器人学习系统,其结构图如图1所示,包括:问题收集模块:用于知识图谱产生未识别问题时或者访客对识别不准或不符合期
望的问题进行上报时, 将问题自动添加到未识别问题库;自动聚类模块:用于以后台的形式提供服务,自动对未识别问题做机器学习自动分类, 形成分类整理后的结果,自动聚类的流程原理如图2所示,其算法处理过程为:对每个待分类问题文本依次计算其与已存在分类的中心文本相似度;如果最大相似度值为sn且sn超过某个阈值,则将该问题归入分类cn;如果最大相似度值为sm但sm小于阈值,将该问题独立成一个新分类;其中,cn为第n个已存在分类;sn为问题文本与分类cn中心文本相似度。
[0015]
学习管理模块:用于进行人机交互操作,人机交互操作包括搜索问题、查看问题列表、查看问题详情、忽略问题、批量操作和查看问题关联的历史对话。
[0016]
一种客服机器人学习系统学习方法,包括如下步骤:a、问题收集:通过问题收集模块的收集,当知识图谱产生未识别问题时或者访客对识别不准或不符合期望的问题进行上报时,将问题自动添加到未识别问题库;b、问题自动聚类:问题收集模块以后台服务的形式,采用聚类single-pass 算法,自动对未识别问题做机器学习自动分类,将一个问题的多个相似问法分为一类,将零散的问题经过分类后呈现为较分类前更少的分类结果;c、系统学习管理:通过管理员操作学习管理模块,对学习系统进行包括搜索问题、查看问题列表、查看问题详情、忽略问题、批量操作和查看问题关联的历史对话的操作,将无效问题忽略,将有效问题重新添加至知识图谱,实现对知识图谱的知识补充。
[0017]
本发明的系统从学习自动化、操作易用性等方面着手实现了更智能的问题收集系统,更自动化的待学习问题处理系统,能支撑业务持续增长的机器人学习系统。考虑到识别率问题将是一个长期迭代优化的过程,新的学习系统以组合多个部件的方式完成学习任务,可以做到后续使用更优的实现替代其中的某些部件。
[0018]
进一步地,所述步骤b中的聚类single-pass 算法包括如下步骤:(1)以第一篇文档为种子,建立一个分类;(2)将文档 d 向量化;(3)将文档 d 与已有的所有分类均以single-link 策略做相似度计算,采用欧氏距离或余弦距离作为距离度量方法;(4)找出与文档 d 具有最大相似度的已有分类;(5)根据聚类的需求设置相似度阈值θ,阈值θ在[0,1]之间,阈值θ设置得越高,得到的簇粒度越小,簇内文本数量越少,簇的个数越多;相反地,阈值θ设置得越低,簇粒度越大,则簇内文本数量越多,簇的个数越少;(6)若相似度值大于阈值θ,则把文档d加入到有最大相似度的分类中,跳转至步骤(8);(7)若相似度值小于阈值θ,则文档d不属于任一已有分类,需创建新的分类,同时将当前文本归属到新创建的分类中;(8)聚类结束,等待下一篇文档进入。
[0019]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。