一种用于概念漂移检测和自适应的方法及iot安全框架
技术领域
1.本发明属于物联网技术领域,具体涉及一种用于概念漂移检测和自适应的方法及iot安全框架。
背景技术:
2.传统安全问题在物联网系统中具有特殊的表现形式,而物联网系统由于自身特性也引入了新的威胁类型。基于传统的有标签分类机器学习的入侵检测是一个“close world”问题。然而,现实情况中的攻击形式是没有标签的“open world”问题,越来越多的学者关注这个研究课题。一方面,由于物联网的设备类型众多,可能存在不同的安全漏洞,会出现未知的攻击形式和病毒样本,这使得物联网恶意流量识别问题成为一个典型的“open world”问题。另一方面,由于物联网设备多,数据量大,攻击形式层出不求,物联网安全领域中的数据异常检测显得尤为重要。在物联网安全领域更容易产生数据的概念漂移,概念漂移会对模型和系统产生重大危害。
3.概念漂移描述了数据流的分布随时间不可预测的变化情况从,但是概念漂移的出现使得系统性能下降不可避免,如何处理并最终改善系统性能,这样的研究成果不多,现有技术中也提出了一些处理概念漂移的架构,从而改善系统性能,但总体来看并不适用于无标签的实际环境。
技术实现要素:
4.本发明的目的在于提供一种用于概念漂移检测和自适应的方法及iot安全框架,以解决现有技术中导致的上述缺陷。
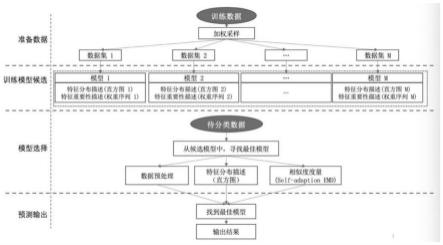
5.本发明公开了一种用于概念漂移检测和自适应的方法,包括如下步骤:
6.s1.数据准备
7.准备iot数据集dataset用来训练模型,对数据集dataset进行有放回抽样,经过采样后,得到m个子训练集dataset1,dataset2,...,datasetm;
8.s2.训练模型候选
9.在模型准备阶段,在每个训练集上,训练出分类器作为候选模型,并使用直方图对训练集的特征分布进行表征,同时记录每个特征对模型的重要程度;
10.s3.模型选择
11.在模型选择阶段,使用直方图对待预测数据的特征分布进行表征,然后,根据直方图的相似度,在候选模型中,寻找到最相似的训练集,并使用该训练集上训练的模型最为决策模型;
12.s4.预测输出
13.通过相似度对直方图表征的比较,寻找到最相似的训练集,并使用该训练集上训练的模型最为决策模型。
14.优选的,所述步骤s1中采用bagging抽样方法,使用不同正负样本配比,选择5%的
原始数据样本。
15.优选的,所述步骤s2中具体方法如下:
16.训练baseline模型:使用m个训练集,n个特征,在每个训练集上,生成一个直方图矩阵h,训练出一个分类器e和对应权重序列k,这样共得到m个直方图(h1,h2,
…hm
),m个分类器(e1,e2,
…em
)和m个权重序列(k1,k2,
…km
);
17.每个训练集的直方图h生成方法如下:
18.对某一个特征x而言,假设x的特征值为一个序列x1,x2,
…
x
t
,t表示该特征值序列的长度,i表示特征值序列中的位置,将特征值序列中的元素按大小分成若干个范围,每个范围称为一个bin,hj表示该特征值在第j个bin中出现的次数,hj的计算方法如公式(1)所示:
[0019][0020]
其中ii为指示函数,计算方法如公式(2)所示:
[0021][0022]
通过公式(1)和(2)可计算出特征x的直方图h=h1,h2,
…
,hc,使用同样的方法,为每个特征计算出直方图,得到直方图矩阵h'如公式(3)所示,c为直方图中bin的数量,n为特征的数量:
[0023][0024]
将直方图矩阵h'转换为一维,得到该训练集的直方图h如公式(4)所示:
[0025]
h=h
1,1
,h
1,2
,
…
,h
1,c
,h
2,1
,h
2,2
,
…
,h
2,c
,
…
,h
n,1
,h
n,2
,
…
,h
n,c
ꢀꢀꢀ
(4)
[0026]
在每个训练集上的生成分类器e和权重序列k的方法如下:
[0027]
选择分类器模型,并使用训练集中的样本对模型进行训练,通过训练得到分类器,在训练同时,记录每个特征对模型的重要程度,并使用序列k1,k2,
…
,kn进行表示,n为特征的数量,称序列k1,k2,
…
,kn为权重序列k。
[0028]
优选的,所述步骤s3中采用了self-adaption emd的相似度的度量方法,该方法首先使用步骤3中的直方图生成方法,为待预测数据生成直方图h',然后分别计算h'与每个训练集直方图h的相似度。
[0029]
优选的,所述步骤s3中,令h=p,h'=q,即p和q分别表示训练样本和待预测数据的直方图,pi和qi分别表示各自的直方图某个bin值,表示pi的权重,表示qi的权重,如公式(5)和(6)所示:
[0030][0031][0032]
定义流动量矩阵f,如公式(7)所示,其中,f
ij
表示从pi到qi的流动数量;
ton-iot中,采样生成一组不同分布的测试集。在模型准备阶段,在每个训练集上,训练出一批二分类模型作为候选模型,并使用直方图对训练集的特征分布进行表征。在模型选择阶段,使用直方图对测试集的特征分布进行表征,然后,根据直方图的相似度,寻找到最相似的训练集,并使用该训练集上训练的模型最为决策模型。通过实验,比较多种相似度度量方法,发现使用self-adaption emd的相似度的度量效果更好,可以从候选模型中挑选出最佳的决策模型。
附图说明
[0045]
图1为采用直方图表征数据集间的相似度。
[0046]
图2为相对于有标签的实验场景,本发明的安全框架相对比平均的baseline模型性能的比较情况。
[0047]
图3为针对无标签的真实场景,本发明的安全框架相对比平均的baseline模型性能的比较情况。
[0048]
图4为本发明的iot安全框架模型。
具体实施方式
[0049]
为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
[0050]
如图1至图4所示,一种用于概念漂移检测和自适应的方法,包括如下步骤:
[0051]
s1.数据准备
[0052]
准备iot数据集dataset用来训练模型,具体如下:
[0053]
采用bagging抽样方法,使用不同正负样本配比,对数据集dataset进行有放回抽样,经过采样后,得到m个子训练集dataset1,dataset2,...,datasetm。
[0054]
以利用流量数据进行物联网异常检测为例,可以使用nf-ton-iot和nf-ton-iot-v2两个基础数据集。由于物联网数据流通常是连续生成的大量数据,因此使用所有的数据样本进行学习模型开发往往是不可行和不必要的。因此,应采用有效的数据抽样方法来选择具有高代表性的数据样本。
[0055]
准备两个iot数据集a和b(每个数据集均包含正常流量和异常流量)
[0056]
a:用来训练模型nf-ton-iot-v2,样本数量16940496;
[0057]
b:用来测试模型nf-ton-iot,样本数量1379274;
[0058]
采用基于bagging抽样方法,对两个iot数据集a和b进行有放回的抽样,分别生成样本数为812570的bootstrap伪样本,完成bagging抽样。使用不同正负样本配比(正样本占比0.1,0.2
…
0.9),从数据集a中,经过加权随机采样,得到9个子集a1,a2,
…
a9(每个子集样本数量为数据集a的1/9)。
[0059]
由于物联网流量数据集的规模较大,因此采用bagging抽样方法选择了5%的原始数据样本来评估所提出的框架。生成的子集的大小可以有所不同,这取决于物联网数据的生成速度和服务器机器的计算能力。与其他采样方法相比,bagging抽样主要要关注降低方差,因此它在不剪枝决策树,神经网络等易受样本扰动的学习器上效用更为明显。
[0060]
s2.训练模型候选
[0061]
在模型准备阶段,在每个训练集上,训练出一批二分类模型作为候选模型,并使用直方图(histogram)对训练集的特征分布进行表征;使用权重序列对模型中每个特征的重要性进行表征。
[0062]
训练baseline模型:使用m个训练集,n个特征,在每个训练集上,生成一个直方图矩阵h,训练出一个分类器e和对应权重序列k,这样共得到m个直方图(h1,h2,
…hm
),m个分类器(e1,e2,
…em
)和m个权重序列(k1,k2,
…km
)
[0063]
每个训练集的直方图h生成方法如下:
[0064]
对某一个特征x而言,假设x的特征值为一个序列x1,x2,
…
x
t
,t表示该特征值序列的长度,i表示特征值序列中的位置,将特征值序列中的元素按大小分成若干个范围,每个范围称为一个bin,hj表示该特征值在第j个bin中出现的次数,hj的计算方法如公式(1)所示。
[0065][0066]
其中ii为指示函数,计算方法如公式(2)所示。
[0067][0068]
通过公式(1)和(2)可计算出特征x的直方图h=h1,h2,
…
,hc,使用同样的方法,为每个特征计算出直方图,得到直方图矩阵h'如公式(3)所示,c为直方图中bin的数量,n为特征的数量。
[0069][0070]
将直方图矩阵h'转换为一维,得到该训练集的直方图h如公式(4)所示
[0071]
h=h
1,1
,h
1,2
,
…
,h
1,c
,h
2,1
,h
2,2
,
…
,h
2,c
,
…
,h
n,1
,h
n,2
,
…
,h
n,c
ꢀꢀꢀ
(4)
[0072]
在每个训练集上的生成分类器e和权重序列k的方法如下:
[0073]
选择分类器模型,并使用训练集中的样本对模型进行训练,通过训练得到分类器,在训练同时,记录每个特征对模型的重要程度,并使用序列k1,k2,
…
,kn进行表示(n为特征的数量),称序列k1,k2,
…
,kn为权重序列k。
[0074]
训练baseline模型,可以选取若干个特征,例如训练多个分类器m1-m9,同时生成d1-d9(数据集)的直方图。根据数据集的特征分布,每个特征按等宽方式生成直方图。
[0075]
s3.模型选择
[0076]
在数据处理阶段对特征处理的时候,会出现两个特征之间不在同一个量级的情况,如果采用线性运算的话,就很容易导致不平衡,本文采用max-min方法对特征进行归一化的操作。
[0077]
max-min是对数据做了一次线性变换,将x值映射到了[0,1]之间。一般是在特征数据较为零散或者是线性关系,并且没有很多离群值的时候,可以采用这种方法进行归一化,公式如下:
[0078][0079]
其中,x和x
norm
分别表示归一化之前和归一化之后的特征,x
max
和x
min
分别表示该特征的最大值和最小值。
[0080]
在模型选择阶段,使用直方图对测试集的特征分布进行表征,然后,根据直方图的相似度,寻找到最相似的训练集,并使用该训练集上训练的模型最为决策模型。通过实验,比较多种相似度度量方法,发现使用self-adaption emd的相似度的度量效果更好,可以从候选模型中挑选出最佳的决策模型。
[0081]
emd距离(earth mover's distance),是由2000年ijcv期刊文章《the earth mover's distance as a metric for image retrieval》提出的一种图像相似度度量方法,最初emd的概念是用于图像检索的。后来因为其各种优点,逐渐用到其他方面的相似度度量,考虑到不同的特征对模型输出影响是不同的,self-adaption emd是emd距离的基础上,增加了一项权重系数,用来计算两组数据分布的相似程度。
[0082]
采用了self-adaption emd的相似度的度量方法。本方法首先使用直方图生成方法,为待预测数据生成直方图h',然后分别计算h'与每个训练集直方图h的相似度,计算方法如下:
[0083]
定义p和q分别表示训练样本和待预测数据的直方图,pi和qi分别表示各自的直方图某个bin值,表示pi的权重,表示qi的权重,如公式(5)和(6)所示。
[0084][0085][0086]
定义流动量矩阵f如公式(7)所示,其中,f
ij
表示从pi到qi的流动数量。
[0087]
f=[f
ij
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0088]
定义d
ij
为从pi到qi的距离,代价函数如公式(8)所示。其中,k表示权重序列,a表示训练集直方图bin的数量,b表示待预测数据直方图bin的数量,g(i)为训练集直方图中,第i个元素对应的特征在权重序列k中的值。
[0089][0090]
通过线性规划,计算出当公式(8)取最小值时,流动量矩阵f的取值。计算方法如公式(9)所示,其中,为代价函数,s.t.表示约束条件。
[0091][0092]
在使用公式(9)计算出流动量矩阵f后,再使用公式(10)计算出待预测数据直方图h'和训练集直方图h的距离,并使用该距离表示直方图h'和h的相似度,距离越小表示两个直方图越相似。
[0093][0094]
s4.预测输出
[0095]
通过使用self-adaption emd的相似度直方图表征比较,寻找到最相似的训练集,并使用该训练集上训练的模型最为决策模型,从而克服了概念漂移问题,改善系统性能,提升了iot安全流量识别的准确率。
[0096]
实验器材及准备
[0097]
实验采用的硬件包括:x86_64架构,20核,内存128gb,硬盘:256gb;软件包括:scipy(1.5.2),h2o(3.34.0.3),scikit-learn(1.0.1),pandas(1.2.1),matplotlib(3.3.2),代表了主流的大数据分析物联网数据的服务器配置。
[0098]
两个数据集被用来评估所提出的框架。第一个数据集是nf-ton-iot数据集,利用公开可用pcaps来生成其netflow记录,从而产生了一个基于netflow的iot网络数据集。数据流总数为1,379,274,其中1,108,995(80.4%)为攻击样本,270,279(19.6%)为良性样本。第二个数据集是nf-ton-iot-v2数据集,数据流总数为16,940,496,其中10,841,027(63.99%)为攻击样本,6,099,469(36.01%)。由于所使用的两个数据集都是不平衡的数据集,因此我们使用精度、准确度、召回率和f1分数这四个指标来评估所提出的框架的综合性能。
[0099]
实验验证
[0100]
用正/负样本配比1:9,2:8,3:7
…
9:1,采样分别生成9个训练集(异常流量为ddos),使用直方图 emd描述9个数据集间的相似度。如图1所示,数值越小,颜色越浅,表示越相似。
[0101]
图1直观的表征数据集间的相似程度。表1从数值上验证相似度度量方法是有效的,正/负数据配比越相近,结果越相似。
[0102]
表1采用直方图表数据征数据集间的相似度
[0103][0104]
对比性能提升
[0105]
1)有标签的场景
[0106]
针对有标签的实验场景,如图2所示,相对比平均的baseline模型性能,提出的cddam框架能够改善3.2个百分点的准确率,1.7个百分点的精度和6.6个百分点的f1分,在召回率上改善最佳,可以增加9.8个百分点。
[0107]
如表2所示,将提出的cddam框架分别与传统的rf、glm、gbm、deeplearn、cnn和bayes等模型进行比较。虽然个别性能不如rf和deeplearn,但实质上由于这两个模型训练的过拟合导致的,并不适用于现实场景中的open world问题。另一方面,虽然个别性能不是最佳,但是提出的cddam框架的平均性能比上述6个模型都好。
[0108]
表2每个模型的提升
[0109] accuracyprecisionrecallf1_scorerf-0.00012769-0.00347093-0.00141618-0.00242901glm0.12639792-0.009527830.256916710.15286328gbm0.02667125-0.001167680.053142800.02668254deeplearn-0.00212379-0.01275931-0.00141750-0.00715475cnn0.025022240.134893740.272785610.22206910bayes0.01839170-0.007319690.009404290.00231622average0.032371940.016774720.098235950.06572456
[0110]
表3是有标签场景下,提出的cddam框架与传统的rf、glm、gbm、deeplearn、cnn和bayes等模型的总体性能比较。
[0111]
表3总体性能提升(总图)-有标签场景
[0112][0113]
2)无标签的真实环境
[0114]
针对无标签的真实场景,如图3所示,相对比平均的baseline模型性能,提出的cddam框架能够改善2.9个百分点的准确率,4.6个百分点的f1分,在召回率上改善最佳,可以增加7.3个百分点,在精度性能上改善不明显。
[0115]
如表4所示,将提出的cddam框架分别与传统的rf、glm、gbm、deeplearn、cnn和bayes等模型进行比较,除了精度性能改善较小以外,其它性能均有显著提高。同样的,由于rf和deeplearn的这两个模型训练的过拟合,改善不显著,但其实这两个模型在无标签的现实场景中是无法使用的。另一方面,提出的cddam框架的平均性能对比glm、gbm、cnn和bayes,均有明显改善。提出的cddam框架的平均性能比上述6个模型都好。
[0116]
表4每个模型的提升
[0117] accuracyprecisionrecallf1_scorerf0.00113408-0.003213780.00189657-0.00051347glm0.07158803-0.029273620.159699950.07537674gbm0.03230318-0.001974130.063756120.03277711deeplearn0.000703330.003021910.001556280.00223637cnn0.042321980.041458760.165958220.14079421bayes0.02721373-0.004225750.050271820.02765012average0.029210720.000965560.073856490.04638684
[0118]
表5是无标签场景下,提出的cddam框架与传统的rf、glm、gbm、deeplearn、cnn和bayes等模型的总体性能比较。
[0119]
表5总体性能提升(总图)-无标签场景
[0120][0121]
由技术常识可知,本发明可以通过其它的不脱离其精神实质或必要特征的实施方案来实现。因此,上述公开的实施方案,就各方面而言,都只是举例说明,并不是仅有的。所有在本发明范围内或在等同于本发明的范围内的改变均被本发明包含。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
