1.本发明涉及数据分析技术领域,更具体涉及一种甄别境外人员一人有多个证件号码的方法。
背景技术:
[0002][0003]
全世界的护照号码参差不齐,没有统一的标准;很多情况下根本无法像中国人一样,通过身份证号码对身份进行查验,所以很难通过护照号码去判断身份的唯一性。
[0004]
在以往工作过程中,工作人员对境外人员管理时,只能通过查询其他业务系统或者对境外人员当面询问,来发现是否有异常情况,整体的工作完全凭借个人经验,难以甄别信息的真实性。
技术实现要素:
[0005]
本发明需要解决的技术问题是提供一种甄别境外人员一人有多个证件号码的方法,以解决目前无法有效甄别境外人员一人有多个证件号码的问题,通过对数据的关联、比对等技术,为出入境、边检等部门提供甄别境外人员唯一身份。
[0006]
为解决上述技术问题,本发明所采取的技术方案如下。
[0007]
一种甄别境外人员一人有多个证件号码的方法,包括以下步骤:
[0008]
s1、对原始数据进行采集;
[0009]
s2、将步骤s1中原始数据共性字段汇总至一起,去重后取并集数据;
[0010]
s3、利用业务规则和最长公共子串算法,将字段拼在一起,数据两两进行比对,并且为每条数据的相似度进行打分;
[0011]
s4、利用业务规则和分词算法,把句子按照字典切分成词,寻找词的最佳组合方式,并且为每个数据打上比对分数;
[0012]
s5、对步骤s3和步骤s4计算后的数据分组排序,取序号为1并且分组最高的数据;
[0013]
s6、关联人像识别的数据,排除掉人证不一致的数据;
[0014]
s7、设置一定的阈值,将分数达到阈值线以上的数据提取至业务库中。
[0015]
进一步优化技术方案,所述原始数据包括出入境数据、签证数据。
[0016]
进一步优化技术方案,在进行步骤s1后,针对不同来源数据标准不一的情况,制定统一的数据标准,按照相应的数据标准进行数据清洗和关联,形成标准库的数据。
[0017]
进一步优化技术方案,所述步骤s3包括以下步骤:
[0018]
将特定的数据转化为字符串,然后给定字符串的集合s={s1,...,sk},其中 |si|=ni,∑ni=n.;对于满足2≤k≤k的k,找出至少s是k个字符串的公共子串的最长串,最终为每个数据打上比对分数。
[0019]
进一步优化技术方案,所述步骤s5中,利用row_number()开窗算法进行对步骤s3和步骤s4计算后的数据分组排序。
[0020]
由于采用了以上技术方案,本发明所取得技术进步如下。
[0021]
本发明主要是通过对数据的关联、比对等技术,为出入境、边检等部门提供甄别境外人员唯一身份。通过提供一种软件、数据规则相结合的方法,采集全省或某一区域所有的涉外数据,对数据分析、比对,根据业务规则和算法对数据进行打分,建立人员置信度等操作,最终汇聚至一起建立成一个业务数据模型,通过这个模型,可以快速地对境外人员的身份进行甄别,刻画出一个更加准确、详细的人像信息,辅助出入境、边检等部门日常的业务工作。
附图说明
[0022]
图1为本发明的整体流程图;
[0023]
图2为本发明对原始数据进行采集的示例数据图;
[0024]
图3为本发明数据汇聚的示例数据图;
[0025]
图4为本发明利用业务规则和最长公共子串算法对数据进行处理的示例数据图;
[0026]
图5为本发明利用业务规则和分词算法对数据进行处理的示例数据图;
[0027]
图6为本发明利用开窗算法对数据进行处理的示例数据图。
具体实施方式
[0028]
下面将结合附图和具体实施例对本发明进行进一步详细说明。
[0029]
本发明公开了一种甄别境外人员一人有多个证件号码的方法,在深入了解具体外管业务的情况下,结合业务人员的实战经验,通过提供一种软件、数据规则相结合的方法,通过采集全省或某一区域所有的涉外数据,对数据分析、比对,根据业务规则和算法对数据进行打分,建立人员置信度等操作,最终汇聚至一起建立成一个业务数据模型,通过这个模型,可以快速地对境外人员的身份进行甄别,刻画出一个更加准确、详细的人像信息,辅助出入境、边检等部门日常的业务工作。
[0030]
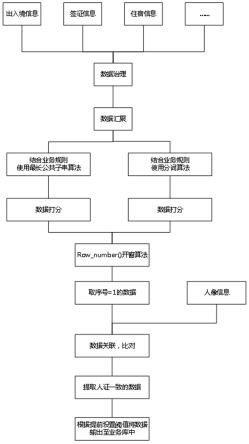
结合图1所示,本发明具体包括以下步骤:
[0031]
s1、对原始数据进行采集。通过服务接口、数据库同步、人工拷贝等多种不同的方式,将各个部门的数据采集至一起,形成“原始库”的数据。使用出入境数据、签证数据等作为原始数据,其他数据作为补充数据,示例数据如图2所示。
[0032]
数据治理:在进行步骤s1后,针对不同来源数据标准不一的情况,制定统一的数据标准,然后按照相应的数据标准进行数据清洗和关联,形成标准库的数据。
[0033]
s2、数据汇聚:根据业务要求,将适合建档的数据按照一定的数据标准汇总至一起,作为模型计算的基础数据。
[0034]
将步骤s1中原始数据共性字段汇总至一起,去重后取并集数据,示例数据如图3所示。
[0035]
将汇聚后的数据,按照业务规则要求,比如:证件号码不能为空,姓名不能为空等,以及加入最长公共子串、分词和row_number()开窗等不同的算法,将数据与业务规则、算法进行关联,比对。
[0036]
s3、利用业务规则和最长公共子串算法,按照业务规则将姓名、性别等字段拼在一起,数据两两进行比对,并且为每条数据的相似度进行打分。
[0037]
业务规则种类繁多,主要是根据实战需求和数据种类来制定,通常是将数据中的姓名、性别、出生日期等进行组合,结合不同的算法进行计算。
[0038]
该步骤是将特定的数据转化为字符串,然后给定字符串的集合s={s1,...,sk},其中|si|=ni,∑ni=n.;对于满足2≤k≤k的k,找出至少s是k个字符串的公共子串的最长串,最终为每个数据打上比对分数。
[0039]
比如:字符串"ababc","babca"以及"abcba",对这两个字符串进行计算,可以发现都包含了"abc",那么最长串"abc",那么这三个字符串的相似度为60%,示例数据如图4所示。
[0040]
s4、利用业务规则和分词算法,主要基于词典的分词,先把句子按照字典切分成词,再寻找词的最佳组合方式。
[0041]
其中,业务规则种类繁多,主要是根据实战需求和数据种类来制定,通常是将数据中的姓名、性别、出生日期等进行组合,结合不同的算法进行计算。
[0042]
分词算法主要是将词组进行切分,然后对切分后的数据进行匹配。
[0043]
比如:姓名“ab abc”以及“abc ab”,按照空格将每个词组进行拆分,然后再进行关联、比对,最后可以发现,以上两个姓名实际是一样的,只不过前后顺序颠倒而已,从而可以判断是同一个人。因此,利用分词算法和业务规则,将特定的字段进行组合计算,最终为每个数据打上比对分数,示例数据如图5 所示。
[0044]
最佳组合是指相似度最高的组合,比如:词组“ab abc ef”和“abc ab”,按照空格将每个词组进行拆分,对这两个词组进行关联、比对后可以发现都包括了“ab”和“abc”,那么两者的相似度就66%。
[0045]
s5、通过以上两种算法计算后,可以出现重复的数据,那么利用row_number() 开窗算法进行对以上的数据分组排序,取序号为1并且分组最高的数据,示例数据如图6所示。
[0046]
row_number()开窗算法是根据表中字段进行分组,然后根据表中的字段排序;即根据其排序顺序,给组中的每条记录添加一个序号;且每组的序号都是从1 开始,可利用该特性进行分组取前n的数据。
[0047]
s6、人像比对:将比对后的数据与人像数据进行关联,排除掉人证不一致的数据。
[0048]
s7、设置一定的阈值,将分数达到阈值线以上的数据提取至业务库中。按照提前设置的阈值,将符合阈值访问内的数据提取出来存放至业务库,供出入境、边检等部门日常的业务工作使用。
[0049]
通过本发明中的数据分析模型,可以快速根据个人信息,对境外人员的身份进行甄别,刻画出一个更加准确、详细的人像信息,辅助出入境、边检等部门日常的业务工作。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。