1.本发明涉及一种基于线程池的模型并行化数据仿真方法,属于仿真系统技术领域。
背景技术:
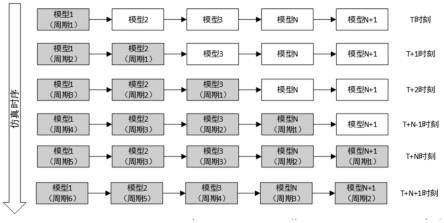
2.现有技术中的数据流仿真系统架构都是采用串行化仿真方式,由上游模型(记为第n个模型)产生数据后,交由下游模型(记为第n 1个模型)处理,直到所有模型计算完成后,开始下一轮计算。此过程中,当第n 1个模型计算时,第n个模型处于空闲状态,整个过程cpu一直处于单任务执行,cpu使用率低,仿真效率低下。串行仿真模型工作状态及仿真时序流的描述如图1所示。
技术实现要素:
3.针对上述技术问题,本发明的目的是提供一种基于线程池的模型并行化数据仿真方法,解决串行仿真过程中cpu使用率低,仿真效率低下的问题。
4.为了解决以上问题,本发明采用的技术方案是:基于线程池的多线程技术,利用面向对象中的“发布-订阅”模型,实现模型的并行工作。具体的技术方案为:一种基于线程池的模型并行化数据仿真方法,包含以下步骤:s1、定义具备“发布-订阅”功能的模型基类,保证模型具备数据的收发功能;s2、根据仿真需求,定义不同功能的仿真模型,要求每个数据处理模型均继承步骤s 1中定义的基类,这样每个模型具备了“发布-订阅”的功能;s3、通过下游仿真模型订阅上游模型的数据实现数据流的拓扑关系搭建;s4、创建线程池,并为每个模型分配一个线程资源,用于仿真运算;s5、启动仿真,即令仿真的第一个模型产生数据即线程1,当数据生成之后,直接将数据发布,由于第二个模型订阅了第一个模型的数据,则第二个仿真模型收到数据后,开始第二个模型的计算即线程2开始工作;同时第一个模型即线程1继续产生下一个仿真周期的数据,第二个模型和第三个模型收到数据后开始计算,即线程2和线程3开始工作;以此类推,则在所有的模型收到数据后,同时并行工作。
5.所有的模型启动仿真时全部激活,当没有数据输入时,处于休眠等待状态,当有数据输入时,则计算数据,处于工作计算状态。
6.进一步的,仿真过程中如果需要仿真暂停,暂停仿真中的第一个模型产生数据,由此,第二个模型由于没有输入,会暂停工作,以此类推,整个仿真会进入暂停状态;如果需要仿真停止,停止第一个仿真模型产生数据,则后续模型没有数据作为输入,整个仿真都将停止。
7.本发明的有益效果:通过本发明的方法操作,实现了基于线程池的模型并行化数据流仿真,提高了cpu的使用效率和仿真效率。
附图说明
8.图1是现有技术的工作状态及数据流向示意图;图2是本发明的工作状态及数据流向示意图。
具体实施方式
9.以下结合附图实施例对本发明的实施方案进一步说明,但本发明并不限于下述实施例:一种基于线程池的模型并行化数据仿真方法,包含以下步骤:s1、定义具备“发布-订阅”功能的模型基类,保证模型具备数据的收发功能;s2、根据仿真需求,定义不同功能的仿真模型,要求每个数据处理模型均继承步骤s 1中定义的基类,这样每个模型具备了“发布-订阅”的功能;s3、通过下游仿真模型订阅上游模型的数据实现数据流的拓扑关系搭建;s4、创建线程池,并为每个模型分配一个线程资源,用于仿真运算;s5、启动仿真,即令仿真的第一个模型产生数据即线程1,当数据生成之后,直接将数据发布,由于第二个模型订阅了第一个模型的数据,则第二个仿真模型收到数据后,开始第二个模型的计算即线程2开始工作;同时第一个模型即线程1继续产生下一个仿真周期的数据,第二个模型和第三个模型收到数据后开始计算,即线程2和线程3开始工作;以此类推,则在所有的模型收到数据后,同时并行工作。
10.还包括,仿真暂停,仿真过程中如果需要仿真暂停,则只需要暂停仿真中的第一个模型产生数据,由此,第二个模型由于没有输入,同样也会暂停工作,以此类推,整个仿真会进入暂停状态。
11.还包括,仿真停止,同仿真暂停类似,只需第一个仿真模型停止产生数据,则后续模型没有数据作为输入,整个仿真都将停止。
12.如图2所示,经过n个时刻以后,所有的模型同时处于工作状态,多线程的使用大大提高了cpu的使用效率和仿真效率。
技术特征:
1.一种基于线程池的模型并行化数据仿真方法,其特征在于,基于线程池的多线程技术,利用面向对象中的“发布-订阅”模型,实现模型的并行工作。2.根据权利要求1所述的一种基于线程池的模型并行化数据仿真方法,其特征在于,具体包括以下步骤:s1、定义具备“发布-订阅”功能的模型基类,保证模型具备数据的收发功能;s2、根据仿真需求,定义不同功能的仿真模型,要求每个数据处理模型均继承步骤s 1中定义的基类,每个模型具备“发布-订阅”的功能;s3、通过下游仿真模型订阅上游模型的数据实现数据流的拓扑关系搭建;s4、创建线程池,并为每个模型分配一个线程资源,用于仿真运算;s5、启动仿真,即令仿真的第一个模型产生数据即线程1,当数据生成之后,直接将数据发布,由于第二个模型订阅了第一个模型的数据,则第二个仿真模型收到数据后,开始第二个模型的计算即线程2开始工作;同时第一个模型即线程1继续产生下一个仿真周期的数据,第二个模型和第三个模型收到数据后开始计算,即线程2和线程3开始工作;以此类推,则在所有的模型收到数据后,同时并行工作。3.根据权利要求1或2所述的一种基于线程池的模型并行化数据仿真方法,其特征在于,仿真过程中如果需要仿真暂停,暂停仿真中的第一个模型产生数据,由此,第二个模型由于没有输入,会暂停工作,以此类推,整个仿真会进入暂停状态。4.根据权利要求1或2所述的一种基于线程池的模型并行化数据仿真方法,其特征在于,如果需要仿真停止,停止第一个仿真模型产生数据,则后续模型没有数据作为输入,整个仿真都将停止。
技术总结
本发明提供一种基于线程池的模型并行化数据仿真方法,定义具备“发布-订阅”功能的模型基类,定义不同功能的仿真模型,要求每个数据处理模型均继承定义的基类;通过下游仿真模型订阅上游模型的数据实现数据流的拓扑关系搭建;创建线程池,并为每个模型分配一个线程资源;令仿真的第一个模型产生数据,第二个仿真模型收到数据后,开始第二个模型的计算;同时第一个模型继续产生下一个仿真周期的数据,第二个模型和第三个模型收到数据后开始计算;以此类推,则在所有的模型收到数据后,同时并行工作。本发明实现了基于线程池的模型并行化数据流仿真,提高了CPU的使用效率和仿真效率。提高了CPU的使用效率和仿真效率。提高了CPU的使用效率和仿真效率。
技术研发人员:孟逍遥 王涛 朱剑平
受保护的技术使用者:北京中科睿信科技有限公司
技术研发日:2022.08.31
技术公布日:2022/11/29
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
