1.本发明涉及基于数据驱动的故障分类方法领域,特别是针对非线性大规模化工过程提出的一种基于堆叠自编码器的递阶故障分类方法。
背景技术:
2.随着现代工业过程的日益复杂,保证工业过程的安全稳定运行的挑战性也在增加。故障检测与诊断(fault detection and diagnosis,fdd)技术对于提高化工过程的可靠性和安全性起重要作用。故障分类是fdd的一个重要方面。故障分类是对故障样本进行分类。故障分类方法包括基于模型的方法、基于知识的方法和数据驱动的方法。由于计算机技术和传感器技术的发展,大量的工业过程历史数据可以被采集和存储,基于数据驱动的方法受到了广泛的关注。
3.多元统计分析是数据驱动方法的一种。主成分分析(principal component analysis,pca)和费歇判别分析(fisher discriminant analysis,fda)等多元统计分析的方法已成功应用于故障分类方法。针对非线性数据,核pca和核fda已被提出。为了考虑工业过程数据的多模态性,并强调关键故障变量,稀疏局部fda已被提出。而多元统计方法只能提取浅层特征,可能对故障分类的性能有不利的影响。深度神经网络由多个隐含层组成,能够提取数据的非线性深层特征。基于深度神经网络的故障分类方法受到了越来越多的关注。深度信念网络(deep belief network,dbn)、卷积神经网络(convolutional neural network,cnn)、堆叠自编码器(stacked autoencoder,sae)等深度神经网络已应用于故障分类。sae是一种无监督模型,已经成功应用于工业过程的故障分类中。为了使sae在工业过程故障分类中具有更好的性能,很多改进的sae模型已被提出,如判别信息自编码器(discriminant information-based autoencoder,diae)、嵌入式字典学习自编码器(autoencoder embedded dictionary learning,aedl)、堆叠监督自编码器(stacked supervised autoencoder,ssae)等。而现代工业过程往往具有大规模的特性,由多个操作单元组成,只建立单一的故障分类模型,可能不利于大规模工业过程的故障分类性能。
技术实现要素:
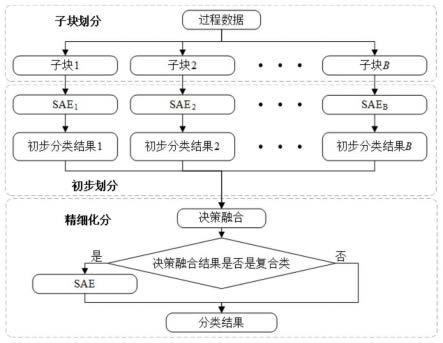
4.为了提高大规模工业过程的故障分类性能,本发明提出了一种基于堆叠自动编码器的递阶故障分类方法(hierarchical fault classification based on stacked autoencoder)。针对工业过程大规模的特性,利用先验知识和相关性将整个工业过程划分为若干子块。然后,为了避免故障类型的误划分,将每个子块上容易误分类的故障类型作为一个复合类,在此基础上,为每个子块建立sae-softmax分类模型。然后,为了处理多个sae-softmax分类结果之间的冲突,提出一种改进的d-s证据理论对多个子块的分类结果进行决策融合,以提高决策融合的精度。最后,建立sae-softmax,对决策融合无法分类的故障样本进行分类。
5.基于堆叠自编码器的递阶故障分类方法,其特征在于包括以下步骤:
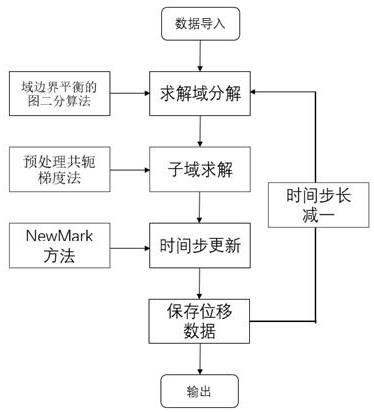
6.a.离线阶段:
7.1)获得历史数据作为训练数据x∈rn×m,其中n表示样本总量,m表示样本包含的变量数,计算正常条件下训练数据的均值和标准差s,标准化训练数据x得到
[0008][0009]
2)根据工业过程的b个操作单元,对标准化后的训练数据进行变量划分,得到b个子块,b个子块对应的数据集为其中b表示第b个子块,表示里第i个变量,为了考虑子块间的相关性,利用互信息评价两个变量之间的相关性,计算第b个子块里的变量与其他变量之间的互信息值
[0010][0011]
其中表示的边缘概率密度,表示的边缘概率密度,表示和的联合概率密度,计算与第b个子块里所有变量之间的互信息值,得到一维向量与第b个子块里所有变量之间的互信息值,得到一维向量其中j=1,2,
…
,mb,计算第b个子块外其他所有变量与第b个子块内变量间的互信息值,则可以得到m
–
mb个一维向量:计算m
–
mb个一维向量的均值得到其中为为的均值,若存在则变量是第b个子块的相关变量,则将加入第b个子块中,则加入相关变量后的第b个子块更新为其中mb′
为第b个子块的变量数,且mb′
》mb,k>1是人为设置的参数,作用是避免子块包含过多的变量;
[0012]
3)为每个子块分别建立sae模型:
[0013]
为了避免故障类别的误划分,首先将每个子块上容易误划分的故障类型作为一个复合类,故障样本的故障类别即为标签,利用复合类数据和不易误划分的故障数据为每个子块训练sae分类模型,sae由l个自编码器(autoencoder,ae)组成,具有提取深层特征的能力,每个ae由输入层、隐含层和输出层组成,隐含层输出为ae提取的特征,输入层和隐含层为编码器,隐含层和输出层为解码器,每个ae的输入层为上一个ae的隐含层,ae的编码器和解码器可以表示为:
[0014]
h=f(wx b)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0015][0016]
其中x表示ae的输入,h表示ae提取的特征,表示ae的输出,w表示输入层到隐含层的权值矩阵,b表示隐含层的偏置向量,表示隐含层到输出层的权值矩阵,表示输出层的偏置向量,f(
·
)表示隐含层的激活函数,g(
·
)表示输出层的激活函数,f
encoder,l
(
·
)表示sae中第l个ae的编码器,f
decoder,l
(
·
)表示sae中第l个ae的解码器,则为第b个子块建立的sae的解码部分和编码部分可以表示为:
[0017][0018][0019]
其中,hb为输入是时sae提取的特征,为输入是时sae的输出;为了实现故障分类,在sae的编码部分后连接一个softmax层,sae的训练分为预训练和微调两个阶段,在预训练阶段,对sae中的每个ae单独训练,利用均方误差损失函数训练ae,均方误差损失函数可以表示为:
[0020][0021]
其中,x(i)表示ae的第i个样本的输入,表示ae的第i个样本的输出,在微调阶段,由于复合类包含多种故障类型,而每种故障类型的样本数量一致,则复合类的样本多于其他故障类型的样本,因此存在样本不均衡的问题,针对样本不均衡,利用加权交叉熵损失函数的思想训练sae模型,采用的损失函数可以表示为:
[0022][0023]
其中yj表示样本的真实标签即故障类别,表示softmax的预测标签,w是权值,当yj的真实标签是复合类时,w=1,当yj的真实标签不是复合类时,w=nc 1,nc为复合类包含故障类型的个数;
[0024]
4)在sae的编码部分后连接一个softmax层实现对故障样本的分类,使用d-s证据理论对多个sae-softmax的分类结果进行决策融合,d-s证据理论能够融合不准确和不完整的信息,已应用于故障诊断领域,θ={a1,a2,...,a
p
}是识别框架,其中的元素是两两互斥的可能性假设,在本方法中θ为所有故障类别的集合,基本概率分配函数(basic probability assignment,bpa)也可称为m函数,可以表示为:
[0025]
m:2
θ
→
[0,1]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0026]
m函数满足以下条件:
[0027][0028]
对b个证据体e1,e2,
…
,eb,m函数分别为m1,m2,
…
,mb,d-s证据组合规则可以表示为:
[0029][0030]
其中为对b个证据体组合的结果,k为归一化系数可以表示为:
[0031][0032]1–
k为证据体之间的冲突程度且0《1
–
k《1,如果1
–
k越大,则证据体之间越冲突,若1–
k接近1,组合结果可能是错误的,在本方法中,b个sae-softmax为b个证据体,故障类型的集合为识别框架,softmax的输出即故障样本故障类别的概率作为m函数,而当多个sae-softmax的输出之间存在高度冲突时,d-s证据理论可能会得到不合理的决策融合结果,为了更加有效地处理多个分类器的冲突,对d-s证据理论进行改进,首先对m函数做出改进:
[0033][0034]
其中q为每个子块上可能发生的故障类别数量,m
′
(ai)为改进后的m函数,meanm为m(a1),m(a2),
…
,m(aq)的均值,maxm为m(a1),m(a2),
…
,m(aq)的最大值,为了进一步提高决策融合的精度,对d-s组合规则进行改进,计算两个证据体之间的归一化系数,ei和ej之间的归一化系数表示为:
[0035][0036]
对于证据体ei,可以得到ei与其他证据之间b
–
1个归一化系数,对b
–
1个归一化系数求均值可得:
[0037][0038]
其中ki越大,ei与其他证据的冲突越小,ei的可信程度越高,根据ki计算ei的权重wi:
[0039][0040]
在进行决策融合时,利用wi对ei的证据体的m函数进行加权,则改进的d-s组合规则可以表示为:
[0041][0042]
其中k
′
可以表示为:
[0043][0044]
5)使用d-s证据理论对多个sae-softmax的分类结果进行决策融合之后,可能存在不能被分类的故障样本,则将这些故障类型作为复合类,并为这些故障类型训练一个sae-softmax分类模型,记为第b 1个sae-softmax;
[0045]
b.在线阶段:
[0046]
1)采集在线样本x
′
,对x
′
标准化得到
[0047][0048]
其中为训练数据x的均值,s为训练数据x的标准差,与公式(1)中的和s相等;
[0049]
2)对进行变量划分得到
[0050]
3)将输入离线建模中的第b个子块的sae-softmax模型,得到第b个sae-softmax的分类结果;
[0051]
4)利用改进的d-s证据理论对b个sae-softmax的分类结果进行决策融合;
[0052]
5)若决策融合结果为复合类,则利用第b 1个sae-softmax实现分类,若决策融合结果不是复合类,则融合结果即为分类结果。
[0053]
有益效果
[0054]
本发明针对非线性大规模工业过程,将整个工业过程划分为多个子块并分别建立sae-softmax分类模型,降低了sae分类模型的复杂度且提高了sae-softmax分类模型的精度,对工业过程的故障诊断具有重要的意义。
附图说明
[0055]
图1所示为本发明方法的流程图;
[0056]
图2所示为ae的示意图;
[0057]
图3所示为te过程的流程图;
[0058]
图4所示为5个子块的sae-softmax分类结果;
[0059]
图5所示为改进d-s证据理论的融合结果;
具体实施方式
[0060]
te过程是真实化工过程的仿真模拟,经常用于验证故障诊断方法的性能。如图3所示为te过程的流程图。te过程能够模拟正常状态和21种故障状态,采集52个变量。本次实验使用的是其中33个变量。te过程包含5个操作单元,分别是输入单元,反应器,分离器,汽提器以及压缩机,每个单元包含的变量如表1所示。本实验的数据集使用的是其中18种故障数据,即故障1,2,4,5,6,7,8,10,11,12,13,14,16,17,18,19,20,21,训练数据每类故障包含480个样本,测试数据每类故障包含800个样本。
[0061]
表1每个单元的变量
[0062][0063]
基于以上描述,按照发明内容,将具体过程实现如下:
[0064]
a.离线阶段:
[0065]
1)对训练数据x∈r
500
×
33
进行标准化,计算x的均值和标准差s,利用公式(1)对x标准化得到
[0066]
2)根据表1对进行变量划分,得到5个子数据集分别为其中为了考虑到子块间的相关性,利用互信息评价
两个变量之间的相关性,计算第b个子块内的变量与其他变量之间的互信息值
[0067][0068]
其中表示的边缘概率密度,表示的边缘概率密度,表示联合概率密度,计算与第b个子块里所有变量之间的互信息值,得到一维向量与第b个子块里所有变量之间的互信息值,得到一维向量其中j=1,2,
…
,mb,计算第b个子块外其他所有变量与第b个子块内变量间的互信息值,则可以得到m
–
mb个一维向量:计算m
–
mb个一维向量的均值得到其中为为的均值,若存在则变量是第b个子块的相关变量,则将加入第b个子块中,则加入相关变量后的第b个子块为其中mb′
为第b个子块的变量数,且mb′
》mb,k=1.04,如表2所示为子块划分的结果和每个子块上发生的故障类型,其中[
·
]表示复合类,在表2中只有故障19是只发生在第5个子块的故障,因此,当只有第5个子块检测到异常时,可确定发生故障为故障19,只有故障20是发生在第3个子块、第4个子块和第5个子块,因此当第3个子块,第4个子块和第5个子块检测到异常时,可判断发生的故障为故障20,因此,不需要sae就可以识别故障19和故障20,对每个子块取窗宽为40的滑动窗,得到动态数据
[0069]
表2子块划分的结果和每个子块上发生的故障类型
[0070][0071][0072]
3)以为训练数据,分别训练5个sae-softmax模型,5个sae-softmax的结构如表3所示,其中“神经元数量”表示sae-softmax的每一层神经元的数量,五个sae-softmax均有3个隐含层,输出层为softmax层,5个sae的3个隐含层和输出层的激活函数分别为高斯函数-线性函数-线性函数-sofmax,其中高斯函数和线性函数分别表示为:
[0073][0074]flinear
(z)=z
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(22)
[0075]
其中z表示输入向量,所有sae的优化器均是adam优化器,学习率是0.001;
[0076]
表3五个子块sae的结构
[0077][0078]
4)使用d-s证据理论对多个sae的分类结果进行决策融合,d-s证据理论能够融合不准确和不完整的信息,已应用于故障诊断领域,识别框架为θ={f1,f2,f4,f5,f6,f7,f8,f
10
,f
11
,f
12
,f
13
,f
14
,f
16
,f
17
,f
18
,f
21
},其中f1表示故障1,f2表示故障2,
…
,f
21
表示故障21,softmax的输出值作为基本概率分配函数的值即m函数值,对m函数做出改进:
[0079][0080]
其中fi为sae-softmax可能的分类结果(i=1,2,
…
,q),q为sae-softmax可能发生故障的类别数量,m
′
(fi)为改进后的m函数,meanm为m(f1),m(f2),
…
,m(fq)的均值,maxm为m(f1),m(f2),
…
,m(fq)的最大值,为了提高决策融合的精度,提出改进的d-s组合规则:
[0081][0082]
其中f为θ中的一个故障类型,为融合后的m函数,fi为第i个子块上发生的故障类型,k
′
为归一化系数:
[0083][0084]
wi为mi′
函数的权值,可以通过以下公式得到
[0085][0086]
其中k
i,j
表示第i个sae-softmax和第j个sae-softmax分类结果之间的归一化系数,ki为第i个sae-softmax与其他sae-softmax分类结果两两之间归一化系数的均值;
[0087]
5)由于故障11和故障14发生在第2个子块且都属于复合类,决策融合无法区分这
两个故障,将这两个故障记为fc1,由于故障5,8,10,12,13,16,18发生在5个子块且都是复合类里的故障类型,因此决策融合也无法区分这些故障,将这些故障记为fc2,以故障5、8、10、11、12、13、14、16、18的动态数据训练第6个sae-softmax分类模型,动态数据通过对故障5、8、10、11、12、13、14、16、18的训练数据取窗宽为40的滑动窗得到,训练数据中的每个样本具有33个变量,该模型由一个输入层,三个隐含层和一个输入层组成,神经元个数分别是1320,660,330,165,16,3个隐含层和输出层的激活函数分别为高斯函数,线性函数,线性函数,softmax,优化器均是adam优化器,学习率是0.001;
[0088]
b.在线阶段:
[0089]
1)采集在线样本x
′
,利用公式(1)对x
′
标准化得到
[0090]
2)按照表2对进行变量划分得到对取窗宽为40的滑动窗得到动态数据
[0091]
3)将输入离线建模中的第b个子块的sae-softmax模型,得到第b个sae-softmax的分类结果;
[0092]
4)利用改进的d-s证据理论对5个sae-softmaxs的分类结果进行决策融合;
[0093]
5)若决策融合结果为fc1或者fc2,则将输入第6个sae-softmax分类模型中实现故障分类,否则,决策融合结果为故障分类的结果;
[0094]
上述步骤即为本方法应用在te过程故障分类的具体应用。本实验利用故障诊断率(fdr)评估方法的性能,fdr是指正确分类为c类的样本数量与c类样本的总量,fdr越大则表明方法的性能越好。如图4为5个子块的sae-softmaxs分类结果,其中22,23,24,25,26表示复合类,图5为改进d-s证据理论的融合结果,为了说明本方法的有效性,将本方法与sae-softmax,线性判别分析(lda)和支持向量机(svm)相比较,如表4所示为本方法、sae-softmax、lda和svm对te过程16种故障的fdrs。sae-softmax由一个输入层、三个隐含层和一个输出层组成,神经元数量分别为1320,660,330,165,16,激活函数为高斯函数-线性函数-线性函数-softmax。本方法在故障8,10,11,12,13,16,17,18下的fdrs均高于其他三种方法,且本方法的fdrs的均值是四种方法中最高的,因此,本方法故障分类的性能有所提升。除此之外,本方法建立的sae-softmax模型的结构比单一的sae-softmax模型结构更简单,这意味着本方法更有利于大规模工业过程的故障分类。因此本方法不仅简化了sae-softmax分类模型的结构也提高了sae模型的分类性能。
[0095]
表4本方法、sae、lda和svm对te过程16种故障的fdrs
[0096][0097]
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。