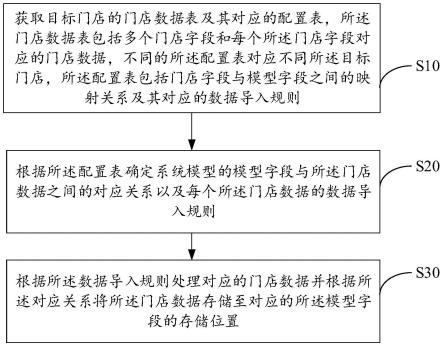
1.本发明涉及知识图谱技术领域,尤其涉及一种基于知识图谱技术的数据智能分级方法。
背景技术:
2.数据管理需要遵循一定的优先级开展,在具体的治理过程中,核心关键数据的识别,对下一步的数据治理、数据分析将起到至关重要的作用。而识别关键数据,通常依赖业务经验、人工定义,存在一定的偏差、盲区;如何精准的识别关键物理表,是需要解决的问题。
技术实现要素:
3.本发明提供了一种基于知识图谱技术的数据智能分级方法,基于数据物理表的关系,对现有的数据进行重要性评估,提高了核心关键数据的识别效率和数据的智能分级水平。
4.本发明提供了一种基于知识图谱技术的数据智能分级方法,包括:
5.s1:获取数据物理表之间的血缘关系,根据血缘关系生成数据物理表知识图谱;
6.s2:利用改进的特征向量中心性算法,计算数据物理表知识图谱中物理表的网络权重;
7.s3:获取两个特征数据集,两个特征数据集为:数据物理表的数据访问情况数据集和数据更新频率数据集,基于k-means聚类算法对所述两个特征数据集进行聚类分析,生成聚类分析结果;
8.s4:根据聚类分析结果和网络权重,基于层次分析法和熵权法,构建数据物理表重要度评估公式;
9.s5:利用数据物理表重要度评估公式对数据物理表进行评估,根据评估结果获得核心关键数据。
10.进一步地,s1包括:构建第一本体模型,基于第一本体模型生成数据物理表的知识图谱;所述构建第一本体模型的方法包括:
11.s101:获取用于创建数据物理表知识图谱的本体模型;
12.s102:基于预设的本体模型质量评价条件对本体模型进行评价;所述本体模型质量评价条件基于数据的完整性、简洁性、清晰性和可用性制定;
13.s103:筛选出评价结果符合预设评价结果阈值的第一本体模型。
14.进一步地,s1包括:
15.s104:解析数据物理表之间的血缘关系,获取血缘关系的特征类别;
16.s105:选取所述特征类别中的归属性、层次性、多源性特征,基于预设的关系抽取模型进行关系抽取,获得数据物理表的实体关系;
17.s106:将数据物理表、数据物理表的实体关系输入第一本体模型,生成数据物理表
的知识图谱。
18.进一步地,s2包括:
19.s201:采用改进的特征向量中心性算法对数据物理表知识图谱中的实体节点进行重要度分析;所述改进的特征向量中心性算法为基于加权的pagerank算法;
20.s202:获取实体节点的重要度数组、节点总数、阻尼系数和收敛门限,并进行初始化赋值;
21.s203:根据初始化赋值,计算实体节点的出弧计数矩阵、出弧权重和矩阵;
22.s204:对实体节点重要度进行迭代计算,获得连续两次的重要度数组值,计算获得连续两次的重要度数组值的差值;
23.s205:将所述差值的正无穷范数与收敛门限进行比较,若所述正无穷范数小于收敛门限,则迭代结束,获得排序后的重要度矩阵;
24.s206:基于排序后的重要度矩阵,获得数据物理表知识图谱物理表的网络权重。
25.进一步地,s3包括:
26.s301:获取数据物理表的数据访问情况特征数据集、数据更新频率特征数据集,将数据访问情况特征数据集、数据更新频率特征数据集分别划分为训练集和验证集,并设置p个初始聚类中心;
27.s302:获取训练集中的每一个样本,计算其与每一个质心的距离,并将其划分到距离最近的质心所属集合;
28.s303:重新计算每个集合的质心,并计算新的质心与原来质心的第一距离;
29.s304:若所述第一距离小于预设的距离阈值,则终止聚类,获得p个聚类质心;
30.s305:若所述第一距离大于预设的距离阈值,则重复步骤s302至s304;
31.s306:获取测试集中的每一个样本,计算其与p个簇的质心的距离,将所述距离转换成相应的分值进行结果输出,得到聚类分析结果。
32.进一步地,s4包括:
33.s401:基于聚类分析结果和网络权重,构建数据物理表的重要度评估指标;
34.s402:通过层次分析法计算获得重要度评估指标的主观权重;
35.s403:通过熵权法计算获得重要度评估指标的客观权重;
36.s404:根据主观权重和客观权重,生成重要度评估指标的复合权重,基于复合权重,生成数据物理表的重要度评估公式。
37.进一步地,s5包括:
38.s501:利用数据物理表重要度评估公式对数据物理表进行评估,获得评估结果列表;
39.s502:基于预设的若干个排序规则,对评估结果列表进行排序,获得若干个排序结果序列;
40.s503:获取排序结果序列中排序最前的数据结果所对应的数据,将所述数据作为核心关键数据进行推荐。
41.进一步地,s5还包括根据评估结果列表生成评估级别;
42.s5011:基于预设的对应规则,设置评估结果与评估级别的对应关系库;
43.s5012:设置评估级别,将重要度级别分为高级、中级和低级;
44.s5013:将重要度评估结果输入对应关系库,生成相对应的评估级别。
45.进一步地,还包括s6,根据数据评估级别进行分类存储:
46.s601:获取数据级别中的参数,基于所述参数,制定数据分类存储策略;所述参数包括物理表影响下游物理表的个数、数据任务的个数和数据报表的张数;
47.s602:根据不同的参数,生成相应的分类存储策略;当影响下游物理表的个数大于第一数量阈值范围上限、并且数据任务的个数大于第二数量阈值范围上限、并且数据报表的张数大于第三数量阈值范围的上限时,生成第一存储策略;
48.当影响下游物理表的个数位于第一数量阈值范围内、并且数据任务的个数位于第二数量阈值范围内、并且数据报表的张数位于第三数量阈值范围内时,生成第二存储策略;
49.当影响下游物理表的个数小于第一数量阈值范围下限、并且数据任务的个数小于第二数量阈值范围下限、并且数据报表的张数小于第三数量阈值范围的下限时,生成第三存储策略;
50.当影响下游物理表的个数位于第一数量阈值范围内,若数据任务的个数大于第二数量阈值范围上限、并且数据报表的张数大于第三数量阈值范围上限时,生成第一存储策略;
51.s603:根据所述第一存储策略、第二存储策略、第三存储策略,对数据进行分类存储。
52.进一步地,包括s7,根据评估级别进行分类展示:
53.s701:根据预设的数据评估级别,获取数据类别和数据标签;
54.s702:基于数据级别、数据类别和数据标签,构建数据分级展示模型;
55.s703:基于数据分级展示模型,结合预设的可视化展示参数,对数据进行可视化处理,获得可视化数据;
56.s704:将可视化数据以图表形式在可视化设备上进行数据分级展示。
57.本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。
58.下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
59.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
60.图1为本发明的一种基于知识图谱技术的数据智能分级方法步骤示意图;
61.图2为本发明的一种基于知识图谱技术的数据智能分级方法筛选本体模式的步骤示意图;
62.图3为本发明一种基于知识图谱技术的数据智能分级方法的获取网络权重的步骤示意图。
具体实施方式
63.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实
施例仅用于说明和解释本发明,并不用于限定本发明。
64.本发明提供了一种基于知识图谱技术的数据智能分级方法,如图1所示,包括:
65.s1:获取数据物理表之间的血缘关系,根据血缘关系生成数据物理表知识图谱;
66.s2:利用改进的特征向量中心性算法,计算数据物理表知识图谱中物理表的网络权重;
67.s3:获取两个特征数据集,两个特征数据集为:数据物理表的数据访问情况数据集和数据更新频率数据集,基于k-means聚类算法对所述两个特征数据集进行聚类分析,生成聚类分析结果;
68.s4:根据聚类分析结果和网络权重,基于层次分析法和熵权法,构建数据物理表重要度评估公式;
69.s5:利用数据物理表重要度评估公式对数据物理表进行评估,根据评估结果获得核心关键数据。
70.上述技术方案的工作原理为:通过获取数据物理表之间的血缘关系,根据血缘关系生成数据物理表知识图谱,可以保证物理表知识图谱的质量;通过改进的特征向量中心性算法,计算数据物理表知识图谱中物理表的网络权重,为后续的重要度分析提供依据;通过获取数据物理表的数据访问情况数据集和数据更新频率数据集,基于k-means聚类算法对所述两个特征数据集进行聚类分析,生成聚类分析结果,保证了数据分类的有效实施;通过根据聚类分析结果和网络权重,基于层次分析法和熵权法,构建数据物理表重要度评估公式,可以保证重要度评估公式的准确度;最后,利用数据物理表重要度评估公式对数据物理表进行评估,根据评估结果获得核心关键数据。
71.上述技术方案的有益效果为:采用本实施例提供的方案,本发明基于数据物理表的关系,对现有的数据进行重要性评估,提高了核心关键数据的识别效率和数据的智能分级水平。
72.在一个实施例中,如图2所示,s1包括:构建第一本体模型,基于第一本体模型生成数据物理表的知识图谱;所述构建第一本体模型的方法包括:
73.s101:获取用于创建数据物理表知识图谱的本体模型;
74.s102:基于预设的本体模型质量评价条件对本体模型进行评价;所述本体模型质量评价条件基于数据的完整性、简洁性、清晰性和可用性制定;
75.s103:筛选出评价结果符合预设评价结果阈值的第一本体模型。
76.上述技术方案的工作原理为:本体即图谱知识模型,是基于知识概念关系抽象而成的知识表示规范,在知识工程中用于对客观事物进行分层的系统化描述;本实施例基于本体构建知识图谱,具体为:构建第一本体模型,基于第一本体模型生成数据物理表的知识图谱;所述构建第一本体模型的方法包括:
77.s101:获取用于创建数据物理表知识图谱的本体模型;
78.s102:基于预设的本体模型质量评价条件对本体模型进行评价;所述本体模型质量评价条件基于数据的完整性、简洁性、清晰性和可用性制定;
79.s103:筛选出评价结果符合预设评价结果阈值的第一本体模型。
80.上述技术方案的有益效果为:采用本实施例提供的方案,通过基于本体模型构建知识图谱,有利于知识图谱构建的质量。
81.在一个实施例中,s1包括:
82.s104:解析数据物理表之间的血缘关系,获取血缘关系的特征类别;
83.s105:选取所述特征类别中的归属性、层次性、多源性特征,基于预设的关系抽取模型进行关系抽取,获得数据物理表的实体关系;
84.s106:将数据物理表、数据物理表的实体关系输入第一本体模型,生成数据物理表的知识图谱。
85.上述技术方案的工作原理为:通过数据物理表之间的血缘关系,可以获取到高质量的物理表之间的关系,有利于关系的提取和知识图谱的构建;具体为:
86.s104:解析数据物理表之间的血缘关系,获取血缘关系的特征类别;
87.s105:选取所述特征类别中的归属性、层次性、多源性特征,基于预设的关系抽取模型进行关系抽取,获得数据物理表的实体关系;
88.s106:将数据物理表、数据物理表的实体关系输入第一本体模型,生成数据物理表的知识图谱。
89.上述技术方案的有益效果为:采用本实施例提供的方案,通过基于物理表之间的血缘关系获得生成知识图谱的实体关系,有利于构建高质量的知识图谱。
90.在一个实施例中,如图3所示,s2包括:
91.s201:采用改进的特征向量中心性算法对数据物理表知识图谱中的实体节点进行重要度分析;所述改进的特征向量中心性算法为基于加权的pagerank算法;
92.s202:获取实体节点的重要度数组、节点总数、阻尼系数和收敛门限,并进行初始化赋值;
93.s203:根据初始化赋值,计算实体节点的出弧计数矩阵、出弧权重和矩阵;
94.s204:对实体节点重要度进行迭代计算,获得连续两次的重要度数组值,计算获得连续两次的重要度数组值的差值;
95.s205:将所述差值的正无穷范数与收敛门限进行比较,若所述正无穷范数小于收敛门限,则迭代结束,获得排序后的重要度矩阵;
96.s206:基于排序后的重要度矩阵,获得数据物理表知识图谱物理表的网络权重。
97.上述技术方案的工作原理为:特征向量中心性算法将节点的重要性与其关联节点的重要性联系起来,即当与个体相关联的节点在网络中具有更大的影响力时,该个体对网络的间接影响力会更大,这样的个体在网络中也会具有更高的地位。特征向量中心性度量节点在网络中的直接与间接影响力,当节点具有越多邻居且邻居节点重要度越高时其特征向量中心性越强。pagerank算法是google基于特征向量中心性思想提出的网页重要度评估算法,本实施例根据该算法提出基于加权的pagerank算法,通过带权物理表重要度表征物理表节点中心性,通过阻尼系数等保证结果收敛,规定收敛门限以作为算法终止的依据。具体为:
98.s201:采用改进的特征向量中心性算法对数据物理表知识图谱中的实体节点进行重要度分析;所述改进的特征向量中心性算法为基于加权的pagerank算法;
99.s202:获取实体节点的重要度数组、节点总数、阻尼系数和收敛门限,并进行初始化赋值;
100.s203:根据初始化赋值,计算实体节点的出弧计数矩阵、出弧权重和矩阵;
101.s204:对实体节点重要度进行迭代计算,获得连续两次的重要度数组值,计算获得连续两次的重要度数组值的差值;
102.s205:将所述差值的正无穷范数与收敛门限进行比较,若所述正无穷范数小于收敛门限,则迭代结束,获得排序后的重要度矩阵;
103.s206:基于排序后的重要度矩阵,获得数据物理表知识图谱物理表的网络权重。
104.上述技术方案的有益效果为:采用本实施例提供的方案,通过基于加权的pagerank算法计算出的关键节点,具有较高的有效性和准确性,对提供准确的分析结果具有一定的可靠性。
105.在一个实施例中,s3包括:
106.s301:获取数据物理表的数据访问情况特征数据集、数据更新频率特征数据集,将数据访问情况特征数据集、数据更新频率特征数据集分别划分为训练集和验证集,并设置p个初始聚类中心;
107.s302:获取训练集中的每一个样本,计算其与每一个质心的距离,并将其划分到距离最近的质心所属集合;
108.s303:重新计算每个集合的质心,并计算新的质心与原来质心的第一距离;
109.s304:若所述第一距离小于预设的距离阈值,则终止聚类,获得p个聚类质心;
110.s305:若所述第一距离大于预设的距离阈值,则重复步骤s302至s304;
111.s306:获取测试集中的每一个样本,计算其与p个簇的质心的距离,将所述距离转换成相应的分值进行结果输出,得到聚类分析结果。
112.上述技术方案的工作原理为:s3包括:
113.s301:获取数据物理表的数据访问情况特征数据集、数据更新频率特征数据集,将数据访问情况特征数据集、数据更新频率特征数据集分别划分为训练集和验证集,并设置p个初始聚类中心;
114.s302:获取训练集中的每一个样本,计算其与每一个质心的距离,并将其划分到距离最近的质心所属集合;
115.s303:重新计算每个集合的质心,并计算新的质心与原来质心的第一距离;
116.s304:若所述第一距离小于预设的距离阈值,则终止聚类,获得p个聚类质心;
117.s305:若所述第一距离大于预设的距离阈值,则重复步骤s302至s304;
118.s306:获取测试集中的每一个样本,计算其与p个簇的质心的距离,将所述距离转换成相应的分值进行结果输出,得到聚类分析结果。
119.上述技术方案的有益效果为:采用本实施例提供的方案,通过根据聚类算法进行聚类,可以提高数据物理表分类的准确性,有利于更好的分级分析。
120.在一个实施例中,s4包括:
121.s401:基于聚类分析结果和网络权重,构建数据物理表的重要度评估指标;
122.s402:通过层次分析法计算获得重要度评估指标的主观权重;
123.s403:通过熵权法计算获得重要度评估指标的客观权重;
124.s404:根据主观权重和客观权重,生成重要度评估指标的复合权重,基于复合权重,生成数据物理表的重要度评估公式。
125.上述技术方案的工作原理为:层次分析法是一种主观赋予权重值的方法,虽然得
出的评价指标的权重值的合理性通常比较高,但是它的主观随意性却比较大;熵权法是一种客观赋予权重值的方法,它主要体现的是原始数据所代表的信息,使得最终的评估结果极具客观性,但是该种方法并未涉及到专家的经验知识和决策者的意见,导致最后得到的权重值与指标的实际重要性程度不相符。本实施例运用层次分析法获取的主观权重与运用熵权法获取的客观权重进行综合从而获取复合权重,有助于生成科学有效的重要度评估公式;具体为:
126.s401:基于聚类分析结果和网络权重,构建数据物理表的重要度评估指标;
127.s402:通过层次分析法计算获得重要度评估指标的主观权重;
128.s403:通过熵权法计算获得重要度评估指标的客观权重;
129.s404:根据主观权重和客观权重,生成重要度评估指标的复合权重,基于复合权重,生成数据物理表的重要度评估公式。
130.上述技术方案的有益效果为:采用本实施例提供的方案,通过采取复合权重作为数据物理表重要度评估公式的生成依据,可以有效的保证评估公式的准确性。
131.在一个实施例中,s5包括:
132.s501:利用数据物理表重要度评估公式对数据物理表进行评估,获得评估结果列表;
133.s502:基于预设的若干个排序规则,对评估结果列表进行排序,获得若干个排序结果序列;
134.s503:获取排序结果序列中排序最前的数据结果所对应的数据,将所述数据作为核心关键数据进行推荐。
135.上述技术方案的工作原理为:s5包括:
136.s501:利用数据物理表重要度评估公式对数据物理表进行评估,获得评估结果列表;
137.s502:基于预设的若干个排序规则,对评估结果列表进行排序,获得若干个排序结果序列;
138.s503:获取排序结果序列中排序最前的数据结果所对应的数据,将所述数据作为核心关键数据进行推荐。
139.为了更好的对评估结果进行分级,有必要设置相应的级别阈值,在级别阈值设置上,基于网络权重、数据访问情况、数据更新频率以及血缘关系四个影响因素,设置四个重要度值,并设置相应的调节参数,计算出平均重要度值,通过调节影响因子的数值,可以获得不同的阈值,根据阈值与重要度值进行比较,可以将数据分为不同的级别;
[0140][0141]
上面公式中,t为全部数据物理表的平均重要度值,其中k为数据中核心关键物理表的的总个数,r代表第r个物理表,1《r《k,wr是第r个物理表的网络权值的重要度值,α是其对应的调节参数;sr是第r个物理表的数据访问情况的重要度值,β是其对应的调节参数;rr是第r个物理表的数据更新频率的重要度值,ε是其对应的调节参数;gr是第r个物理表的数据的血缘关系的重要度值,δ是其对应的调节参数;
[0142]
上述技术方案的有益效果为:采用本实施例提供的方案,通过对评估结果列表的
排序,可以清晰地显示出核心关键数据;通过设置级别阈值,可以更准确的划分数据级别。
[0143]
在一个实施例中,s5还包括根据评估结果列表生成评估级别;
[0144]
s5011:基于预设的对应规则,设置评估结果与评估级别的对应关系库;
[0145]
s5012:设置评估级别,将重要度级别分为高级、中级和低级;
[0146]
s5013:将重要度评估结果输入对应关系库,生成相对应的评估级别。
[0147]
上述技术方案的工作原理为:根据评估结果,生成评估级别,有利于更好地区分分级数据;具体包括:
[0148]
s5011:基于预设的对应规则,设置评估结果与评估级别的对应关系库;
[0149]
s5012:设置评估级别,将重要度级别分为高级、中级和低级;
[0150]
s5013:将重要度评估结果输入对应关系库,生成相对应的评估级别。
[0151]
上述技术方案的有益效果为:采用本实施例提供的方案,通过生成与评估结果相对应地评估级别,可以提高数据分级区分的效果。
[0152]
在一个实施例中,还包括s6,根据数据评估级别进行分类存储:
[0153]
s601:获取数据级别中的参数,基于所述参数,制定数据分类存储策略;所述参数包括物理表影响下游物理表的个数、数据任务的个数和数据报表的张数;
[0154]
s602:根据不同的参数,生成相应的分类存储策略;当影响下游物理表的个数大于第一数量阈值范围上限、并且数据任务的个数大于第二数量阈值范围上限、并且数据报表的张数大于第三数量阈值范围的上限时,生成第一存储策略;
[0155]
当影响下游物理表的个数位于第一数量阈值范围内、并且数据任务的个数位于第二数量阈值范围内、并且数据报表的张数位于第三数量阈值范围内时,生成第二存储策略;
[0156]
当影响下游物理表的个数小于第一数量阈值范围下限、并且数据任务的个数小于第二数量阈值范围下限、并且数据报表的张数小于第三数量阈值范围的下限时,生成第三存储策略;
[0157]
当影响下游物理表的个数位于第一数量阈值范围内,若数据任务的个数大于第二数量阈值范围上限、并且数据报表的张数大于第三数量阈值范围上限时,生成第一存储策略;
[0158]
s603:根据所述第一存储策略、第二存储策略、第三存储策略,对数据进行分类存储。
[0159]
上述技术方案的工作原理为:根据数据评估级别进行分类存储,可以提高存储的质量,从而有利于数据的调用和管理;具体为:
[0160]
s601:获取数据级别中的参数,基于所述参数,制定数据分类存储策略;所述参数包括物理表影响下游物理表的个数、数据任务的个数和数据报表的张数;
[0161]
s602:根据不同的参数,生成相应的分类存储策略;当影响下游物理表的个数大于第一数量阈值范围上限、并且数据任务的个数大于第二数量阈值范围上限、并且数据报表的张数大于第三数量阈值范围的上限时,生成第一存储策略;
[0162]
当影响下游物理表的个数位于第一数量阈值范围内、并且数据任务的个数位于第二数量阈值范围内、并且数据报表的张数位于第三数量阈值范围内时,生成第二存储策略;
[0163]
当影响下游物理表的个数小于第一数量阈值范围下限、并且数据任务的个数小于第二数量阈值范围下限、并且数据报表的张数小于第三数量阈值范围的下限时,生成第三
存储策略;
[0164]
当影响下游物理表的个数位于第一数量阈值范围内,若数据任务的个数大于第二数量阈值范围上限、并且数据报表的张数大于第三数量阈值范围上限时,生成第一存储策略;
[0165]
s603:根据所述第一存储策略、第二存储策略、第三存储策略,对数据进行分类存储。
[0166]
上述技术方案的有益效果为:采用本实施例提供的方案,通过制定不同的而存储策略进行分类存储,可以保证存储的效果,有利于提高数据的管理效率。
[0167]
在一个实施例中,包括s7,根据评估级别进行分类展示:
[0168]
s701:根据预设的数据评估级别,获取数据类别和数据标签;
[0169]
s702:基于数据级别、数据类别和数据标签,构建数据分级展示模型;
[0170]
s703:基于数据分级展示模型,结合预设的可视化展示参数,对数据进行可视化处理,获得可视化数据;
[0171]
s704:将可视化数据以图表形式在可视化设备上进行数据分级展示。
[0172]
上述技术方案的工作原理为:根据数据的评估级别进行分类展示,并进行可视化的展示,可以直观地显示数据的分类效果;具体为:
[0173]
s701:根据预设的数据评估级别,获取数据类别和数据标签;
[0174]
s702:基于数据级别、数据类别和数据标签,构建数据分级展示模型;
[0175]
s703:基于数据分级展示模型,结合预设的可视化展示参数,对数据进行可视化处理,获得可视化数据;
[0176]
s704:将可视化数据以图表形式在可视化设备上进行数据分级展示。
[0177]
上述技术方案的有益效果为:采用本实施例提供的方案,通过进行数据的分类可视化展示,可以提高数据分类管理的效果。
[0178]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。