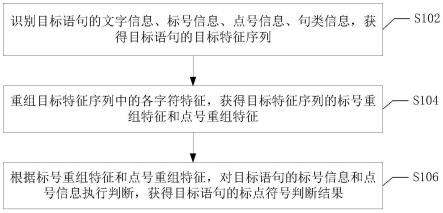
一种基于hdf5格式的核反应数据库制作方法及装置
技术领域:
:1.本公开涉及数据处理
技术领域:
:,尤其涉及一种基于hdf5格式的核反应数据库制作方法及装置、电子设备和存储介质。
背景技术:
::2.传统的蒙特卡罗数据库主要为ace格式,该格式的数据库通过将不同核素的核反应数据以一维数组的方式存储在文本文件中,使这些文本文件形成了ace格式数据库。3.核反应蒙特卡罗程序在使用ace格式的数据库时首先需要读入数据库目录文件,根据目录文件中给出的数据库路径及对应的数据文本文件中核数据的起始位置和个数在指定路径下将核数据读入程序中。由于读入的是一维数组,然而其中包含种类繁多的核数据(以连续能量中子数据库举例,其核数据包含了核反应截面数据、能量分布数据、角分布数据,对于可裂变核素还包含裂变中子数据以及概率表),蒙卡程序在使用这些数据前需要通过一套复杂的索引方法在一维数组中查找对应的数据,所以数据访问效率较低。4.由于ace格式的数据库使用njoy程序加工而成,且所述ace格式的数据库将大量核数据不加区分地罗列在文本文件中,各类数据前没有对应的标签,从而导致ace格式的数据库数据结构固定,用户无法轻易的根据自己的需求对数据库进行扩充,且基本不具备人的可读性。技术实现要素:5.本公开提供了一种基于hdf5格式的核反应数据库制作方法及装置、电子设备和存储介质。其主要目的在于解决ace格式数据库存在着数据结构固定,用户无法轻易的根据自己的需求对数据库进行扩充,基本不具备人的可读性,数据访问效率较低,占用存储空间大的问题。6.根据本公开的第一方面,提供了一种基于hdf5格式的核反应数据库制作方法,包括:7.基于第一预设类方法读取ace格式数据库的目录文件;8.基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对;9.通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应;10.将所述第二存储数据表参数传输至第三预设类方法;11.通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对;12.基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应;13.将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。14.可选的,所述基于第一预设类方法读取ace格式数据库的目录文件包括:15.基于预设输入方式,输入所述目录文件的第一绝对路径;16.基于预设输入方式,输入第二绝对路径,所述第二绝对路径为hdf5格式数据库的生成路径与存储路径;17.根据所述第一绝对路径,使用第一预设类方法读取ace格式数据库的目录文件。18.可选的,在所述通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数之前,所述方法还包括:19.基于预设输入方式,输入所述第二数据表标识字符串。20.可选的,所述通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典包括:21.基于所述第二数据表标识字符串的标识后缀,确定数据库类型;22.通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法;23.通过所述第四预设类方法基于所述第二存储数据表参数从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二存储数据表参数包括ace格式数据库的相对路径、数据表所在数据文件的起始位置和数据表长度。24.可选的,所述方法应用于制作连续能量中子数据库、连续能量光原数据库、连续能量光核数据库、中子热化库、多群数据库、连续能量电子数据库。25.根据本公开的第二方面,提供了一种基于hdf5格式的核反应数据库制作装置,包括:26.读取单元,用于基于第一预设类方法读取ace格式数据库的目录文件;27.第一解析单元,用于基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对;28.第一获取单元,用于通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应;29.传输单元,用于将所述第二存储数据表参数传输至第三预设类方法;30.第二解析单元,用于通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对;31.第二获取单元,用于基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应;32.写入单元,用于将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。33.可选的,所述读取单元包括:34.第一输入模块,用于基于预设输入方式,输入所述目录文件的第一绝对路径;35.第二输入模块,用于基于预设输入方式,输入第二绝对路径,所述第二绝对路径为hdf5格式数据库的生成路径与存储路径;36.读取模块,用于根据所述第一绝对路径,使用第一预设类方法读取ace格式数据库的目录文件。37.可选的,所述装置还包括:38.第二输入单元,用于基于预设输入方式,输入所述第二数据表标识字符串。39.可选的,所述第二解析单元包括:40.确定模块,用于基于所述第二数据表标识字符串的标识后缀,确定数据库类型;41.调用模块,用于通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法;42.解析模块,用于通过所述第四预设类方法基于所述第二存储数据表参数从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二存储数据表参数包括ace格式数据库的相对路径、数据表所在数据文件的起始位置和数据表长度。43.可选的,所述装置应用于制作连续能量中子数据库、连续能量光原数据库、连续能量光核数据库、中子热化库、多群数据库、连续能量电子数据库。44.根据本公开的第三方面,提供了一种电子设备,包括:45.至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行前述第一方面所述的方法。46.根据本公开的第四方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行前述第一方面所述的方法。47.根据本公开的第五方面,提供了一种计算机程序产品,包括计算机程序,所述计算机程序在被处理器执行时实现如前述第一方面所述的方法。48.本公开提供的基于hdf5格式的核反应数据库制作方法及装置、电子设备和存储介质,基于第一预设类方法读取ace格式数据库的目录文件;基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对;通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应;将所述第二存储数据表参数传输至第三预设类方法;通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对;基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应;将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。与相关技术相比,基于对ace格式数据库目录文件的解析,得到第一字典,基于输入的第二数据表标识字符串,在所述第一字典中遍历查询得到与第二数据表标识字符串对应的第二存储数据表参数,基于所述第二存储数据表参数,索引读取ace格式数据库的目标数据文件,对所述数据文件进行解析,并写入hdf5格式的文件,得到hdf5格式数据库,通过改变数据库格式从而解决ace格式数据库数据结构固定而难以扩展,不具备人的可读性,数据访问效率低,占用存储空间大的问题。49.应当理解,本部分所描述的内容并非旨在标识本技术的实施例的关键或重要特征,也不用于限制本技术的范围。本技术的其它特征将通过以下的说明书而变得容易理解。附图说明50.附图用于更好地理解本方案,不构成对本公开的限定。其中:51.图1为本公开实施例所提供的一种基于hdf5格式的核反应数据库制作方法的流程示意图;52.图2为本公开实施例提供的另一种基于hdf5格式的核反应数据库制作方法的流程示意图;53.图3a本公开实施例提供的一种neutronaceparser类设计部分结构示意图;54.图3b本公开实施例提供的一种neutronaceparser类设计另一部分结构示意图;55.图4a本公开实施例提供的一种photonuclearaceparser类设计部分结构示意图;56.图4b本公开实施例提供的一种photonuclearaceparser类设计另一部分结构示意图;57.图5本公开实施例提供的一种thermalneutronaceparser类设计结构示意图;58.图6本公开实施例提供的一种photoatomicaceparser类设计部分结构示意图;59.图7本公开实施例提供的一种multigroupaceparser类设计结构示意图;60.图8本公开实施例提供的一种electronaceparser类设计结构示意图;61.图9为本公开实施例所提供的一种基于hdf5格式的核反应数据库制作装置的结构示意图;62.图10为本公开实施例所提供的另一种基于hdf5格式的核反应数据库制作装置的结构示意图;63.图11为本公开实施例的示例电子设备300的示意性框图。具体实施方式64.以下结合附图对本公开的示范性实施例做出说明,其中包括本公开实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本公开的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。65.下面参考附图描述本公开实施例的基于hdf5格式的核反应数据库制作方法及装置、电子设备和存储介质。66.图1为本公开实施例所提供的一种基于hdf5格式的核反应数据库制作方法的流程示意图。如图1所示,该方法包含以下步骤:67.步骤101,基于第一预设类方法读取ace格式数据库的目录文件。68.所述第一预设类方法,为提前设计用于读取数据的算法。69.为了得到ace格式数据库的目录文件,基于输入的目录文件绝对路径,通过第一预设类方法获取ace格式数据库的目录文件,进而执行下一步操作。70.步骤102,基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对。71.所述第一存储数据表参数包括核素原子质量比、数据表所在数据文件的相对路径、核数据在数据文件中开始的行以及数据数目,对于个别类型数据库还有数据库制作的温度。72.为了对所述第一存储数据表参数内容进行获取,基于第二预设类方法将所述目录文件解析为第一数据表标识字符串和第一存储数据表参数为键值对的第一字典,从而实现使用预设类方法调用输入的键对应的值,所述键即指第一数据表标识字符串,值为第一存储数据表参数,二者形成键值对,进而实现输入指第一数据表标识字符串调用对应的第一存储数据表参数。73.步骤103,通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应。74.为了得到第一存储数据表参数中目标内容,通过输入的第二数据表标识字符串在所述第一字典中匹配查询其对应的存储数据表参数,即第二存储数据表参数;实现过程即是,基于形成的键值对第一字典,在第一字典中查询输入键所匹配的值进行输出。75.所述第一字典指键值对的数据集,所述第二数据表标识字符串为用户为了获取第一存储数据表参数中目标内容输入索引字段,第二存储数据表参数为目标内容。76.步骤104,将所述第二存储数据表参数传输至第三预设类方法。77.基于所述第二存储数据表参数,由第三预设类方法进行数据库制作的后续处理。78.步骤105,通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对。79.所述第三预设类方法为编写的算法,所述第三预设类方法通过数据库类型结合所述第二存储数据表参数内容分析调用相应的第四预设类方法,通过所述第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第四预设类方法为第三预设类方法内包含的预设类方法的一个。80.由于将ace格式数据库转换成hdf5格式数据库,需要将ace格式数据库中的数据进行获取再导入基于ace格式数据库结构设计的hdf5格式数据库,在获取ace格式数据库中的数据文件时,需要设计不同种类的预设类方法对不同种类数据文件进行调用,因此所述第三预设类方法需要基于数据库类型及所述第二存储数据表参数来判断调用的预设类方法,即先判断用户目标获取的数据文件,根据所述数据文件的种类选用调用预设类方法。具体的,本公开实施例对预设类方法的调用方式不进行限定。81.在选取调用预设类方法后,还需对基于预设类方法获取的目标数据文件进行解析,将其解析为以第二数据表标识字符串和存储核数据类为键值对的第二字典,使得被解析后的数据可以被预设类方法导入hdf5格式数据库。82.步骤106,基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应。83.为了将经由步骤106处理的在ace格式数据库的目标数据文件导入hdf5格式数据库,需要对第二字典进行遍历查询,以获取全部的目标数据文件。用户输入所述第二数据表标识字符串在第二字典中查找对应的存储核数据类,从而实现对目标数据文件的查找。84.步骤107,将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。85.通过预设类方法将存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,为了实现数据的整理分类,不同类存储核数据类将被存入与之对应的文件夹。86.本公开提供的基于hdf5格式的核反应数据库制作方法,基于第一预设类方法读取ace格式数据库的目录文件;基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对;通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应;将所述第二存储数据表参数传输至第三预设类方法;通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对;基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应;将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。与相关技术相比,基于对ace格式数据库目录文件的解析,得到第一字典,基于输入的第二数据表标识字符串,在所述第一字典中遍历查询得到与第二数据表标识字符串对应的第二存储数据表参数,基于所述第二存储数据表参数,索引读取ace格式数据库的目标数据文件,对所述数据文件进行解析,并写入hdf5格式的文件,得到hdf5格式数据库,通过改变数据库格式从而解决ace格式数据库数据结构固定而难以扩展,不具备人的可读性,数据访问效率低,占用存储空间大的问题。87.为了更详细的说明hdf5格式数据库的制作过程,图2为本公开实施例提供的另一种基于hdf5格式的核反应数据库制作方法的流程示意图。如图2所示,该方法包含以下步骤:88.首先根据用户输入的路径读入ace格式数据库目录文件“xsdir”,通过xsdirparser类中的paser()函数和format()函数进行解析和格式化,获取存储在其中的整个数据库的绝对路径(abs_path),并将数据表参数解析为一个分别以数据表标识字符串(zaid.xxx)和存储数据表参数为键值对的嵌套字典(xsdir_contents),其中数据表参数包括了核素原子质量比(awr)、数据表所在数据文件的相对路径(path)、核数据在数据文件中开始的行以及数据数目(number),对于个别类型数据库还有数据库制作的温度(temp)。然后通过用户输入的数据表标识字符串从xsdir_contents中获取解析该数据表所必须的参数,若用户输入的数据表标识字符串是“none”,则通过循环遍历xsdir_contents,获取解析每个数据表所必须的参数。然后将获取的参数传入aceparser类中,aceparser类根据数据库类型以及获取的数据库绝对路径和数据表所在数据文件的相对路径调用相应的数据解析类从ace数据库(acedatabase)中读入数据文件进行解析,将每个数据表中的核数据解析为分为别以数据表标识字符串和存储核数据的类为键值对的字典(ace_contents)。最后使用aceparser类中构建的to_hdf5函数通过循环遍历ace_contents将所有数据表标识对应的核数据写入以该数据表标识前缀命名的h5文件中。对于不同类型的数据库由于其包含数据有差异,所以解析过程中所调用的类的设计有所不同,因此生成的hdf5格式数据库的结构也不同。针对ace格式的连续能量中子数据库、连续能量光原数据库、连续能量光核数据库、中子热化库、多群数据库、连续能量电子数据库这六类数据库分别设计了neutronaceparser类、photoatomicaceparser类、photonuclearaceparser类、thermalneutronaceparser类、multigroupaceparser类、elctronaceparser类。数据库解析过程中根据数据表标识后缀识别解析的数据库类型并确定调用哪个类进行解析和hdf5格式数据库的生成,生成的hdf5格式核数据库的存储路径为用户输入的路径(pathofhdf5)。89.作为本公开实施例的细化,在步骤101执行基于第一预设类方法读取ace格式数据库的目录文件时,可以采用但不限于以下实施方式,例如:基于预设输入方式,输入所述目录文件的第一绝对路径;基于预设输入方式,输入第二绝对路径,所述第二绝对路径为hdf5格式数据库的生成路径与存储路径;根据所述第一绝对路径,使用第一预设类方法读取ace格式数据库的目录文件。90.作为上述实施例的细化,在步骤103执行所述通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数之前,所述方法还可以采用但不限于以下实施方式,例如:基于预设输入方式,输入所述第二数据表标识字符串。91.作为上述实施例的细化,在步骤105执行通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典时,可以采用但不限于以下实施方式,例如:基于所述第二数据表标识字符串的标识后缀,确定数据库类型;通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法;通过所述第四预设类方法基于所述第二存储数据表参数从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二存储数据表参数包括ace格式数据库的相对路径、数据表所在数据文件的起始位置和数据表长度。92.作为上述实施例的细化,所述方法可以应用于制作连续能量中子数据库、连续能量光原数据库、连续能量光核数据库、中子热化库、多群数据库、连续能量电子数据库。93.为了详细介绍针对ace格式的连续能量中子数据库所设计的neutronaceparser类,图3a本公开实施例提供的一种neutronaceparser类设计部分结构示意图。图3b本公开实施例提供的一种neutronaceparser类设计另一部分结构示意图。如图3a与图3b所示,neutronaceparser类设计结构包括:94.在ace格式数据库中所有核数据都存储在xss数组中,并需要通过nxs、jxs两个整形数组进行数据索引。如图3a所示,对ace格式连续能量中子数据库中所包含的数据设计了五个数据块:energy、nu、precursors、probability_table、reactions,所有数据块都从xss数组中解析获得并通过每个python类中的to_hdf5()函数写入h5文件。energy数据块包含了不同温度下的主能量网格点,解析到了neutronaceparser类中energy列表中。在生成hdf5格式的核数据库时会根据neutronaceparser类中的temperature属性值在energy目录下创建相应的数据集并将主能量网格点写入其中。因此,在批量化解析连续能量中子ace数据库时会将数据库中同一核素对应的不同温度的数据表的能量网格点写入同一h5文件的同一目录下,实现了数据的整合。95.nu数据块出现在可裂变核素核数据库中,包含了裂变反应所产生的瞬发、缓发中子数以及总裂变中子数,解析到了neutronaceparser类中的字典nu中。因此在生成hdf5格式的核数据库时将根据neutronaceparser类中的字典nu中的键值将在nu目录下分别创建nu_prompt、nu_delayed、nu_total目录。对于裂变中子数目还可能有两种存储方式:表格式、多项式,因此分别设计了两个类进行解析:nu_tableform、nu_polynomialform,并且会将存储方式写入上述三个目录的属性中。表格存储方式存储的值为能量点、对应的裂变中子数目以及插值参数(break_points、interpolation),在生成hdf5格式的核数据库时将能量点和对应的裂变中子数目分别写入上述三个目录下的energy和nu数据集,插值参数若存在写入上述三个目录的属性,否则默认为线性插值。多项式存储方式存储的值只有多项式系数,在生成hdf5格式的核数据库时将系数写入上述三个目录的coefficients数据集中。96.precursors数据块也出现在可裂变核素核数据库中,一般包含六组先驱核数据,解析到了neutronaceparser类中的列表precursor中,每组先驱核数据都包含有能量点、衰变概率、插值参数和衰变常数,分别对应precursor类中的energy、probability、break_points、interpolation、decayed_constant。在生成hdf5格式的核数据库时将遍历precursor列表,生成对应数目的precursor目录,在每个目录下写入对应的energy、probability数据集,break_points、interpolation作为衰变概率的插值参数写入energy属性中(若不存在默认为线性插值),decayed_constant写入对应目录的属性中。97.probability_table数据块包含了不同温度下的给出概率表的能量点、与之对应的概率表、表间插值参数、非弹性散射竞争标识、其他吸收标识、截面因子标识,分别对应probabilitytable类中的energy、probability_table、interpolation、inelastic_competition_flag、other_absorption_flag、multiply_smooth_flag。在生成hdf5格式的核数据库时在probability_table目录下创建以temperature属性值命名的目录,然后将energy、probability_table数据集写入对应目录下,interpolation、inelastic_competition_flag、other_absorption_flag、multiply_smooth_flag作为目录的属性写入。因此,在批量化解析连续能量中子ace数据库时会将数据库中同一核素对应的不同温度的数据表的概率表写入同一h5文件的probability_table目录下,实现了数据的整合。98.reactions数据块最为庞大也最为复杂,它包含了中子核反应的所有反应道信息,解析到了neutronaceparser类中的字典reactions中,字典reactions的键值对分别为endf反应道编号和存储反应道信息的neutronreaction类。在生成hdf5格式的核数据库时将根据字典reactions中的键值以及endf反应道编号和反应道名称在reacions目录下创建以各反应道名称命名的目录,同时也会将endf反应道编号写入该目录的属性mt中。然后再将对应的neutronreaction类中的数据写入每个反应道目录下,neutronreaction类中的q、coordinate分别表示该反应道对应的释能和反应道中给出的出射粒子信息所在的坐标系,这两个数据也都写入对应反应道目录的属性中。neutronreaction类中的两个列表energy和xs分别存储了该反应道给出的能量点和对应的核反应截面值,这两个列表中的数值随数据库的温度变化,因此在生成hdf5格式的核数据库时在各反应道目录下创建以temperature属性值命名的目录,然后将能量和截面值写入对应目录下的energy、xs数据集因此,在批量化解析连续能量中子ace数据库时会将数据库中同一核素对应的不同温度的数据表的概率表写入同一h5文件的统一目录下,实现了数据的整合。99.neutronreaction类中的字典productions中存储了该反应道生成的次级粒子信息,该字典的键值对分别为产物粒子的序号和存储产物粒子信息的类,连续能量中子ace数据库中的次级产物粒子只包括中子和光子,因此分别设计了neutronproduct和photonproduct类进行解析。两个类中都包含了particle_type和emission_mode参数,他们分别表示产物粒子的类型和出射方式(瞬发、缓发)。在生成hdf5格式的核数据库时针对每种产物粒子创建一个目录,对于中子产物要么给出生成的中子个数particle_number(对于裂变反应这部分数据放在了nu目录下),要么给出产额数据,对于光子产物要么给出产生该光子的截面数据,要么给出产额数据,产额数据存储在neutronproduct和photonproduct类的yields列表中,截面数据存储在photonproduct类的xs列表中,产额数据、截面数据依赖的出射粒子能量存储在energy列表中,break_points和interpolation是它们对应的插值参数。在生成生成hdf5格式的核数据库时将particle_type、emission_mode、particle_number、break_points、interpolation写入相应产物粒子目录的属性中,energy、yields、xs写入相应产物粒子目录下的数据集中。100.对于每种产物粒子都有相应的出射角分布和能量分布,它们存储在distribution类中,从图3a中可以看到,distribution类中包含了三个字典:angle、energy、angle_energy,分别代表角分布、能量分布、角度-能量耦合分布,当分布类型为角度-能量耦合时,将不会有角分布和能量分布,因此在生成hdf5格式的核数据库时,不会同时出现三种分布的目录。角分布数据存储在angle类中,其中energy表示给出角分布的能量点,字典mu表示每个能量点对应的出射角分布,字典的键值对分别为能量点序号和存储出射角余弦信息的mu类,在生成hdf5格式的核数据库时创建angle目录,将energy和energy中每个能量点对应的出射角余弦写入该目录下的数据集中。当角分布是各向同性时将没有相关数据,此时需要将角分布类型type写入angle目录的属性中。由于不同的能量下给出的出射角余弦的个数可能不同,也或者是根本没有给出(即各向同性),所以需要对每个能量点对应的出射角余弦单独创建数据集,如果某个数据集为空则其属性中一定会表明是各向同性。101.能量分布、角度-能量耦合分布数据较为复杂,因为分布的种类较多,因此针对每种分布都设计了相应的law。每个law都包含了该分布的概率probability以及与之对应的能量energy_for_probability和插值参数interpolationfor_probability,由于每个出射粒子都可能不含不止一种出射能量分布类型,所以以上参数便是蒙卡程序用来抽样不同能量分布所需的参数。102.为了详细介绍针对ace格式的连续能量光核数据库所设计的photonuclearaceparserr类,图4a本公开实施例提供的一种photonuclearaceparser类设计部分结构示意图。图4b本公开实施例提供的一种photonuclearaceparser类设计另一部分结构示意图。如图4a与图4b所示,photonuclearaceparser类设计结构包括:103.对ace格式连续能量光核数据库中所包含的数据设计了三个数据块:energy、secondary_particles、reactions,其中reactions数据块中包含的数据有各反应道对应的能量点、光核反应截面值以及反应的释热量,此部分数据结构的设计与连续能量中子数据库的设计相同,因此不再赘述。104.不同于连续能量中子数据库,连续能量光核数据库的次级粒子除了中子、光子,还包含有电子、质子、氘核、氦核、氚核,photonuclearaceparser类中的字典secondary_particles的键值对分别为次级粒子编号和存储次级粒子数据的secondaryparticles类,在生成hdf5格式的光核数据库时会对每个次级粒子创建一个目录并将次级粒子的名称写入目录的属性中,由于能产生该次级粒子的反应道可能有多个,所以会将endf反应道编号也写入次级粒子目录的属性中。secondaryparticles类中的energy、xs、heating分别表示能量点、反应生成该次级粒子的截面以及热沉积数,这些数据全部写入次级粒子目录下的数据集中。由于能产生该次级粒子的反应道可能有多个,所以设计了secparproducereaction类对产生该次级粒子的所有反应道数据进行解析,secparproducereaction类中的corordinate表示该反应道数据所在坐标系,xs、yileds、energy分别表示该反应道产生该粒子的截面、产额以及对应的能量点,当然xs、yileds不会同时给出,若给出的是yileds可能还会给出相应的插值参数break_points、interpolation(若没有给出则默认线性插值)。105.为了详细介绍针对ace格式的中子热化库所设计的thermalneutronaceparser类,图5本公开实施例提供的一种thermalneutronaceparser类设计结构示意图。如图5所示,thermalneutronaceparser类设计结构包括:106.对ace格式连续能量中子热化核数据库中所包含的数据只设计一个数据块:reactions,解析到了thermalneutronaceparser类中的字典reactions字典中,该字典的键值对分别为反应道名称和存储反应道数据的类。对于热化库只有三个反应道:非相干非弹性散射、相干弹性散射、相干非弹性散射,分别设计了incoherentinelastic、coherentelastic、incoherentelastic类进行解析。由于不同温度下的热化库包含的反应道数据有所不同,因此在生成hdf5格式的中子热化核数据库时将根据thermalneutronaceparser类中temperature属性值创建相应的温度目录,然后根据reactions字典中的键值在温度目录下分别创建incoherentinelastic、coherentelastic、incoherentelastic目录。coherentelastic、incoherentelastic类比较简单,coherentelastic类只包含energy和xs,分别表示相干弹性散射的能量点和对应的截面值,incoherentelastic类除了包含energy和xs外还包含角分布数据mu。incoherentinelastic类除了包含energy和xs外还包含次级中子分布数据,存储在distributions字典中。次级中子分布均为角度-能量耦合分布,分为连续型和离散型,分别通过angleenergycontinuous、angleenergydiscrete类进行解析,两个类中都包含type属性,在生成hdf5格式的连续能量热化库时会将其写入对应反应道目录的属性中。其中angleenergydiscrete类中只包含了energy和mu,分别表示次级中子的能量和角分布,angleenergycontinuous类中的angle_energy字典用于存储incoherentinelastic类中energy给出的每个能量点对应的出射中子分布数据,angle_energy字典的键值对分别为energy中的能量点序号以及与之对应的存储出射中子分布数据的angleenergy类。angleenergy类中包含有出射能量点以及与之对应的出射角分布数据,每个出射能量点对应的出射角分布数据又通过mu类进行解析并存入angleenergy类中的字典mu中。107.为了详细介绍针对ace格式的连续能量光原数据库所设计的photoatomicaceparser类,图6本公开实施例提供的一种photoatomicaceparser类设计部分结构示意图。如图6所示,photoatomicaceparser类设计结构包括:108.对ace格式连续能量光原核数据库中所包含的数据设计了三个数据块:energy、heating、reactions、shells,其中energy和heating分别表示光原反应的主能量网格点以及与之对应的热沉积数,在生成hdf5格式的光原反应核数据库时解析到了energy和heating数据集中。photoatomicaceparser类中的reactions为存储光原反应的反应道数据的字典,该字典的键值对分别为反应道名称字符串以及对应的存储该反应道数据的类,光原反应一共有五种:非相干散射、相干散射、光电效应、电子对效应、荧光效应,分别对应五个类:incoherent、coherent、photoelectric、pairproduction、fluorescence。在生成hdf5格式的光原反应核数据库时通过遍历字典reactions将上述五个类中存储的数据写入以字典键值命名的目录下。photoatomicaceparser类中的shells为存储着原子壳层数据的列表,原子壳层数据包含了每个壳层的反应概率interpolation_probability、电子数electron_number、结合能binding_energy、康普顿轮廓compton_profile和其插值参数interpolation,在生成hdf5格式的光原反应核数据库时通过遍历列表shells将每个壳层的数据写入对应目录下,将interpolation_probability写入目录的属性,将interpolation写入compton_profile的属性。109.为了详细介绍针对ace格式的多群数据库所设计的multigroupaceparser类,图7本公开实施例提供的一种multigroupaceparser类设计结构示意图。如图7所示,multigroupaceparser类设计结构包括:110.ace格式多群数据库分为多群中子数据库和多群光子数据库,两者的数据格式完全相同,所以设计了multigroupaceparser类对整个多群数据库进行解析。对ace格式多群数据库中所包含的数据设计了八个数据块:particle_mass、group_center、group_width、fission_fraction、stopping_power、nu、secondary_particles、reactions,其中fission_fraction和nu分别表示各群的裂变份额及各群产生的裂变中子数,只对可裂变核素存在。particle_mass表示各能群对应的入射粒子的质量,只对除中子和光子外的其他粒子才会给出该数据。stopping_power只对带电粒子存在,表示各能群下该核素对入射粒子的阻止本领。group_center、group_width表示各群的中心能量值及能群宽度。reactions数据块存储着各反应道的截面和释热量数据,截面和释热量数据均与能群对应,在生成hdf5格式的多群核数据库时会创建reactions目录,然后通过遍历reactions字典reactions目录下生成各反应道子目录,目录以反应道名称命名,然后将截面和释热量数据写入反应道目录下的数据集中,endf反应道编号写入反应道目录的属性中,secondary_particles数据块存储着次级粒子数据,次级粒子数据通过multigroupsecondaryparticle类进行解析,particle_type表示次级粒子的类型,xs_p0是一个二维数组,表示各入射能群向各出射能群散射的截面,group_center、group_width表示次级粒子能群中心和能群宽度,angle是一个键值对分别为入射能群号和存储次级粒子角分布数据类multigroupangle的字典。multigroupangle类中的type表示分布的类型,字典to_group是键值对分别为出射能群号和存储次级粒子角分布数据类togroup的字典,togroup类中的id表示出射能群编号,mu表示某入射能群向该出射能群出射的角度余弦,type表示分布类型。在生成hdf5格式的多群核数据库时会创建secondary_particle目录,然后通过遍历secondary_particles字典创建每个次级粒子的目录,将xs_p0、group_center、group_width写入该目录下的数据集中,particle_type写入该目录的属性中。然后通过遍历字典angle对每个入射能群创建角分布目录,若type为“isotropic”(即各向同性)则会将其写入角分布目录属性,该目录将为空目录,否则将会遍历to_group字典该角分布目录下创建每个次级粒子能群的角分布数据集,数据集属性中会标明角分布的类型(“isotropic”或“equiprobable_cosine_bins”(即等概率余弦箱))。111.为了详细介绍针对ace格式的连续能量电子数据库所设计的electronaceparser类,图8本公开实施例提供的一种electronaceparser类设计结构示意图。如图8所示,electronaceparser类设计结构包括:112.对ace格式连续能量电子数据库中所包含的数据设计了两个数据块:reactions、shells,其中shells数据块包含的是原子各壳层的数据,之前的光原核数据库中已经进行过说明,此处不再赘述。electronaceparser类中的reactions为存储电子反应道数据的字典,该字典的键值对分别为反应道名称字符串以及对应的存储该反应道数据的类,光原反应一共有五种:非相干散射、相干散射、光电效应、电子对效应、荧光效应,分别对应四个类:augereffect、mottscattering、rileyscattering、bremsstrahlung,分别表示俄歇效应、莫特散射、瑞丽散射、韧致辐射。在生成hdf5格式的电子反应核数据库时通过遍历字典reactions将上述四个类中存储的数据写入以字典键值命名的目录下。113.综上所述,本技术实施例能够达到以下效果:114.1.本公开实施例生成了一套全新格式的核数据库,数据结构富有层次性且更具物理意义,清晰易懂,解决了传统ace格式核数据库人不可读的问题。115.2.通过整合不同温度点的核数据,减少了ace格式核数据库中大量的冗余数据,并且由于生成的hdf5格式的核数据库为二进制文件,占用存储空间也大大减小,解决了传统ace格式占用存储空间大的问题。116.3.科研工作者可以轻松地将自己需要的数据写入hdf5格式核数据库并在程序中得以应用,有效解决了传统ace核数据库难以扩展的问题。117.与上述的基于hdf5格式的核反应数据库制作方法相对应,本发明还提出一种基于hdf5格式的核反应数据库制作装置。由于本发明的装置实施例与上述的方法实施例相对应,对于装置实施例中未披露的细节可参照上述的方法实施例,本发明中不再进行赘述。118.图9为本公开实施例所提供的一种基于hdf5格式的核反应数据库制作装置的结构示意图。如图9所示,所述装置包括:119.读取单元21,用于基于第一预设类方法读取ace格式数据库的目录文件;120.第一解析单元22,用于基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对;121.第一获取单元23,用于通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应;122.传输单元24,用于将所述第二存储数据表参数传输至第三预设类方法;123.第二解析单元25,用于通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对;124.第二获取单元26,用于基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应;125.写入单元27,用于将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。126.本公开提供的基于hdf5格式的核反应数据库制作装置,基于第一预设类方法读取ace格式数据库的目录文件;基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对;通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应;将所述第二存储数据表参数传输至第三预设类方法;通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对;基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应;将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。与相关技术相比,基于对ace格式数据库目录文件的解析,得到第一字典,基于输入的第二数据表标识字符串,在所述第一字典中遍历查询得到与第二数据表标识字符串对应的第二存储数据表参数,基于所述第二存储数据表参数,索引读取ace格式数据库的目标数据文件,对所述数据文件进行解析,并写入hdf5格式的文件,得到hdf5格式数据库,通过改变数据库结构和格式从而解决ace格式数据库数据结构固定而难以扩展,不具备人的可读性,数据访问效率低,占用存储空间大的问题。127.图10为本公开实施例所提供的另一种基于hdf5格式的核反应数据库制作装置的结构示意图。如图10所示,所述读取单元21包括:128.第一输入模块211,用于基于预设输入方式,输入所述目录文件的第一绝对路径;129.第二输入模块212,用于基于预设输入方式,输入第二绝对路径,所述第二绝对路径为hdf5格式数据库的生成路径与存储路径;130.读取模块213,用于根据所述第一绝对路径,使用第一预设类方法读取ace格式数据库的目录文件。131.进一步地,在本实施例一种可能的实现方式中,如图10所示,所述装置还包括:132.第二输入单元28,用于基于预设输入方式,输入所述第二数据表标识字符串。133.进一步地,在本实施例一种可能的实现方式中,如图10所示,所述第二解析单元25包括:134.确定模块251,用于基于所述第二数据表标识字符串的标识后缀,确定数据库类型;135.调用模块252,用于通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法;136.解析模块253,用于通过所述第四预设类方法基于所述第二存储数据表参数从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二存储数据表参数包括ace格式数据库的相对路径、数据表所在数据文件的起始位置和数据表长度。137.需要说明的是,前述对方法实施例的解释说明,也适用于本实施例的装置,原理相同,本实施例中不再限定。138.根据本公开的实施例,本公开还提供了一种电子设备、一种可读存储介质和一种计算机程序产品。139.图11示出了可以用来实施本公开的实施例的示例电子设备300的示意性框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本公开的实现。140.如图11所示,设备300包括计算单元301,其可以根据存储在rom(read-onlymemory,只读存储器)302中的计算机程序或者从存储单元308加载到ram(randomaccessmemory,随机访问/存取存储器)303中的计算机程序,来执行各种适当的动作和处理。在ram303中,还可存储设备300操作所需的各种程序和数据。计算单元301、rom302以及ram303通过总线304彼此相连。i/o(input/output,输入/输出)接口305也连接至总线304。141.设备300中的多个部件连接至i/o接口305,包括:输入单元303,例如键盘、鼠标等;输出单元307,例如各种类型的显示器、扬声器等;存储单元308,例如磁盘、光盘等;以及通信单元309,例如网卡、调制解调器、无线通信收发机等。通信单元309允许设备300通过诸如因特网的计算机网络和/或各种电信网络与其他设备交换信息/数据。142.计算单元301可以是各种具有处理和计算能力的通用和/或专用处理组件。计算单元301的一些示例包括但不限于cpu(centralprocessingunit,中央处理单元)、gpu(graphicprocessingunits,图形处理单元)、各种专用的ai(artificialintelligence,人工智能)计算芯片、各种运行机器学习模型算法的计算单元、dsp(digitalsignalprocessor,数字信号处理器)、以及任何适当的处理器、控制器、微控制器等。计算单元301执行上文所描述的各个方法和处理,例如基于hdf5格式的核反应数据库制作方法。例如,在一些实施例中,地基于hdf5格式的核反应数据库制作方法可被实现为计算机软件程序,其被有形地包含于机器可读介质,例如存储单元308。在一些实施例中,计算机程序的部分或者全部可以经由rom302和/或通信单元309而被载入和/或安装到设备300上。当计算机程序加载到ram303并由计算单元301执行时,可以执行上文描述的方法的一个或多个步骤。备选地,在其他实施例中,计算单元301可以通过其他任何适当的方式(例如,借助于固件)而被配置为执行前述基于hdf5格式的核反应数据库制作方法。143.本文中以上描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、fpga(fieldprogrammablegatearray,现场可编程门阵列)、asic(application-specificintegratedcircuit,专用集成电路)、assp(applicationspecificstandardproduct,专用标准产品)、soc(systemonchip,芯片上系统的系统)、cpld(complexprogrammablelogicdevice,复杂可编程逻辑设备)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。144.用于实施本公开的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。145.在本公开的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、ram、rom、eprom(electricallyprogrammableread-only-memory,可擦除可编程只读存储器)或快闪存储器、光纤、cd-rom(compactdiscread-onlymemory,便捷式紧凑盘只读存储器)、光学储存设备、磁储存设备、或上述内容的任何合适组合。146.为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,crt(cathode-raytube,阴极射线管)或者lcd(liquidcrystaldisplay,液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者、触觉输入)来接收来自用户的输入。147.可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:lan(localareanetwork,局域网)、wan(wideareanetwork,广域网)、互联网和区块链网络。148.计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。服务器可以是云服务器,又称为云计算服务器或云主机,是云计算服务体系中的一项主机产品,以解决了传统物理主机与vps服务("virtualprivateserver",或简称"vps")中,存在的管理难度大,业务扩展性弱的缺陷。服务器也可以为分布式系统的服务器,或者是结合了区块链的服务器。149.其中,需要说明的是,人工智能是研究使计算机来模拟人的某些思维过程和智能行为(如学习、推理、思考、规划等)的学科,既有硬件层面的技术也有软件层面的技术。人工智能硬件技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理等技术;人工智能软件技术主要包括计算机视觉技术、语音识别技术、自然语言处理技术以及机器学习/深度学习、大数据处理技术、知识图谱技术等几大方向。150.应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发公开中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本公开公开的技术方案所期望的结果,本文在此不进行限制。151.上述具体实施方式,并不构成对本公开保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本公开的精神和原则之内所作的修改、等同替换和改进等,均应包含在本公开保护范围之内。当前第1页12当前第1页12
技术领域:
:1.本公开涉及数据处理
技术领域:
:,尤其涉及一种基于hdf5格式的核反应数据库制作方法及装置、电子设备和存储介质。
背景技术:
::2.传统的蒙特卡罗数据库主要为ace格式,该格式的数据库通过将不同核素的核反应数据以一维数组的方式存储在文本文件中,使这些文本文件形成了ace格式数据库。3.核反应蒙特卡罗程序在使用ace格式的数据库时首先需要读入数据库目录文件,根据目录文件中给出的数据库路径及对应的数据文本文件中核数据的起始位置和个数在指定路径下将核数据读入程序中。由于读入的是一维数组,然而其中包含种类繁多的核数据(以连续能量中子数据库举例,其核数据包含了核反应截面数据、能量分布数据、角分布数据,对于可裂变核素还包含裂变中子数据以及概率表),蒙卡程序在使用这些数据前需要通过一套复杂的索引方法在一维数组中查找对应的数据,所以数据访问效率较低。4.由于ace格式的数据库使用njoy程序加工而成,且所述ace格式的数据库将大量核数据不加区分地罗列在文本文件中,各类数据前没有对应的标签,从而导致ace格式的数据库数据结构固定,用户无法轻易的根据自己的需求对数据库进行扩充,且基本不具备人的可读性。技术实现要素:5.本公开提供了一种基于hdf5格式的核反应数据库制作方法及装置、电子设备和存储介质。其主要目的在于解决ace格式数据库存在着数据结构固定,用户无法轻易的根据自己的需求对数据库进行扩充,基本不具备人的可读性,数据访问效率较低,占用存储空间大的问题。6.根据本公开的第一方面,提供了一种基于hdf5格式的核反应数据库制作方法,包括:7.基于第一预设类方法读取ace格式数据库的目录文件;8.基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对;9.通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应;10.将所述第二存储数据表参数传输至第三预设类方法;11.通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对;12.基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应;13.将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。14.可选的,所述基于第一预设类方法读取ace格式数据库的目录文件包括:15.基于预设输入方式,输入所述目录文件的第一绝对路径;16.基于预设输入方式,输入第二绝对路径,所述第二绝对路径为hdf5格式数据库的生成路径与存储路径;17.根据所述第一绝对路径,使用第一预设类方法读取ace格式数据库的目录文件。18.可选的,在所述通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数之前,所述方法还包括:19.基于预设输入方式,输入所述第二数据表标识字符串。20.可选的,所述通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典包括:21.基于所述第二数据表标识字符串的标识后缀,确定数据库类型;22.通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法;23.通过所述第四预设类方法基于所述第二存储数据表参数从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二存储数据表参数包括ace格式数据库的相对路径、数据表所在数据文件的起始位置和数据表长度。24.可选的,所述方法应用于制作连续能量中子数据库、连续能量光原数据库、连续能量光核数据库、中子热化库、多群数据库、连续能量电子数据库。25.根据本公开的第二方面,提供了一种基于hdf5格式的核反应数据库制作装置,包括:26.读取单元,用于基于第一预设类方法读取ace格式数据库的目录文件;27.第一解析单元,用于基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对;28.第一获取单元,用于通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应;29.传输单元,用于将所述第二存储数据表参数传输至第三预设类方法;30.第二解析单元,用于通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对;31.第二获取单元,用于基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应;32.写入单元,用于将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。33.可选的,所述读取单元包括:34.第一输入模块,用于基于预设输入方式,输入所述目录文件的第一绝对路径;35.第二输入模块,用于基于预设输入方式,输入第二绝对路径,所述第二绝对路径为hdf5格式数据库的生成路径与存储路径;36.读取模块,用于根据所述第一绝对路径,使用第一预设类方法读取ace格式数据库的目录文件。37.可选的,所述装置还包括:38.第二输入单元,用于基于预设输入方式,输入所述第二数据表标识字符串。39.可选的,所述第二解析单元包括:40.确定模块,用于基于所述第二数据表标识字符串的标识后缀,确定数据库类型;41.调用模块,用于通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法;42.解析模块,用于通过所述第四预设类方法基于所述第二存储数据表参数从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二存储数据表参数包括ace格式数据库的相对路径、数据表所在数据文件的起始位置和数据表长度。43.可选的,所述装置应用于制作连续能量中子数据库、连续能量光原数据库、连续能量光核数据库、中子热化库、多群数据库、连续能量电子数据库。44.根据本公开的第三方面,提供了一种电子设备,包括:45.至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行前述第一方面所述的方法。46.根据本公开的第四方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行前述第一方面所述的方法。47.根据本公开的第五方面,提供了一种计算机程序产品,包括计算机程序,所述计算机程序在被处理器执行时实现如前述第一方面所述的方法。48.本公开提供的基于hdf5格式的核反应数据库制作方法及装置、电子设备和存储介质,基于第一预设类方法读取ace格式数据库的目录文件;基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对;通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应;将所述第二存储数据表参数传输至第三预设类方法;通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对;基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应;将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。与相关技术相比,基于对ace格式数据库目录文件的解析,得到第一字典,基于输入的第二数据表标识字符串,在所述第一字典中遍历查询得到与第二数据表标识字符串对应的第二存储数据表参数,基于所述第二存储数据表参数,索引读取ace格式数据库的目标数据文件,对所述数据文件进行解析,并写入hdf5格式的文件,得到hdf5格式数据库,通过改变数据库格式从而解决ace格式数据库数据结构固定而难以扩展,不具备人的可读性,数据访问效率低,占用存储空间大的问题。49.应当理解,本部分所描述的内容并非旨在标识本技术的实施例的关键或重要特征,也不用于限制本技术的范围。本技术的其它特征将通过以下的说明书而变得容易理解。附图说明50.附图用于更好地理解本方案,不构成对本公开的限定。其中:51.图1为本公开实施例所提供的一种基于hdf5格式的核反应数据库制作方法的流程示意图;52.图2为本公开实施例提供的另一种基于hdf5格式的核反应数据库制作方法的流程示意图;53.图3a本公开实施例提供的一种neutronaceparser类设计部分结构示意图;54.图3b本公开实施例提供的一种neutronaceparser类设计另一部分结构示意图;55.图4a本公开实施例提供的一种photonuclearaceparser类设计部分结构示意图;56.图4b本公开实施例提供的一种photonuclearaceparser类设计另一部分结构示意图;57.图5本公开实施例提供的一种thermalneutronaceparser类设计结构示意图;58.图6本公开实施例提供的一种photoatomicaceparser类设计部分结构示意图;59.图7本公开实施例提供的一种multigroupaceparser类设计结构示意图;60.图8本公开实施例提供的一种electronaceparser类设计结构示意图;61.图9为本公开实施例所提供的一种基于hdf5格式的核反应数据库制作装置的结构示意图;62.图10为本公开实施例所提供的另一种基于hdf5格式的核反应数据库制作装置的结构示意图;63.图11为本公开实施例的示例电子设备300的示意性框图。具体实施方式64.以下结合附图对本公开的示范性实施例做出说明,其中包括本公开实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本公开的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。65.下面参考附图描述本公开实施例的基于hdf5格式的核反应数据库制作方法及装置、电子设备和存储介质。66.图1为本公开实施例所提供的一种基于hdf5格式的核反应数据库制作方法的流程示意图。如图1所示,该方法包含以下步骤:67.步骤101,基于第一预设类方法读取ace格式数据库的目录文件。68.所述第一预设类方法,为提前设计用于读取数据的算法。69.为了得到ace格式数据库的目录文件,基于输入的目录文件绝对路径,通过第一预设类方法获取ace格式数据库的目录文件,进而执行下一步操作。70.步骤102,基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对。71.所述第一存储数据表参数包括核素原子质量比、数据表所在数据文件的相对路径、核数据在数据文件中开始的行以及数据数目,对于个别类型数据库还有数据库制作的温度。72.为了对所述第一存储数据表参数内容进行获取,基于第二预设类方法将所述目录文件解析为第一数据表标识字符串和第一存储数据表参数为键值对的第一字典,从而实现使用预设类方法调用输入的键对应的值,所述键即指第一数据表标识字符串,值为第一存储数据表参数,二者形成键值对,进而实现输入指第一数据表标识字符串调用对应的第一存储数据表参数。73.步骤103,通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应。74.为了得到第一存储数据表参数中目标内容,通过输入的第二数据表标识字符串在所述第一字典中匹配查询其对应的存储数据表参数,即第二存储数据表参数;实现过程即是,基于形成的键值对第一字典,在第一字典中查询输入键所匹配的值进行输出。75.所述第一字典指键值对的数据集,所述第二数据表标识字符串为用户为了获取第一存储数据表参数中目标内容输入索引字段,第二存储数据表参数为目标内容。76.步骤104,将所述第二存储数据表参数传输至第三预设类方法。77.基于所述第二存储数据表参数,由第三预设类方法进行数据库制作的后续处理。78.步骤105,通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对。79.所述第三预设类方法为编写的算法,所述第三预设类方法通过数据库类型结合所述第二存储数据表参数内容分析调用相应的第四预设类方法,通过所述第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第四预设类方法为第三预设类方法内包含的预设类方法的一个。80.由于将ace格式数据库转换成hdf5格式数据库,需要将ace格式数据库中的数据进行获取再导入基于ace格式数据库结构设计的hdf5格式数据库,在获取ace格式数据库中的数据文件时,需要设计不同种类的预设类方法对不同种类数据文件进行调用,因此所述第三预设类方法需要基于数据库类型及所述第二存储数据表参数来判断调用的预设类方法,即先判断用户目标获取的数据文件,根据所述数据文件的种类选用调用预设类方法。具体的,本公开实施例对预设类方法的调用方式不进行限定。81.在选取调用预设类方法后,还需对基于预设类方法获取的目标数据文件进行解析,将其解析为以第二数据表标识字符串和存储核数据类为键值对的第二字典,使得被解析后的数据可以被预设类方法导入hdf5格式数据库。82.步骤106,基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应。83.为了将经由步骤106处理的在ace格式数据库的目标数据文件导入hdf5格式数据库,需要对第二字典进行遍历查询,以获取全部的目标数据文件。用户输入所述第二数据表标识字符串在第二字典中查找对应的存储核数据类,从而实现对目标数据文件的查找。84.步骤107,将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。85.通过预设类方法将存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,为了实现数据的整理分类,不同类存储核数据类将被存入与之对应的文件夹。86.本公开提供的基于hdf5格式的核反应数据库制作方法,基于第一预设类方法读取ace格式数据库的目录文件;基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对;通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应;将所述第二存储数据表参数传输至第三预设类方法;通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对;基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应;将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。与相关技术相比,基于对ace格式数据库目录文件的解析,得到第一字典,基于输入的第二数据表标识字符串,在所述第一字典中遍历查询得到与第二数据表标识字符串对应的第二存储数据表参数,基于所述第二存储数据表参数,索引读取ace格式数据库的目标数据文件,对所述数据文件进行解析,并写入hdf5格式的文件,得到hdf5格式数据库,通过改变数据库格式从而解决ace格式数据库数据结构固定而难以扩展,不具备人的可读性,数据访问效率低,占用存储空间大的问题。87.为了更详细的说明hdf5格式数据库的制作过程,图2为本公开实施例提供的另一种基于hdf5格式的核反应数据库制作方法的流程示意图。如图2所示,该方法包含以下步骤:88.首先根据用户输入的路径读入ace格式数据库目录文件“xsdir”,通过xsdirparser类中的paser()函数和format()函数进行解析和格式化,获取存储在其中的整个数据库的绝对路径(abs_path),并将数据表参数解析为一个分别以数据表标识字符串(zaid.xxx)和存储数据表参数为键值对的嵌套字典(xsdir_contents),其中数据表参数包括了核素原子质量比(awr)、数据表所在数据文件的相对路径(path)、核数据在数据文件中开始的行以及数据数目(number),对于个别类型数据库还有数据库制作的温度(temp)。然后通过用户输入的数据表标识字符串从xsdir_contents中获取解析该数据表所必须的参数,若用户输入的数据表标识字符串是“none”,则通过循环遍历xsdir_contents,获取解析每个数据表所必须的参数。然后将获取的参数传入aceparser类中,aceparser类根据数据库类型以及获取的数据库绝对路径和数据表所在数据文件的相对路径调用相应的数据解析类从ace数据库(acedatabase)中读入数据文件进行解析,将每个数据表中的核数据解析为分为别以数据表标识字符串和存储核数据的类为键值对的字典(ace_contents)。最后使用aceparser类中构建的to_hdf5函数通过循环遍历ace_contents将所有数据表标识对应的核数据写入以该数据表标识前缀命名的h5文件中。对于不同类型的数据库由于其包含数据有差异,所以解析过程中所调用的类的设计有所不同,因此生成的hdf5格式数据库的结构也不同。针对ace格式的连续能量中子数据库、连续能量光原数据库、连续能量光核数据库、中子热化库、多群数据库、连续能量电子数据库这六类数据库分别设计了neutronaceparser类、photoatomicaceparser类、photonuclearaceparser类、thermalneutronaceparser类、multigroupaceparser类、elctronaceparser类。数据库解析过程中根据数据表标识后缀识别解析的数据库类型并确定调用哪个类进行解析和hdf5格式数据库的生成,生成的hdf5格式核数据库的存储路径为用户输入的路径(pathofhdf5)。89.作为本公开实施例的细化,在步骤101执行基于第一预设类方法读取ace格式数据库的目录文件时,可以采用但不限于以下实施方式,例如:基于预设输入方式,输入所述目录文件的第一绝对路径;基于预设输入方式,输入第二绝对路径,所述第二绝对路径为hdf5格式数据库的生成路径与存储路径;根据所述第一绝对路径,使用第一预设类方法读取ace格式数据库的目录文件。90.作为上述实施例的细化,在步骤103执行所述通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数之前,所述方法还可以采用但不限于以下实施方式,例如:基于预设输入方式,输入所述第二数据表标识字符串。91.作为上述实施例的细化,在步骤105执行通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典时,可以采用但不限于以下实施方式,例如:基于所述第二数据表标识字符串的标识后缀,确定数据库类型;通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法;通过所述第四预设类方法基于所述第二存储数据表参数从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二存储数据表参数包括ace格式数据库的相对路径、数据表所在数据文件的起始位置和数据表长度。92.作为上述实施例的细化,所述方法可以应用于制作连续能量中子数据库、连续能量光原数据库、连续能量光核数据库、中子热化库、多群数据库、连续能量电子数据库。93.为了详细介绍针对ace格式的连续能量中子数据库所设计的neutronaceparser类,图3a本公开实施例提供的一种neutronaceparser类设计部分结构示意图。图3b本公开实施例提供的一种neutronaceparser类设计另一部分结构示意图。如图3a与图3b所示,neutronaceparser类设计结构包括:94.在ace格式数据库中所有核数据都存储在xss数组中,并需要通过nxs、jxs两个整形数组进行数据索引。如图3a所示,对ace格式连续能量中子数据库中所包含的数据设计了五个数据块:energy、nu、precursors、probability_table、reactions,所有数据块都从xss数组中解析获得并通过每个python类中的to_hdf5()函数写入h5文件。energy数据块包含了不同温度下的主能量网格点,解析到了neutronaceparser类中energy列表中。在生成hdf5格式的核数据库时会根据neutronaceparser类中的temperature属性值在energy目录下创建相应的数据集并将主能量网格点写入其中。因此,在批量化解析连续能量中子ace数据库时会将数据库中同一核素对应的不同温度的数据表的能量网格点写入同一h5文件的同一目录下,实现了数据的整合。95.nu数据块出现在可裂变核素核数据库中,包含了裂变反应所产生的瞬发、缓发中子数以及总裂变中子数,解析到了neutronaceparser类中的字典nu中。因此在生成hdf5格式的核数据库时将根据neutronaceparser类中的字典nu中的键值将在nu目录下分别创建nu_prompt、nu_delayed、nu_total目录。对于裂变中子数目还可能有两种存储方式:表格式、多项式,因此分别设计了两个类进行解析:nu_tableform、nu_polynomialform,并且会将存储方式写入上述三个目录的属性中。表格存储方式存储的值为能量点、对应的裂变中子数目以及插值参数(break_points、interpolation),在生成hdf5格式的核数据库时将能量点和对应的裂变中子数目分别写入上述三个目录下的energy和nu数据集,插值参数若存在写入上述三个目录的属性,否则默认为线性插值。多项式存储方式存储的值只有多项式系数,在生成hdf5格式的核数据库时将系数写入上述三个目录的coefficients数据集中。96.precursors数据块也出现在可裂变核素核数据库中,一般包含六组先驱核数据,解析到了neutronaceparser类中的列表precursor中,每组先驱核数据都包含有能量点、衰变概率、插值参数和衰变常数,分别对应precursor类中的energy、probability、break_points、interpolation、decayed_constant。在生成hdf5格式的核数据库时将遍历precursor列表,生成对应数目的precursor目录,在每个目录下写入对应的energy、probability数据集,break_points、interpolation作为衰变概率的插值参数写入energy属性中(若不存在默认为线性插值),decayed_constant写入对应目录的属性中。97.probability_table数据块包含了不同温度下的给出概率表的能量点、与之对应的概率表、表间插值参数、非弹性散射竞争标识、其他吸收标识、截面因子标识,分别对应probabilitytable类中的energy、probability_table、interpolation、inelastic_competition_flag、other_absorption_flag、multiply_smooth_flag。在生成hdf5格式的核数据库时在probability_table目录下创建以temperature属性值命名的目录,然后将energy、probability_table数据集写入对应目录下,interpolation、inelastic_competition_flag、other_absorption_flag、multiply_smooth_flag作为目录的属性写入。因此,在批量化解析连续能量中子ace数据库时会将数据库中同一核素对应的不同温度的数据表的概率表写入同一h5文件的probability_table目录下,实现了数据的整合。98.reactions数据块最为庞大也最为复杂,它包含了中子核反应的所有反应道信息,解析到了neutronaceparser类中的字典reactions中,字典reactions的键值对分别为endf反应道编号和存储反应道信息的neutronreaction类。在生成hdf5格式的核数据库时将根据字典reactions中的键值以及endf反应道编号和反应道名称在reacions目录下创建以各反应道名称命名的目录,同时也会将endf反应道编号写入该目录的属性mt中。然后再将对应的neutronreaction类中的数据写入每个反应道目录下,neutronreaction类中的q、coordinate分别表示该反应道对应的释能和反应道中给出的出射粒子信息所在的坐标系,这两个数据也都写入对应反应道目录的属性中。neutronreaction类中的两个列表energy和xs分别存储了该反应道给出的能量点和对应的核反应截面值,这两个列表中的数值随数据库的温度变化,因此在生成hdf5格式的核数据库时在各反应道目录下创建以temperature属性值命名的目录,然后将能量和截面值写入对应目录下的energy、xs数据集因此,在批量化解析连续能量中子ace数据库时会将数据库中同一核素对应的不同温度的数据表的概率表写入同一h5文件的统一目录下,实现了数据的整合。99.neutronreaction类中的字典productions中存储了该反应道生成的次级粒子信息,该字典的键值对分别为产物粒子的序号和存储产物粒子信息的类,连续能量中子ace数据库中的次级产物粒子只包括中子和光子,因此分别设计了neutronproduct和photonproduct类进行解析。两个类中都包含了particle_type和emission_mode参数,他们分别表示产物粒子的类型和出射方式(瞬发、缓发)。在生成hdf5格式的核数据库时针对每种产物粒子创建一个目录,对于中子产物要么给出生成的中子个数particle_number(对于裂变反应这部分数据放在了nu目录下),要么给出产额数据,对于光子产物要么给出产生该光子的截面数据,要么给出产额数据,产额数据存储在neutronproduct和photonproduct类的yields列表中,截面数据存储在photonproduct类的xs列表中,产额数据、截面数据依赖的出射粒子能量存储在energy列表中,break_points和interpolation是它们对应的插值参数。在生成生成hdf5格式的核数据库时将particle_type、emission_mode、particle_number、break_points、interpolation写入相应产物粒子目录的属性中,energy、yields、xs写入相应产物粒子目录下的数据集中。100.对于每种产物粒子都有相应的出射角分布和能量分布,它们存储在distribution类中,从图3a中可以看到,distribution类中包含了三个字典:angle、energy、angle_energy,分别代表角分布、能量分布、角度-能量耦合分布,当分布类型为角度-能量耦合时,将不会有角分布和能量分布,因此在生成hdf5格式的核数据库时,不会同时出现三种分布的目录。角分布数据存储在angle类中,其中energy表示给出角分布的能量点,字典mu表示每个能量点对应的出射角分布,字典的键值对分别为能量点序号和存储出射角余弦信息的mu类,在生成hdf5格式的核数据库时创建angle目录,将energy和energy中每个能量点对应的出射角余弦写入该目录下的数据集中。当角分布是各向同性时将没有相关数据,此时需要将角分布类型type写入angle目录的属性中。由于不同的能量下给出的出射角余弦的个数可能不同,也或者是根本没有给出(即各向同性),所以需要对每个能量点对应的出射角余弦单独创建数据集,如果某个数据集为空则其属性中一定会表明是各向同性。101.能量分布、角度-能量耦合分布数据较为复杂,因为分布的种类较多,因此针对每种分布都设计了相应的law。每个law都包含了该分布的概率probability以及与之对应的能量energy_for_probability和插值参数interpolationfor_probability,由于每个出射粒子都可能不含不止一种出射能量分布类型,所以以上参数便是蒙卡程序用来抽样不同能量分布所需的参数。102.为了详细介绍针对ace格式的连续能量光核数据库所设计的photonuclearaceparserr类,图4a本公开实施例提供的一种photonuclearaceparser类设计部分结构示意图。图4b本公开实施例提供的一种photonuclearaceparser类设计另一部分结构示意图。如图4a与图4b所示,photonuclearaceparser类设计结构包括:103.对ace格式连续能量光核数据库中所包含的数据设计了三个数据块:energy、secondary_particles、reactions,其中reactions数据块中包含的数据有各反应道对应的能量点、光核反应截面值以及反应的释热量,此部分数据结构的设计与连续能量中子数据库的设计相同,因此不再赘述。104.不同于连续能量中子数据库,连续能量光核数据库的次级粒子除了中子、光子,还包含有电子、质子、氘核、氦核、氚核,photonuclearaceparser类中的字典secondary_particles的键值对分别为次级粒子编号和存储次级粒子数据的secondaryparticles类,在生成hdf5格式的光核数据库时会对每个次级粒子创建一个目录并将次级粒子的名称写入目录的属性中,由于能产生该次级粒子的反应道可能有多个,所以会将endf反应道编号也写入次级粒子目录的属性中。secondaryparticles类中的energy、xs、heating分别表示能量点、反应生成该次级粒子的截面以及热沉积数,这些数据全部写入次级粒子目录下的数据集中。由于能产生该次级粒子的反应道可能有多个,所以设计了secparproducereaction类对产生该次级粒子的所有反应道数据进行解析,secparproducereaction类中的corordinate表示该反应道数据所在坐标系,xs、yileds、energy分别表示该反应道产生该粒子的截面、产额以及对应的能量点,当然xs、yileds不会同时给出,若给出的是yileds可能还会给出相应的插值参数break_points、interpolation(若没有给出则默认线性插值)。105.为了详细介绍针对ace格式的中子热化库所设计的thermalneutronaceparser类,图5本公开实施例提供的一种thermalneutronaceparser类设计结构示意图。如图5所示,thermalneutronaceparser类设计结构包括:106.对ace格式连续能量中子热化核数据库中所包含的数据只设计一个数据块:reactions,解析到了thermalneutronaceparser类中的字典reactions字典中,该字典的键值对分别为反应道名称和存储反应道数据的类。对于热化库只有三个反应道:非相干非弹性散射、相干弹性散射、相干非弹性散射,分别设计了incoherentinelastic、coherentelastic、incoherentelastic类进行解析。由于不同温度下的热化库包含的反应道数据有所不同,因此在生成hdf5格式的中子热化核数据库时将根据thermalneutronaceparser类中temperature属性值创建相应的温度目录,然后根据reactions字典中的键值在温度目录下分别创建incoherentinelastic、coherentelastic、incoherentelastic目录。coherentelastic、incoherentelastic类比较简单,coherentelastic类只包含energy和xs,分别表示相干弹性散射的能量点和对应的截面值,incoherentelastic类除了包含energy和xs外还包含角分布数据mu。incoherentinelastic类除了包含energy和xs外还包含次级中子分布数据,存储在distributions字典中。次级中子分布均为角度-能量耦合分布,分为连续型和离散型,分别通过angleenergycontinuous、angleenergydiscrete类进行解析,两个类中都包含type属性,在生成hdf5格式的连续能量热化库时会将其写入对应反应道目录的属性中。其中angleenergydiscrete类中只包含了energy和mu,分别表示次级中子的能量和角分布,angleenergycontinuous类中的angle_energy字典用于存储incoherentinelastic类中energy给出的每个能量点对应的出射中子分布数据,angle_energy字典的键值对分别为energy中的能量点序号以及与之对应的存储出射中子分布数据的angleenergy类。angleenergy类中包含有出射能量点以及与之对应的出射角分布数据,每个出射能量点对应的出射角分布数据又通过mu类进行解析并存入angleenergy类中的字典mu中。107.为了详细介绍针对ace格式的连续能量光原数据库所设计的photoatomicaceparser类,图6本公开实施例提供的一种photoatomicaceparser类设计部分结构示意图。如图6所示,photoatomicaceparser类设计结构包括:108.对ace格式连续能量光原核数据库中所包含的数据设计了三个数据块:energy、heating、reactions、shells,其中energy和heating分别表示光原反应的主能量网格点以及与之对应的热沉积数,在生成hdf5格式的光原反应核数据库时解析到了energy和heating数据集中。photoatomicaceparser类中的reactions为存储光原反应的反应道数据的字典,该字典的键值对分别为反应道名称字符串以及对应的存储该反应道数据的类,光原反应一共有五种:非相干散射、相干散射、光电效应、电子对效应、荧光效应,分别对应五个类:incoherent、coherent、photoelectric、pairproduction、fluorescence。在生成hdf5格式的光原反应核数据库时通过遍历字典reactions将上述五个类中存储的数据写入以字典键值命名的目录下。photoatomicaceparser类中的shells为存储着原子壳层数据的列表,原子壳层数据包含了每个壳层的反应概率interpolation_probability、电子数electron_number、结合能binding_energy、康普顿轮廓compton_profile和其插值参数interpolation,在生成hdf5格式的光原反应核数据库时通过遍历列表shells将每个壳层的数据写入对应目录下,将interpolation_probability写入目录的属性,将interpolation写入compton_profile的属性。109.为了详细介绍针对ace格式的多群数据库所设计的multigroupaceparser类,图7本公开实施例提供的一种multigroupaceparser类设计结构示意图。如图7所示,multigroupaceparser类设计结构包括:110.ace格式多群数据库分为多群中子数据库和多群光子数据库,两者的数据格式完全相同,所以设计了multigroupaceparser类对整个多群数据库进行解析。对ace格式多群数据库中所包含的数据设计了八个数据块:particle_mass、group_center、group_width、fission_fraction、stopping_power、nu、secondary_particles、reactions,其中fission_fraction和nu分别表示各群的裂变份额及各群产生的裂变中子数,只对可裂变核素存在。particle_mass表示各能群对应的入射粒子的质量,只对除中子和光子外的其他粒子才会给出该数据。stopping_power只对带电粒子存在,表示各能群下该核素对入射粒子的阻止本领。group_center、group_width表示各群的中心能量值及能群宽度。reactions数据块存储着各反应道的截面和释热量数据,截面和释热量数据均与能群对应,在生成hdf5格式的多群核数据库时会创建reactions目录,然后通过遍历reactions字典reactions目录下生成各反应道子目录,目录以反应道名称命名,然后将截面和释热量数据写入反应道目录下的数据集中,endf反应道编号写入反应道目录的属性中,secondary_particles数据块存储着次级粒子数据,次级粒子数据通过multigroupsecondaryparticle类进行解析,particle_type表示次级粒子的类型,xs_p0是一个二维数组,表示各入射能群向各出射能群散射的截面,group_center、group_width表示次级粒子能群中心和能群宽度,angle是一个键值对分别为入射能群号和存储次级粒子角分布数据类multigroupangle的字典。multigroupangle类中的type表示分布的类型,字典to_group是键值对分别为出射能群号和存储次级粒子角分布数据类togroup的字典,togroup类中的id表示出射能群编号,mu表示某入射能群向该出射能群出射的角度余弦,type表示分布类型。在生成hdf5格式的多群核数据库时会创建secondary_particle目录,然后通过遍历secondary_particles字典创建每个次级粒子的目录,将xs_p0、group_center、group_width写入该目录下的数据集中,particle_type写入该目录的属性中。然后通过遍历字典angle对每个入射能群创建角分布目录,若type为“isotropic”(即各向同性)则会将其写入角分布目录属性,该目录将为空目录,否则将会遍历to_group字典该角分布目录下创建每个次级粒子能群的角分布数据集,数据集属性中会标明角分布的类型(“isotropic”或“equiprobable_cosine_bins”(即等概率余弦箱))。111.为了详细介绍针对ace格式的连续能量电子数据库所设计的electronaceparser类,图8本公开实施例提供的一种electronaceparser类设计结构示意图。如图8所示,electronaceparser类设计结构包括:112.对ace格式连续能量电子数据库中所包含的数据设计了两个数据块:reactions、shells,其中shells数据块包含的是原子各壳层的数据,之前的光原核数据库中已经进行过说明,此处不再赘述。electronaceparser类中的reactions为存储电子反应道数据的字典,该字典的键值对分别为反应道名称字符串以及对应的存储该反应道数据的类,光原反应一共有五种:非相干散射、相干散射、光电效应、电子对效应、荧光效应,分别对应四个类:augereffect、mottscattering、rileyscattering、bremsstrahlung,分别表示俄歇效应、莫特散射、瑞丽散射、韧致辐射。在生成hdf5格式的电子反应核数据库时通过遍历字典reactions将上述四个类中存储的数据写入以字典键值命名的目录下。113.综上所述,本技术实施例能够达到以下效果:114.1.本公开实施例生成了一套全新格式的核数据库,数据结构富有层次性且更具物理意义,清晰易懂,解决了传统ace格式核数据库人不可读的问题。115.2.通过整合不同温度点的核数据,减少了ace格式核数据库中大量的冗余数据,并且由于生成的hdf5格式的核数据库为二进制文件,占用存储空间也大大减小,解决了传统ace格式占用存储空间大的问题。116.3.科研工作者可以轻松地将自己需要的数据写入hdf5格式核数据库并在程序中得以应用,有效解决了传统ace核数据库难以扩展的问题。117.与上述的基于hdf5格式的核反应数据库制作方法相对应,本发明还提出一种基于hdf5格式的核反应数据库制作装置。由于本发明的装置实施例与上述的方法实施例相对应,对于装置实施例中未披露的细节可参照上述的方法实施例,本发明中不再进行赘述。118.图9为本公开实施例所提供的一种基于hdf5格式的核反应数据库制作装置的结构示意图。如图9所示,所述装置包括:119.读取单元21,用于基于第一预设类方法读取ace格式数据库的目录文件;120.第一解析单元22,用于基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对;121.第一获取单元23,用于通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应;122.传输单元24,用于将所述第二存储数据表参数传输至第三预设类方法;123.第二解析单元25,用于通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对;124.第二获取单元26,用于基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应;125.写入单元27,用于将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。126.本公开提供的基于hdf5格式的核反应数据库制作装置,基于第一预设类方法读取ace格式数据库的目录文件;基于第二预设类方法对所述目录文件进行解析和格式化,得到第一字典,所述第二预设类方法包括解析函数与格式化函数,所述第一字典分别以第一数据表标识字符串和第一存储数据表参数为键值对;通过循环遍历所述第一字典,根据第二数据表标识字符串获取所述第一字典中第二存储数据表参数,所述第二存储数据表参数与所述第二数据表标识字符串相对应;将所述第二存储数据表参数传输至第三预设类方法;通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二字典分别以第二数据表标识字符串和存储核数据类为键值对;基于预设函数循环遍历第二字典,获取存储核数据类,所述预设函数为第三预设类方法中函数的一种,所述存储核数据类与第二数据表标识字符串相对应;将所述存储核数据类写入hdf5格式的文件中,得到hdf5格式数据库,所述存储核数据类写入的文件以其对应的第二数据表标识字符串的标识前缀名命名。与相关技术相比,基于对ace格式数据库目录文件的解析,得到第一字典,基于输入的第二数据表标识字符串,在所述第一字典中遍历查询得到与第二数据表标识字符串对应的第二存储数据表参数,基于所述第二存储数据表参数,索引读取ace格式数据库的目标数据文件,对所述数据文件进行解析,并写入hdf5格式的文件,得到hdf5格式数据库,通过改变数据库结构和格式从而解决ace格式数据库数据结构固定而难以扩展,不具备人的可读性,数据访问效率低,占用存储空间大的问题。127.图10为本公开实施例所提供的另一种基于hdf5格式的核反应数据库制作装置的结构示意图。如图10所示,所述读取单元21包括:128.第一输入模块211,用于基于预设输入方式,输入所述目录文件的第一绝对路径;129.第二输入模块212,用于基于预设输入方式,输入第二绝对路径,所述第二绝对路径为hdf5格式数据库的生成路径与存储路径;130.读取模块213,用于根据所述第一绝对路径,使用第一预设类方法读取ace格式数据库的目录文件。131.进一步地,在本实施例一种可能的实现方式中,如图10所示,所述装置还包括:132.第二输入单元28,用于基于预设输入方式,输入所述第二数据表标识字符串。133.进一步地,在本实施例一种可能的实现方式中,如图10所示,所述第二解析单元25包括:134.确定模块251,用于基于所述第二数据表标识字符串的标识后缀,确定数据库类型;135.调用模块252,用于通过第三预设类方法根据数据库类型及所述第二存储数据表参数调用相应的第四预设类方法;136.解析模块253,用于通过所述第四预设类方法基于所述第二存储数据表参数从所述ace格式数据库中读取目标数据文件进行解析,得到第二字典,所述第二存储数据表参数包括ace格式数据库的相对路径、数据表所在数据文件的起始位置和数据表长度。137.需要说明的是,前述对方法实施例的解释说明,也适用于本实施例的装置,原理相同,本实施例中不再限定。138.根据本公开的实施例,本公开还提供了一种电子设备、一种可读存储介质和一种计算机程序产品。139.图11示出了可以用来实施本公开的实施例的示例电子设备300的示意性框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本公开的实现。140.如图11所示,设备300包括计算单元301,其可以根据存储在rom(read-onlymemory,只读存储器)302中的计算机程序或者从存储单元308加载到ram(randomaccessmemory,随机访问/存取存储器)303中的计算机程序,来执行各种适当的动作和处理。在ram303中,还可存储设备300操作所需的各种程序和数据。计算单元301、rom302以及ram303通过总线304彼此相连。i/o(input/output,输入/输出)接口305也连接至总线304。141.设备300中的多个部件连接至i/o接口305,包括:输入单元303,例如键盘、鼠标等;输出单元307,例如各种类型的显示器、扬声器等;存储单元308,例如磁盘、光盘等;以及通信单元309,例如网卡、调制解调器、无线通信收发机等。通信单元309允许设备300通过诸如因特网的计算机网络和/或各种电信网络与其他设备交换信息/数据。142.计算单元301可以是各种具有处理和计算能力的通用和/或专用处理组件。计算单元301的一些示例包括但不限于cpu(centralprocessingunit,中央处理单元)、gpu(graphicprocessingunits,图形处理单元)、各种专用的ai(artificialintelligence,人工智能)计算芯片、各种运行机器学习模型算法的计算单元、dsp(digitalsignalprocessor,数字信号处理器)、以及任何适当的处理器、控制器、微控制器等。计算单元301执行上文所描述的各个方法和处理,例如基于hdf5格式的核反应数据库制作方法。例如,在一些实施例中,地基于hdf5格式的核反应数据库制作方法可被实现为计算机软件程序,其被有形地包含于机器可读介质,例如存储单元308。在一些实施例中,计算机程序的部分或者全部可以经由rom302和/或通信单元309而被载入和/或安装到设备300上。当计算机程序加载到ram303并由计算单元301执行时,可以执行上文描述的方法的一个或多个步骤。备选地,在其他实施例中,计算单元301可以通过其他任何适当的方式(例如,借助于固件)而被配置为执行前述基于hdf5格式的核反应数据库制作方法。143.本文中以上描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、fpga(fieldprogrammablegatearray,现场可编程门阵列)、asic(application-specificintegratedcircuit,专用集成电路)、assp(applicationspecificstandardproduct,专用标准产品)、soc(systemonchip,芯片上系统的系统)、cpld(complexprogrammablelogicdevice,复杂可编程逻辑设备)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。144.用于实施本公开的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。145.在本公开的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、ram、rom、eprom(electricallyprogrammableread-only-memory,可擦除可编程只读存储器)或快闪存储器、光纤、cd-rom(compactdiscread-onlymemory,便捷式紧凑盘只读存储器)、光学储存设备、磁储存设备、或上述内容的任何合适组合。146.为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,crt(cathode-raytube,阴极射线管)或者lcd(liquidcrystaldisplay,液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者、触觉输入)来接收来自用户的输入。147.可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:lan(localareanetwork,局域网)、wan(wideareanetwork,广域网)、互联网和区块链网络。148.计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。服务器可以是云服务器,又称为云计算服务器或云主机,是云计算服务体系中的一项主机产品,以解决了传统物理主机与vps服务("virtualprivateserver",或简称"vps")中,存在的管理难度大,业务扩展性弱的缺陷。服务器也可以为分布式系统的服务器,或者是结合了区块链的服务器。149.其中,需要说明的是,人工智能是研究使计算机来模拟人的某些思维过程和智能行为(如学习、推理、思考、规划等)的学科,既有硬件层面的技术也有软件层面的技术。人工智能硬件技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理等技术;人工智能软件技术主要包括计算机视觉技术、语音识别技术、自然语言处理技术以及机器学习/深度学习、大数据处理技术、知识图谱技术等几大方向。150.应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发公开中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本公开公开的技术方案所期望的结果,本文在此不进行限制。151.上述具体实施方式,并不构成对本公开保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本公开的精神和原则之内所作的修改、等同替换和改进等,均应包含在本公开保护范围之内。当前第1页12当前第1页12
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。