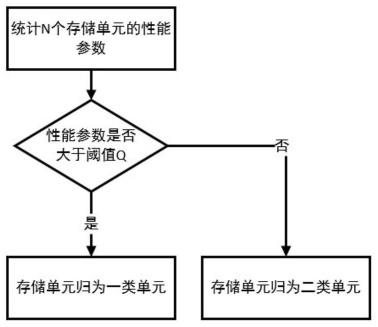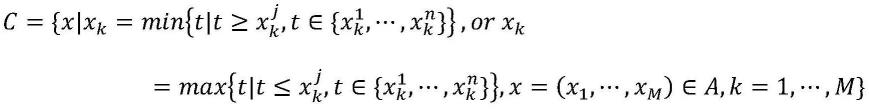
1.本发明属于合成气生产技术领域,具体涉及基于多目标粒子群优化算法的合成气生产优化方法。
背景技术:
2.合成气是一种用作化工原料的原料气,以一氧化碳和氢气为主要组成成分。广泛应用于甲醇,氨,氢和高级碳氢化合物的生产,由含碳化合物如煤、石油、天然气等转化而成。目前常采用的途径有甲烷的蒸汽重整、甲烷的二氧化碳重整、甲烷的部分氧化以及二氧化碳重整和甲烷部分氧化的组合等。按合成气的不同来源、组成和用途,它们也可被称为煤气、合成氨原料气,甲醇合成气等。
3.制造合成气的原料含有不同的h/c摩尔比,如煤中的h/c大约为1:1,而天然气中大约为4:1等,由这些原料所制得的合成气,其组成比例也各不相同。本应用通过二氧化碳重整和天然气在pt/γ-al2o3催化剂的作用下部分氧化的组合方法来生产合成气。这种合成气的生产方法会产生非常低的h2/co比,而且因为它是甲烷氧化的高放热反应和甲烷的二氧化碳重整的适度吸热反应的组合,更容易控制反应器温度。
4.本实验希望能得到最高的ch4转换率,最高的co选择率,以及最低的h2/co比率。希望在这三个维度上得到的结果都能尽可能地最优,而在有多个目标函数,且这些目标函数相互冲突的情况下,若使用单目标优化技术来优化参数,难以得到各方兼顾的结果,因此可以使用多目标优化技术更好地处理。与单目标问题会得到一个最优解不同,多目标优化问题往往会得到一系列的非支配解,称为帕累托最优解,这些解在空间上形成的曲面被称为帕累托前沿面。多目标优化算法的目的是尽可能达到以下几点:(1)得到的解尽可能接近最优解,(2)得到的解在帕累托前沿面上能尽量均匀地分布,(3)得到的解尽可能广泛地覆盖帕累托前沿。
5.一个多目标优化问题可以如下表示:
[0006][0007]
其中被称为决策变量,x是n维决策空间。fi(x)(i=1,
…
,m)是第i个需要最小化的目标。gi(x)(i=1,2,
…
,q)定义第i个不等式约束,hj(x)(j=1,2,
…
,p)定义第j个等式约束,所有的约束条件决定了可行解的集合,用ω表示,y={f(x)|x∈ω}表示目标空间。而多目标优化的任务就是尽量找到可行解x∈ω使每个fi(x)(i=1,
…
,m)尽可能小。以下是多目标优化问题中的几个定义:
[0008]
1)帕累托支配(pareto dominance):两个解x,z∈ω之间的帕累托支配定义如下,若:
[0009][0010]
则称x支配z,记作x>z。
[0011]
2)帕累托最优(pareto optimal):若则称解向量x是ω的帕累托最优解。
[0012]
3)帕累托最优解集(pareto optimal set(ps)):帕累托最优解的集合:
[0013][0014]
4)帕累托前沿面:帕累托最优解集经目标函数映射构成了该问题的帕累托前沿面:
[0015]
pf={f(x)|x∈ps}。
[0016]
粒子群算法是一种基于种群的随机全局进化算法,初始化为一群随机粒子(随机解),然后通过迭代找到最优解。粒子群算法有易实现,有效存储,能有效维护解的方案的多样性的特点,但是也有其缺点。它的首要问题是如何平衡收敛性和多样性。首先,因为多目标粒子群算法(multi-objective particle swarm optimization algorithms,mpso)的档案大小不受限制,非支配解的数量增长得非常快,因此会增加更新档案的成本。其次,物理内存的大小总是有限的,因此需要一种方案来筛选这些非支配解。此外,多目标粒子群优化问题还涉及到全局最优gbest与局部最优pbest的问题,因为不存在绝对的最佳解决方案,而是一组非支配解决方案,因此需要考虑该如何选择及更新pbest与gbest。
[0017]
而在基于分解的多目标进化算法(multi-objective evolutionary algorithm based on decomposition,moea/d)算法中,将靠近帕累托前沿的任务转换为多个单目标优化问题,若新解比旧解更接近最优解,再将旧解进行替换,这种算法搜索效率高,更有确定性,但这种方法忽略了新解可能在目标空间中的位置过于集中,会导致解集的多样性较差,而且面对未知前沿面的效率较差。
[0018]
超体积在多目标进化算法中主要用于评价搜索结果,另一方面,超体积也被结合在多目标进化算法中,作为归档策略或选择策略,引导算法进行搜索。在估计解的多样性和收敛性方面都有好的表现,超体积值越大,算法的综合性能越好。但它的缺点是计算复杂度大,因此我们仅将它应用在部分解,即剩余解的部分,来提高算法的效率。
技术实现要素:
[0019]
为了解决现有技术中存在的问题,本发明提供基于多目标粒子群优化算法的合成气生产优化方法,针对moea/d算法和mpso算法各自的缺点,本发明提出的算法采用分解的方法将目标空间分为数个子区域,将解也通过各个子区域进行分类,并选出每个子区域中的最优解,再对剩余解进行分类,选出能使该子区域超体积值最大的解,这样尽可能保证下一代种群的超体积值也尽量大,以达到同时提高多样性和收敛性的目的。
[0020]
为了实现上述目的,本发明采用的技术方案是:基于多目标粒子群优化算法的合成气生产优化方法,包括如下步骤:
[0021]
s1,设定合成气的工艺参数和目标函数,优化目标如下:
[0022]
1)最大化ch4转换率,f1;
[0023]
2)最大化co选择率,f2;
[0024]
3)最小化h2/co比率,f3;
[0025]
s2,初始化:设需要的种群数量为n,以o2/ch4进料摩尔比、气体时空速gv及温度t为生产工艺参数的三个自变量x=(x1,x2,x3),在符合实验要求的范围内随机生成一组数量为
2n的初始粒子以及一组初始速度,通过所述随机生成的初始粒子计算出相应的f(x)={fi(x)|x∈ω,i=1,2,3},即为目标空间,通过一组方向向量(γ1,γ2,
…
γn),将目标空间划分为n个子区域,并设立一个参考点z=(z1,
…
,zm),其中,zi=min{fi(x)|x∈ω,i=1,2,3};
[0026]
s3,分解和适应度计算:对种群根据子区域进行分解,选出各子区域中的最优解;根据最优解对剩余解再进行划分,选择能使超体积值最大的解,选出等于种群数量n的解为止,同时为领域更稀疏的解分配更高的适应度值;
[0027]
s4,生成新解:利用所述能使超体积值最大的解进行交叉操作和领域校正来产生后代,以及产生一组新的速度;
[0028]
s5,更新:如果存在j=1,
…
,m,使得zj》min{fj(x)|x∈ω},更新参考点,并根据适应度来更新粒子,以及更新pbest和gbest;
[0029]
s6,变异:使一部分粒子变异;
[0030]
s7,混合父代与子代,竞争产生下一种群,返回s3重复操作,迭代至设定次数后完成,即得到尽可能使f1、f2和f3最优时的o2/ch4进料摩尔比、气体时空速gv及温度t三个生产工艺参数。
[0031]
目标函数为:
[0032]
f1=-8.87
×
10-6
×
(86.74 14.6(o2/ch4)-3.06gv 18.82t 3.14(o2/ch4)gv-6.91(o2/ch4)
2-13.31t2)
[0033]
f2=-2.152
×
10-9
×
(39.46 5.98(o2/ch4)-2.4cv 13.06t 2.5(o2/ch4)cv 1.64cvt-3.9(o2/ch4)
2-10.15t
2-3.69gv2(o2/ch4)) 45.7
[0034]
f3=4.425
×
10-10
×
(1.29-0.45t-0.112(o2/ch4)gv-0.142gvt 0.109(o2/ch4)2 0.405t2 1.67t2gv) 0.18
[0035]
f1=c
ch4
,f2=s
co
,f3=h2/coratio。
[0036]
种群pop通过公式分成n类(p1,p2,
…
,pn),
[0037]
目标空间y通过公式分为n个子区域(y1,y2,
…
,yn),
[0038]
δ(f(x),γi)是γi与f(x)-z之间夹角的余弦,如果一个子区域内有一个解,则选择该解;如果一个子区域内有多个解,选择δ(f(x),γi)值最大的点作为该子区域中的最优解。
[0039]
分解和适应度计算时,采用超体积值作为适应度函数,选择最优解以及剩余解中使超体积值最大的粒子。
[0040]
s3中,对于已选出的最优解,将其组成的集合定义为a={x1,
…
,xn},剩余解所组成的集合定义为b={x
n 1
,...,xn},对于b中的任意一个解由下式确定其邻居集合其中m是集合c的大小:
[0041]
[0042]
然后确定c的上界和下界其中其中再由cu和c
l
确定集合df:
[0043][0044]
计算df中每一个解与cu构成的超体积值,选择该子区域中能使超体积值最大的个体记为y1,令b=b-df,重复上面的操作可以得到一组解y1,
…
,yk。
[0045]
s3中,为相对更加稀疏领域的支配解赋予更好的适应度值,采用拥挤度距离作为适应度函数,通过基于拥挤距离的二元锦标赛选择,选择出n个最佳粒子。
[0046]
s3中,若最优解的个数n≥n/2,即根据最优解划分出的区域数n 1≥n/2,得到的超体积值最大的解k≥n/2,则根据它们超体积值的大小进行排序,将超体积值大的和集合a保留下来作为下一代种群;若最优解的个数n《n/2,则每次可以选择出数量为n 1个超体积值最大的解,直到距离种群数量所缺的解数目小于n 1为止,剩余选择的解通过超体积值的大小排序决定,通过这几部分来构成下一代种群。
[0047]
s4中,第k个粒子的速度为vk=(v
k1
,
…
,v
kn
),位置为xk=(x
k1
,
…
,x
kn
),在每一次迭代中,粒子通过之前的全局最优值gbest与局部最优值pbest来更新粒子的速度与位置:
[0048][0049][0050]
通过当前粒子的领域进行搜索,利用邻域信息对当前粒子进行校正,粒子x的校正策略为:
[0051]
x
new
=x 0.5*(x
′‑
x
″
)
[0052]
其中,x
′
是全局最优,x
″
是局部最优。
[0053]
选择粒子x时,确定每个选定粒子的局部最优值pbest和全局最优值gbest,随机选择一个解作为全局最优值gbest或使用粒子的相邻解来确定其全局最优值gbest,全局最优值gbest是相邻解中目标向量与中心向量夹角最小的那个非支配解。
[0054]
与现有技术相比,本发明至少具有以下有益效果:种群的多样性与收敛性是矛盾的,本发明所述方法可以采用超体积的适应度函数来平衡算法的多样性与收敛性;超体积的计算中算法复杂度高,本发明通过结合分解的方式来提高算法效率。
[0055]
进一步的,分解和适应度计算时,采用超体积值作为适应度函数。选择最优解以及剩余解中使超体积值最大的那部分粒子,可以使下一代种群的超体积值尽可能大,从而提高解的多样性与收敛性。
附图说明
[0056]
图1为本发明一种算法流程图。
[0057]
图2为目标空间分解示意图。
具体实施方式
[0058]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发
明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0059]
参考图1,本发明应用了一种新的基于分解和超体积的多目标粒子群优化算法,结合了基于分解的多目标进化算法(multi-objective evolutionary algorithm based on decomposition,moea/d),分类并选择出超体积值(hypervolume,hv)最大的粒子,对多目标粒子群算法(multi-objective particle swarm optimization algorithms,mpso)的一种改进。
[0060]
本发明提出的改进算法主要包括四个部分:空间分解与种群分类、基于超体积的适应度函数进行更新、交叉操作和选择策略。其中,空间分解与种群分类和基于超体积的适应度函数进行更新来保持解的多样性;交叉操作用于搜索决策空间;选择策略帮助交叉操作进行全局搜索和局部搜索。
[0061]
(1)空间分解与种群分类
[0062]
将多目标优化问题的目标空间y基于一组方向向量(γ1,γ2,
…
γn)分解为一组子区域y1,y2,
…
,yn,然后对种群pop的解进行分类;空间分解与种群分类实现如下:
[0063][0064][0065][0066]
z=(z1,
…
,zm)是一个参考点,其中,zi=min{fi(x)|x∈ω},δ(f(x),γi)是γi与f(x)-z之间夹角的余弦,如果一个子区域内有一个解,则选择该解;如果一个子区域内有多个解,选择δ(f(x),γi)值最大的点作为该子区域中的最优解,即夹角应该尽可能小。种群pop通过公式(2)分成n类(p1,p2,
…
,pn),目标空间y通过公式(3)分为n个子区域(y1,y2,
…
,yn),所述分解方法有如下特征:1)所有子区域的帕累托前沿构成了多目标优化问题的帕累托前沿,2)因为每个子区域的帕累托前沿只是一小部分,因此即使该多目标优化问题的整个帕累托前沿是非线性集合形状,每个子区域的帕累托前沿也可以近似为线性,3)这种分类方法不需要任何聚合方法,只需要用户选择一组方向向量,因此,其计算量会很少。
[0067]
(2)基于超体积的适应度函数进行更新
[0068]
不一定每个子区域中都一定有解存在,当前最优解的个数一定小于或等于子区域的个数。对于已选出的最优解,将其组成的集合定义为a={x1,
…
,xn},剩余解所组成的集合定义为b={x
n 1
,
…
,xn},对于b中的任意一个解由下式确定其的邻居集合由下式确定其的邻居集合期中m是集合c的大小。
[0069][0070]
然后确定c的上界和下界其中
再由cu和c
l
确定集合df,
[0071][0072]
计算df中每一个解与cu构成的超体积值,选择该子区域中能使超体积值最大的个体记为y1,令b=b-df,重复上面的操作可以得到一组解y1,
…
,yk。
[0073]
如图2所示,每个点表示目标空间中的一个解,菱形的点是选出的最优解;虚线是目标空间通过权重向量分解出的均匀子区域,再通过最优解进行划分;最优解划分出的区域用实线表示,选出每个实线划分出的子区域内超体积值最大的解。
[0074]
若最优解的个数n≥n/2,即根据最优解划分出的区域数n 1≥n/2,得到的超体积值最大的解k≥n/2,则根据它们超体积值的大小进行排序,将超体积值大的和集合a保留下来作为下一代种群;若最优解的个数n《n/2,则每次可以选择出数量为n 1个超体积值最大的解,直到距离种群数量所缺的解数目小于n 1为止,剩余选择的解通过超体积值的大小排序决定,通过这几部分来构成下一代种群。
[0075]
通过精英策略,将子代与将父代种群混合,共同通过竞争来产生下一代种群,这有利于保持父代种群中的优良个体,保证那些优良的个体在进化的过程中能够被保留下来,从而提高种群水平,精英策略通常可以加快收敛速度,提高解的质量,而同时,我们也需要保持解的多样性。
[0076]
(3)交叉操作
[0077]
采用的交叉操作有两种:粒子群算法的交叉操作和领域校正。算法的全局搜索主要通过pso算法的交叉操作来实现,即通过等式(6)(7)实现。第k个粒子的速度表示为vk=(v
k1
,
…
,v
kn
),位置表示为xk=(x
k1
,
…
,x
kn
),在每一次迭代中,粒子通过之前的全局最优值(gbest)与局部最优值(pbest)来更新粒子的速度与位置:
[0078][0079][0080]
邻域校正是通过当前粒子的领域进行搜索,利用邻域信息对当前粒子进行校正,可以提高得到的解的质量,加速收敛到帕累托前沿。粒子x的校正策略为:
[0081]
x
new
=x 0.5*(x
′‑
x
″
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0082]
其中,x
′
是全局最优,x
″
是局部最优。
[0083]
(4)选择策略
[0084]
选择策略对算法的性能有很大的影响,选择策略的主要目的是帮助交叉算子进行局部搜索和全局搜索,选择合适的解产生后代。
[0085]
本发明中的第一种选择策略用于选择粒子x,即等式(6)(7)中的xk和等式(8)中的x。但存在一种特殊情况,如(3)中所说,一个支配解与一个比它更有优势的非支配解共存于一个区域内,但这个支配解的领域相对稀疏,选择该支配解可以保持更好的多样性,该支配解及其领域解生成的子解会比其他非支配解生成的子解更接近于该支配解所对应的子区域的帕累托前沿,所以需要给该支配解分配更高的适应度值,使该支配解更有可能被选中来产生后代。本发明使用拥挤距离来计算适应度值,以更好地选择出这类领域更稀疏的解。然后,通过基于拥挤距离的二元锦标赛选择,选择出n个最佳粒子。
[0086]
第二种选择策略是确定每个选定粒子的pbest和gbest。为节省存储空间,粒子的
pbest是它先前的最佳相邻粒子,而且是从其相邻粒子中随机选出的,在单目标问题中,只会有一个全局最优gbest,但在多目标问题中,会有一组非支配解都可以作为gbest,有两种策略可以用来选择gbest。第一种是随机选择一个解作为gbest,这种策略可以帮助交叉操作进行全局搜索;第二种是使用粒子的相邻解来确定其gbest,gbest是相邻解中目标向量与中心向量夹角最小的那个非支配解,这种策略可以帮助交叉操作进行局部搜索。
[0087]
原实验在由石英制成的微型u形管式反应器中进行,并放置催化剂。反应物是天然气,由79%ch4,17%c2h6,4%c3h8组成,在分子筛上的压缩干燥空气由20%o2、79%n2和1%ar和超纯co2(99.99%)组成,o2/ch4进料摩尔比在[0.25,0.55]gmol/gmol;气体时空速gv在[10.000,20.000]h-1
;实验温度t在[600,1100]℃。
[0088]
co2重整与ch4部分氧化实验反应公式如下:
[0089][0090]
尽可能做到以下几点:
[0091]
1)最大化ch4转换率,f1;
[0092]
2)最大化co选择率,f2;
[0093]
3)最小化h2/co比率,f3;
[0094]
其中,目标函数的系数如下:
[0095][0096]
目标函数为:
[0097]
f1=-8.87
×
10-6
×
(86.74 14.6(o2/ch4)-3.06gv 18.82t 3.14(o2/ch4)gv-6.91(o2/ch4)
2-13.31t2)
[0098]
f2=-2.152
×
10-9
×
(39.46 5.98(o2/ch4)-2.4gv 13.06t 2.5(o2/ch4)gv 1.64gvt-3.9(o2/ch4)
2-10.15t
2-3.69gv2(o2/ch4)) 45.7
[0099]
f3=4.425
×
10-10
×
(1.29-0.45t-0.112(o2/ch4)gv-0.142gvt 0.109(o2/ch4)2 0.405t2 1.67t2gv) 0.18
[0100]
算法参数设置:种群数量为1275,交叉概率为1,变异概率为1/3,迭代1000次。步骤如下:
[0101]
1)初始化:通过一组方向向量(γ1,γ2,
…
γn),将目标空间划分为n个子区域,随
机生成一组初始个体以及一组初始速度。且设立一个参考点z=(z1,
…
,zm)是一个参考点,其中,zi=min{fi(x)|x∈ω}
[0102]
2)分解和适应度计算:对种群根据子区域进行分解,选出各子区域中的最优解;根据最优解对剩余解再进行划分,选择能使超体积值最大的解,选出等于种群数量n的解为止。并给领域更稀疏的解分配更高的适应度值。
[0103]
3)生成新解:利用这些被选出来的解进行交叉操作和领域校正来产生后代,以及产生一组新的速度。
[0104]
4)更新:如果存在j=1,
…
,m,使得zj》min{fj(x)|x∈ω},则更新参考点,并根据适应度来更新粒子,以及更新pbest和gbest。
[0105]
5)变异:使一部分粒子变异,以使粒子分布更加均匀,提高种群的多样性。
[0106]
6)混合父代与子代,竞争产生下一种群,返回步骤2)重复操作,直到迭代完成。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。