1.本发明涉及人工智能技术领域,特别是涉及一种基于特征和动作的视频行为检测人工智能方法和机器人。
背景技术:
2.物体检测类项目中经过了多年的发展,形成了一套成熟的建模体系。这主要包括两种:二级(two stage)目标检测算法,其首先获取候选区域,然后再对候选区域进行类别判定和位置修正,算法本身精度较高,但速度较慢;一级(one stage)目标检测算法,神经网络直接输出目标位置和位置信息。二级目标检测算法有代表性的比如:rcnn、sppnet、mask rcnn等;一级目标检测算法代表性的比如yolo、ssd、fpn、efficientdet等。
3.行为检测action detection类似图像目标检测,不仅要知道一个动作在视频中是否发生,还需要知道动作发生在视频的哪段时间。行为检测action detection问题难度比action recognition高很多,所以现在还没有效果较好的方法。需要处理较长的,未分割的视频。且视频通常有较多干扰,目标动作一般只占视频的一小部分。根据待检测视频是一整段读入的还是逐次读入的,分为online和offline两种。offline action detection一次读入一整段视频,然后在这一整段视频中定位动作发生的时间。online action detection不断读入新的帧,在读入帧的过程中需要尽可能早的发现动作的发生(在动作尚未结束时就检测到)。同时online action detection还需要满足实时性要求,这点非常重要。这导致online action detection不能采用计算复杂度过大的方法(在现有的计算能力下)。逐帧检测法即在视频序列的每帧上独立判断动作的类型,可以用cnn等方法,仅用上了spatial的信息。滑窗法即设置一个固定的滑窗大小,在视频序列上进行滑窗,然后对滑窗得到的视频小片断利用action recognition的方法进行分类。
4.在实现本发明过程中,发明人发现现有技术中至少存在如下问题:现有技术下,视频中行为检测如果用滑窗方式则速度太慢、太耗时,如果用逐帧检测法则只能检测静态的内容、对于动态的动作检测不准确。
5.因此,现有技术还有待于改进和发展。
技术实现要素:
6.基于此,有必要针对现有技术的缺陷或不足,提供基于特征和动作的视频行为检测人工智能方法和机器人,用来辅助人工视频行为检测,可以提高视频行为检测的效率和效果,使得预设类型的行为能够毫无遗漏地被检测到。
7.第一方面,本发明实施例提供一种人工智能方法,所述方法包括:
8.典型特征选择步骤:获取每一种预设类型的行为动作的k个视频片段(k为大于1的自然数),将所述多个视频片段中每一视频片段作为输入,通过预设的物体检测深度学习模型计算,得到所述每一种预设类型的行为动作的所述每一视频片段中的每一物体类型,将所述每一视频片段中的每一物体类型加入典型特征备选集合;统计典型特征备选集合中每
一物体类型的数量,若所述每一物体类型的数量/k大于或等于预设比例,则将所述每一物体类型作为一种典型特征;
9.典型特征检测步骤:获取待检测视频中每一帧图像,将所述每一帧图像作为输入,通过典型特征检测深度学习模型的计算,得到的输出作为所述每一帧图像的典型特征的标签;若所述每一帧图像的典型特征的标签不为空,则根据所述每一帧图像的典型特征的标签中的标记范围从所述每一帧图像中截取标记范围内的图像;将所述标记范围内的图像作为输入,通过人物识别图像深度学习模型的计算,得到的输出作为所述每一帧图像的典型特征的标签中人物的信息;
10.待检测帧标记步骤:获取所述待检测视频中每一帧图像及所述每一帧图像的典型特征的标签;若所述每一帧图像的典型特征的标签不为空,则将根据所述典型特征的标签中典型特征的名称确定对应的预设类型的行为动作的预设最大时长,作为待检测预设时长;若所述典型特征的标签有多个不为空,则根据所述典型特征的多个标签中多个典型特征的名称确定对应的多个预设类型的行为动作的多个预设最大时长,取多个预设最大时长中最大的多个预设最大时长,作为待检测预设时长;若所述每一帧图像的典型特征的标签不为空,则将所述每一帧图像标记为待检测帧,将所述每一帧图像前所述待检测预设时长/2的时长的所有帧标记为待检测帧,将所述每一帧图像后所述待检测预设时长/2的时长的所有帧标记为待检测帧;有些帧会被重复地标记为待检测帧,有些帧则不会被标记为待检测帧;
11.待检测视频片段截取步骤:将所述待检测视频中标记为待检测帧且未标记为已抽取的连续帧抽取出来作为一个待检测视频片段,将已抽取的待检测帧标记为已抽取;
12.预设类型的行为动作检测步骤:将所述待检测视频片段作为输入,经过预设类型的行为动作检测深度学习模型计算得到的输出作为所述待检测视频片段中预设类型的行为动作的标签;将所述标记范围内的视频片段作为输入,通过人物视频识别深度学习模型的计算,得到的输出作为所述视频片段的预设类型的行为动作的标签中人物的信息;将所有所述待检测视频片段中预设类型的行为动作的标签作为所述待检测视频中预设类型的行为动作的标签;
13.待检测视频标记步骤:将所述带有每一种预设类型的行为动作的标签的所述待检测视频片段替换所述待检测视频中对应的所述待检测视频片段,得到标记了预设类型的行为动作后的待检测视频。
14.优选地,所述方法还包括:
15.视频获取步骤:获取待检测视频;
16.预设类型的行为动作设置步骤:获取用户设置的预设类型的行为动作;
17.获取预设类型的行为动作的视频步骤:获取每一种所述预设类型的行为动作的视频样本;
18.获取预设类型的行为动作典型特征设置步骤:获取用户设置的预设类型的行为动作的典型特征;
19.获取预设类型的行为动作的典型特征的图像步骤:获取每一种所述典型特征的图像样本。
20.优选地,所述方法还包括:
21.建立视频行为知识图谱步骤:建立多个预设类型的行为动作实体、多个典型特征实体、多个人物实体、多个监管部门实体、多个监管人员实体;
22.某些人物,例如名人、领导干部,也需要从视频检测中顺便查找出来并发送给监管部门,以免侵权行为的发生。
23.某些人物,例如逃犯等等,需要从视频检测中顺便查找出来,并发送给监管部门。
24.视频行为知识图谱关系定义步骤:人物实体通过具有关系指向预设类型的行为动作实体;人物实体通过具有关系指向典型特征实体;人物实体通过在关系指向监管部门实体;监管人员实体通过在关系指向监管部门实体;
25.视频行为知识图谱静态关系生成步骤:根据用户设置的预设类型的行为动作的典型特征,在典型特征实体和预设类型的行为动作实体之间建立关系。
26.优选地,所述方法还包括:
27.典型特征检测模型构建步骤:将每一种典型特征的图像样本作为输入,将所述每一种典型特征的标签作为预期输出,对深度学习模型进行训练和测试,得到典型特征检测深度学习模型;
28.预设类型的行为动作检测模型构建步骤:将每一种预设类型的行为动作的视频样本作为输入,将所述每一种预设类型的行为动作的标签作为预期输出,对深度学习模型进行训练和测试,得到预设类型的行为动作检测深度学习模型;
29.人物图像识别模型构建步骤:获取每一人物的照片,将所述每一人物的照片作为输入,将所述人物的信息作为预期输出,对人脸图像识别深度学习模型进行迁移学习,得到人物图像识别深度学习模型;
30.人物视频识别模型构建步骤:获取每一人物的视频,将所述每一人物的视频作为输入,将所述人物的信息作为预期输出,对人脸视频识别深度学习模型进行迁移学习,得到人物视频识别深度学习模型。
31.第二方面,本发明实施例提供一种人工智能系统,所述系统包括:
32.典型特征选择模块:获取每一种预设类型的行为动作的k个视频片段(k为大于1的自然数),将所述多个视频片段中每一视频片段作为输入,通过预设的物体检测深度学习模型计算,得到所述每一种预设类型的行为动作的所述每一视频片段中的每一物体类型,将所述每一视频片段中的每一物体类型加入典型特征备选集合;统计典型特征备选集合中每一物体类型的数量,若所述每一物体类型的数量/k大于或等于预设比例,则将所述每一物体类型作为一种典型特征;
33.典型特征检测模块:获取所述待检测视频中每一帧图像,将所述每一帧图像作为输入,通过典型特征检测深度学习模型的计算,得到的输出作为所述每一帧图像的典型特征的标签;若所述每一帧图像的典型特征的标签不为空,则根据所述每一帧图像的典型特征的标签中的标记范围从所述每一帧图像中截取标记范围内的图像;将所述标记范围内的图像作为输入,通过人物识别图像深度学习模型的计算,得到的输出作为所述每一帧图像的典型特征的标签中人物的信息;
34.待检测帧标记模块:获取所述待检测视频中每一帧图像及所述每一帧图像的典型特征的标签;若所述每一帧图像的典型特征的标签不为空,则将根据所述典型特征的标签中典型特征的名称确定对应的预设类型的行为动作的预设最大时长,作为待检测预设时
长;若所述典型特征的标签有多个不为空,则根据所述典型特征的多个标签中多个典型特征的名称确定对应的多个预设类型的行为动作的多个预设最大时长,取多个预设最大时长中最大的多个预设最大时长,作为待检测预设时长;若所述每一帧图像的典型特征的标签不为空,则将所述每一帧图像标记为待检测帧,将所述每一帧图像前所述待检测预设时长/2的时长的所有帧标记为待检测帧,将所述每一帧图像后所述待检测预设时长/2的时长的所有帧标记为待检测帧;有些帧会被重复地标记为待检测帧,有些帧则不会被标记为待检测帧;
35.待检测视频片段截取模块:将所述待检测视频中标记为待检测帧且未标记为已抽取的连续帧抽取出来作为一个待检测视频片段,将已抽取的待检测帧标记为已抽取;
36.预设类型的行为动作检测模块:将所述待检测视频片段作为输入,经过预设类型的行为动作检测深度学习模型计算得到的输出作为所述待检测视频片段中预设类型的行为动作的标签;将所述标记范围内的视频片段作为输入,通过人物视频识别深度学习模型的计算,得到的输出作为所述视频片段的预设类型的行为动作的标签中人物的信息;将所有所述待检测视频片段中预设类型的行为动作的标签作为所述待检测视频中预设类型的行为动作的标签;
37.待检测视频标记模块:将所述带有每一种预设类型的行为动作的标签的所述待检测视频片段替换所述待检测视频中对应的所述待检测视频片段,得到标记了预设类型的行为动作后的待检测视频。
38.优选地,所述系统还包括:
39.视频获取模块:获取待检测视频;
40.预设类型的行为动作设置模块:获取用户设置的预设类型的行为动作;
41.获取预设类型的行为动作的视频模块:获取每一种所述预设类型的行为动作的视频样本;
42.获取预设类型的行为动作典型特征设置模块:获取用户设置的预设类型的行为动作的典型特征;
43.获取预设类型的行为动作的典型特征的图像模块:获取每一种所述典型特征的图像样本。
44.优选地,所述系统还包括:
45.建立视频行为知识图谱模块:建立多个预设类型的行为动作实体、多个典型特征实体、多个人物实体、多个监管部门实体、多个监管人员实体;
46.视频行为知识图谱关系定义模块:人物实体通过具有关系指向预设类型的行为动作实体;人物实体通过具有关系指向典型特征实体;人物实体通过在关系指向监管部门实体;监管人员实体通过在关系指向监管部门实体;
47.视频行为知识图谱静态关系生成模块:根据用户设置的预设类型的行为动作的典型特征,在典型特征实体和预设类型的行为动作实体之间建立关系。
48.优选地,所述系统还包括:
49.典型特征检测模型构建模块:将每一种典型特征的图像样本作为输入,将所述每一种典型特征的标签作为预期输出,对深度学习模型进行训练和测试,得到典型特征检测深度学习模型;
50.预设类型的行为动作检测模型构建模块:将每一种预设类型的行为动作的视频样本作为输入,将所述每一种预设类型的行为动作的标签作为预期输出,对深度学习模型进行训练和测试,得到预设类型的行为动作检测深度学习模型;
51.人物图像识别模型构建模块:获取每一人物的照片,将所述每一人物的照片作为输入,将所述人物的信息作为预期输出,对人脸图像识别深度学习模型进行迁移学习,得到人物图像识别深度学习模型;
52.人物视频识别模型构建模块:获取每一人物的视频,将所述每一人物的视频作为输入,将所述人物的信息作为预期输出,对人脸视频识别深度学习模型进行迁移学习,得到人物视频识别深度学习模型。
53.第三方面,本发明实施例提供一种人工智能装置,所述装置包括第二方面实施例任意一项所述系统的模块。
54.第四方面,本发明实施例提供一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现第一方面实施例任意一项所述方法的步骤。
55.第五方面,本发明实施例提供一种机器人,包括存储器、处理器及存储在存储器上并可在处理器上运行的人工智能机器人程序,所述处理器执行所述程序时实现第一方面实施例任意一项所述方法的步骤。
56.本实施例提供的基于特征和动作的视频行为检测人工智能方法和机器人,包括:典型特征选择步骤;典型特征检测步骤;待检测帧标记步骤;待检测视频片段截取步骤;预设类型的行为动作检测步骤;待检测视频标记步骤。上述方法、系统和机器人,通过先选择典型特征可以得到行为动作的典型特征种类,然后检测典型特征,再在具备典型特征的那些视频段进行预设类型的行为动作的检测,就减少了很多不含有典型特征的视频段的检测,从而可以极大地提高检测的速度和效率。这种方式,对于实时视频获取同样适用,在没有典型特征出现时则无需进行预设类型的行为动作的检测,从而可以极大地节省计算成本,提高检测速度,能够达到实时检测的效果。
附图说明
57.图1为本发明的一个实施例提供的人工智能系统的模块图;
58.图2为本发明的一个实施例提供的人工智能系统包括的模块图;
59.图3为本发明的一个实施例提供的人工智能系统包括的模块图;
60.图4为本发明的一个实施例提供的人工智能系统包括的模块图。
具体实施方式
61.下面结合本发明实施方式,对本发明实施例中的技术方案进行详细地描述。
62.本发明的基本实施例
63.第一方面,本发明实施例提供一种人工智能方法,所述方法包括:典型特征选择步骤;典型特征检测步骤;待检测帧标记步骤;待检测视频片段截取步骤;预设类型的行为动作检测步骤;待检测视频标记步骤。技术效果:通过先选择典型特征可以得到行为动作的典型特征种类,然后检测典型特征,再在具备典型特征的那些视频段进行预设类型的行为动作的检测,就减少了很多不含有典型特征的视频段的检测,从而可以极大地提高检测的速
度和效率。这种方式,对于实时视频获取同样适用,在没有典型特征出现时则无需进行预设类型的行为动作的检测,从而可以极大地节省计算成本,提高检测速度,能够达到实时检测的效果。
64.优选地,所述方法还包括:视频获取步骤;预设类型的行为动作设置步骤;获取预设类型的行为动作的视频步骤;获取预设类型的行为动作典型特征设置步骤;获取预设类型的行为动作的典型特征的图像步骤。技术效果:允许用户自行设置典型特征和预设类型的行为动作,从而可以实现千人千面的个性化的检测,满足不同用户的需求,因为不能用户希望的检测标准不同,如果事先在系统中固定、不允许用户设置,那么就会存在技术缺陷,本技术有效地克服了此技术缺陷,能够更为个性化地进行检测。
65.优选地,所述方法还包括:建立视频行为知识图谱步骤;视频行为知识图谱关系定义步骤;视频行为知识图谱静态关系生成步骤。技术效果:通过知识图谱可以让人物、监管部门、典型特征、预设类型的行为动作等关系一目了然,能够提高用户体验,且有利于利用这种关系进行更为精准的检测。
66.优选地,所述方法还包括:典型特征检测模型构建步骤;预设类型的行为动作检测模型构建步骤;人物图像识别模型构建步骤;人物视频识别模型构建步骤。技术效果:通过深度学习技术进行典型特征和动作模型的训练,可以克服传统的模式匹配和专家系统的不足。
67.第二方面,本发明实施例提供一种人工智能系统,如图1所示,所述系统包括:典型特征选择模块;典型特征检测模块;待检测帧标记模块;待检测视频片段截取模块;预设类型的行为动作检测模块;待检测视频标记模块。
68.优选地,如图2所示,所述系统还包括:视频获取模块;预设类型的行为动作设置模块;获取预设类型的行为动作的视频模块;获取预设类型的行为动作典型特征设置模块;获取预设类型的行为动作的典型特征的图像模块。
69.优选地,如图3所示,所述系统还包括:建立视频行为知识图谱模块;视频行为知识图谱关系定义模块;视频行为知识图谱静态关系生成模块。
70.优选地,如图4所示,所述系统还包括:典型特征检测模型构建模块;预设类型的行为动作检测模型构建模块;人物图像识别模型构建模块;人物视频识别模型构建模块。
71.第三方面,本发明实施例提供一种人工智能装置,所述装置包括第二方面实施例任意一项所述系统的模块。
72.第四方面,本发明实施例提供一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现第一方面实施例任意一项所述方法的步骤。
73.第五方面,本发明实施例提供一种机器人,包括存储器、处理器及存储在存储器上并可在处理器上运行的人工智能机器人程序,所述处理器执行所述程序时实现第一方面实施例任意一项所述方法的步骤。
74.本发明的优选实施例
75.视频获取步骤:获取待检测视频;优选地,实时地获取待检测视频。
76.预设类型的行为动作设置步骤:获取用户设置的预设类型的行为动作,包括暴力的动作、或色情的动作、或血腥的动作、或裸露的动作。优选地,获取用户设置的多个预设类型的行为动作。
77.获取预设类型的行为动作的视频步骤:获取每一种所述预设类型的行为动作的视频样本;优选地,获取每一种所述预设类型的行为动作的大量视频样本;优选地,获取每一种所述预设类型的行为动作的第一预设数个视频样本;优选地,不同种类的所述预设类型的行为动作的第一预设数不同,复杂的所述预设类型的行为动作的第一预设数大,简单的所述预设类型的行为动作的第一预设数小,越复杂的所述预设类型的行为动作的第一预设数越大。
78.获取预设类型的行为动作典型特征设置步骤:获取用户设置的预设类型的行为动作的典型特征,包括暴力的动作的典型特征为刀或枪或拳头、或色情的动作的典型特征为乳房或阴部或人在床上、或裸露的动作的典型特征为身上全部或部分没有穿衣服。优选地,获取用户设置的预设类型的行为动作的典型特征。可以看出的是,是某个动作的典型特征,则不一定是该动作,反过来,如果是某个动作,必然会出现该动作的典型特征,也就是说依靠典型特征,容易出现误检,把没有预设类型的行为动作当成预设类型的行为动作,但不会发生漏检,也就是说不会出现是预设类型的行为动作却检不出该典型特征。因此,预设类型的行为动作典型特征可以用于初检,从而提高预设类型的行为动作检测的速度和效率,节省检测的时间和成本,因为典型特征是静态的图像就可以描述的,而预设类型的行为动作是一连贯的动作,只能用视频来描述,显然从待检测视频中检测特定图像的效率和速度要远远高于检测特定视频的效率和速度,从而降低检测的成本,对于碳中和和节能都有着重要的意义。但仅仅靠典型特征来进行检测是不够的,因为典型特征无法唯一确定是预设类型的行为动作,例如典型特征刀,也有可能是超市货架上的刀。所以通过典型特征的图像进行初检之后需要通过动作视频进一步进行确诊。
79.获取预设类型的行为动作的典型特征的图像步骤:获取每一种所述典型特征的图像样本;优选地,获取每一种所述典型特征的大量图像样本;优选地,获取每一种所述典型特征的第二预设数个图像样本;优选地,不同种类的所述典型特征的第二预设数不同,复杂的所述典型特征的第二预设数大,简单的所述典型特征的第二预设数小,越复杂的所述典型特征的第二预设数越大。
80.建立视频行为知识图谱步骤:建立多个预设类型的行为动作实体、多个典型特征实体、多个人物实体、多个监管部门实体、多个监管人员实体。
81.视频行为知识图谱关系定义步骤:典型特征实体通过属于关系指向预设类型的行为动作实体,一个典型特征实体与一个或多个预设类型的行为动作实体之间存在属于关系,一个预设类型的行为动作实体与一个或多个典型特征实体之间存在属于关系。人物实体通过具有关系指向预设类型的行为动作实体,一个人物实体与零个或一个或多个预设类型的行为动作实体之间存在具有关系,一个预设类型的行为动作实体与零个或一个或多个人物实体之间存在具有关系。人物实体通过具有关系指向典型特征实体,一个人物实体与零个或一个或多个典型特征实体之间存在具有关系,一个典型特征实体与零个或一个或多个人物实体之间存在具有关系。人物实体通过在关系指向监管部门实体,一个人物实体与一个监管部门实体之间存在在关系,一个监管部门实体与多个人物实体之间存在在关系。监管人员实体通过在关系指向监管部门实体,一个监管人员实体与一个监管部门实体之间存在在关系,一个监管部门实体与多个监管人员实体之间存在在关系。
82.视频行为知识图谱静态关系生成步骤:根据用户设置的预设类型的行为动作的典
型特征,在典型特征实体和预设类型的行为动作实体之间建立关系。
83.典型特征选择步骤:获取预设的物体检测深度学习模型,所述物体检测深度学习模型能够从图像中检测出非常多种的物体,例如yolo、ssd、fpn、efficientdet;获取每一种预设类型的行为动作的多个视频片段,将所述多个视频片段中每一视频片段作为输入,通过预设的物体检测深度学习模型计算,得到所述每一种预设类型的行为动作的所述每一视频片段中的每一物体类型,将所述每一视频片段中的每一物体类型加入典型特征备选集合(例如,获取每一种预设类型的行为动作的k个视频片段,将所述k个视频片段中每一视频片段作为输入,通过预设的物体检测深度学习模型计算,得到所述每一种预设类型的行为动作的所述每一视频片段中的每一物体的物体类型;将第1视频片段至第k视频片段中的每一物体的物体类型加入典型特征备选集合)。所述每一种预设类型的行为动作的视频片段中的每一帧图像组成了所述每一种预设类型的行为动作。统计典型特征备选集合中每一物体类型的数量,若所述每一物体类型的数量/k大于或等于预设比例,则将所述每一物体类型作为一种典型特征,得到多种典型特征。
84.典型特征检测模型构建步骤:将每一种典型特征的图像样本作为输入,将所述每一种典型特征的标签作为预期输出,对深度学习模型进行训练和测试,得到典型特征检测深度学习模型。所述每一种典型特征的图像样本中用预设标志标记出了具有所述每一种典型特征的范围,例如典型特征为刀或枪或拳头,将图像中刀或枪或拳头用方框框上。所述每一种典型特征的标签包括所述每一种典型特征的名称(例如刀或枪或拳头)、所述每一种典型特征在图像中的标志的位置,例如方框的位置(4个顶点坐标)。若所述每一种典型特征的标签中所述每一种典型特征在图像中的标志的位置为空,则表明所述图像样本不包含所述每一种典型特征。
85.预设类型的行为动作检测模型构建步骤:将每一种预设类型的行为动作的视频样本作为输入,将所述每一种预设类型的行为动作的标签作为预期输出,对深度学习模型进行训练和测试,得到预设类型的行为动作检测深度学习模型;所述每一种预设类型的行为动作的视频样本中用预设标志标记出了所述每一种预设类型的行为动作且标记的范围需要涵盖所述每一种预设类型的行为动作,这里范围包括空间范围和时间范围,时间范围从所述每一种预设类型的行为动作的起始帧到结束帧,例如预设类型的行为动作为暴力的动作,将视频中预设类型的行为动作为暴力的动作从起始帧到结束帧中每一帧的预设类型的行为动作为暴力的动作用方框框上。所述每一种预设类型的行为动作的标签包括所述每一种预设类型的行为动作的名称(例如暴力的动作)、所述每一种预设类型的行为动作的起始帧、结束帧、在每一帧中的标志的位置,例如每一帧中方框的位置(4个顶点坐标)。若所述每一种预设类型的行为动作的标签中所述每一种预设类型的行为动作的起始帧、结束帧为空,则表明所述视频样本不包含所述每一种预设类型的行为动作。
86.人物图像识别模型构建步骤:获取每一人物的照片,将所述每一人物的照片作为输入,将所述人物的信息(人物的信息例如人物的姓名或身份证号或学号)作为预期输出,对人脸图像识别深度学习模型进行迁移学习,得到人物图像识别深度学习模型。
87.人物视频识别模型构建步骤:获取每一人物的视频,将所述每一人物的视频作为输入,将所述人物的信息(人物的信息例如人物的姓名或身份证号或学号)作为预期输出,对人脸视频识别深度学习模型进行迁移学习,得到人物视频识别深度学习模型。
88.典型特征检测步骤:获取所述待检测视频中每一帧图像,将所述每一帧图像作为输入,通过典型特征检测深度学习模型的计算,得到的输出作为所述每一帧图像的典型特征的标签。若所述每一帧图像的典型特征的标签不为空(若为空,则表明所述每一帧图像不具备典型特征),则根据所述每一帧图像的典型特征的标签中的标记范围从所述每一帧图像中截取标记范围内的图像。将所述标记范围内的图像作为输入,通过人物识别图像深度学习模型的计算,得到的输出作为所述每一帧图像的典型特征的标签中人物的信息(人物的信息可以为空,因为有的动作中不一定有人物)。若所述每一帧图像的典型特征的标签不为空,则所述每一帧图像含有一个或多个典型特征。
89.待检测帧标记步骤:获取所述待检测视频中每一帧图像及所述每一帧图像的典型特征的标签。若所述每一帧图像的典型特征的标签不为空,则将根据所述典型特征的标签中典型特征的名称确定对应的预设类型的行为动作的预设最大时长,作为待检测预设时长。若所述典型特征的标签有多个不为空,则根据所述典型特征的多个标签中多个典型特征的名称确定对应的多个预设类型的行为动作的多个预设最大时长,取多个预设最大时长中最大的多个预设最大时长,作为待检测预设时长。若所述每一帧图像的典型特征的标签不为空,则将所述每一帧图像标记为待检测帧,将所述每一帧图像前所述待检测预设时长/2的时长的所有帧标记为待检测帧,将所述每一帧图像后所述待检测预设时长/2的时长的所有帧标记为待检测帧。有些帧会被重复地标记为待检测帧,有些帧则不会被标记为待检测帧。
90.待检测视频片段截取步骤:将所述待检测视频中标记为待检测帧且未标记为已抽取的连续帧抽取出来作为一个待检测视频片段,将已抽取的待检测帧标记为已抽取。从待检测视频中能够抽取0个或1个或多个待检测视频片段。
91.预设类型的行为动作检测步骤:将所述待检测视频片段作为输入,经过预设类型的行为动作检测深度学习模型计算得到的输出作为所述待检测视频片段中预设类型的行为动作的标签。将所述标记范围内的视频片段作为输入,通过人物视频识别深度学习模型的计算,得到的输出作为所述视频片段的预设类型的行为动作的标签中人物的信息信息(人物的信息可以为空,因为有的动作中不一定有人物)。若所述每一帧图像的典型特征的标签不为空,则所述每一帧图像含有一个或多个典型特征。将所有所述待检测视频片段中预设类型的行为动作的标签作为所述待检测视频中预设类型的行为动作的标签。
92.待检测视频标记步骤:将所述带有每一种预设类型的行为动作的标签的所述待检测视频片段替换所述待检测视频中对应的所述待检测视频片段,得到标记了预设类型的行为动作后的待检测视频。
93.通过上面先检测典型特征,再在具备典型特征的那些视频段进行预设类型的行为动作的检测,就减少了很多不含有典型特征的视频段的检测,从而可以极大地提高检测的速度和效率。这种方式,对于实时视频获取同样适用,在没有典型特征出现时则无需进行预设类型的行为动作的检测,从而可以极大地节省计算成本,提高检测速度,能够达到实时检测的效果。
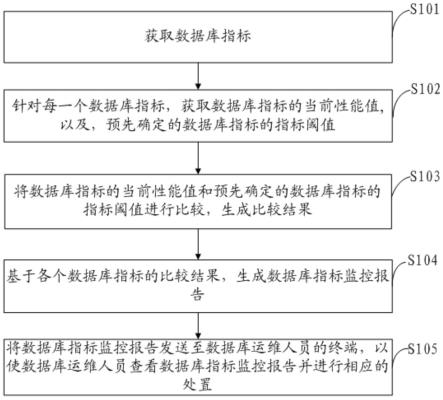
94.每一种典型特征检测模型构建步骤:将每一种典型特征的图像样本作为输入,将所述每一种典型特征的标签作为预期输出,对现有的特征检测深度学习模型进行训练和测试(迁移学习),得到所述每一种典型特征检测深度学习模型。所述每一种典型特征的图像
样本中用预设标志标记出了具有所述每一种典型特征的范围,例如典型特征为刀或枪或拳头,将图像中刀或枪或拳头用方框框上。所述每一种典型特征的标签包括所述每一种典型特征的名称(例如刀或枪或拳头)、所述每一种典型特征在图像中的标志的位置,例如方框的位置(4个顶点坐标)。若所述每一种典型特征的标签中所述每一种典型特征在图像中的标志的位置为空,则表明所述图像样本不包含所述每一种典型特征。
95.每一种预设类型的行为动作检测模型构建步骤:将每一种预设类型的行为动作的视频样本作为输入,将每一种预设类型的行为动作的标签作为预期输出,对现有的动作检测深度学习模型进行训练和测试(迁移学习),得到所述每一种预设类型的行为动作检测深度学习模型;
96.所述每一种预设类型的行为动作的视频样本中用预设标志标记出了所述每一种预设类型的行为动作且标记的范围需要涵盖所述每一种预设类型的行为动作,这里范围包括空间范围和时间范围,时间范围从所述每一种预设类型的行为动作的起始帧到结束帧,例如预设类型的行为动作为暴力的动作,将视频中预设类型的行为动作为暴力的动作从起始帧到结束帧中每一帧的预设类型的行为动作为暴力的动作用方框框上。所述每一种预设类型的行为动作的标签包括所述每一种预设类型的行为动作的名称(例如暴力的动作)、所述每一种预设类型的行为动作的起始帧、结束帧、在每一帧中的标志的位置,例如每一帧中方框的位置(4个顶点坐标)。若所述每一种预设类型的行为动作的标签中所述每一种预设类型的行为动作的起始帧、结束帧为空,则表明所述视频样本不包含所述每一种预设类型的行为动作。
97.对每一种典型特征和每一种预设类型的行为动作都训练一个深度学习模型,可以使得深度学习模型更有针对性也更精准,虽然在某种程度上提高了计算的成本,但可以通过有针对性的检测来反过来降低成本。
98.人物图像识别模型构建步骤:获取每一人物的照片,将所述每一人物的照片作为输入,将所述人物的信息(人物的信息例如人物的姓名或身份证号或学号)作为预期输出,对人脸图像识别深度学习模型进行迁移学习,得到人物图像识别深度学习模型。
99.人物视频识别模型构建步骤:获取每一人物的视频,将所述每一人物的视频作为输入,将所述人物的信息(人物的信息例如人物的姓名或身份证号或学号)作为预期输出,对人脸视频识别深度学习模型进行迁移学习,得到人物视频识别深度学习模型。
100.典型特征检测步骤:获取所述待检测视频中每一帧图像,将所述每一帧图像作为输入,通过典型特征检测深度学习模型的计算,得到的输出作为所述每一帧图像的典型特征的标签,若所述每一帧图像的典型特征的标签不为空(若为空,则表明所述每一帧图像不具备典型特征),则根据所述每一帧图像的典型特征的标签中的标记范围从所述每一帧图像中截取标记范围内的图像。将所述标记范围内的图像作为输入,通过人物识别图像深度学习模型的计算,得到的输出作为所述每一帧图像的典型特征的标签中人物的信息(人物的信息可以为空,因为有的动作中不一定有人物)。若所述每一帧图像的典型特征的标签不为空,则所述每一帧图像含有一个或多个典型特征。
101.待检测帧标记步骤:获取所述待检测视频中每一帧图像及所述每一帧图像的典型特征的标签。若所述每一帧图像的典型特征的标签不为空,则将根据所述典型特征的标签中典型特征的名称确定对应的预设类型的行为动作的预设最大时长,作为待检测预设时
长。若所述典型特征的标签有多个不为空,则根据所述典型特征的多个标签中多个典型特征的名称确定对应的多个预设类型的行为动作的多个预设最大时长,取多个预设最大时长中最大的多个预设最大时长,作为待检测预设时长。若所述每一帧图像的典型特征的标签不为空,则将所述每一帧图像标记为待检测帧,将所述每一帧图像前所述待检测预设时长/2的时长的所有帧标记为待检测帧,将所述每一帧图像后所述待检测预设时长/2的时长的所有帧标记为待检测帧。有些帧会被重复地标记为待检测帧,有些帧则不会被标记为待检测帧。
102.待检测视频片段截取步骤:将所述待检测视频中标记为待检测帧且未标记为已抽取的连续帧抽取出来作为一个待检测视频片段,将已抽取的待检测帧标记为已抽取。从待检测视频中能够抽取0个或1个或多个待检测视频片段。
103.待检测视频片段备选预设类型的行为动作确定步骤:获取每一个待检测视频片段,获取所述每一个待检测视频片段中所有帧图像的典型特征的不为空的标签中典型特征的名称,得到多个典型特征的名称,将所述多个典型特征的名称去重,得到各不相同的典型特征的名称集合,作为待检测典型特征集合。
104.确定待检测预设类型的行为动作步骤:获取待检测典型特征集合中每一典型特征的名称,根据视频行为知识图谱中典型特征实体和预设类型的行为动作实体之间的关系,得到所述每一典型特征的名称对应的一个或多个预设类型的行为动作的名称。将根据待检测典型特征集合中所有典型特征的名称得到的所有预设类型的行为动作的名称去重,得到各不相同的预设类型的行为动作的名称集合,作为待检测预设类型的行为动作集合。
105.特定预设类型的行为动作检测步骤:将所述每一个待检测视频片段作为输入,经过待检测预设类型的行为动作集合中每一个预设类型的行为动作对应的所述每一个预设类型的行为动作检测深度学习模型计算得到的输出作为所述待检测视频片段中所述每一种预设类型的行为动作的标签。将所述标记范围内的视频片段作为输入,通过人物视频识别深度学习模型的计算,得到的输出作为所述视频片段的每一种预设类型的行为动作的标签中人物的信息(人物的信息可以为空,因为动作中不一定有人物)。若所述每一帧图像的典型特征的标签不为空,则所述每一帧图像含有一个或多个典型特征。将所有所述待检测视频片段中每一种预设类型的行为动作的标签作为所述待检测视频中每一种预设类型的行为动作的标签。
106.通过这个方案就无需对视频片段检测所有类型的预设类型的行为动作,只需要检测典型特征对应的预设类型的行为动作,从而降低了预设类型的行为动作检测的计算量。
107.待检测视频标记步骤:将所述带有每一种预设类型的行为动作的标签的所述待检测视频片段替换所述待检测视频中对应的所述待检测视频片段,得到标记了预设类型的行为动作后的待检测视频。
108.通过上面先检测典型特征,再在具备典型特征的那些视频段进行预设类型的行为动作的检测,就减少了很多不含有典型特征的视频段的检测,从而可以极大地提高检测的速度和效率。这种方式,对于实时视频获取同样适用,在没有典型特征出现时则无需进行预设类型的行为动作的检测,从而可以极大地节省计算成本,提高检测速度,能够达到实时检测的效果。
109.人物典型特征画像步骤:获取所述待检测视频中每一帧图像中典型特征的不为空
的标签中的典型特征名称和人物的信息,在视频行为知识图谱的典型特征实体和人物实体之间建立关系。
110.人物预设类型的行为动作画像步骤:获取所述待检测视频中待检测视频片段中每一种预设类型的行为动作不为空的标签中的预设类型的行为动作名称和人物的信息,在视频行为知识图谱的预设类型的行为动作实体和人物实体之间建立关系。
111.具有预设类型的动作的人物确定步骤:获取视频行为知识图谱中每一人物,若所述每一人物与预设类型的行为动作实体在视频行为知识图谱中存在关系连接,则所述每一人物存在预设类型的行为。
112.预设类型的动作预警步骤:获取视频行为知识图谱中所述存在预设类型的行为的所述每一人物存在关系的监管部门,获取视频行为知识图谱中所述监管部门存在关系的视频行为监管人员,将所述每一人物存在预设类型的行为的信息发送给所述视频行为监管人员。
113.以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,则对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。