基于注意力和unet网络生成对抗网络的超分辨率方法
技术领域
1.本发明属于医学图像重构技术领域,尤其涉及基于注意力和unet网络生成对抗网络的超分辨率方法。
背景技术:
2.目前,在核医学领域中,正电子发射断层成像(positron emission tomography,pet)是一种先进的影像技术。pet成像的基础是该技术检测由正电子发射放射性核素(也称为放射性药物,放射性核素或放射性示踪剂)间接发射的γ射线对。将示踪剂注入生物活性分子的静脉中,通常是用于细胞能量的糖。pet系统灵敏的探测器捕获身体内部的伽马射线辐射,并使用软件绘制三角测量排放源,创建体内示踪剂浓度的三维计算机断层扫描图像。
3.由于医学图像在成像的过程中,医学设备在现实使用时,往往会受到各种条件的影响,比如成像设备的物理限制、放射素剂量的差异以及患者所能承受的放射素多寡等,导致获得的图像分辨率极其有限。但在临床使用,尤其是面对一些疑难杂症,高分辨率图像的需求越来越高。
4.在现有技术中,获得比较广泛使用的是2016年提出的srgan(super resolution generative adversarial network,超分辨率生成对抗网络),这种技术取得了不错了的成果。但在现有成果及其改进的技术的工作,主要集中在模拟一个更复杂和更现实的退化过程或构建一个更好的生成器。然而,判别器的重要性不能被忽视,因为它为生成器提供了生成更好的图像的方向,因此srgan在提升图像分辨率上仍具有上升空间。
5.经检索,中国专利申请号:202110375243.3,申请日为:2021.04.07,主题名称为:基于生成对抗网络的图像增强系统和图像增强方法,该申请的系统包括原始图像采集模组及对抗网络模型。所述对抗网络模型包括图像合成模组、图像判别模组及多损失函数。所述图像合成模组输出合成图像,所述图像判别模组输出增强图像,所述多损失函数根据所述图像判别模组的输出结果感知图像损失,并调整所述图像合成模组输出的合成图像,改善增强效果,所述损失函数包括对抗损失函数、循环一致性损失函数、感知损失函数和总损失函数。但该申请更主要应用于自然图像的增强。医学图像有着噪声大,关键信息占比小的特点,不同的图像处理方式可能会造成较大的影响。该申请在上述图像合成模组,图像判别模组及多损失函数中与本发明均存在较大差别,因此对医学图像增强的效果不明显。
技术实现要素:
6.1.发明要解决的技术问题鉴于现有的技术在图像识别时,获得的图像分辨率有限,本发明提供了基于注意力和unet网络生成对抗网络的超分辨率方法,通过引入注意力机制与unet网络,提高脑pet图像的分辨率。
7.2.技术方案为达到上述目的,本发明提供的技术方案为:
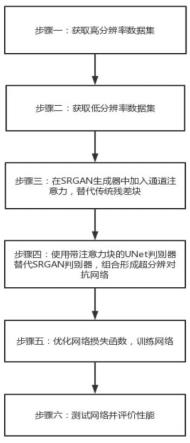
本发明的基于注意力和unet网络生成对抗网络的超分辨率方法,包括以下步骤:步骤一、获取脑pet高分辨率图像数据集,获得高分辨率图像训练集和测试集;步骤二、分别对步骤一获得的高分辨率图像训练集和测试集进行下采样,获得低分辨率图片训练集与测试集;步骤三、构建带有通道注意力块和unet判别器的基于注意力和unet网络的超分辨率生成对抗网络;步骤四、对高分辨率图像训练集和低分辨率图片训练集进行归一化,并使用二进制交差熵损失来计算判别器的总损失,使用高分辨率图像训练集和低分辨率图片训练集对网络进行训练;步骤五、利用步骤一和步骤二获得的高分辨率图像测试集和低分辨率图片测试集对基于注意力和unet网络的超分辨率生成对抗网络进行测试,对网络的性能进行评估。
8.3.有益效果采用本发明提供的技术方案,与已有的公知技术相比,具有如下显著效果:(1)本发明的基于注意力和unet网络生成对抗网络的超分辨率方法,在传统srgan的基础上,通过为超分辨对抗网络生成器引入通道注意力机制,使得生成器可以生成更详细的特征,能够获取更高分辨率的图像。
9.(2)本发明的基于注意力和unet网络生成对抗网络的超分辨率方法,通过使用带有注意力机制的unet网络改进判别器,加强了边缘部分,能够更精确的识别图像特征,以此帮助医生获得更好的诊断结果。
10.(3)本发明的基于注意力和unet网络生成对抗网络的超分辨率方法,通过对损失函数进行改进,能够在保证输出图像具有高分辨率的同时,有效地提高该对抗网络的运行效率。
附图说明
11.图1(a)为本发明中au-srgan的总体网络结构框图,其中g表示生成器,d表示判别器;图1(b)为本发明中au-srgan生成器的总体结构框图;图1(c)为本发明中cab的通道结构的结构框图;图1(d)为本发明中au-srgan判别器的总体结构框图;图1(e)为本发明中ab的结构框图;图1(f)为本发明中cb的结构框图;图2(a)为进行测试的输入的低分辨率图;图2(b)为基于最近邻插值法(nearest)得到的结果图;图2(c)为双三次插值法(bicubic)得到的结果图;图2(d)为使用srgan得到的结果图;图2(e)为使用au-srgan得到的结果图;图3为本发明au-srgan的步骤流程框图。
具体实施方式
12.为进一步了解本发明的内容,结合附图和实施例对本发明作详细描述。
13.实施例结合图3,本实施例的基于注意力和unet网络生成对抗网络的超分辨率方法,在srgan网络的基础上,改进判别器网络,进一步提升了网络的超分辨能力与图片质量和边缘效果。
14.如图1(a)-图1(f)所示,本实施例的基于注意力和unet网络生成对抗网络的超分辨率方法,包括如下步骤:步骤一、获取脑pet高分辨率图像数据集,并将此数据集按照7:3的比例分配为高分辨率图像训练集与高分辨率图像测试集。比例可根据需求进行调整。其中训练集图片包含3000张,测试集图片包含100张。采用随机裁剪的方法,将训练集图像随机裁剪像素值为88
×
88大小。
15.步骤二、使用bicubic函数对步骤一中的训练集和测试集双三次下采样,得到低分辨率的图片训练集与测试集,并使用随机裁剪方法,将其裁剪为像素值为88
×
88的大小。
16.步骤三、构建带有通道注意力块和unet判别器的基于注意力和unet网络的超分辨率生成对抗网络:1、在srgan生成器中引入通道注意力机制,使用通道注意力块代替传统的残差块:如图1(a)所示,所述au-srgan(attention and unet super resolution generative adversarial network,基于注意力和unet网络的超分辨率生成对抗网络)包括生成器、判别器两个模块。
17.如图1(b)所示,所述au-srgan的生成器组成的顺序依次为:第一层是一个拥有64个卷积核的卷积层,该卷积核的是9
×
9大小,步长为1;第二层为prelu激活层;第三层为5个结构相同的cab块;第四层为一个含64个卷积核大小为3
×
3,步长为1的卷积层;第五层是一层批归一化层(batch normalization,bn层);第六层为一个跳跃连接层;第七层是两个上采样层和一个卷积层,该卷积层由1个大小为9
×
9,步长为1的卷积核组成。其中,cab块的结构依次为:第一层为一个含64个大小为3
×
3,步长为1的卷积核的卷积层;第二层是bn层;第三层是prelu激活层;第四层结构与第一层相同;在第五层加入通道注意力层;第六层一个bn层;最后一层是一个按元素求和的跳跃连接层。所述通道注意力层的结构为:第一层为全局平均池化层;第二层为包含4个大小为1
×
1,长度为1的卷积核的卷积层;第三层为一个prelu激活层;第四层为包含64个大小为1
×
1,长度为1的卷积核的卷积层;第五层为一个sigmoid激活层;最后一层为一个按元素求积的跳跃连接层。
18.其中,上采样层的结构为:一个含256个步长为1,大小为3
×
3卷积核的卷积层,其次是2倍上采样的亚像素层,最后是prelu激活层,依次串联。
19.2、在上述超分辨率生成对抗网络的判别器中,使用带有注意力块的unet判别器替代传统判别器,与上述生成器共同组成联合分类的超分辨率生成对抗网络:如图1(d)所示,所述au-srgan的判别器aud结构依次为:横向第一层为频谱归一层与一个包含64个步长为1,大小为3
×
3卷积核的卷积层组合的卷积块,并且将输出数据复制后分别传递到纵向同层的注意力块(attention block,ab)与横向下一层的卷积块;第二层和第三层的结构与输出与第一层相同;横向第四层为卷积块并将输出结果传递到下一层卷
积块与纵向第三层连接块(concatenate block,cb);横向第五层将数据以门信号分别传输到三个ab块;横向第六与第七层由一个输入数据流,一个频谱归一层与一个输出数据流组成;最后一层由三个卷积块组合而成。
20.所述注意力块ab的结构为:第一层为门控信号和unet输入信息的异或层;第二层relu层;第三层为sigmoid函数层;第四层为重采集层(resample);最后一层为第四层结果与unet结果的与或。
21.所述连接块cb的结构为:第一层为将unet输入的数据通过两次双线过滤上采样(bilinear interpolation);第二层为一层频谱归一层;第三层将从ab得到的输入数据与第二层后得到的数据进行集中(concentration)操作。
22.步骤四、使用sigmoid函数对训练集进行归一化,并使用二进制交差熵损失来计算判别器的总损失,对网络进行训练,其中,au-srgan的损失为像素损失、内容损失、对抗损失。au-srgan的损失l
sr
表示为:l
sr
=lg ld(1)lg表示生成器的损失函数,ld是判别的判别损失,au-srgan的生成器损失lg为:lg=l
mse
γl
vgg
δl
gen
(2)其中,γ,δ为超参数,l
mse
是像素损失,l
vgg
为网络内容损失,l
gen
是对抗网络的对抗损失。本网络的像素损失l
mse
使用的是像素级的标准均方误差(mean square error,mse),其表示为:(3)其中,r为下采样因子,w、h分别代表了图像的宽和高,i
lr
、i
hr
分别表示低分辨pet图像和高分辨pet图,g
θg
(i
lr
)表示生成器生成的超分辨率图,其中的下标x,y表示一个具体的像素点。
23.使用vgg19网络中第i个最大池化层之前的第j个卷积层操作所得到损失用l
vgg
表示,其可以表示为:(4)其中,w
i,j
、h
i,j
表示的是vgg19网络中所有特征图的大小,
ø
i,j
表示的是vgg19网络第i个最大池化层之前的第j个卷积层操作。根据判别器的概率定义对抗损失l
gen
为:(5)其中,上述生成器生成的图像被判别器判断为真实图像的概率值用d
θg
(g
θg
(i
lr
))表示。
24.采用带有注意力机制的unet作为au-srgan判别器的判别损失ld,unet判别器的输
出是一个w
×
h矩阵,每个元素表示它所表示的像素为真的可能性。为了计算一个鉴别器的总损失,使用sigmoid函数对输出进行归一化,并使用二进制交叉熵损失来计算损失。假设c是输出矩阵,定义d=σ(c),xr为真实数据, xf为假数据。其表示为:(6)步骤五、用步骤一获得的高分辨率图像训练集和步骤二得到的低分辨率图像训练集训练网络。参数设置如下:batchsize为16,迭代次数为200,损失函数的系数γ,δ分别为6
×
10-3
, 1
×
10-3
,用于优化损失的优化器采用adam,学习率设置为1
×
10-3
。
25.步骤六、用步骤一中的高分辨率图像测试集和步骤二中的低分辨率图像测试集对训练获得的au-srgan模型进行测试与验证,为了对该模型的有效性进行更好的评估,采用常用的图像质量评价指标psnr与ssim对结果进行验证,并且将au-srgan分别与双三次插值法(bicubic)、基于最近邻插值法(nearest)、srgan方法进行对比,实验结果如下:表1 图像质量评价指标值从表中可以看出,au-srgan模型在psnr和ssim上都优于其他方法。
26.对图2(a)使用不同方法得到的超分辨率结果见图2(b)至图2(e),可以看到,基于nearest和bicubic方法得到的超分辨图较为模糊,使用srgan方法得到的超分辨图片在画质上得到了提高,但在图像边缘部分不够清晰。而使用了au-srgan后,图片在边缘部分的效果得到了提高,纹理也更加清晰,证明了此方法在改善脑pet图像质量上的有效性。
27.以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
