1.本发明涉及油气田开发领域,特别涉及一种高倾角油藏开发方式选择方法。
背景技术:
2.随着高倾角厚层岩性砂岩油藏不断被勘探发现,高倾角油藏有着巨大的地质储量,实现该类油藏高效开发对于保障国家能源安全具有重要意义。相对于低倾角层状油藏,高倾角厚层砂岩油藏纵向发育多套含油层系、层间物性及压力系数差异大;油藏倾角普遍较高(大于10
°
),重力对原油流动的影响作用显著,油藏不同部署部位(底部、腰部、顶部)生产井产能差异大;底部天然水体能量对腰部和高部位油井补充有限,导致该类油藏地层压力保持水平低,且不同部位不平衡,如远离边水的高部位油井区脱气严重,导致开发效果变差。尚未形成高倾角厚层砂岩油藏合理开发层系、最优井型井网系统、合理开发方式及能量补充时机、注入介质及合理注采比,并且高倾角油藏没有成熟的开发模式可供借鉴。选择天然能量开发方式可以减少油藏开发成本,但是长时间开采会导致地层压力衰竭使开发效果变差。而注水注气开发虽然能补充油藏能量,但是水窜气窜后同样对开发效果有较大影响,个别油藏不适合注水注气开发导致开发改善效果不佳,但是成本投入较大,因此快速的选择适合的开发方式对于高倾角油藏开发至关重要。
3.专利号为cn201810714510.3的中国专利“高倾角油藏优化调整方法”,提出了一种结合地质综合研究、油藏工程研究、先导实验结果,应用数值模拟结果确定剩余油分布密集区,在剩余油密集区布置调整井网。该专利没有涉及到油藏开发技术政策决策方法的问题。
4.专利号为cn201610355499.7的中国专利“一种采用平面重力驱开采高倾角稠油油藏的方法”,提出了一种以注入蒸汽为主、注入非凝析气体为辅的驱动方式,注入介质由于密度差形成空间分异明显的“次生气顶”和“次生水带”,从而阻挡注入气向低构造部位生产井的突破。该专利没有提及到高倾角油藏开发方式的决策方法。
5.专利号为cn201611158240.x的中国专利“高倾角稠油油藏火驱与烟道气回注重力驱协同开采方法”,提出了从火驱注气井注入空气,将燃烧的烟道气由火驱生产井采出,将烟道气分离过滤后,回注到烟道气注气井中,为顶部注气提供气源。该专利没有提到高倾角油藏开发方式决策的方法。
技术实现要素:
6.针对现有技术存在的上述问题,本发明要解决的技术问题是:如何快速决策解决高倾角油藏的开发方式。
7.为解决上述技术问题,本发明采用如下技术方案:
8.一种高倾角油藏开发方式选择方法,包括如下步骤:
9.s01:选用国内外油藏公开数据集,公开数据集包括高倾角油藏静态参数,取得高倾角油藏静态参数的方式包括天然能量开发方式、底部注水开发方式和底部注水 顶部注气开发方式,选取i个高倾角油藏静态参数作为主要油藏参数,每个主要油藏参数包含j个
取值水平;
10.s02:将i个主要油藏参数及其j个水平进行正交实验,得到共计得到m组概念数据模型,每组概念数据模型对应一次正交实验;
11.将m组概念数据模型作为地质建模软件的输入,建立与m组概念数据模型一一对应的m组高倾角油藏概念模型;
12.s03:针对天然能量开发方式、底部注水开发方式和底部注水 顶部注气开发方式三种开发方式分别应用数值模拟软件对m组高倾角油藏概念模型进行目标参数计算依次得到样品数据数量集m1,样品数据数量集m2和样品数据数量集m3;
13.所述m1,m2和m3构成概念模型库,且m1=m2=m3;
14.所述m1,m2或m3中的第m个样品数据包括第m组高倾角油藏概念模型及相对应的目标参数实际值;
15.s031:将所述m1,m2和m3中的每个样品数据对应的所有取值水平进行归一化处理后对应的得到m
′1,m
′2和m
′3,进行归一化处理的表达式如下:
[0016][0017]
其中,x
m,i
表示第m个样品数据中第i个主要油藏参数的第j个水平,x'
m,i
表示归一化后的数据,其中i=1,2,
…
i,j=1,2,
…
j,m=1,2,
…
,m;
[0018]
s04:构建基于神经网络的预测代理模型ann,并对该ann进行初始化;
[0019]
s041:分别从m
′1,m
′2和m
′3中选取相同比例的样品数据合并作为初始训练集train0,m
′1,m
′2和m
′3剩余的样品数据合并作为初始测试集test0,其中,train0中的一个样品数据作为一个训练样品,test0中的一个样品数据作为一个测试样品;
[0020]
s042:使用k折交叉验证法对train0进行处理,将train0分为k折数据;
[0021]
s043:预设迭代次数,每折数据对应一个ann,共计有k个ann;
[0022]
s044:选取第s个ann及其对应的第s折数据,将除第s折数据以外的其他k-1折数据作为第s个ann的输入,对第s个ann进行训练,当训练达到预设迭代次数时得到训练好的第s个ann;
[0023]
s045:将第s折数据作为训练好的第s个ann的输入,输出为第s折数据的预测数据集;
[0024]
s046:重复s044和s045,对k个ann进行训练,得到训练好的k个ann,同时也得到k个预测数据集,将k个预测数据集进行上下堆叠处理得到新的k折数据,并将新的k折数据中每个训练样品的预测值和对应的实际值进行组合,得到新的训练集a1;
[0025]
s047:将s041所述test0分别作为训练好的k个ann的输入,得到k个预测数据集,其中每个ann的输出作为一个预测数据集,该预测数据集中的每个预测值与初始测试集中的每个测试样品数据一一对应;
[0026]
s048:对test0中的每个测试样品对应的k个预测数据求算术平均值,得到一个平均预测数据集,将每个测试样品的平均预测值与对应的实际值进行组合,作为新的测试集b1;
[0027]
s05:构建基于回归决策树的预测代理模型rt,并对该rt进行初始化;
[0028]
使用s041-s046所述方法,创建新的训练集a2,使用s047所述方法,创建新的测试
集b2;
[0029]
s06:基于机器学习算法构建高倾角油藏开发方式预测模型w;
[0030]
s061:预设训练迭代次数,初始化w并对w进行训练:
[0031]
s062:将a1和a2合并作为w的训练集将b1和b2合并作为w的测试集
[0032]
s063:将作为w的输入计算目标参数预测值,并采用反向传播更新w的参数,当达到预设训练迭代次数时停止训练,得到当前高倾角油藏开发方式预测模型w’;
[0033]
s064:令t=1;
[0034]
s065:从中选择第t个测试样品数据,将第t个测试样品数据输入到w’中,得到第t个测试样品数据的目标参数预测值;
[0035]
s066:计算第t个测试样品数据的目标参数预测值和第t个测试样品数据的目标参数实际值之间的相关评价系数r,且定义r为预测准确率;
[0036]
s067:如果r≥85%,则得到训练好的高倾角油藏开发方式预测模型,并执行下一步;否则令s064中的t=t 1,并返回s065;
[0037]
s07:利用训练好的高倾角油藏开发方式预测模型计算待预测高倾角油藏的目标参数预测值,所述目标参数为油藏采收率和地层压力水平,具体步骤如下:
[0038]
s071:将待预测高倾角油藏的主要参数分别使用天然能量开发方式标记、底部注水开发方式标记和底部注水 顶部注气开发方式标记,得到三组数据;
[0039]
s072:将所述三组数据分别输入到训练好的高倾角油藏开发方式预测模型中,得到三种开发方式下待预测高倾角油藏的油藏采收率预测值和地层压力水平预测值;
[0040]
s08:分别计算待预测油藏在三种开发方式下的经济采收率er,er的计算表达式如下:
[0041][0042]
其中:er为经济采收率;f为含油面积;b为平均单井总投资;s为极限井网密度;n为地质储量;p为原油价格;r为税率;c为吨油操作成本;
[0043]
s09:通过对三种开发方式相对应的经济采收率、油藏采收率预测值和地层压力水平预测值的比较,得到对待预测高倾角油藏的开发方式推荐结果,具体步骤如下:
[0044]
s091:针对天然能量开发方式,当天然能量开发方式的油藏采收率预测值大于等于对应的经济采收率时,则予以保留;否则,排除该开发方式;
[0045]
针对底部注水开发方式,当底部注水开发方式的油藏采收率预测值大于等于对应的经济采收率且地层压力水平预测值大于等于50%时,则予以保留;否则,排除该开发方式;
[0046]
针对底部注水 顶部注气开发方式,当底部注水 顶部注气开发方式的油藏采收率预测值大于等于对应的经济采收率且地层压力水平预测值大于等于50%时,则予以保留;否则,排除该开发方式;
[0047]
其中,如果三种开发方式都被排除时,则表示该油藏不适合开发;
[0048]
如果保留下来的开发方式为两种或三种,则选取最大油藏采收率预测值所对应的开发方式作为推荐结果。
[0049]
作为优选,所述s02中地质建模软件使用的是petrel地质建模软件。
[0050]
petrel是唯一的一个完全整合到完整的油藏描述系统中的油藏精细描述、建模工具。拥有三维可视化平台,可直观观察油藏变化,应用petrel可以简单快速建立高倾角油藏概念模型;petrel建立的油藏地质模型更好地考虑了为油藏数值模拟服务。在建立油藏地质模型的过程中,petrel就充分考虑了网格的空间形态、网格结构特征对数值模拟计算速度的影响,建立的地质模型直接应田于油藏数值模拟中具有最好的计算性能。
[0051]
作为优选,所述s03中数值模拟软件使用的是eclipse数值模拟软件。
[0052]
联合油藏数值模拟软件eclipse的研发,可以更好的配合petrel进行模型模拟,而且eclipse对于黑油模型处理能力强大、技术比较成熟。
[0053]
作为优选,所述s03中的目标参数包括油藏采收率和地层压力水平。
[0054]
油藏采收率的高低反应了一个油藏开发的水平,油藏采收率增加相对应该油藏采出原油数量增加,是油田开发主要的指标;原油开采主要依靠油藏能量,地层压力水平反映了油藏的能量大小,较高地层压力水平的油藏较容易开采并且投入的成本越小,若地层能量不足则需要补充能量,这会大大增加油藏开采成本,因此油藏能量大小也是油田开发的重要指标;因此这两个指标可以非常直观便捷的反映出高倾角油藏的状态。
[0055]
作为优选,所述s06中基于机器学习算法构建高倾角油藏开发方式预测模型m所使用的基线模型为lr线性回归模型。
[0056]
选择机器学习算法模型是为了避免过拟合现象,因此需要选择简单的模型,所以预测模型选择了lr线性回归模型作为基线模型。
[0057]
作为优选,所述s066中r的计算表达式如下:
[0058][0059]
其中,h表示使用测试样品得到的预测结果总数,z表示h中的第z个结果,pz为目标参数实际值,qz为目标参数预测值。
[0060]
相对于现有技术,本发明至少具有如下优点:
[0061]
1.本发明公开了一种高倾角油藏开发方式选择方法。通过建立多组考虑了油藏静态参数的概念模型及数值模拟结果,构建了以地层倾角、厚度、孔隙度、渗透率、水体倍数等静态参数和开发方式为自变量、以采收率、原始地层压力保持水平为因变量的概念模型库,然后应用机器学习中的神经网络算法和决策树算法,以构建的概念模型库作为训练集和预测集对构建的代理模型进行训练,再应用堆叠stacking将神经网络和决策树两种弱学习器集成,得到拟合精度更高的代理模型。基于该训练好的模型可以将其他类似高倾角油藏的静态参数和开发方式作为输入变量,即可对油藏不同开发方式的采收率及原始地层压力保持水平进行快速预测,对不同开发方式的开发效果进行比较,可以指导油田开发方式的进行。
[0062]
2.本发明利用神经网络与决策树回归进行集成,以概念模型样本进行训练,构建一个预测精度高的高倾角油藏采收率和压力水平预测模型,从而实现油藏采收率和压力水平的快速预测。
[0063]
3.本发明所公布的方法解决了高倾角油藏数值模拟难度大、耗时长的不足,可以有效指导待投产区开发方式优选、快速预测采收率水平,具有广阔的工程实际应用价值。
附图说明
[0064]
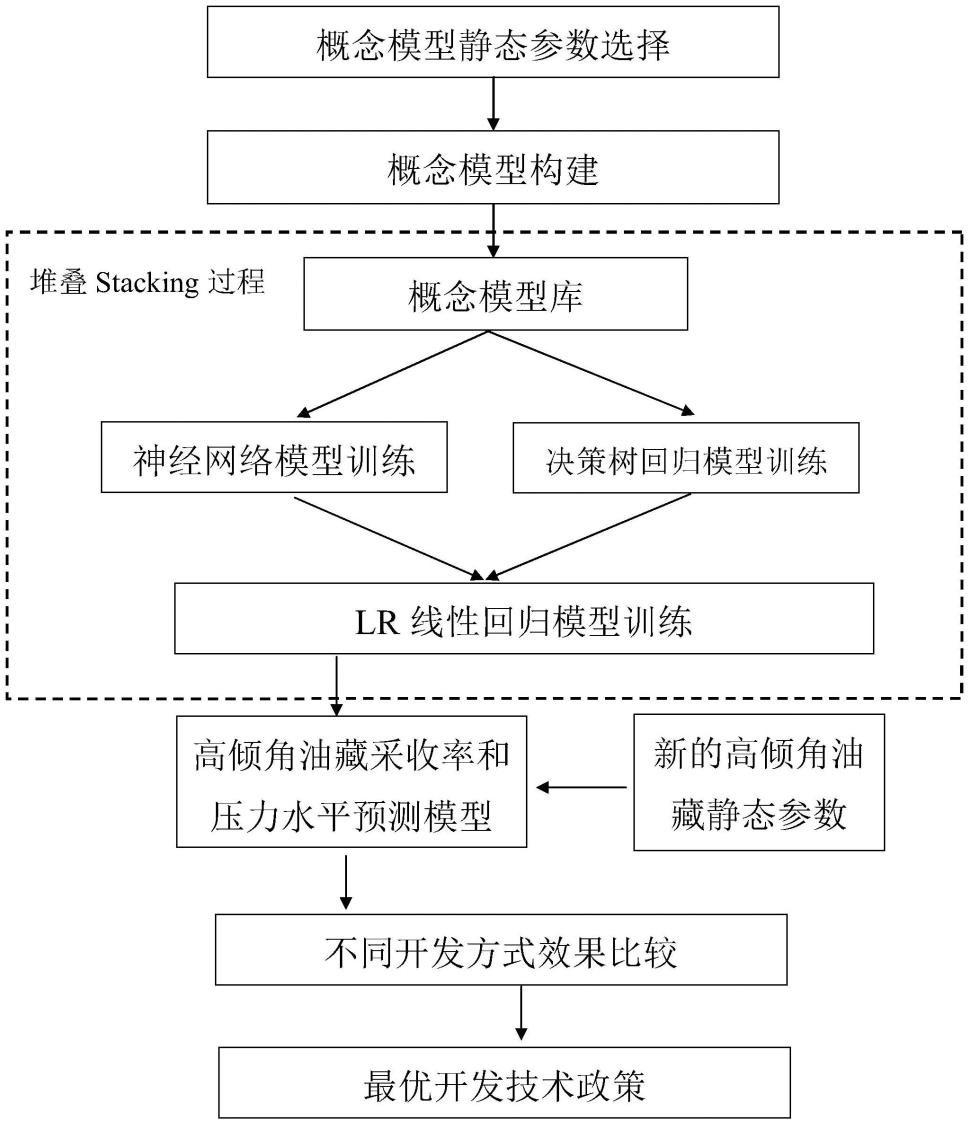
图1为高倾角油藏开发方式选择方法流程图。
[0065]
图2a为不同开采方式概念模型示意图:天然能量开采方式。
[0066]
图2b为不同开采方式概念模型示意图:底部注水开采方式。
[0067]
图2c为不同开采方式概念模型示意图:底部注水 顶部注气开采方式。
[0068]
图3为神经网络概述图。
[0069]
图4为stacking堆叠算法框架图。
具体实施方式
[0070]
下面对本发明作进一步详细说明。
[0071]
神将网络能够以任意精度逼近任何非线性连续函数,特别适合于求解内部机制复杂的问题。高倾角油藏中地层倾角、厚度、孔隙度、渗透率等静态参数及开发方式都会不同程度影响油藏的开发效果,因此可以应用神经网络对不同高倾角油藏的不同开发方式的效果进行预测。但是单一的个体学习器的预测精度较低,而且有预测准确率极限,无论样本数量多大,精度都无法提高,因此将不同的弱学习器集成为强学习器可以得到预测精度高且稳定的预测模型。堆叠stacking可以将异质弱学习器集成,并行地学习它们,并通过训练一个第二层模型将它们组合起来,根据不同弱模型的预测结果输出一个最终的预测结果,从而得到一个精度高的预测模型,进一步进行开发方式的决策。常规的数值模拟方法完成开发方式决策需要收集大量数据资料,费时费力,相比于数值模拟方法,此发明方法可以快速得到最优的开发技术政策。
[0072]
实施例1:参见图1-图4,一种高倾角油藏开发方式选择方法,包括如下步骤:
[0073]
本发明提供的高倾角油藏开发方式选择方法,为进一步说明该技术方法的有效性,以某高倾角油藏为例,对本发明实施方式做进一步详细说明,由图1可知,本发明的具体步骤如下:
[0074]
s01:选用国内外油藏公开数据集,公开数据集包括高倾角油藏静态参数,取得高倾角油藏静态参数的方式包括天然能量开发方式、底部注水开发方式和底部注水 顶部注气开发方式,选取i个高倾角油藏静态参数作为主要油藏参数,每个主要油藏参数包含j个取值水平具体实施时,可以根据预测目标从所有高倾角油藏静态参数中选择参数,所述高倾角油藏静态参数中的主要参数包括地层倾角、地层厚度、渗透率、孔隙度和水体倍数;
[0075]
具体实施时,依据实施例油藏参数,确定本发明概念模型的主要油藏参数及其取值水平,地层倾角分别为10
°
、15
°
、20
°
、25
°
、30
°
,地层厚度分别为20、60、100、140、180,孔隙度分别为20%、25%、30%、35%、40%,渗透率分别为300md、600md、900md、1200md、1500md,水体倍数分别为1、5、10、25、50。
[0076]
s02:将i个主要油藏参数及其j个水平进行正交实验,得到共计得到m组概念数据模型,每组概念数据模型对应一次正交实验,正交实验方法为现有技术;
[0077]
将m组概念数据模型作为地质建模软件的输入,建立与m组概念数据模型一一对应
的m组高倾角油藏概念模型,所述地质建模软件为现有技术;
[0078]
每个高倾角油藏概念模型大小均为a
×
b,所述a和b分别表示每个模型所代表油田的长和宽,每个油田包含有c排井,每排井含有d口生产井,且生产井之间的井距为e;在天然能量开发方式下每口生产井的单井产量为lp;在底部注水开发方式下,底部一排生产井转换为注水井,生产井的单井产量为lp,保持1.1的注采比,所述注采比为注水量与采油量的比值,注水井的单井注入量为lw;在底部注水 顶部注气开发方式下,底部一排生产井转换为注水井,顶部一排生产井转换为注气井,生产井的单井产量为lp,保持1.1的注采比,注水井的单井注入量为lw,注气井的单井注入量为lq;
[0079]
所述s02中地质建模软件使用的是petrel地质建模软件。
[0080]
具体实施时,应用正交实验方法,建立5参数5水平不同参数组合,共25组概念数据模型;应用petrel地质建模软件建立高倾角油藏概念模型。概念模型大小均为1200
×
1200m有3排井排,每排3口井,井距为400。在天然能量开发方式下每口井的单井产量为100m3/d。在底部注水开发方式下,底部三口生产井转换为三口注水井,生产井的单井产量为100m3/d,保持1.1的注采比,注水井的单井注入量为220m3/d。在底部注水 顶部注气开发方式下,底部三口生产井转换为三口注水井,顶部三口生产井转换为三口注气井,生产井的单井产量为100m3/d,保持1.1的注采比,注水井的单井注入量为55m3/d,注气井的单井注入量为6050m3/d。
[0081]
s03:针对天然能量开发方式、底部注水开发方式和底部注水 顶部注气开发方式三种开发方式分别应用数值模拟软件对m组高倾角油藏概念模型进行目标参数计算依次得到样品数据数量集m1,样品数据数量集m2和样品数据数量集m3,得到样品数据数集m1,样品数据数量集m2和样品数据数量集m3的过程属于现有技术;
[0082]
所述m1,m2和m3构成概念模型库,且m1=m2=m3;
[0083]
所述m1,m2或m3中的第m个样品数据包括第m组高倾角油藏概念模型及相对应的目标参数实际值;具体的,选用天然能量开发方式得到的样品数据数量m1、选用底部注水开发方式得到的样品数据数量m2和选用底部注水 顶部注气开发方式得到的样品数据数量m3,三种不同的开发方式是通过设置不同开采条件进行区分的,它们会体现出不同的采集结果,天然能量开发方式终止条件为生产井单井产量低于lp
min
;底部注水方式为先天然能量开采,当达到终止条件后底部开始转注水,结束条件为油藏含水率达到fw
max
;顶部注气 底部注水开发方式为先天然能量开采,再底部注水开发,当达到底部注水终止条件后顶部开始注气,结束条件为生产井气油比达到g
max
;
[0084]
s031:将所述m1,m2和m3中的每个样品数据对应的所有取值水平进行归一化处理后对应的得到m
′1,m
′2和m
′3,进行归一化处理所采用的是最大最小标准化方法,最大最小标准化方法为现有技术,进行归一化处理的表达式如下:
[0085][0086]
其中,x
m,i
表示第m个样品数据中第i个主要油藏参数的第j个水平,x'
m,i
表示归一化后的数据,其中i=1,2,
…
i,j=1,2,
…
j,m=1,2,
…
,m;
[0087]
所述s03中数值模拟软件使用的是eclipse数值模拟软件,所述s03中的目标参数包括油藏采收率和地层压力水平。
[0088]
具体实施时,应用eclipse数值模拟软件,针对上述概念模型,研究天然能量开发、底部注水、顶部注气 底部注水开发方式下预测期末(天然能量开发方式终止条件为生产井单井产量低于50m3/d;底部注水方式为先天然能量开采,当达到终止条件后底部开始转注水,结束条件为油藏含水率达到60%;顶部注气 底部注水开发方式为先天然能量开采,再底部注水开发,当达到底部注水终止条件后顶部开始注气,结束条件为生产井气油比达到500m3/m3)油藏采收率及压力保持水平。通过数值模拟得到不同组合下的油藏采收率及地层压力水平,将其作为概念模型库。将以上得到的概念模型库采用最大最小标准化进行归一化。
[0089]
s04:构建基于神经网络的预测代理模型ann,并对该ann进行初始化,神经网络是现有技术,该模型可以计算出概念模型库中的每个样品的目标参数,神经网络所构建预测模型拟合程度比较高,利用神将网络可以找出油藏静态参数和开发技术政策与目标参数之间的响应关系;
[0090]
s041:分别从m
′1,m
′2和m
′3中选取相同比例的样品数据合并作为初始训练集train0,m
′1,m
′2和m
′3剩余的样品数据合并作为初始测试集test0,其中,train0中的一个样品数据作为一个训练样品,test0中的一个样品数据作为一个测试样品;
[0091]
s042:使用k折交叉验证法对train0进行处理,k折交叉验证法为现有技术,主要是为了减少直接训练导致的过拟合风险,将train0分为k折数据;
[0092]
s043:预设迭代次数,每折数据对应一个ann,共计有k个ann;
[0093]
s044:选取第s个ann及其对应的第s折数据,将除第s折数据以外的其他k-1折数据作为第s个ann的输入,对第s个ann进行训练,当训练达到预设迭代次数时得到训练好的第s个ann;神经网络的训练过程为现有技术;
[0094]
s045:将第s折数据作为训练好的第s个ann的输入,输出为第s折数据的预测数据集;
[0095]
s046:重复s044和s045,对k个ann进行训练,得到训练好的k个ann,同时也得到k个预测数据集,将k个预测数据集进行上下堆叠处理得到新的k折数据,并将新的k折数据中每个训练样品的预测值和对应的实际值进行组合,得到新的训练集a1,所述堆叠方式如图4所示;
[0096]
s047:将s041所述test0分别作为训练好的k个ann的输入,得到k个预测数据集,其中每个ann的输出作为一个预测数据集,该预测数据集中的每个预测值与初始测试集中的每个测试样品数据一一对应;
[0097]
s048:对test0中的每个测试样品对应的k个预测数据求算术平均值,得到一个平均预测数据集,将每个测试样品的平均预测值与对应的实际值进行组合,作为新的测试集b1;
[0098]
具体实施时,将归一化后的概念模型库导入matlab并建立神经网络模型ann。使用概念模型库80%的样品作为训练集共20组,概念模型库20%的样品作为测试集共5组,将训练集分为4折,其中3折作为训练数据,另外一折作为预测数据,将得到的4折预测数据上下进行堆叠,从而得到第二层模型新的训练集a1;
[0099]
建立起拟合程度高的利用神将网络找出油藏静态参数和开发技术政策与采收率和地层压力水平之间的响应关系,利用建立起的神经网络预测模型对测试集进行预测,并
将4组测试集预测值取算数平均,作为第二层模型测试集b1。
[0100]
s05:构建基于回归决策树的预测代理模型rt,并对该rt进行初始化,回归决策树是现有技术,该模型可以计算出概念模型库中的每个样品的目标参数预测值;使用s041-s046所述方法,创建新的训练集a2,使用s047所述方法,创建新的测试集b2;
[0101]
具体实施时,将归一化后的概念模型库导入并建立回归决策树模型。同样使用概念模型库80%的样品作为训练集共20组,概念模型库20%的样品作为测试集共5组。将训练集分为4折,其中3折作为训练数据,另外一折作为预测数据,将得到的4折预测数据上下进行堆叠,从而得到第二层模型新的训练集a2。建立起利用决策树回归模型找出油藏静态参数和开发技术政策与采收率和地层压力水平之间的响应关系,利用建立起的决策树回归模型对测试集进行预测,并将4组测试集预测值取算数平均,作为第二层模型测试集b2。
[0102]
s06:基于机器学习算法构建高倾角油藏开发方式预测模型w,机器学习算法为现有技术;
[0103]
所述s06中基于机器学习算法构建高倾角油藏开发方式预测模型m所使用的基线模型为lr线性回归模型。
[0104]
s061:预设训练迭代次数,初始化w并对w进行训练:
[0105]
s062:将a1和a2合并作为w的训练集将b1和b2合并作为w的测试集
[0106]
s063:将作为w的输入计算目标参数预测值,并采用反向传播更新w的参数,当达到预设训练迭代次数时停止训练,得到当前高倾角油藏开发方式预测模型w’;
[0107]
s064:令t=1;
[0108]
s065:从中选择第t个测试样品数据,将第t个测试样品数据输入到w’中,得到第t个测试样品数据的目标参数预测值;
[0109]
s066:计算第t个测试样品数据的目标参数预测值和第t个测试样品数据的目标参数实际值之间的相关评价系数r,且定义r为预测准确率;
[0110]
所述s066中r的计算表达式如下:
[0111][0112]
其中,h表示使用测试样品得到的预测结果总数,z表示h中的第z个结果,pz为目标参数实际值,qz为目标参数预测值。
[0113]
s067:如果r≥85%,则得到训练好的高倾角油藏开发方式预测模型,并执行下一步;否则令s064中的t=t 1,并返回s065;
[0114]
s07:利用训练好的高倾角油藏开发方式预测模型计算待预测高倾角油藏的目标参数预测值,所述目标参数为油藏采收率和地层压力水平,具体步骤如下:
[0115]
s071:将待预测高倾角油藏的主要参数分别使用天然能量开发方式标记、底部注水开发方式标记和底部注水 顶部注气开发方式标记,得到三组数据;
[0116]
s072:将所述三组数据分别输入到训练好的高倾角油藏开发方式预测模型中,得到三种开发方式下待预测高倾角油藏的油藏采收率预测值和地层压力水平预测值;
[0117]
具体实施时,将实施例高倾角油藏的静态参数及开发技术政策导入高倾角油藏开发方式预测模型,得到三种方式的油藏采收率和地层压力水平:天然能量开发的采收率为8%,底部注水开发的采收率为34%并保持原始地层压力的60%,底部注水 顶部注气开发方式的采收率为63%同时该方式的地层压力可以恢复至原始地层压力。
[0118]
s08:根据实际经济情况指标分别计算出三种方式对应的经济采收率,分别计算待预测油藏在三种开发方式下的经济采收率er,er的计算表达式如下:
[0119][0120]
其中:er为经济采收率,单位:%;f为含油面积,单位:km2;b为平均单井总投资,单位:104元/井;s为极限井网密度,单位:口/km2;n为地质储量,单位:104t;p为原油价格,单位:元/t;r为税率,单位:元/t;c为吨油操作成本,单位:元/t;不同类型的开发方式包含的单井类型及数量不同,所以涉及到的相关参数值也是有差异的;
[0121]
s09:通过对三种开发方式相对应的经济采收率、油藏采收率预测值和地层压力水平预测值的比较,得到对待预测高倾角油藏的开发方式推荐结果,具体步骤如下:
[0122]
s091:针对天然能量开发方式,当天然能量开发方式的油藏采收率预测值大于等于对应的经济采收率时,则予以保留;否则,排除该开发方式;
[0123]
针对底部注水开发方式,当底部注水开发方式的油藏采收率预测值大于等于对应的经济采收率且地层压力水平预测值大于等于50%时,则予以保留;否则,排除该开发方式;
[0124]
针对底部注水 顶部注气开发方式,当底部注水 顶部注气开发方式的油藏采收率预测值大于等于对应的经济采收率且地层压力水平预测值大于等于50%时,则予以保留;否则,排除该开发方式;
[0125]
其中,如果三种开发方式都被排除时,则表示该油藏不适合开发;
[0126]
如果保留下来的开发方式为两种或三种,则选取最大油藏采收率预测值所对应的开发方式作为推荐结果。
[0127]
具体实施时,在本实施例中天然能量开发的油藏采收率为8%,地层能量保持水平较低,低于该油藏的泡点压力,因此未能恢复地层压力水平;底部注水开发的油藏采收率为34%,比之该开发方式的经济采收率要高,在该油藏采收率下可以保证满足注水开发过程中的成本,而且地层压力水平可以恢复,并保持原始地层压力的60%,因此底部注水开发方式可行;底部注水 顶部注气开发方式的油藏采收率为63%,同样高于对应的经济采收率,在该油藏采收率下可以保证满足注水注气开发过程中的成本,而且地层压力水平可以恢复至原始地层压力水平,因此底部注水 顶部注气开发方式可行;对比两种开发方式,显然底部注水 顶部注气开发方式效果最佳。因此,选择底部注水 顶部注气开发方式作为该项目工程的推荐开发方式,自此则完成了对该高倾角油藏开发方式的快速决策与推荐。
[0128]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
