1.本方法属于计算机视觉技术领域,更进一步涉及一种立体匹配方法,可用于对双目相机获取的图像与视频进行视差估计。
背景技术:
2.双目视觉是计算机视觉领域的一个重要方向,其中的立体匹配任务又是双目视觉中最重要的子任务之一。立体匹配指对双目相机获取的二维双目图像进行极线矫正,通过对校正后的二维双目图像进行特征点匹配以获取三维场景下的视差值及深度信息。其基本原理是在左右目图像中查找双目图像的对应点,获取左右目图像中对应点相对的横坐标之差的绝对值,便可获得视差值。利用视差值与相机的焦距、双目相机的基线距离可进一步获得三维的深度信息。立体匹配方法建立在空间几何结构的基础上,具有求解速度快、硬件成本低等优势。
3.传统的立体匹配方法分为了全局方法与半全局方法两类。全局方法基于平滑性假设构造全局能量函数,并利用最优化方法求解能量函数的最小值点。该方法运算量大、用时长、实时性差。半全局方法利用局部信息,通过计算特定大小匹配窗口内的总匹配代价,利用赢家通吃wta策略查找最小值最终得到视差值。该方法受窗口大小影响较大,窗口过小会造成无法包含物体的全部纹理信息产生多义性,窗口过大则会在深度非连续区域产生膨胀效应,且增大计算量。
4.随着计算机技术的发展,人工智能领域的深度学习得到了迅速的发展,相比传统的立体匹配方法,基于深度学习的立体匹配方法具有更强的特征表达能力与特征学习能力,且具有可并行化的优点。使用深度学习的立体匹配方法通过基于卷积神经网络的构建,以及不断的训练与基于反向传播的梯度更新,可以完成对立体匹配网络的建立,实现一次性完成立体匹配的功能。
5.北京理工大学在申请号为202110550638.2,公开号为113177565a的专利文献中提出了“一种基于图像金字塔距离度量的近邻传播立体匹配方法”,其实现步骤如下:1)对左图和右图组成的立体图像对进行特征提取,并利用距离度量的方式进行配对;2)对图像进行连续的二倍下采样,并对下采样之后的图像进行匹配;3)选取匹配正确的像素点对,向相邻像素点传播匹配结果。该方法使用特征匹配构建的约束来寻找匹配点,但是由于只针对输入的左右目图像对构建图像金字塔并获取特征,无法对图像更深层次的语义、纹理等信息进行充分的提取,得到的匹配结果精度较差。
6.山东大学在申请号为202110281313.9,公开号为112991420a的专利文献中提出了“一种视差图的立体匹配特征提取及后处理方法”,其实现步骤如下:1)使用卷积核进行立体匹配特征的提取,并使用卷积核金字塔特征提取法;2)使用4路径代价聚合方法对卷积网络输出的特征进行聚合;3)使用内部型左右一致性检查对视差图进行左右一致性检测,对无效视差点进行填充从而获得最终的视差图。该方法存在的不足之处是:将卷积神经网络仅用于特征提取部分,未构建端到端的网络进行学习与训练,不利于算法对视差的进一步
学习以及降低模型的训练难度;同时其使用的代价聚合算法复杂度高,且不易于进行并行处理与加速,最终输出的视差图精度较低、耗时较长。
7.北京理工大学在申请号为202110550638.2,公开号为113177565a的申请专利文献中公开了“一种基于深度学习的双目视觉位置测量系统及方法”用于进行双目视觉位置测量。其系统包括图像捕获、深度学习物体识别、图像分割模块、拟合模块、双目点云模块的系统。其方法的实现步骤为:1)使用卷积神经网络搭建视差计算子模块,得到对其在双目左相机上的视差图;2)使用点云计算子模块,对得到的视差图通过双目相机内外参数得到该场景下的三维点云信息。该方法由于在视差聚合时使用了半全局匹配方法,得到的视差图易出现较多的离群点,导致最终输出的噪声较多。
8.jiaren chang等人于论文“pyramid stereo matching network”(conference on computer vision and pattern recognition,2018)中提出了一种端到端的双目立体匹配网络。该网络首先使用带有空间池化金字塔的卷积神经网络对双目图像进行特征提取,之后构建四维卷积代价体并用堆叠的三维卷积神经网络对代价体进行学习与聚合,最终得到视差图。该方法由于的特征提取网络由于仅使用空间平均池化金字塔来提取多个尺度上的平均特征,因而无法将原始图像与特征图中的边缘信息、纹理信息进行保留,易造成最终左右目图像匹配失败,导致在语义边缘处与纹理复杂区域的匹配效果差。
技术实现要素:
9.本发明目的在于克服上述现有技术存在的不足,提出一种基于双重空间池化金字塔的立体匹配方法,以对图像的特征信息进行充分的提取,提升语边缘处与纹理复杂区域的匹配效果,同时减少匹配结果中的离群点,提高最终立体匹配的准确性,获得更精确的视差图。
10.本发明的技术关键是:通过在端到端的双目立体匹配网络中的特征提取模块中使用双重池化金字塔结构,提升最终输出视差图的精度。其实现方案包括如下:
11.(1)获取双目立体匹配训练样本集t与验证样本集v
12.从已有的双目立体匹配数据集中获取n m组图像对ii={i
il
,i
ir
,i
igt
},其中i
il
、i
ir
分别为第i个图像对的左目图像及右目图像,i
igt
为第i个图像对的真实视差图像;
13.将数据集中n个图像对作为训练的样本集t={i1,i2,
…
,ij,
…
,in},1≤j≤n;m个图像对作为训练结果的验证集v={i
n 1
,i
n 2
,
…
,i
n k
,
…
,i
n m
},1≤k≤m,n≥180、m≥20;
14.(2)构建基于双重空间池化金字塔的双目立体匹配网络s
15.(2a)建立由平均池化金字塔e2
avg
和最大池化金字塔e2
max
并联构成的双重金字塔池化网络e2;
16.(2b)建立由初始卷积神经网络e1、双重池化金字塔网络e2以及特征融合网络e3级联构成的特征提取网络e;
17.(2c)建立由三个堆叠的三维卷积神经网络级联构成的代价聚合网络r;
18.(2d)将特征提取网络e、代价聚合网络r以及视差回归网络g级联构成双目立体匹配网络s;
19.(3)对双目立体匹配网络s进行训练:
20.(3a)设置学习率η,最大训练次数t
max
,当前迭代周期t'=0;
21.(3b)对训练集t中的左目图像i
il
与右目图像i
ir
使用前向传播方法得到网络输出的预测视差图i
ipred
;
22.(3c)对输出的图像使用smoothl1损失函数计算预测视差图i
ipred
与真实视差图i
igt
之间的误差li,并使用反向传播的梯度下降算法对当前网络s
t
中的卷积核权重参数ω
t
以及卷积核偏置参数b
t
进行更新;
23.(3d)将当前迭代周期加1,即t'=t' 1,判断是否达到最大迭代次数:
24.若t'=t
max
,则达到最大迭代次数,此时训练结束,得到训练好的双目立体匹配网络s
t
,
25.若t'<t
max
,则返回(3b);
26.(4)将验证样本集v输入到训练好的双重空间池化金字塔的立体匹配网络s中,依次经过其中的特征提取网络e、代价聚合网络r及视差回归网络g,得到视差图的预测结果i
ipred
,该预测结果即为立体匹配的结果。
27.本发明与现有的技术相比具有以下优点:
28.1.本发明由于使用双重金字塔池化网络e2,为双目立体匹配网络提供了具有丰富纹理信息与全局语义信息的多尺度特征,提升了立体匹配结果在语义边缘处、纹理复杂区域及纹理缺失区域的立体匹配精度。
29.2.本发明由于使用特征提取网络e,实现了左目及右目图像特征的提取以及进一步融合,提升了最终立体匹配结果的准确性,有效地减少了匹配结果中错误的离群点。
30.3.本发明由于使用代价聚合网络r及视差回归网络g,实现了双目图像的匹配,完成了对预测视差图的输出。
附图说明
31.图1是本发明的实现流程图;
32.图2是本发明中的池化金字塔结构示意图;
33.图3是用本发明仿真对左右目图像进行立体匹配后的输出视差图。
具体实施方式
34.下面结合附图对本发明的实施例和效果作进一步的详细描述。
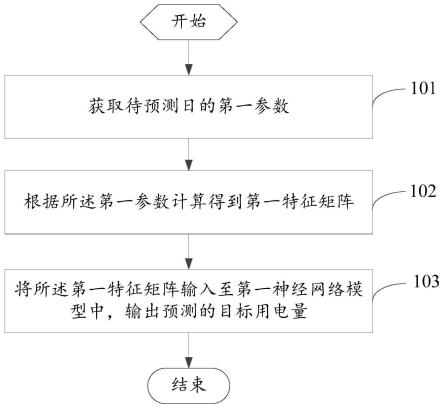
35.参照图1,本实例的实现步骤如下:
36.步骤1.获取双目立体匹配训练样本集t与验证样本集v。
37.获取kitti数据集,该数据集由卡尔斯鲁厄理工学院的geiger等人建立,其是使用装有两个高清彩色摄像头、velodyne激光雷达以及gps全球定位系统的汽车,拍摄城市、乡间、以及高速公路三个场景下的数据。通过该数据集提供双目图像、视差图、光流图等信息,可用于进行立体匹配、光流预测、3d物体检测、3d跟踪等任务。其分为kitti2012及kitti2015两个子数据集。其中kitti2012子数据集提供了194组含有双目图像及真实视差值的训练图像组,以及195组仅含有双目图像,真实视差值未公开的验证图像组;kitti2015在此基础上扩充,增加了200张训练图像组与200张验证图像组。
38.从kitti双目立体匹配数据集中获取分辨率为w
×
h的n m组图像对ii={i
il
,i
ir
,i
igt
},其中i
il
、i
ir
分别为第i个图像对的左目图像及右目图像,i
igt
为第i个图像对的真实视
差图像,在本实施例中w=512、h=256。
39.将数据集中n=394个图像对作为训练的样本集t={i1,i2,
…
,ij,
…
,in},1≤j≤n;
40.将m=200个图像对作为训练结果的验证集v={i
n 1
,i
n 2
,
…
,i
n k
,
…
,i
n m
},1≤k≤m,n≥180、m≥20。
41.将kitti2012与kitti2015中共计394个训练图像组作为训练图像集t,
42.将kitti2012中200张验证图像作为验证集v1,
43.将kitti2015中200张验证图像作为验证集v2。
44.步骤2.构建基于双重空间池化金字塔的立体匹配网络s。
45.2.1)参照图2,建立由平均池化金字塔e2
avg
和最大池化金字塔e2
max
并联构成的双重金字塔网络e2,其中:
46.平均池化金字塔e2
avg
,包含四个大小分别为4
×
4,8
×
8,16
×
16,64
×
64的平均池化核,每一种池化核的数量为32;
47.最大池化金字塔e2
max
,包含四个大小分别为4
×
4,8
×
8,16
×
16,64
×
64的最大池化核,每一种池化核的数量为32;
48.2.2)建立由初始卷积神经网络e1、双重池化金字塔网络e2以及特征融合网络e3级联构成的特征提取网络e,其中:
49.初始卷积神经网络e1,包含三个依次连接的残差单元,每个残差单元包括两组卷积层,第一组卷积层包含两组依次连接的32个大小为3
×
3、步长为2的卷积核;第二组卷积层包含三组依次连接的32个大小为3
×
3、步长为1的卷积核;
50.特征融合网络e3,包含四组并联的卷积层,每组卷积层均包含依次连接的两层卷积核,每层卷积核的大小为3
×
3、步长为1,数量为32个;
51.2.3)建立由三个堆叠的三维卷积神经网络级联构成的代价聚合网络r,每个三维卷积神经网络由依次连接的三组卷积层构成,每一组卷积层包含32个大小为3
×
3、步长为1的三维卷积核;
52.2.4)建立由两组依次连接的三维卷积层构成视差回归网络g,其第一组包含32个大小为3
×
3、步长为1的三维卷积核,第二组包含1个大小为3
×
3、步长为1的三维卷积核;
53.2.5)将特征提取网络e、代价聚合网络r以及视差回归网络g级联构成双目立体匹配网络s。
54.步骤3.对基于双重池化金字塔的双目立体匹配网络s进行训练。
55.3.1)设置学习率η,最大训练次数t
max
,当前迭代周期t'=0,在本实施例中η=0.001,t
max
=500;
56.3.2)对训练集t中的左目图像i
il
与右目图像i
ir
使用前向传播方法得到网络输出的预测视差图i
ipred
:
57.3.2a)利用初始卷积神经网络e1分别对左图像i
il
与右图像i
ir
进行特征提取,分别得到左图像特征图f
il
与右图像特征图f
ir
;
58.3.2b)利用双重池化金字塔网络e2对左右目特征图f
il
、f
ir
进行池化运算,得到左目平均池化特征图组f
il_avg
、左目最大池化特征图组f
il_max
,以及右目平均池化特征图组f
ir_avg
、右目最大池化特征图组f
ir_max
,其中:
59.在平均空间池化金字塔e2
avg
中使用四个不同大小的平均池化核对左图像特征图与右图像特征图进行平均池化操作提取含有语义信息的特征,得到左目平均池化特征图组f
il_avg
、右目平均池化特征图组f
ir_avg
:
60.f
il_avg
={f
il_avg1
,f
il_avg2
,f
il_avg3
,f
il_avg4
}
61.f
ir_avg
={f
ir_avg1
,f
ir_avg2
,f
ir_avg3
,f
ir_avg4
}
62.其中,f
il_avgi
、f
ir_avgi
为第i个平均池化核的输出,1≤i≤4;
63.在最大空间池化金字塔e2
max
中使用四个不同大小的最大池化核对左图像特征图与右图像特征图进行最大池化操作获得具有纹理与边缘信息的特征,得到左目图像最大池化特征图组f
il_max
、右目图像最大池化特征图组f
ir_max
:
64.f
il_max
={f
il_max1
,f
il_max2
,f
il_max3
,f
il_max4
}
65.f
ir_max
={f
ir_max1
,f
ir_max2
,f
ir_max3
,f
ir_max4
}
66.其中,f
il_maxi
、f
ir_maxi
为第i个最大池化核的输出,1≤i≤4;
67.3.2c)将两个池化金字塔得到的特征图进行堆叠并经过特征融合网络e3,输出左图像特征图与右图像多尺度特征图
68.3.2d)设置视差搜索范围d,在本实施例中d=192,首先对每一个视差值d使用拼接的方式构建当前视差值的代价体,得到三维匹配代价体组ci={c
i1
,c
i2
,
…
,c
id
,
…
,c
id
},再依次将其d个三维匹配代价体c
id
进行拼接,构建四维匹配代价体
69.3.2e)利用代价聚合网络r对四维匹配代价体c
id
进行卷积运算,得到聚合后的代价体
70.3.2f)使用视差回归网络g,将聚合后代价体依次进行卷积和通道压缩操作,并利用双线性插值法其大小进行尺寸恢复,得到视差三维代价体c
ipred
;
71.3.2g)对三维代价体c
ipred
使用软argmin操作,得到网络预测的视差图i
ipred
,其公式如下:
[0072][0073]
3.3)对输出的图像使用smoothl1损失函数计算预测视差图i
ipred
与真实视差图i
igt
之间的误差li,其计算公式如下:
[0074][0075]
3.4)使用反向传播的梯度下降算法对当前网络s
t
中的卷积核权重参数ω
t
以及卷积核偏置参数b
t
进行更新,公式如下:
[0076][0077][0078]
其中,ω
t 1
和b
t 1
分别表示经过更新后的卷积核权重参数及更新后的卷积核偏置参数。
[0079]
3.4)将当前迭代周期加1,即t'=t' 1,判断是否达到最大迭代次数:
[0080]
若t'=t
max
,则达到最大迭代次数,此时训练结束,得到训练好的双目立体匹配网络s
t
,
[0081]
若t'<t
max
,则返回3.2);
[0082]
步骤4.利用训练好的双目立体匹配网络,获取双目立体匹配验证集结果。
[0083]
将验证样本集v输入到训练好的双重空间池化金字塔的立体匹配网络s
t
中,先经过其中的特征提取网络e,分别对第i个样本的左目图像i
il
与右目图像i
ir
提取包含语义信息特征与纹理边缘信息特征的左图像特征图与右图像多尺度特征图并对这两个特征使用拼接的方式构建d个视差值的代价体,再进行拼接构建四维匹配代价体该四维代价体通过代价聚合网络r进行卷积运算,得到聚合后的代价体;该聚合后的代价体通过视差回归网络g进行卷积和通道压缩操作,并利用双线性插值法对其大小进行尺寸恢复,得到视差三维代价体c
ipred
,再对该视差三维代价体使用软argmin操作,得到立体匹配的结果,即预测的视差图i
ipred
。
[0084]
下面结合仿真实验对本发明的效果做进一步的描述:
[0085]
1、仿真实验条件
[0086]
仿真实验的软件平台为:ubuntu 16.04lts操作系统,python3.7编程语言,pytorch深度学习框架;
[0087]
仿真实验的硬件平台为:中央处理器为英特尔i9-7700x的主机,内存为32gb,图形处理器为英伟达rtx 2080ti,其显存为11gb。
[0088]
仿真实验的数据集为:kitti2012与kitti2015中共计394个训练图像组为训练图像集t,kitti2012中200张验证图像为验证集v1,kitti2015中200张验证图像为验证集v2。
[0089]
在kitti2012验证集v1中,将预测视差值i
ipred
与真实视差值i
igt
的误差值大于e像素的区域a
e-all
的面积s
ae-all
占图像a
all
总面积s
aall
的比值定义为e-all评价指标:
[0090][0091]
将视差非闭合区域a
noc
中视差误差值大于e像素值的区域a
e-noc
的面积s
ae-noc
占视差非闭合区域面积s
anoc
的比值定义为e-noc评价指标:
[0092][0093]
在本实例中e=2,3,可得四类评价指标:二像素全局误差2-all、三像素全局误差3-all、二像素非闭合误差2-noc、三像素非闭合误差3-noc;
[0094]
在kitti2015验证集v2中,将区域a中的预测视差图与真实视差图的误差大于3像素或大于该点视差真实值5%的区域a
t
与a区域的面积的比值定义为区域a内的d1误差评价指标:
[0095][0096]sat
为区域a
t
的面积,sa区域a的面积;在验证集v2中,区域a分别选取图像的前景区
域计算前景误差评价指标d1-fg,选取背景区域计算背景误差评价指标d1-bg,选取整体区域计算全局误差评价指标d1-all。
[0097]
2、仿真内容及其结果分析
[0098]
仿真1.将kitti2012与kitti2015中共计394个训练图像组作为训练图像集t,对构建的双目立体匹配网络s进行训练,得到训练好的立体匹配网络s
t
,将kitti2012中200张验证图像作为验证集v1输入到训练好的立体匹配网络s
t
中,得到本发明方法的立体匹配的结果,并计算二像素全局误差2-all、三像素全局误差3-all、二像素非闭合误差2-noc、三像素非闭合误差3-noc评价指标;
[0099]
将论文“pyramid stereo matching network”作为基准方法,并利用论文中的方法构建基准网络,将训练图像集t对基准网络进行训练,得到训练好的基准网络,将验证集v1输入到训练好的基准网络中,得到基准方法的立体匹配结果,并计算二像素全局误差2-all、三像素全局误差3-all、二像素非闭合误差2-noc、三像素非闭合误差3-noc评价指标;
[0100]
将kitti2012测试集分别经过基准方法与本发明方法得到的评价指标进行对比,结果见表1:
[0101]
表1本发明方法与基准方法在kitti2012数据集上的验证指标对比
[0102][0103]
从表1中可看出,在kitti2012验证集v1上,本发明方法相对基准方法的评价均得到提升,其中2-noc指标提升了1.18%,2-all指标提升了0.23%,3-noc提升了0.07%,3-all指标提升了0.16%。
[0104]
仿真2.使用仿真1中训练好的立体匹配网络s
t
,将kitti2015中200张验证图像作为验证集v2输入到训练好的立体匹配网络s
t
中,得到本发明方法的立体匹配结果,如图3,其中图3(a)为待匹配的左目图像,图3(b)为待匹配的右目图像,图3(c)为使用本发明仿真对左右目图像进行立体匹配后的输出视差图。图3(c)表明本发明可在语边缘处与纹理复杂区域获得较好的匹配结果。
[0105]
对本发明方法的立体匹配结果计算其前景误差评价指标d1-fg、背景误差评价指标d1-bg、全局误差评价指标d1-all;
[0106]
使用仿真1中训练好的基准网络,将验证集v2输入到训练好的基准网络中,得到基准方法的立体匹配结果,并计算其前景误差评价指标d1-fg、背景误差评价指标d1-bg、全局误差评价指标d1-all;
[0107]
将kitti2015测试集分别经过基准方法与本发明方法得到的评价指标进行对比,结果见表2:
[0108]
表2本发明方法与基准方法在kitti2015数据集上的验证指标对比
[0109][0110]
从表2中可看出,在kitti2015数据集v2上进行验证,全局误差指标d1-all相比基准方法提升0.19%,背景误差指标相比基准方法d1-bg提升0.06%,前景误差指标d1-fg相比基准方法提升0.67%,
[0111]
上述仿真结果表明,本发明相比基准方法在kitti2012验证数据集v1及kitti2015验证数据集v2上的误差评价指标均得到提升,可有效提升立体匹配结果的准确性并获得更精确的视差图。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。