1.本发明涉及降雨数据处理的技术领域,特别是一种降雨空间数据复原和重构的方法。
背景技术:
2.近几年,随着全球气候变化,极端暴雨出现的频次逐年增多,极端暴雨带来的洪涝灾害也逐年增加。极端暴雨出现在城市,会给城市带来严重的洪涝灾害,极端暴雨出现在山区,会形成山洪灾害。为了应对极端暴雨带来的影响,最大限度的降低极端大暴雨带来的灾害,除了提高防洪工程标准之外,还需要加强暴雨风险精细化管理。
3.暴雨风险精细化管理中最重要的环节是提前预知、预判暴雨精细化特征,以帮助识别暴雨可能引发的风险,进而提醒人民避免或减少洪涝高风险的地区的活动,从而降低洪涝造成的灾害和损失。因此,需要在历史观测资料基础上总结暴雨的时空分布精细化特征,根据历史规律提前预测降雨的动态发展趋势,并建立有针对性的应急管理预案,可为合理部署救援力量和快速调度救灾物资提供科学参考。而极端暴雨的降雨时空不均匀以及不确定性,是影响洪涝过程的评估预测、影响洪涝风险精细化管理的主要短板之一。
4.对降雨精细化时空规律的提取和总结,完全依赖于降雨观测资料的数量和质量,观测资料直接影响降雨特征的提取和重构。观测资料时间序列越长、降雨数据间隔越短、观测站点分布越密集,总结的规律越精细,反之,则相反。长间隔的降雨资料,不能反应降雨在短时间内精细化的时空变化规律,而城市洪涝风险精细化管理迫切需要短间隔、精细化的降雨特征。
5.因此,将宝贵的历史长间隔的降雨空间资料有效的利用起来,使得历史的长间隔(逐24h、逐12h、逐6h等)降雨观测资料也可以反应出降雨短间隔(如逐1h、逐30min等)时空特征,以充实、扩充短间隔降雨学习样本库,为提取降雨时空分布进行特征提供更丰富的学习样本库,是当前需要迫切解决的主要问题。
6.2019年6月第50卷第60期的《水利学报》公开了刘媛媛、刘洪伟、霍风霖和刘业森的题目为《基于机器学习短历时暴雨时空分布规律研究》的文章,该文章提出:城市内涝风险的精细化管理和防洪排涝市政工程的科学设计,需要对当地降雨的时空分布特征有深入的了解。而传统以单站雨型代表整个区域降雨特征的分析方法,不能满足这一要求。本文尝试将机器算法引入到暴雨时空分布特征研究中,以北京城区2004—2016年降雨资料为研究样本,利用动态聚类算法,提取北京城区短历时暴雨时空分布的动态特征。经分析,北京汛期的短历时暴雨时空分布特征,可以分为3种类型:(1)降雨自西北部山区移动到城中心区,逐渐扩散到城区;(2)降雨集中在城区西南部地区,逐渐向北部和城中心区扩散;(3)降雨集中在城区中心区和东部地区,基本不发生移动。研究结果表明,基于机器学习算法提取的暴雨时空分布特征,与实际暴雨时空动态发展趋势相符,并且有各自对应的降雨形成的不同物理机制,可为城区降雨设计、城市内涝风险管理等工作提供借鉴与参考。该方法的
缺点是对数据数量和质量的要求比较高,需要大量的历史降雨资料进行学习和训练以提取时空特征,而且需要降雨资料的颗粒度比较小,如需要逐分钟级的降雨资料。而由于历史原因,大量的历史降雨资料,都是逐日、逐月等,颗粒度比较大的资料,这就限制了该方法的进一步推广和应用。
7.2010年第3期的《计算机学报》公开了孟德宇、徐晨和徐宗本的题目为《基于isomap的流形结构重建方法》的文章,该文章提出:已有的流形学习方法仅能建立点对点的降维嵌入,而未建立高维数据流形空间与低维表示空间之间的相互映射。此缺陷已限制了流形学习方法在诸多数据挖掘问题中的进一步应用。针对这一问题,文中提出了两种新型高效的流形结构重建算法:快速算法与稳健算法。其均以经典的isomap方法内在运行机理为出发点,进而推导出高维流形空间与低维表示空间之间双向的显式映射函数关系,基于此函数即可实现流形映射的有效重建。理论分析与实验结果证明,所提算法在计算速度,噪音敏感性,映射表现等方面相对已有方法具有明显优势。该方法当前主要应用在图像处理和人脸识别上,表现出了明显的优势。但在其他方面并没有得到应用,尤其是在大尺度的空间监测数据的处理上。
技术实现要素:
8.为了解决上述的技术问题,本发明提出的一种基于流形学习重构降雨空间数据的方法,首先将暴雨过程(近期短间隔的降雨资料)进行数字化和结构化,从时间维度和空间维度构造高维数组,再通过isomap算法进行降维。通过机器学习中的动态聚类方法,对降维后的降雨时空分布特征进行分类,再提取挖掘各类暴雨精细化时空分布特征,最后基于提取精细化特征,对历史中长历时降雨空间资料进行复原和重构。
9.本发明的目的是提供一种降雨空间数据复原和重构的方法,包括获取近期短间隔的降雨资料,还包括以下步骤:步骤1:对所述近期短间隔的降雨资料进行数字化和结构化处理,从时间维度和空间维度构造暴雨时空分布动态矩阵;步骤2:对所述暴雨时空分布动态矩阵进行降维;步骤3:对降维后的降雨时空分布特征进行分类;步骤4:提取挖掘各类暴雨精细化时空分布特征;步骤5:基于提取的精细化时空分布特征,对历史长历时降雨空间资料进行复原和重构。
10.优选的是,所述步骤1包括对不同历时的各场次降雨,构建时间维度和空间维度占比矩阵,用雨量占比的矩阵来描述某个时段降雨的分布特征。
11.在上述任一方案中优选的是,所述步骤1还包括建立降雨过程样本集ω,实现多场次降雨的时空动态发展特征的数学描述,公式如下
其中,ω包括n场暴雨,xj为第j次降雨的占比矩阵,为j次降雨过程中第i个雨量站t时刻的降雨量占该时刻所有站降雨量的百分比,s为雨量站数,m为总时刻数。
12.在上述任一方案中优选的是,所述j次降雨过程中第i个雨量站t时刻的降雨量占该时刻所有站降雨量的百分比的公式为其中,为第j次降雨过程中,第i雨量站t时刻的降雨量,i=1,2,3
…
s,t=1,2,3
…
m。
13.在上述任一方案中优选的是,所述步骤2包括以下子步骤:步骤21:确定在流形m上的邻域点,构造近邻图;步骤22:采用计算最短路径dg(p,q)的方法近似估计流形m 上的测地线距离dm(p,q);步骤23:使用经典cmds 将样本向量压缩到d 维,并使压缩后样本向量之间的欧式距离尽可能接近已求出的最短路径。
14.在上述任一方案中优选的是,所述步骤21包括设定输入空间x 的任意两个样本向量x
p
与xq的欧式距离为de(p,q),然后用全部的样本向量x
k (1≤k≤n)构造有权图g。
15.在上述任一方案中优选的是,所所述步骤22包括设任意两个样本向量 x
p
与xq之间的最短距离为dg(p,q),如果x
p
与xq之间存在连线,则初始化dg(p,q) =de(p,q),否则令dg(p,q)= ∞。
16.在上述任一方案中优选的是,所述步骤22还包括更新dg(p,q)的数值,对于k = 1,2,3,
…
n ,令dg(p,q)= min{ dg(p,q),dg(p,k) dg(p,k 1)} ,经过多次迭代,样本向量间最短路径矩阵dg={dg(p,q)}收敛。
17.在上述任一方案中优选的是,所述步骤23包括设矩阵τ(d
g )的前d个特征值λ
1 ≥λ
2 ≥λ
3 ≥
…
≥ λd对应的特征向量为 v1,v2,v3,
ꢀ…
,vd,λp 是第p个特征值,是λp对应的特征向量的第m个分量,则d维嵌入向量yi的第p个分量等于,高维空间中各点在低维空间中的嵌入坐标y ,表示为:
。
18.在上述任一方案中优选的是,所述动态聚类的计算方法包括以下子步骤:步骤31:分析的样本集为φ={y1,y2,
…
,yn},y为低维空间中的映射点,m为最大迭代次数,r为初始划分的子集数,c={c1,c2,
…
,cr}为r个子集,其中,初始时,jj=1,2,
…
r,r《n;步骤32:从φ中随机选取r个样本,作为初始r个子集的各中心向量;步骤33:对于n=1,2,
……
n,计算样本y
ii
与每个聚类中心z
jj
={z1,z2,
……
zr}的距离,如果d
iijj =min{d
iijj
},ii=1,2,
…
n,则,更新,其中,;步骤34:对于jj=1,2,
…
r,对c
jj
中的所有样本点,重新计算中心向量;步骤35:不断重复迭代,如果 ,j=1,2,
……
r,则重新执行步骤32,重复迭代计算,如果, j=1,2,
……
r,运算结束;步骤36:输出各子集c={c1,c2,
…
,cr},属于各子集的样本以及各子集的均,其中,o为各子集里样本的个数。
19.在上述任一方案中优选的是,所述步骤5包括在低维空间中的各子集c={c1,c2,
…
,cr}中的样本,在高维空间中,也分别属于同一子集,b={b1,b2,
…
,br},在高维空间中求各子集的均值,为高维空间中各类的聚类中心,即为属于该类样本的动态时空分布特征。
20.本发明提出了一种降雨空间数据复原和重构的方法,将ai技术中的流形学习算法有效的引入到历史降雨空间数据的修补、复原和重构中,可将宝贵的历史降雨资料有效的
利用起来,有效的扩充和完善了短间隔降雨空间数据,为地区降雨精细化时空特征分析和提取提供了更为丰富和合理的训练样本,为人工智能技术在防洪减灾方向的应用提供了新思路。
附图说明
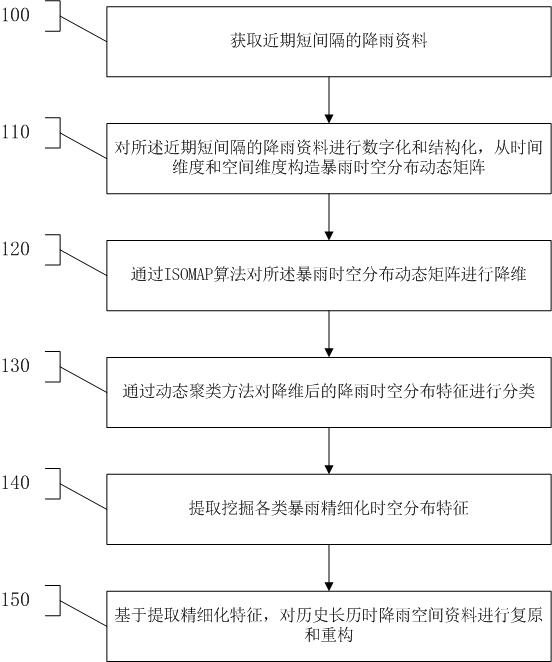
21.图1为按照本发明的降雨空间数据复原和重构的方法的一优选实施例的流程图。
22.图2为按照本发明的降雨空间数据复原和重构的方法的另一优选实施例的技术流程图。
具体实施方式
23.下面结合附图和具体的实施例对本发明做进一步的阐述。
24.实施例一如图1所示,执行步骤100,获取近期短间隔的降雨资料。
25.执行步骤110,对所述近期短间隔的降雨资料进行数字化和结构化处理,从时间维度和空间维度构造暴雨时空分布动态矩阵。对不同历时的各场次降雨,构建时间维度和空间维度占比矩阵,用雨量占比的矩阵来描述某个时段降雨的分布特征。建立降雨过程样本集ω,实现多场次降雨的时空动态发展特征的数学描述,公式如下公式如下其中,ω包括n场暴雨,xj为第j次降雨的占比矩阵,为j次降雨过程中第i个雨量站t时刻的降雨量占该时刻所有站降雨量的百分比,s为雨量站数,m为总时刻数。所述j次降雨过程中第i个雨量站t时刻的降雨量占该时刻所有站降雨量的百分比的公式为其中,为第j次降雨过程中,第i雨量站t时刻的降雨量,i=1,2,3
…
s,t=1,2,3
…
m。
26.执行步骤120,对所述暴雨时空分布动态矩阵进行降维,包括以下子步骤:执行步骤121,确定在流形m上的邻域点,构造近邻图,设定输入空间x 的任意两个样本向量x
p
与xq的欧式距离为de(p,q),然后用全部的样本向量x
k (1≤k≤n)构造有权图g。
27.执行步骤122,采用计算最短路径dg(p,q)的方法近似估计流形m 上的测地线距离dm(p,q),所述步骤22包括设任意两个样本向量 x
p
与xq之间的最短距离为dg(p,q),如果x
p
与xq之间存在连线,则初始化dg(p,q) =de(p,q),否则令dg(p,q)= ∞。更新dg(p,q)的数值,对于k = 1,2,3,
…
n ,令dg(p,q)= min{ dg(p,q),dg(p,k) dg(p,k 1)} ,经过多次迭代,样
本向量间最短路径矩阵dg={dg(p,q)}收敛。
28.执行步骤123,使用经典cmds 将样本向量压缩到d 维,并使压缩后样本向量之间的欧式距离尽可能接近已求出的最短路径。设矩阵τ(d
g )的前d个特征值λ
1 ≥λ
2 ≥λ
3 ≥
…
≥ λd对应的特征向量为 v1,v2,v3,
ꢀ…
,vd,λp 是第p个特征值,是λp对应的特征向量的第m个分量,则d维嵌入向量yi的第p个分量等于,高维空间中各点在低维空间中的嵌入坐标y ,表示为:。
29.执行步骤130,对降维后的降雨时空分布特征进行分类,包括以下子步骤:执行步骤131,分析的样本集为φ={y1,y2,
…
,yn},y为低维空间中的映射点,m为最大迭代次数,r为初始划分的子集数,c={c1,c2,
…
,cr}为r个子集,其中,初始时,jj=1,2,
…
r,r《n;执行步骤132,从φ中随机选取r个样本,作为初始r个子集的各中心向量;执行步骤133,对于n=1,2,
……
n,计算样本y
ii
与每个聚类中心z
jj
={z1,z2,
……
zr}的距离,如果d
iijj =min{d
iijj
},ii=1,2,
…
n,则,更新,其中,。
30.执行步骤134,对于jj=1,2,
…
r,对c
jj
中的所有样本点,重新计算中心向量。
31.执行步骤135,不断重复迭代,如果 ,j=1,2,
……
r,则重新执行步骤132,重复迭代计算,如果, j=1,2,
……
r,运算结束。
32.执行步骤136,输出各子集c={c1,c2,
…
,cr},属于各子集的样本以及各子集的均,其中,o为各子集里样本的个数。
33.执行步骤140,提取挖掘各类暴雨精细化时空分布特征。
34.执行步骤150,基于提取的精细化时空分布特征,对历史长历时降雨空间资料进行
复原和重构。在低维空间中的各子集c={c1,c2,
…
,cr}中的样本,在高维空间中,也分别属于同一子集,b={b1,b2,
…
,br},在高维空间中求各子集的均值,为高维空间中各类的聚类中心,即为属于该类样本的动态时空分布特征。
35.实施例二本发明适用于历史长间隔降雨资料数据的处理和雨量站点分布较为稀疏地区的降雨数据的处理。虽然重建结果具有随机性和不确定性,但是它们能在已知该地区降雨时空分布特征的基础上,对历史长间隔降雨空间资料进行修补、复原和重构,使得历史长历时降雨数据可客观、合理的反应出短间隔降雨过程的的时空变化特征,从而进一步充实、扩充短间隔、短历时的降雨资料样本库,提高降雨空间数据的颗粒度,对于该地区短历时降雨精细特征的提取,具有一定实际意义。
36.通过本发明,利用isomaps的空间数据重建方法,对历史长间隔的降雨观测资料进行扩充、修补和完善,使得历史长间隔的降雨观测资料可以得到有效、充分的利用,扩充了降雨时空分布特征提取和学习的样本库,提高了降雨空间数据的颗粒度,并进一步增强了降雨时空特征,以实现降雨时空分布精细化特征的有效、合理的提取和总结1、技术流程本发明的技术流程如图2所示。
37.传统处理降雨空间资料的方法,主要利用曲线拟合、线性插值等分配方法,把逐6h、逐12h或逐24h长间隔的降雨资料分配到逐1h、逐30min等短间隔中,但是这种曲线拟合分配降雨量的方式,依据不足,主观影响因素大。
38.随着机器学习技术的发展,这种基于数据本身驱动的方法,应用越来越广泛。本发明就是把机器学习中的流形学习算法应用到降雨空间资料的重构、修补和完善中,通过分析近期短间隔降雨的雨型特征,对历史长间隔逐6h、逐12h以及逐24h的降雨资料进行插补和复原,使得历史长间隔的降雨资料也可以反应出降雨的短间隔精细化时空变化特征。同时,利用该方法插补和复原的历史长间隔降雨数据,也是对短间隔降雨资料的扩充和特征增强。
39.经分析计算,基于该算法重构和还原的历史长间隔降雨数据,可以客观合理的反应出当时降雨精细化的时空分布特征。经过该算法修补和还原的历史降雨资料,可以为降雨时空分布精细特征提取的学习样本,以实现降雨时空分布精细化特征的提取和总结。
40.2、主要内容机器学习其主要的工作就是通过算法提取海量数据样本的主要特征,根据学习到的规律,预测未来。本方法主要包括5部分内容:建立短间隔降雨空间特征模式库、模式的降维、模式的分类、模式的提取、模式重构。
41.本方法首先将暴雨过程(近期短间隔的降雨资料)进行数字化和结构化,从时间维度和空间维度构造高维数组,再通过isomap算法进行降维。通过机器学习中的动态聚类方法,对降维后的降雨时空分布特征进行分类,再提取挖掘各类暴雨精细化时空分布特征,最后基于提取精细化特征,对历史长历时降雨空间资料进行重构。
42.描述暴雨时空分布精细化特征的样本为高维样本,直接对其动态聚类分析,分类
2000)。isomap算法是建立在cmds基础之上,试图保持数据的内在的几何特性,获得流形上数据点之间的测地线距离。isomap算法用测地线距离替代欧式距离,并应用cmds对测地线距离进行低维嵌入,克服了cmds的局限性。一个流形上的测地线距离可以表示为一系列邻域点之间的距离之和。算法的关键在于利用样本向量之间的欧式距离de(i,j)计算出样本之间的测地线距离dg(i,j),然后使用经典cmds算法构造一个新的d维(d为降维空间的维数)欧式空间y,最大限度地保持样本之间的欧式距离de(i,j)与dg(i,j)误差最小,从而起到降维的作用。对于邻域点,isomap由输入空间直接得到其测地线距离;对于非邻域点,其测地线距离可近似为一系列邻域点的测地线距离之和。
48.isomap的算法有三个步骤:第一个步骤是确定在流形m上,哪些点是相互邻域点。第二个步骤是通过计算最短路径dg(i,j)的方法估计流形m上的测地线距离dm(i,j)。第三个步骤是应用cmds构造d维嵌入。具体算法如下:第一个步骤是确定在流形m上的邻域点,构造近邻图。设输入空间x的任意两个样本向量xi与xj的欧式距离为de(i,j),然后用全部的样本向量xi(1≤i≤n)构造有权图g。采用如下方法确定xi的邻域,即对于xi将距离其最近的k个点作为邻域。在图g中,若xj是xi的邻域点,则将它们连接起来,设连接线的长度分别为它们的欧式距离de(i,j)。对输入样本集中所有的点都执行上述相同的操作,则可得到有权图g。
49.第二个步骤是估计流形m上的测地线距离dm(i,j)。采用计算最短路径dg(i,j)的方法近似估计流形m上的测地线距离dm(i,j)。在图g中,设任意两个样本向量xi与xj之间的最短距离为dg(i,j),如果xi与xj之间存在连线,则初始化dg(i,j)=de(i,j),否则令dg(i,j)=∞。然后更新dg(i,j)的数值,对于k=1,2,3,
…
n,令dg(i,j)=min{dg(i,j),dg(i,k) dg(i,k 1)},经过多次迭代,样本向量间最短路径矩阵dg={dg(i,j)}便可收敛。最短路径矩阵可以采用dijkstra算法计算得到。
50.第三个步骤是应用cmds构造d维嵌入。使用经典cmds将样本向量压缩到d维,并使压缩后样本向量之间的欧式距离尽可能接近已求出的最短路径。设矩阵τ(dg)的前d个特征值λ1≥λ2≥λ3≥
…
≥λd对应的特征向量为v1,v2,v3,
…
,vd,λp是第p个特征值,是λp对应的特征向量的第m个分量,则d维嵌入向量yi的第p个分量等于,高维空间中各点在低维空间中的嵌入坐标y,表示为:(4)从而实现了高维数据的降维。
51.(3)动态聚类分析将经过降维的样本集(d为投影的低维空间维度,n为样本数)进行分
类,划分为r个子集,各子集内的样本近似,而各子集之间的样本不同。通过求各子集的质心,提取属于该类的特征。本文主要采用动态聚类法(dynamical clustering methods )对降维后样本进行分类。动态聚类分析的基本思想是:通过迭代寻找r个聚类的一种划分方案,使得用这r个聚类的均值来代表相应各类样本时,所得的总体误差最小。即,通过该算法,将总体样本集划分为r个子集,使得各子集内的样本最近似,而各子集之间的样本最不同。再提取各子集的均值,得到属于该子集的特征。
52.分析时,先随机选择r个样本点,作为r个子集的初始聚类中心,计算所有样本与这r个初始聚类中心的距离,并把样本划分到与之距离最近的那个中心所在的子集中,使所有的样本根据距离自动聚集到各个子集中,从而得到初始分类类别数以及初始子集。计算各子集所有样本的均值,得到新一代的聚类中心,再次计算所有样本与新的聚类中心的距离,自动聚集,得到新的聚类中心,计算各子集所有样本的均值
……
。不断迭代,并比较第p代和第p 1代聚类中心,如果相差在范围之内,则认为计算收敛,从而得到最终的子集及各子集的聚类中心。
53.该聚类方法收敛速度快,容易解释,聚类效果较好。但是该方法的聚类结果受初始聚类中心的选择的影响较大。因此本方法在迭代收敛后,不断的比较分析,判断子集数和初始子集中心是否合理,调整子集数以及子集的初始中心,以此反复进行聚类的迭代运算,直至确定合理的空间分布特征类别数和聚类中心。计算步骤如下:(1)分析的样本集为φ={y1,y2,
…
,yn},y为低维空间中的映射点,m为最大迭代次数,r为初始划分的子集数,c={c1,c2,
…
,cr}为r个子集,其中,初始时,jj=1,2,
…
r,r《n。
54.(2)从φ中随机选取r个样本,作为初始r个子集的各中心向量(0为迭代次数初始值)。
55.(3)对于n=1,2,
……
n,计算样本y
ii
与每个聚类中心z
jj
={z1,z2,
……
zr}的距离,如果d
iijj =min{d
iijj
},ii=1,2,
…
n,则,更新,其中,。
56.(4)对于jj=1,2,
…
r,对c
jj
中的所有样本点,重新计算中心向量。
57.(5)不断重复迭代,如果 ,j=1,2,
……
r,则回到(2),重复迭代计算,如果, j=1,2,
……
r,运算结束。
58.(6)输出各子集c={c1,c2,
…
,cr},属于各子集的样本以及各子集的均。
59.(4)短间隔降雨时空特征空间的重构以上的聚类方法得到的各子集c={c1,c2,
…
,cr}以及各子集的均值并不是所求的特征空间,而降维后数据集的特征空间。本文所用的isomap算法认为高维空间和低维
空间局部线性关系保持不变。也就是说,高维空间中的样本xi与其周围的样本线性关系,与其在低维空间中的映射点yi与其周围对应样本的局部线性关系相同。因此,在该空间中,属于同一个子集的样本,在高维空间中,也具有相似性。低维空间中,属于同一子集的样本,在高维空间中,也划分为同一子集。
60.这意味着,在低维空间中的各子集c={c1,c2,
…
,cr}中的样本,在高维空间中,也分别属于同一子集,b={b1,b2,
…
,br},在高维空间中求各子集的均值,为高维空间中各类的聚类中心,即为属于该类样本的动态时空分布特征。
61.四、有益效果:利用该算法,对以北京市的历史长间隔(6h、12h、24h等)降雨监测数据进行了修补和重构,得到符合该地区降雨时空分布特征的短间隔(10min、30min、1h等)降雨空间数据,较为准确、合理的复原和重构了该地区的短间隔降雨空间数据,有效的扩充和完善了短间隔降雨空间资料样本库,可以满足对降雨时空分布精细化特征分析的要求,为流形学习算法处理非线性空间数据提供了新思路。
62.得到有效扩充和完善的,符合该地区降雨时空分布精细化特征的学习样本库,可为地区的工程规划设计、洪涝风险分析等提供高颗粒度的降雨空间资料,为地区洪涝风险精细化管理提供有效的数据支撑。
63.本发明将ai技术中的流形学习算法有效的引入到历史降雨空间数据的修补和重构中,可将宝贵的历史降雨资料有效的利用起来,有效的扩充和完善了短间隔降雨空间数据,为地区降雨精细化时空特征分析和提取提供了更为丰富和合理的训练样本,为人工智能技术在防洪减灾方向的应用提供了新思路。
64.为了更好地理解本发明,以上结合本发明的具体实施例做了详细描述,但并非是对本发明的限制。凡是依据本发明的技术实质对以上实施例所做的任何简单修改,均仍属于本发明技术方案的范围。本说明书中每个实施例重点说明的都是与其它实施例的不同之处,各个实施例之间相同或相似的部分相互参见即可。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。