1.本发明涉及氢能源产业大数据技术领域,尤其是基于大数据的氢能产业链风险监测系统及监测方法。
背景技术:
2.能源和环境问题已经变成全人类共同面对的至关重要的全球性问题。然而,近半个世纪来,随着全球工业化进程的不断加速,能源紧缺问题日益凸显出来,特别是汽车、远洋轮船、飞机等现代交通运输行业的飞速发展,使得全球范围内围绕石油、天然气等化石能源的争夺越来越激烈。氢是组成水及有机物的主要元素之一,在自然界中主要以化合物的形式存在,由氢和氧元素组成的水占地表面积的70%以上,因此氢能来源广泛。氢气是由氢元素组成的双原子分子气体,具有无色无味无毒的特性,在燃烧时的燃烧产物仅有水,而不会产生二氧化碳等温室气体,也不会产生其它造成大气污染的气体,因此氢气在使用过程中是非常清洁的。氢能虽然有诸多优点,但是作为一种高密度的能量载体在其使用过程中往往也面临着许多安全问题。近年来国内外均出现过多起氢气泄漏、爆炸事故。现有技术中,针对氢能产业链的风险进行检测与处理的方法少之又少,产业链上的氢能数据仅依赖于各企业的自行处理与维护,管理部门获取的数据具有滞后性,不能及时对产业链中的异常情况进行处理,延误了故障的最佳排除时间。
技术实现要素:
3.本发明的目的是通过提出基于大数据的氢能产业链风险监测方法,以解决上述背景技术中提出的缺陷。
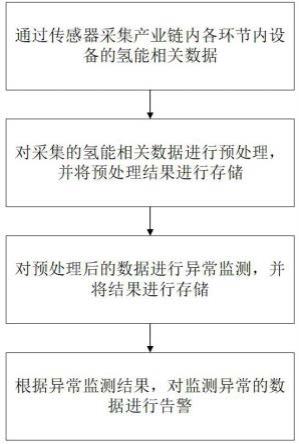
4.本发明采用的技术方案如下:提供基于大数据的氢能产业链风险监测系统及监测方法,包括如下步骤:s1.1:通过传感器采集产业链内氢能相关数据;s1.2:对采集的氢能相关数据进行预处理,并将预处理结果进行存储;s1.3:对预处理后的数据进行异常监测,并将结果进行存储;s1.4:根据异常监测结果,对监测异常的数据进行告警。
5.作为本发明的一种优选技术方案:所述s1.1中,所述氢能相关数据包括制氢企业的制氢设备和运氢设备的温度、压力、倾角、泄露指数及设备周围烟雾检测环境数据。
6.作为本发明的一种优选技术方案:所述s1.2中,对氢能相关数据进行预处理包括氢能相关数据的标准化处理和氢能相关数据的数据清洗处理。
7.作为本发明的一种优选技术方案:所述氢能相关数据的标准化处理步骤如下:建立氢能相关数据样本,其中,i=1,2,
…
,n,j=1,2,
…
,m,表示第j个氢能相关设备日常检测属性第i个采集的氢能相关数据,采用标准化处理:;
其中,和分别为第j个日常监测变量的氢能数据样本均值和氢能数据样本标准差,为进行标准化处理后的氢能相关数据。
8.作为本发明的一种优选技术方案:传感器连续监测氢能相关数据,得到连续型氢能相关数据,当氢能相关数据出现缺失时,氢能相关数据则不再连续;将氢能相关数据集分为连续样本值与不连续样本值,对不连续样本值进行氢能相关数据清洗,所述氢能相关数据的清洗处理步骤如下:设中共e个氢能数据,从e个氢能数据中选择f个监测氢能样本数据,每个监测氢能样本数据为,其中,f=1,2,
…
,q;当每个氢能样本数据与变量属性间满足线性关系:;式中,,
…
,为对应监测氢能样本数据的变量属性、为监测氢能样本数据,为检测系数,,f=1,2,
…
,q为测试误差,相互独立且服从正态分布,且;通过回归方程:;式中,,
…
,、均为预测监测氢能样本数据,为估计检测系数值,为估计误差值,计算回归系数,通过回归方程对缺失氢能相关数据进行填充。
9.作为本发明的一种优选技术方案:所述s1.3中对氢能相关数据进行异常检测,从预处理后的氢能相关数据中抽取某个时长的传感器数据集r个,在氢能相关数据处理中根据传感器数据的更新对氢能相关数据进行更新迭代,取来自节点u的氢能相关数据,将氢能相关数据集中的数据根据数值与节点u的数值距离进行权重分配,其中权重,其中t=1,2,
…
,r-1,根据节点u的样本数据集的权重计算加权均值:;为来自节点u的数据均值,为来自节点u的氢能数据,为来自节点u的每个氢能数据的权重,为来自节点u的数据集个数;聚类得到:;为来自节点u的前t个氢能数据的聚类值;
得到每个数据点离散值:;其中,为前t-1个氢能数据的变化值,为节点u的第t个氢能数据变化值,其中,;其中,p为样本数据中的离散系数,为前r-1个氢能数据的离散值,根据离散系数判断氢能数据异常点。
10.作为本发明的一种优选技术方案:所述s1.4中,根据:;其中,为样本含量参数,和为监测样本的第g个和第h个氢能数据值,数据点和之间的欧式距离在特征空间中表示为:;设数据集为n各数据点的集合;整数c为类别数;满足条件;隶属度矩阵满足约束条件::;;其中,为隶属度矩阵u的第i行第j列数据值;为c个聚类中心的集合,得到目标函数::;其中,m为模糊加权指数,为模糊加权后的隶属度矩阵u的第i行第j列数据值,为集合v中的第i个聚类中心,为氢能数据的邻域,为邻域大小,为正则化系数;根据目标函数得到的函数值为氢能数据阈值,其中,正则化系数通过自适应调整目标函数值,根据风险等级设定离散系数划分阈值等级,将数据实际离散系数与设定的阈值等级相比较,当实际离散系数在正常工作范围内时,系统正常工作并存储相关数据,否则根据实际离散系数与阈值等级的关系,发出相应告警信息并进行记录。
11.算法实现阈值的自适应调整,根据风险等级设定离散系数划分阈值等级,将数据实际离散系数与设定的阈值等级相比较,当实际离散系数在正常工作范围内时,系统正常工作并存储相关数据,否则根据实际离散系数与阈值等级的关系,发出相应告警信息并进行记录。
12.提供基于大数据的氢能产业链风险监测系统:包括多个数据交互节点,所述多个数据交互节点接收告警信息并通过可视化屏幕显示,所述可视化屏幕实时显示当前节点的氢能相关数据信息,所述数据交互节点包括:数据采集模块;用于使用传感器采集产业链内各环节包含的氢能相关数据;
数据预处理模块:用于对采集的氢能相关数据进行预处理;数据监测模块:用于建立数据异常监测模型对各环节氢能相关数据进行监测;监测告警模块:用于对监测到的氢能异常数据进行告警。
13.作为本发明的一种优选技术方案:所述监测告警模块根据风险等级进行告警,并通过可视化屏幕进行显示。
14.作为本发明的一种优选技术方案:所述基于大数据的氢能产业链风险监测系统还包括数据存储模块,所述数据存储模块用于存储监测过程中的各类氢能相关数据及告警信息。
15.本发明提供的基于大数据的氢能产业链风险监测系统及监测方法,与现有技术相比,其有益效果有:本发明通过对氢能产业链中的各环节的设备运行情况及数据指标进行监测,通过数据清洗步骤对采集的数据样本中的缺失数据进行预测、填充,对当前的氢能数据进行异常检测,通过自适应调节正则化系数设置阈值划分氢能风险等级,并进行分等级告警,有助于及时采取相应措施,减少损失;并对产业链中各项数据进行记录,有利于后期对产业链的溯源监测。
附图说明
16.图1为本发明优选实施例的方法流程图;图2为本发明优选实施例中系统框图。
17.图中各个标记的意义为:100、数据采集模块;200、数据预处理模块;300、数据监测模块;400、监测告警模块;500、数据存储模块。
具体实施方式
18.需要说明的是,在不冲突的情况下,本实施例中的实施例及实施例中的特征可以相互组合,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
19.参照图1,本发明优选实施例提供了基于大数据的氢能产业链风险监测方法,包括如下步骤:s1.1:通过传感器采集产业链内氢能相关数据;s1.2:对采集的氢能相关数据进行预处理,并将预处理结果进行存储;s1.3:对预处理后的数据进行异常监测,并将结果进行存储;s1.4:根据异常监测结果,对监测异常的数据进行告警。
20.所述s1.1中,所述氢能相关数据包括制氢企业的制氢设备和运氢设备的温度、压力、倾角、泄露指数及设备周围烟雾检测环境数据。
21.所述s1.2中,对氢能相关数据进行预处理包括氢能相关数据的标准化处理和氢能相关数据的数据清洗处理。
22.所述氢能相关数据的标准化处理步骤如下:
建立氢能相关数据样本,其中,i=1,2,
…
,n,j=1,2,
…
,m,表示第j个氢能相关设备日常检测属性第i个采集的氢能相关数据,采用标准化处理:;其中,和分别为第j个日常监测变量的氢能数据样本均值和氢能数据样本标准差,为进行标准化处理后的氢能相关数据。
23.传感器连续监测氢能相关数据,得到连续型氢能相关数据,当氢能相关数据出现缺失时,氢能相关数据则不再连续;将氢能相关数据集分为连续样本值与不连续样本值,对不连续样本值进行氢能相关数据清洗,所述氢能相关数据的清洗处理步骤如下:设中共e个氢能数据,从e个氢能数据中选择f个监测氢能样本数据,每个监测氢能样本数为,其中,f=1,2,
…
,q;当每个氢能样本数据与变量属性间满足线性关系:;式中,,
…
,为对应监测氢能样本数据的变量属性、为监测氢能样本数据,为检测系数,(f=1,2,
…
,q)为测试误差,相互独立且服从正态分布,且;通过回归方程:;式中,,
…
,、均为预测监测氢能样本数据,为估计检测系数值,为估计误差值,计算回归系数,通过回归方程对缺失氢能相关数据进行填充。
24.所述s1.3中对氢能相关数据进行异常检测,从预处理后的氢能相关数据中抽取某个时长的传感器数据集r个,在氢能相关数据处理中根据传感器数据的更新对氢能相关数据进行更新迭代,取来自节点u的氢能相关数据,将氢能相关数据集中的数据根据数值与节点u的数值距离进行权重分配,其中权重,其中t=1,2,
…
,r-1,根据节点u的样本数据集的权重计算加权均值:;为来自节点u的数据均值,为来自节点u的氢能数据,为来自节点u的每个氢能数据的权重,为来自节点u的数据集个数;聚类得到:
;为来自节点u的前t个氢能数据的聚类值;得到每个数据点离散值:;其中,为前t-1个氢能数据的变化值,为节点u的第t个氢能数据变化值,其中,;其中,p为样本数据中的离散系数,为前r-1个氢能数据的离散值,根据离散系数判断氢能数据异常点。
25.所述s1.4中,根据:;其中,为样本含量参数,和为监测样本的第g个和第h个氢能数据值,数据点和之间的欧式距离在特征空间中表示为:;设数据集为n各数据点的集合;整数c为类别数;满足条件;隶属度矩阵满足约束条件::;;其中,为隶属度矩阵u的第i行第j列数据值;为c个聚类中心的集合,得到目标函数:;其中,m为模糊加权指数,为模糊加权后的隶属度矩阵u的第i行第j列数据值,为集合v中的第i个聚类中心,为氢能数据的邻域,为邻域大小,为正则化系数;根据目标函数得到的函数值为氢能数据阈值,其中,正则化系数通过自适应调整目标函数值,根据风险等级设定离散系数划分阈值等级,将数据实际离散系数与设定的阈值等级相比较,当实际离散系数在正常工作范围内时,系统正常工作并存储相关数据,否则根据实际离散系数与阈值等级的关系,发出相应告警信息并进行记录。
26.提供基于大数据的氢能产业链风险监测系统,包括多个数据交互节点,所述多个数据交互节点接收告警信息并通过可视化屏幕显示,所述可视化屏幕实时显示当前节点的氢能相关数据信息,所述数据交互节点包括:数据采集模块100;用于使用传感器采集产业链内各环节包含的氢能相关数据;数据预处理模块200:用于对采集的氢能相关数据进行预处理;
数据监测模块300:用于建立数据异常监测模型对各环节氢能相关数据进行监测;监测告警模块400:用于对监测到的氢能异常数据进行告警。
27.所述监测告警模块400根据风险等级进行告警,并通过可视化屏幕进行显示。
28.所述基于大数据的氢能产业链风险监测系统还包括数据存储模块500,所述数据存储模块500用于存储监测过程中的各类氢能相关数据及告警信息。
29.本实施例中,以氢能产业链中氢燃料电池公交车氢能风险监测为例。
30.数据采集模块100使用传感器采集氢燃料电池公交车的各项氢能相关数据并实时更新;数据预处理模块200对采集的氢能相关数据进行数据标准化处理:以氢能源公交车排气管处氢能相关数据检测为例,设定其温度为第1个氢能相关设备日常检测属性,压力为第2个氢能相关设备日常检测属性,倾角为第三个氢能相关设备日常检测属性,泄露指数为第5个氢能相关设备日常检测属性,烟雾环境检测环境数据为第6个氢能相关设备日常检测属性,即j=1,收集氢能相关数据样本;对六中检测属性值分别进行标准化处理得到六种属性数据的标准化处理值,以j=1、2为例,其中,j=1时,即温度属性单位为摄氏度,j=2时,即压力属性单位为kpa。
31.建立氢能相关数据样本,其中,i=1,2,
…
,n,j=1,2,
…
,m,表示第j个氢能相关设备日常检测属性第i个采集的氢能相关数据,采用标准化处理:;其中,和分别为第j个日常监测变量的氢能数据样本均值和氢能数据样本标准差,为进行标准化处理后的氢能相关数据。
32.数据标准化处理完成后监测数据的完整性,传感器每分钟监测连续监测一次氢能相关数据,得到时间连续的排气管处氢气样本温度属性数据,监测仅发现排气管处氢气样本温度属性数据出现缺失,氢气样本数据则不再连续;将其分为连续样本集和不连续样本,当数据不完整时,通过数据清洗补充缺失数据:不连续样本集中共4个温度属性数据,选取这4个样本数据;当每个氢能样本数据与变量属性间满足线性关系:;式中,为对应监测氢能样本数据的采样时间、为温度属性数据,为检测系数,(f=1,2,
…
,4)为测试误差;通过回归方程:
;式中,为检测时间、均为预测温度属性数据,为估计检测系数值,为估计误差值,计算回归系数,通过回归方程根据监测到的排气管处氢气数据样本对缺失的氢能相关数据的排气管处氢气温度属性数据样本进行预测得到数据,并根据预测结果对缺失的温度属性数据的排气管处氢气温度属性数据样本值进行填充得到。
33.数据气体扩散过程中,监测的数据不可能出现突变情况,所以通过数据清洗操作可以很好的保证数据的有效性。
34.缺失数据填充完成后,通过数据监测模块300建立数据异常监测模型对各氢能相关数据进行实时监测,实时监测数据中是否存在异常数据。
35.从预处理后的氢能源公交车排气管处温度、压力、倾角、泄露指数及设备周围烟雾检测环境数据中抽取一个小时内的传感器数据集各60个,在氢能相关数据处理中根据传感器数据的更新对氢能相关数据进行更新迭代,取来自排气管尾端节点u的氢能相关数据,将氢能相关数据集中的数据根据数值与节点u的数值距离进行权重分配,其中权重,其中;根据节点u的样本数据集的权重计算加权均值:;为来自节点u的数据均值,为来自节点u的氢能数据,为来自节点u的每个氢能数据的权重,为来自节点u的数据集个数;聚类得到:;为来自节点u的前t个氢能数据的聚类值;得到每个数据点离散值:;其中,为前t-1个氢能数据的变化值,为节点u的第t个氢能数据变化值,其中,;其中,p为样本数据中的离散系数。为前r-1个氢能数据的离散值,将每一个样本数据都与前59个样本数据作为一个数据集计算它的变化值得到离散系数p。
36.根据离散系数p判断氢能数据异常点。根据:
;其中,为样本含量参数,和为监测样本的第g个和第h个氢能数据值,数据点和之间的欧式距离在特征空间中表示为:;设数据集为n各数据点的集合;整数c为类别数;满足条件;隶属度矩阵满足约束条件::;;其中,为隶属度矩阵u的第i行第j列数据值;为c个聚类中心的集合,得到目标函数:;其中,m为模糊加权指数,为模糊加权后的隶属度矩阵u的第i行第j列数据值,为集合v中的第i个聚类中心,为氢能数据的邻域,为邻域大小,为正则化系数;上述目标函数根据采集的氢能样本数据按照相似性准则将其划分成若干子类中,使同类样本数据差异尽可能小,例如根据属性将数据划分成六类,可以再根据采样时间划分成多个子类。再选择聚类中心,然后根据样本与聚类中心的距离,将样本划分到该类中,再重新调整聚类中心即目标函数,直至每个样本距聚类中心的距离最小,得到的目标函数即为最合适的样本阈值。代入不同属性、不同时间的数据即得到对应的不同属性、不同时间的数据的样本阈值。
37.根据目标函数得到的函数值即为设置的氢能数据阈值,其中,正则化系数通过自适应调整目标函数值,当监测当前位置的氢气浓度降低速度较快时,可通过调节正则化系数自适应调节当前位置的氢气浓度阈值,根据当前节点所处环境自适应调节正则化系数,得到调节的目标函数值,根据自适应调节的目标函数值比例划分风险等级并进行异常检测中,得到根据风险等级划分的离散系数阈值,将数据实际离散系数与设定的阈值等级相比较,当实际离散系数在正常工作范围内时,系统正常工作并存储相关数据,否则根据实际离散系数与阈值等级的关系,发出相应告警信息并进行记录。
38.例如在车辆排气管上的氢气泄露监测传感器监测空气氢气聚集浓度,当监测空气中氢气含量超过1
‰
时,定为低于为轻度风险,当监测空气中氢气含量超过5
‰
时,定为低于为中度风险,当监测空气中氢气含量超过1%时,定为高度风险。当监测的实时空气中的氢气含量数据高于1
‰
时,可视化屏幕显示黄色,提示司机需要注意,当监测的实时空气中的氢气含量数据高于5
‰
时,可视化屏幕低频闪烁橙色警示灯并发出警报,提示司机需要立即停车检查,当监测的实时空气中的氢气含量数据高于1%时,可视化屏幕高频闪烁红色警示灯并发出全车警报,并立即关闭车辆电磁阀,提醒司机远离车辆。
39.对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权
利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
40.此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。