1.本公开涉及语音识别技术领域,特别是涉及一种基于亲密度的语音识别模型训练方法、装置及设备。
背景技术:
2.自动语音识别asr(automaticspeechrecognition)是基于人类的语音,通过语音信号处理和模式识别自动识别语音中的内容,进而可以使得电子设备能够快速、便捷地根据用户语音执行相应的操作,从而解放了人类的双手,提高了用户使用电子设备的方式,然而在语义解析时单独的语音识别准确性较低,造成查询内容的召回率和准确率较低。
3.现有的语音识别方法种类比较多,例如,基于全变量(total variability,tv)的语音识别方法,基于因子分析技术的语音识别方法、基于端到端(end2end)的语种识别框架的语音识别方法,但是上述方法始终无法将不同区域的语音进行转换,使不同区域的人能够正常进行语音交流。
4.有鉴于此,如何识别不同区域的用户语音,从而克服语言难以听懂的障碍成为亟待解决的问题。
技术实现要素:
5.基于此,有必要针对如何识别不同区域的用户语音,从而克服语言难以听懂的障碍成为亟待解决的问题,提供一种基于亲密度的语音识别模型训练方法、装置及设备。
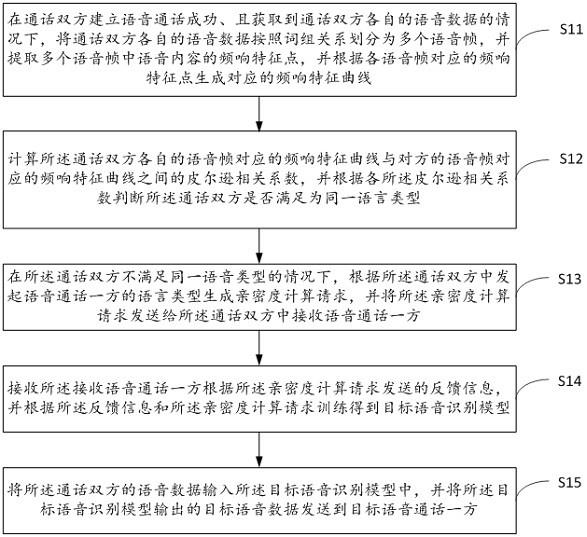
6.本公开第一方面,提供一种基于亲密度的语音识别模型训练方法,所述方法应用于语音识别系统,所述方法包括:在通话双方建立语音通话成功、且获取到所述通话双方各自的语音数据的情况下,将所述通话双方各自的语音数据按照词组关系划分为多个语音帧,并提取所述多个语音帧中语音内容的频响特征点,并根据各语音帧对应的频响特征点生成对应的频响特征曲线;计算所述通话双方各自的语音帧对应的频响特征曲线与对方的语音帧对应的频响特征曲线之间的皮尔逊相关系数,并根据各所述皮尔逊相关系数判断所述通话双方是否满足为同一语言类型,其中,所述语言类型是根据使用不同种类的语言的区域所属的语言分区进行排序后确定的;在所述通话双方不满足同一语音类型的情况下,根据所述通话双方中发起语音通话一方的语言类型生成亲密度计算请求,并将所述亲密度计算请求发送给所述通话双方中接收语音通话一方;接收所述接收语音通话一方根据所述亲密度计算请求发送的反馈信息,并根据所述反馈信息和所述亲密度计算请求训练得到目标语音识别模型;将所述通话双方的语音数据输入所述目标语音识别模型中,并将所述目标语音识别模型输出的目标语音数据发送到目标语音通话一方,所述目标语音通话一方为所述通话
双方中当前接收语音的一方。
7.在其中一个实施例中,所述根据所述反馈信息和所述亲密度计算请求训练得到目标语音识别模型的步骤,包括:根据所述反馈信息中携带的所述接收语音通话一方的亲密性语言类型以及所述亲密度计算请求中携带的所述发起语音通话一方的亲密性语言类型,计算所述通话双方的亲密度;根据所述亲密度更新语音识别模型的损失函数,并根据所述反馈信息中携带的接收语音通话一方的地区性语言种类以及所述亲密度计算请求中携带的发起语音通话一方的地区性语言种类,对更新损失函数后的语音识别模型进行训练,得到所述目标语音识别模型。
8.在其中一个实施例中,所述反馈信息中携带的亲密性语言类型是通过如下方式生成的:根据所述亲密度计算请求中携带的发起语音通话一方的地区性语言种类,查询所述接收语音通话一方的历史通话对象中是否存在与所述发起语音通话一方的地区性语言种类相同的目标历史通话对象;在所述历史通话对象中存在与所述发起语音通话一方的地区性语言种类相同的目标历史通话对象的情况下,根据所述接收语音通话一方与所述目标历史通话对象的通话频率以及通话时长,从预设的人物属性数据库以及对话语句数据库中筛选符合所述接收语音通话一方的语言风格以及语言片段;基于lovins算法,对所述语言风格以及语言片段进行除梗预处理;将所述语言片段输入到孤立森林模型中,以得到所述孤立森林模型输出的每一语言片段的预测分类值,其中,所述孤立森林模型中每一孤立树的分类类型均不同;根据预设的语言风格与权重值的对应关系,确定所述每一所述孤立树对应的目标权重值,并根据所述目标权重值以及所述预测分类值,确定所述反馈信息中携带的亲密性语言类型。
9.在其中一个实施例中,所述将所述通话双方的语音数据输入目标语音识别模型中,并将所述目标语音识别模型输出的目标语音数据发送到目标语音通话一方的步骤,包括:在所述通话双方的语音数据来自所述发起语音通话一方的情况下,将所述发起语音通话一方的语音数据输入所述目标语音识别模型中,以得到语言类型与所述接收语音通话一方的语言类型一致的目标语音数据,并将所述目标语音识别模型输出的目标语音数据发送到所述接收语音通话一方;或者,在所述通话双方的语音数据来自所述接收语音通话一方的情况下,将所述接收语音通话一方的语音数据输入所述目标语音识别模型中,以得到语言类型与所述发起语音通话一方的语言类型一致的目标语音数据,并将所述目标语音识别模型输出的目标语音数据发送到所述发起语音通话一方。
10.在其中一个实施例中,所述语言分区是通过如下方式进行划分的:按照第一区划级别排序,将若干区划字段中的若干第一区划字段与数据库中的语言区划映射表进行匹配,得到第一候选语言区划集合,其中,所述语言区划映射表中包括多
级行政区划以及所述多级行政区划之间的语言相似度,所述语言相似度是根据发音方式以及词语使用频率进行确定的;确定所述第一候选语言区划集合是否满足预设的不可再分条件,其中,所述不可再分条件为所述候选语言区划内用户只使用一种语言,如果否,则按照第二区划级别排序,将所述候选语言区划集合中的第二区划字段与所述语言区划映射表再次进行匹配,得到第二候选语言区划集合;确定所述第二候选语言区划集合是否满足所述不可再分条件,如果否,则按照第三区划级别排序,将所述候选语言区划集合中的第三区划字段与所述语言区划映射表再次进行匹配,得到第三候选语言区划集合,直到新得到的候选语言区划集合满足所述不可再分条件。
11.本公开第二方面,提供一种基于亲密度的语音识别模型训练装置,包括:划分模块,被配置为在通话双方建立语音通话成功、且获取到所述通话双方各自的语音数据的情况下,将所述通话双方各自的语音数据按照词组关系划分为多个语音帧,并提取所述多个语音帧中语音内容的频响特征点,并根据各语音帧对应的频响特征点生成对应的频响特征曲线;计算模块,被配置为计算所述通话双方各自的语音帧对应的频响特征曲线与对方的语音帧对应的频响特征曲线之间的皮尔逊相关系数,并根据各所述皮尔逊相关系数判断所述通话双方是否满足为同一语言类型,其中,所述语言类型是根据使用语音的区域所属的行政区域进行排序后确定的;发送模块,被配置为在所述通话双方不满足同一语音类型的情况下,根据所述通话双方中发起语音通话一方的语言类型生成亲密度计算请求,并将所述亲密度计算请求发送给所述通话双方中接收语音通话一方;接收模块,被配置为接收所述接收语音通话一方根据所述亲密度计算请求发送的反馈信息,并根据所述反馈信息和所述亲密度计算请求训练得到目标语音识别模型;执行模块,被配置为将所述通话双方的语音数据输入所述目标语音识别模型中,并将所述目标语音识别模型输出的目标语音数据发送到目标语音通话一方,所述目标语音通话一方为所述通话双方中当前接收语音的一方。
12.在其中一个实施例中,所述接收模块,包括:第一计算子模块,被配置为根据所述反馈信息中携带的所述接收语音通话一方的亲密性语言类型以及所述亲密度计算请求中携带的所述发起语音通话一方的亲密性语言类型,计算所述通话双方的亲密度;更新子模块,被配置为根据所述亲密度更新语音识别模型的损失函数,并根据所述反馈信息中携带的接收语音通话一方的地区性语言种类以及所述亲密度计算请求中携带的发起语音通话一方的地区性语言种类,对更新损失函数后的语音识别模型进行训练,得到所述目标语音识别模型。
13.在其中一个实施例中,所述反馈信息中携带的亲密性语言类型是通过如下方式生成的:根据所述亲密度计算请求中携带的发起语音通话一方的地区性语言种类,查询所述接收语音通话一方的历史通话对象中是否存在与所述发起语音通话一方的地区性语言
种类相同的目标历史通话对象;在所述历史通话对象中存在与所述发起语音通话一方的地区性语言种类相同的目标历史通话对象的情况下,根据所述接收语音通话一方与所述目标历史通话对象的通话频率以及通话时长,从预设的人物属性数据库以及对话语句数据库中筛选符合所述接收语音通话一方的语言风格以及语言片段;基于lovins算法,对所述语言风格以及语言片段进行除梗预处理;将所述语言片段输入到孤立森林模型中,以得到所述孤立森林模型输出的每一语言片段的预测分类值,其中,所述孤立森林模型中每一孤立树的分类类型均不同;根据预设的语言风格与权重值的对应关系,确定所述每一所述孤立树对应的目标权重值,并根据所述目标权重值以及所述预测分类值,确定所述反馈信息中携带的亲密性语言类型。
14.在其中一个实施例中,所述执行模块,被配置为:在所述通话双方的语音数据来自所述发起语音通话一方的情况下,将所述发起语音通话一方的语音数据输入所述目标语音识别模型中,以得到语言类型与所述接收语音通话一方的语言类型一致的目标语音数据,并将所述目标语音识别模型输出的目标语音数据发送到所述接收语音通话一方;或者,在所述通话双方的语音数据来自所述接收语音通话一方的情况下,将所述接收语音通话一方的语音数据输入所述目标语音识别模型中,以得到语言类型与所述发起语音通话一方的语言类型一致的目标语音数据,并将所述目标语音识别模型输出的目标语音数据发送到所述发起语音通话一方。
15.在其中一个实施例中,所述语言分区是通过如下方式进行划分的:按照第一区划级别排序,将若干区划字段中的若干第一区划字段与数据库中的语言区划映射表进行匹配,得到第一候选语言区划集合,其中,所述语言区划映射表中包括多级行政区划以及所述多级行政区划之间的语言相似度,所述语言相似度是根据发音方式以及词语使用频率进行确定的;确定所述第一候选语言区划集合是否满足预设的不可再分条件,其中,所述不可再分条件为所述候选语言区划内用户只使用一种语言,如果否,则按照第二区划级别排序,将所述候选语言区划集合中的第二区划字段与所述语言区划映射表再次进行匹配,得到第二候选语言区划集合;确定所述第二候选语言区划集合是否满足所述不可再分条件,如果否,则按照第三区划级别排序,将所述候选语言区划集合中的第三区划字段与所述语言区划映射表再次进行匹配,得到第三候选语言区划集合,直到新得到的候选语言区划集合满足所述不可再分条件。
16.本公开第三方面,提供一种电子设备,包括:存储器,其上存储有计算机程序;处理器,用于执行所述存储器中的所述计算机程序,以实现第一方面中任意一项所述基于亲密度的语音识别模型训练方法的步骤。
17.上述基于亲密度的语音识别模型训练方法通过在通话双方建立语音通话成功、且获取到通话双方各自的语音数据的情况下,将通话双方各自的语音数据按照词组关系划分
为多个语音帧,并提取多个语音帧中语音内容的频响特征点,并根据各语音帧对应的频响特征点生成对应的频响特征曲线;计算通话双方各自的语音帧对应的频响特征曲线与对方的语音帧对应的频响特征曲线之间的皮尔逊相关系数,并根据各皮尔逊相关系数判断通话双方是否满足为同一语言类型,其中,语言类型是根据使用不同种类的语言的区域所属的语言分区进行排序后确定的;在通话双方不满足同一语音类型的情况下,根据通话双方中发起语音通话一方的语言类型生成亲密度计算请求,并将亲密度计算请求发送给通话双方中接收语音通话一方;接收语音通话一方根据亲密度计算请求发送的反馈信息,并根据反馈信息和亲密度计算请求训练得到目标语音识别模型;将通话双方的语音数据输入目标语音识别模型中,并将目标语音识别模型输出的目标语音数据发送到目标语音通话一方,目标语音通话一方为通话双方中当前接收语音的一方。可以识别不同区域的用户语音,从而克服语言难以听懂的障碍,从而提高了通话的灵活性和便携性,进而提升了用户体验。
附图说明
18.图1为其中一个实施例的基于亲密度的语音识别模型训练方法的流程图。
19.图2为其中一个实施例的实现图1中步骤s14的流程图。
20.图3为其中一个实施例的基于亲密度的语音识别模型训练装置的框图。
具体实施方式
21.为使本公开的上述目的、特征和优点能够更加明显易懂,下面结合附图对本公开的具体实施方式做详细的说明。在下面的描述中阐述了很多具体细节以便于充分理解本公开。但是本公开能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本公开内涵的情况下做类似改进,因此本公开不受下面公开的具体实施例的限制。
22.此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。
23.图1为其中一个实施例的基于亲密度的语音识别模型训练方法的流程图,所述方法应用于语音识别系统,如图1所示,该方法包括以下步骤:在步骤s11中,在通话双方建立语音通话成功、且获取到所述通话双方各自的语音数据的情况下,将所述通话双方各自的语音数据按照词组关系划分为多个语音帧,并提取所述多个语音帧中语音内容的频响特征点,并根据各语音帧对应的频响特征点生成对应的频响特征曲线;在步骤s12中,计算所述通话双方各自的语音帧对应的频响特征曲线与对方的语音帧对应的频响特征曲线之间的皮尔逊相关系数,并根据各所述皮尔逊相关系数判断所述通话双方是否满足为同一语言类型,其中,所述语言类型是根据使用不同种类的语言的区域所属的语言分区进行排序后确定的;在步骤s13中,在所述通话双方不满足同一语音类型的情况下,根据所述通话双方中发起语音通话一方的语言类型生成亲密度计算请求,并将所述亲密度计算请求发送给所述通话双方中接收语音通话一方;在步骤s14中,接收所述接收语音通话一方根据所述亲密度计算请求发送的反馈
信息,并根据所述反馈信息和所述亲密度计算请求训练得到目标语音识别模型;在步骤s15中,将所述通话双方的语音数据输入所述目标语音识别模型中,并将所述目标语音识别模型输出的目标语音数据发送到目标语音通话一方,所述目标语音通话一方为所述通话双方中当前接收语音的一方。
24.上述基于亲密度的语音识别模型训练方法通过在通话双方建立语音通话成功、且获取到通话双方各自的语音数据的情况下,将通话双方各自的语音数据按照词组关系划分为多个语音帧,并提取多个语音帧中语音内容的频响特征点,并根据各语音帧对应的频响特征点生成对应的频响特征曲线;计算通话双方各自的语音帧对应的频响特征曲线与对方的语音帧对应的频响特征曲线之间的皮尔逊相关系数,并根据各皮尔逊相关系数判断通话双方是否满足为同一语言类型,其中,语言类型是根据使用不同种类的语言的区域所属的语言分区进行排序后确定的;在通话双方不满足同一语音类型的情况下,根据通话双方中发起语音通话一方的语言类型生成亲密度计算请求,并将亲密度计算请求发送给通话双方中接收语音通话一方;接收语音通话一方根据亲密度计算请求发送的反馈信息,并根据反馈信息和亲密度计算请求训练得到目标语音识别模型;将通话双方的语音数据输入目标语音识别模型中,并将目标语音识别模型输出的目标语音数据发送到目标语音通话一方,目标语音通话一方为通话双方中当前接收语音的一方。可以识别不同区域的用户语音,从而克服语言难以听懂的障碍,从而提高了通话的灵活性和便携性,进而提升了用户体验。
25.在其中一个实施例中,图2为其中一个实施例的实现图1中步骤s14的流程图,在步骤s14中,所述根据所述反馈信息和所述亲密度计算请求训练得到目标语音识别模型的步骤,包括:在步骤s141中,根据所述反馈信息中携带的所述接收语音通话一方的亲密性语言类型以及所述亲密度计算请求中携带的所述发起语音通话一方的亲密性语言类型,计算所述通话双方的亲密度;在步骤s142中,根据所述亲密度更新语音识别模型的损失函数,并根据所述反馈信息中携带的接收语音通话一方的地区性语言种类以及所述亲密度计算请求中携带的发起语音通话一方的地区性语言种类,对更新损失函数后的语音识别模型进行训练,得到所述目标语音识别模型。
26.在其中一个实施例中,所述反馈信息中携带的亲密性语言类型是通过如下方式生成的:根据所述亲密度计算请求中携带的发起语音通话一方的地区性语言种类,查询所述接收语音通话一方的历史通话对象中是否存在与所述发起语音通话一方的地区性语言种类相同的目标历史通话对象;在所述历史通话对象中存在与所述发起语音通话一方的地区性语言种类相同的目标历史通话对象的情况下,根据所述接收语音通话一方与所述目标历史通话对象的通话频率以及通话时长,从预设的人物属性数据库以及对话语句数据库中筛选符合所述接收语音通话一方的语言风格以及语言片段;基于lovins算法,对所述语言风格以及语言片段进行除梗预处理;将所述语言片段输入到孤立森林模型中,以得到所述孤立森林模型输出的每一语言片段的预测分类值,其中,所述孤立森林模型中每一孤立树的分类类型均不同;
根据预设的语言风格与权重值的对应关系,确定所述每一所述孤立树对应的目标权重值,并根据所述目标权重值以及所述预测分类值,确定所述反馈信息中携带的亲密性语言类型。
27.在其中一个实施例中,所述将所述通话双方的语音数据输入目标语音识别模型中,并将所述目标语音识别模型输出的目标语音数据发送到目标语音通话一方的步骤,包括:在所述通话双方的语音数据来自所述发起语音通话一方的情况下,将所述发起语音通话一方的语音数据输入所述目标语音识别模型中,以得到语言类型与所述接收语音通话一方的语言类型一致的目标语音数据,并将所述目标语音识别模型输出的目标语音数据发送到所述接收语音通话一方;或者,在所述通话双方的语音数据来自所述接收语音通话一方的情况下,将所述接收语音通话一方的语音数据输入所述目标语音识别模型中,以得到语言类型与所述发起语音通话一方的语言类型一致的目标语音数据,并将所述目标语音识别模型输出的目标语音数据发送到所述发起语音通话一方。
28.在其中一个实施例中,所述语言分区是通过如下方式进行划分的:按照第一区划级别排序,将若干区划字段中的若干第一区划字段与数据库中的语言区划映射表进行匹配,得到第一候选语言区划集合,其中,所述语言区划映射表中包括多级行政区划以及所述多级行政区划之间的语言相似度,所述语言相似度是根据发音方式以及词语使用频率进行确定的;确定所述第一候选语言区划集合是否满足预设的不可再分条件,其中,所述不可再分条件为所述候选语言区划内用户只使用一种语言,如果否,则按照第二区划级别排序,将所述候选语言区划集合中的第二区划字段与所述语言区划映射表再次进行匹配,得到第二候选语言区划集合;确定所述第二候选语言区划集合是否满足所述不可再分条件,如果否,则按照第三区划级别排序,将所述候选语言区划集合中的第三区划字段与所述语言区划映射表再次进行匹配,得到第三候选语言区划集合,直到新得到的候选语言区划集合满足所述不可再分条件。
29.本公开还提供一种基于亲密度的语音识别模型训练装置,图3为其中一个实施例的基于亲密度的语音识别模型训练装置的框图,参见图3所示,所述装置300包括:划分模块310,被配置为在通话双方建立语音通话成功、且获取到所述通话双方各自的语音数据的情况下,将所述通话双方各自的语音数据按照词组关系划分为多个语音帧,并提取所述多个语音帧中语音内容的频响特征点,并根据各语音帧对应的频响特征点生成对应的频响特征曲线;计算模块320,被配置为计算所述通话双方各自的语音帧对应的频响特征曲线与对方的语音帧对应的频响特征曲线之间的皮尔逊相关系数,并根据各所述皮尔逊相关系数判断所述通话双方是否满足为同一语言类型,其中,所述语言类型是根据使用语音的区域所属的行政区域进行排序后确定的;发送模块330,被配置为在所述通话双方不满足同一语音类型的情况下,根据所述通话双方中发起语音通话一方的语言类型生成亲密度计算请求,并将所述亲密度计算请求
发送给所述通话双方中接收语音通话一方;接收模块340,被配置为接收所述接收语音通话一方根据所述亲密度计算请求发送的反馈信息,并根据所述反馈信息和所述亲密度计算请求训练得到目标语音识别模型;执行模块350,被配置为将所述通话双方的语音数据输入所述目标语音识别模型中,并将所述目标语音识别模型输出的目标语音数据发送到目标语音通话一方,所述目标语音通话一方为所述通话双方中当前接收语音的一方。
30.在其中一个实施例中,所述接收模块340,包括:第一计算子模块,被配置为根据所述反馈信息中携带的所述接收语音通话一方的亲密性语言类型以及所述亲密度计算请求中携带的所述发起语音通话一方的亲密性语言类型,计算所述通话双方的亲密度;更新子模块,被配置为根据所述亲密度更新语音识别模型的损失函数,并根据所述反馈信息中携带的接收语音通话一方的地区性语言种类以及所述亲密度计算请求中携带的发起语音通话一方的地区性语言种类,对更新损失函数后的语音识别模型进行训练,得到所述目标语音识别模型。
31.在其中一个实施例中,所述反馈信息中携带的亲密性语言类型是通过如下方式生成的:根据所述亲密度计算请求中携带的发起语音通话一方的地区性语言种类,查询所述接收语音通话一方的历史通话对象中是否存在与所述发起语音通话一方的地区性语言种类相同的目标历史通话对象;在所述历史通话对象中存在与所述发起语音通话一方的地区性语言种类相同的目标历史通话对象的情况下,根据所述接收语音通话一方与所述目标历史通话对象的通话频率以及通话时长,从预设的人物属性数据库以及对话语句数据库中筛选符合所述接收语音通话一方的语言风格以及语言片段;基于lovins算法,对所述语言风格以及语言片段进行除梗预处理;将所述语言片段输入到孤立森林模型中,以得到所述孤立森林模型输出的每一语言片段的预测分类值,其中,所述孤立森林模型中每一孤立树的分类类型均不同;根据预设的语言风格与权重值的对应关系,确定所述每一所述孤立树对应的目标权重值,并根据所述目标权重值以及所述预测分类值,确定所述反馈信息中携带的亲密性语言类型。
32.在其中一个实施例中,所述执行模块350,被配置为:在所述通话双方的语音数据来自所述发起语音通话一方的情况下,将所述发起语音通话一方的语音数据输入所述目标语音识别模型中,以得到语言类型与所述接收语音通话一方的语言类型一致的目标语音数据,并将所述目标语音识别模型输出的目标语音数据发送到所述接收语音通话一方;或者,在所述通话双方的语音数据来自所述接收语音通话一方的情况下,将所述接收语音通话一方的语音数据输入所述目标语音识别模型中,以得到语言类型与所述发起语音通话一方的语言类型一致的目标语音数据,并将所述目标语音识别模型输出的目标语音数据发送到所述发起语音通话一方。
33.在其中一个实施例中,所述语言分区是通过如下方式进行划分的:
按照第一区划级别排序,将若干区划字段中的若干第一区划字段与数据库中的语言区划映射表进行匹配,得到第一候选语言区划集合,其中,所述语言区划映射表中包括多级行政区划以及所述多级行政区划之间的语言相似度,所述语言相似度是根据发音方式以及词语使用频率进行确定的;确定所述第一候选语言区划集合是否满足预设的不可再分条件,其中,所述不可再分条件为所述候选语言区划内用户只使用一种语言,如果否,则按照第二区划级别排序,将所述候选语言区划集合中的第二区划字段与所述语言区划映射表再次进行匹配,得到第二候选语言区划集合;确定所述第二候选语言区划集合是否满足所述不可再分条件,如果否,则按照第三区划级别排序,将所述候选语言区划集合中的第三区划字段与所述语言区划映射表再次进行匹配,得到第三候选语言区划集合,直到新得到的候选语言区划集合满足所述不可再分条件。
34.本公开实施例还提供一种电子设备,包括:存储器,其上存储有计算机程序;处理器,用于执行所述存储器中的所述计算机程序,以实现上述实施例中任意一项所述基于亲密度的语音识别模型训练方法的步骤。
35.以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
36.以上所述实施例仅表达了本公开的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对公开专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本公开构思的前提下,还可以做出若干变形和改进,这些都属于本公开的保护范围。因此,本公开专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。