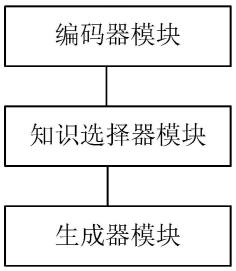
1.本发明涉及开放域对话生成-自然语言处理技术领域,具体为一种基于外部知识的电网客服对话生成方法及装置。
背景技术:
2.在开放域对话生成技术中,基于外部知识的对话生成技术近年来受到了广泛的关注。基于外部知识的对话生成技术也称知识型对话生成技术,由两个子任务组成:知识选择,回复生成。现有工作主要有两个改进方向:提升知识选择准确率,提升知识感知的回复生成模块。第一类改进方向通过挖掘对话历史中的潜在特征以及引入后验知识提升知识选择准确率。如meng等人设计了一个基于对偶学习范式下的知识选择网络(chuan meng,pengjie ren,zhumin chen,weiwei sun,zhaochun ren,zhaopeng tu,and maarten de rijke.2020.dukenet:a dual knowledge interaction network for knowledge-grounded conversation.in proceedings of the 43rd international acm sigir conference on research and development in information retrieval,sigir 2020,virtual event,china,july 25-30,2020,pages 1151
–
1160.acm),将知识追踪和知识转移当作一对对偶任务,在训练过程中互相提供反馈信息,实现两个模块性能的共同提升。zheng等人考虑了两轮对话间知识的差异性(chujie zheng,yunbo cao,daxin jiang,and minlie huang.2020.difference-aware knowledge selection for knowledge-grounded conversation generation.in findings of the association for computational linguistics:emnlp 2020,pages 115
–
125,online.association for computational linguistics.),知识在对话中的转移既不能太突兀,也不能完全一致产生重复,利用此特征作者设计了一个知识差异感知的选择器。kim等人根据条件变分自编码器(cvae)的思想设计了一个序列隐变量模型(byeongchang kim,jaewoo ahn,and gunhee kim.2020.sequential latent knowledge selection for knowledge-grounded dialogue.in 8th international conference on learning representations,iclr 2020,addis ababa,ethiopia,april 26-30,2020.openreview.net.),将整个对话回合当作序列知识选择的过程,提高了知识选择的多样性。zhan等人发现不仅知识选择阶段可以通过从隐空间采样隐变量提升多样性,在对话生成阶段使用此技巧同样可以提升回复生成的多样性,因此他们提出了一个协同隐变量模型(haolan zhan,leishen,hongshen chen,hainan zhang.2021.colv:a collaborative latent variable model for knowledge-grounded dialogue generation.emnlp(1)2021:2250-2261)。第二类改进方向考虑如何更好地利用模型在第一阶段选到的知识,将知识信息高效融入到回复中。由于黄金知识中存在词语级别噪声,这些噪声信息会降低回复生成的质量,zheng等人设计了一个词语级别去噪发明(wen zheng,natasa milic-frayling,and ke zhou.2021.knowledge-grounded dialogue generation with termlevel de-noising.in findings of the association for computational linguistics:acl-ijcnlp 2021,pages 2972
–
2983,
online.association for computational linguistics.),通过改进损失函数,利用注意力机制(attention)让模型更关注标准回复中出现过的知识词语,提高了生成质量。zhao等人引入预训练生成模型gpt-2作为生成器,并在segment嵌入层对知识、对话历史、回复做了标记,以提高生成效果(xueliang zhao,wei wu,can xu,chongyang tao,dongyan zhao,and rui yan.2020b.knowledge grounded dialogue generation with pre-trained language models.in proceedings of the 2020 conference on empirical methods in natural language processing(emnlp),pages 3377
–
3390.association for computational linguistics)。
3.现有的知识选择技术大多直接将整个对话历史不加处理的传给知识选择器构造查询向量,并利用该查询向量选择候选知识,这种做法平等的对待了所有的历史信息。然而,对话历史中的各部分信息起着不同的作用,在不同的对话回合中,同一语句既可能含有关键信息也可能对本回合的知识选择带来负面的噪声影响。仅依赖模型难以从冗杂的历史信息中提取最合适的信息检索当前轮知识,需要人为引入一些先验知识辅助模型过滤噪声信息。从meng等人的工作中的发明可以看到(chuan meng,pengjie ren,zhumin chen,zhaochun ren,tengxiao xi,and maarten de rijke.2021.initiative-aware self-supervised learning for knowledge-grounded conversations.in proceedings of the 44th international acm sigir conference on research and development in information retrieval(sigir’21),july 11
–
15,2021,virtual event,canada.acm,new york,ny,usa,11pages),通过引入主导性特征对知识选择器解耦合,每个知识选择器只利用对话历史中的部分信息,可以有效提高模型对历史信息的应用效率并减少噪声干扰。多轮对话中存在用户方和系统方,一般而言用户方是更积极的一方,主导着话题的方向;系统方即代理方,需要接住用户方抛出的话题将对话继续并且尽可能做出知识性、趣味性强的回复。在用户积极的对话回合,用户当前的消息中含有更多关键信息,应该用于构造查询向量;否则,应该基于以前对话回合中的历史知识找一个相近话题继续对话。
4.基于上述调研和观察,本技术发现目前的知识型对话研究工作仍然存在几点待改善问题
5.1)对话中的主导性特征并不是影响知识选择过程的内在原因,由于主导性需要依靠话题在相邻两轮中的变化做判断,所以话题才是影响知识选择的根本原因。
6.2)主导性标签难以通过经验进行标注,往往只能通过人工方法逐条标记,这在具体应用时过于耗费人力资源,而以往发明中的自监督方法准确性又一般。
技术实现要素:
7.针对以上问题,本发明公开了一种基于外部知识的电网客服对话生成方法及装置,所述方法通过设计的话题转移/话题继承知识选择器,可以更准确地构造查询向量,提升客服回复的准确率。
8.本发明的技术内容包括:
9.一种基于外部知识的客服对话生成方法,所述方法包括:
10.针对客服对话中第t轮的用户消息x
t
,获取知识库历史轮的知识{k
′1,
…
,k
′
t-1
}和历史轮知识的高维表征
11.将用户消息x
t
与知识库中的每一候选知识分别拼接,并利用bert编码器,分别计算每一拼接结果的标志位[cls]的隐向量表示候选知识的高维语义表征以及用户消息x
t
的高维语义表征其中,i表示知识库中候选知识的序号;
[0012]
基于所述用户消息高维语义表征与所述历史轮知识高维表征集合预测本轮对话话题发生转移的概率以确定进行话题转移计算或话题继承计算,得到用户消息x
t
对应的候选知识概率分布;
[0013]
综合所述候选知识概率分布与所述对话x
t
,生成第t轮的回复。
[0014]
进一步地,所述将用户消息x
t
与知识库中的每一候选知识分别拼接,并利用bert编码器,分别计算每一拼接结果的标志位[cls]的隐向量表示每一候选知识在隐空间上的高维语义表征以及用户消息x
t
在隐空间上的高维语义表征包括:
[0015]
对用户消息x
t
与知识库中的每条候选知识分别做拼接,并添加上bert中的标志位[cls]和标志位[sep],得到拼接结果
[0016]
利用bert编码器,将拼接结果编码为隐向量表征,得到每一拼接结果的标志位[cls]的隐向量表示用户消息x
t
的隐向量表示每一拼接结果的标志位[sep]的隐向量表示和每一候选知识的隐向量表示
[0017]
对所述隐向量表示和所述隐向量表示做平均池化操作,得到候选知识在隐空间上的高维语义表征和用户消息x
t
的高维语义表征
[0018]
对所述高维语义表征进行非线性变换之后,利用注意力机制计算各高维语义表征的权重以得到所述用户消息x
t
在隐空间上的高维语义表征
[0019]
进一步地,所述基于所述用户消息高维语义表征与所述历史轮知识高维表征集合预测本轮对话话题发生转移的概率以确定进行话题转移计算或话题继承计算,包括:
[0020]
将所述高维语义表征过一前馈层,得到所述用户消息x
t
中蕴含的表明话题转移的信息
[0021]
将所述历史知识高维表征拼接后过transfomerencoder层,得到历史知识中的综合特征信息
[0022]
拼接所述信息与所述综合特征信息得到高维向量得到高维向量
[0023]
拼接所述信息本轮知识高维表征与所述综合特征信息得到高维向量量
[0024]
将所述高维向量输入学生话题转移判别器,得到本轮对话话题发生转移的概率其中,所述学生话题转移判别器的结构包括:一全连接层和一softmax层;
[0025]
根据所述概率确定进行话题继承计算或话题转移计算。
[0026]
进一步地,所述学生话题转移判别器的训练过程,包括:
[0027]
将所述高维向量输入教师话题转移判别器,得到本轮对话话题发生转移的概率其中,所述教师话题转移判别器的结构包括:一全连接层和一softmax层;
[0028]
基于所述概率表示所述学生话题转移判别器的二元交叉熵损失函数,基于所述概率表示所述教师话题转移判别器的二元交叉熵损失函数,并采用kl散度作为知识蒸馏的损失函数,以使所述概率与所述概率互相逼近。
[0029]
对于话题迁移和话题继承标签的获取,将构造数据集时每轮所选正确知识中的检索词作为话题词,对比每相邻两轮话题词的异同,以得到每轮对话话题转移的标签;
[0030]
利用课程学习方法与知识蒸馏的方法,对标签中可能含有的噪声做降噪,提升模型的鲁棒性。
[0031]
进一步地,在确定进行话题转移计算的情况下,所述得到用户消息x
t
对应的候选知识概率分布,包括:
[0032]
对所述隐向量表示经过一个relu激活的全连接层,提取每一候选知识与所述用户消息x
t
的语义关联的高维表征
[0033]
基于所述高维语义表征对候选知识间进行注意力计算,并通过激活函数和全连接层提取出候选知识间差异的高维表征
[0034]
将所述高维表征与所述高维语义表征拼接之后,通过全连接层变换维度并构造注意力机制中的键向量
[0035]
将所述高维表征与所述高维语义表征拼接之后,通过全连接层变换维度并构造注意力机制中的查询向量q
shift
;
[0036]
将所述键向量与所述查询向量q
shift
按照加性模型进行注意力计算之后,过softmax层得到候选知识概率分布。
[0037]
进一步地,在确定进行话题继承计算的情况下,所述得到用户消息x
t
对应的候选知识概率分布,包括:
[0038]
将所述历史知识高维表征拼接后过transfomerencoder层,得到历史知识中的综合特征信息
[0039]
对所述隐向量表示经过一个relu激活的全连接层,提取每一候选知识与所述用户消息x
t
的语义关联的高维表征
[0040]
基于所述高维语义表征对候选知识间进行注意力计算,并通过激活函数和全连接层提取出候选知识间差异的高维表征
[0041]
将所述高维表征与所述高维语义表征拼接之后,通过全连接层变换维度并构造注意力机制中的键向量
[0042]
将所述高维表征与所述综合特征信息拼接之后,通过全连接层变换维度并构造注意力机制中的查询向量q
inherit
;
[0043]
将所述键向量与所述查询向量q
inherit
按照加性模型进行注意力计算之后,过softmax层得到候选知识概率分布。
[0044]
进一步地,所述综合所述候选知识概率分布与所述对话x
t
,生成第t轮的回复,包括:
[0045]
基于所述候选知识概率分布在所述知识库选择候选知识;
[0046]
在gpt2 tokenizer的字典中定义新的token;其中,所述新的token包括:《context》、《response》和《knowledge》;
[0047]
将所述新的token作为segment embedding以标记所述对话x
t
与选择的候选知识中的不同信息成分;
[0048]
将标记后的所述对话x
t
与选择的候选知识,输入以gpt2为backbone设计的生成器,得到第t轮的回复。
[0049]
进一步地,所述将所述新的token作为segment embedding以标记所述对话x
t
与选择的候选知识中的不同信息成分,包括:
[0050]
将《context》拼接到所述对话x
t
前,将《knowledge》拼接到选择的候选知识前以及训练阶段将《response》拼接到本轮回复前,帮助区分输入gpt2模型的不同信息。
[0051]
一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一所述方法。
[0052]
一种电子设备,其特征在于,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一所述方法。
[0053]
与现有技术相比,本发明的积极效果为:
[0054]
1)本发明为知识选择过程依靠话题转移特性建模,设计了话题转移/话题继承知识选择器,在每轮对话开始前通过话题转移判别器依靠对话历史以及用户消息判断本回合对话将会发生话题转移或是话题继承,这种设计能够更好地抓住对话历史中的关键信息更准确地构造查询向量,提升知识选择的准确率。
[0055]
2)针对标签标注困难问题,本发明设计了一个基于远程监督的标注方法。本发明将构造数据集时用于检索候选知识的检索词当作话题词,并通过话题词是否在历史对话回合中出现标注话题转移伪标签。考虑到远程监督得到伪标签会带来一定的噪声,本发明结合课程学习与知识蒸馏减轻噪声的负面影响。
附图说明
[0056]
图1话题转移感知的知识型对话生成模型示意图。
[0057]
图2编码器模块示意图。
[0058]
图3知识选择模块示意图。
[0059]
图4生成器模块示意图。
具体实施方式
[0060]
为了使本发明的目的、发明及优点更加清楚明白,以在真实数据集上进行的实验为例,对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0061]
本发明的基于外部知识的电网客服对话生成方法,在每轮对话开始时,话题转移判别器根据对话历史信息判断本轮对话话题是否将发生转移。假如用户方引入了新话题导致话题与上轮产生差异,模型将会选用话题转移知识选择器进行本轮知识的选择;否则模型将会通过话题继承知识选择器,并根据历史轮对话的话题选择相近话题继续对话。针对每个子选择器,模型会喂入不同类型的输入信息。在训练阶段,本发明设计了一种基于远程监督的伪标签标注方法,帮助模型在推断时更准确地捕捉对话中话题转移的发生。
[0062]
如图1所示,本发明包括编码器模块、知识选择器模块以及解码器模块。各模块的具体功能如下:
[0063]
一.编码器模块
[0064]
本发明采用bert作为编码器,如图2所示,给定当前轮用户消息x
t
和知识库对用户消息x
t
与知识库中的每条候选知识分别做拼接,并添加上bert中的标志位[cls]和[sep],得到结果如下:
[0065][0066]
之后将过bert编码器,将其编码为隐向量表征,按照下标位置分别得到[cls]的隐向量表示、x
t
的隐向量表示、[sep]的隐向量表示和的隐向量表示:
[0067][0068]
对于和因为它们的长度为预设的句子长度,长度不统一不利于之后构造查询变量query做attention,所以做平均池化操作,得到:
[0069][0070]
通过以上操作,可以得到知识库中的每条候选知识在隐空间上的高维语义表征对于在高维空间做一次非线性变换得到之后利用注意力机制计算得到权重加权综合d个知识感知下的当前轮用户消息x
t
得到在隐空间上的高维语义表征
[0071]
[0072][0073][0074]
其中wc,是模型中可训练的参数。
[0075]
二.知识选择器模块
[0076]
如图3所示,该模块主要分为话题转移判别器、话题转移知识选择器以及话题继承知识选择器三个子模块。
[0077]
1.话题转移判别器
[0078]
话题转移判别器可以判断每一轮对话是否将发生话题转移,由于本发明结合了知识蒸馏技术,话题转移判别器有两个子模块构成:教师话题转移判别器和学生话题转移判别器。给定当前轮用户消息高维表征历史轮知识高维表征话题转移判别器可以预测出本轮对话话题发生转移的概率教师判别器多出了属于后验信息的本轮黄金知识的高维表征该教师判别器只在训练阶段辅助训练学生判别器,在推断阶段不工作。
[0079]
对于当前轮用户消息高维表征将其过一个前馈层,尝试提取出用户消息中蕴含的表明话题转移的信息
[0080][0081]
此处本发明将历史所选知识的高维隐向量表征拼接后过transfomerencoder层,它由数层transformer encoder blocks堆叠而成,并且它含有一个独特的位置嵌入层,该嵌入层标注了历史知识所在的对话轮数,这种位置关系有利于提升模型对序列知识信息的感知能力,能够帮助模型更好的提取多轮对话中传递着的特征。此外,在这些编码器块中有从左到右单向的自注意力掩码,这些掩码可以保证每个位置的知识只能参考以前轮的知识,不可见未来轮的知识,这有利于提升模型的泛化能力,防止模型在推断阶段性能骤降。
[0082][0083]
之后,对用户本轮消息蕴涵信息以及历史知识中的综合特征信息做简单处理后拼接,得到高维向量作为学生模型前馈层的输入,如下:
[0084][0085]
对于教师模型,向量多拼接了本轮知识高维表征
[0086]
[0087]
通过全连接层并经过softmax层归一化,得到教师话题转移判别器的输出为代表本轮发生子话题转移的概率,其取值在0到1之间。保留此概率值不做处理,仅当作软化标签。
[0088][0089][0090]
学生话题转移判别器模块的损失函数为二元交叉熵损失函数:
[0091][0092]
教师话题转移判别器模块的损失函数为二元交叉熵损失函数:
[0093][0094]
本发明采用kl散度作为知识蒸馏的损失函数,该损失可以约束教师模型与学生模型得到的概率分布互相逼近:
[0095][0096]
2.话题转移知识选择器
[0097]
对于话题转移,根据调查,一般是由于对话中用户方的消息中提到了新的话题,所以本发明利用当前轮用户消息做知识选择。给定当前轮用户消息的高维表征当前轮知识库中各候选知识的高维表征以及标志位[cls]的高维表征本发明首先对经过一个relu激活的全连接层,提取出知识句与当前轮用户消息之间的语义关联。
[0098][0099]
之后,本发明对候选知识间使用注意力机制,并通过激活函数和全连接层提取出候选知识间的关联信息,模型可以利用其中的差异信息更好地选择知识。
[0100][0101][0102][0103][0104]
其中wk是模型中的可训练参数。
[0105]
在经过以上两个特征提取层后,可以得到用户消息和知识语义关联的高维表征
候选知识间差异的高维表征将前者与对应的候选知识表征做拼接,之后通过全连接层变换维度并构造注意力机制中的键向量(key);将后者与用户当前轮消息的高维表征拼接后过全连接层变换维度,构造注意力机制中的查询向量(query)。本发明将二者按照加性模型进行注意力机制,之后过softmax层得到候选知识的概率分布
[0106][0107][0108][0109][0110]
其中w、u是模型中的可训练参数。
[0111]
3.话题继承知识选择器
[0112]
而对于话题继承的情况,用户方此轮大概率在附和或肯定系统方的消息并没有提出新话题,此时系统方需要从之前对话的话题中选择一个合适的将对话进行下去,这种情况下模型需要充分利用历史轮所选知识做本轮知识选择。本发明首先采取与话题转移知识选择器中一样的网络提取出[cls]中存在的语义关联,并提取出候选知识间的关联信息
[0113]
之后,本发明使用与话题转移判别器中相同结构的模块提取历史知识中的综合特征信息,但是该模块与前文的模块不共享参数。
[0114][0115]
对于注意力机制部分,此前面类似,该模块同样采用加性模型实现,最终可得到候选知识的分布
[0116][0117][0118][0119][0120]
综合以上模块,首先我们的发明根据话题转移判别器判别出当前轮是否将发生话题转移,如果是,我们根据话题转移知识选择器的分布选择概率最大的知识用于之后的生成步骤,否则我们根据话题继承知识选择器的分布选择概率最大的知识。
[0121]
三.生成器模块
[0122]
在给定选到的知识和对话历史k
′1,
…
,k
′
t-1
后,如图4所示,由解码器综合两部分信息生成回复。本发明采用gpt-2作为backbone设计生成器,在gpt2 tokenizer的字典中定义新的tokens:"《context》","《response》","《knowledge》"并用它们当作segment embedding以标记输入中的不同信息成分。生成器模块通过交叉熵损失做训练,需要注意的是只需要对生成回复计算损失,前面的知识与对话历史在构造target时用掩码遮蔽住。
[0123][0124]
此外,知识型对话生成任务面临着数据集中不含话题标签的难题,为了解决该困难,本发明使用了远程监督的数据标注方法,通过假设检索知识库中候选知识句的实体词为话题词为数据补上标签。然而上述方法的假设性很强噪声较大,所以本发明配合噪声标签学习方法对其做出改进。具体来讲,通过将课程学习与知识蒸馏的方法结合,模型可以减缓噪声标签在训练阶段带来的毒害。实验效果表明多轮对话中的话题信息的确能够帮助建模知识选择过程。
[0125]
综上所述,本发明为知识选择过程依靠话题转移特性建模,设计了话题转移/话题继承知识选择器,在每轮对话开始前通过话题转移判别器依靠对话历史以及用户消息判断本回合对话将会发生话题转移或是话题继承,这种设计能够利用对话历史中的关键信息更准确地构造查询向量,提升知识选择的准确率。
[0126]
针对标签标注困难问题,本发明设计了一个基于远程监督的标注方法。本发明将构造数据集时用于检索候选知识的检索词当作话题词,并通过话题词是否在历史对话回合中出现标注话题转移伪标签。考虑到远程监督得到伪标签会带来一定的噪声,本发明结合课程学习与知识蒸馏减轻噪声的负面影响。
[0127]
在实验验证中,数据集采用的是wizard of wikipedia(简称wow)数据集。wow数据集由facebook团队通过众包的方式从数据收集网站得来,构造数据集的具体方法如下:
[0128]
在收集数据时,巫师(wizard)和学徒(apprentice)都由用户扮演,区别是wizard方可以用维基百科检索到的知识作为支撑产生富含知识信息的回复,wizard方用户在构造回复时用户会被提示结合知识,但是不允许直接复制知识。
[0129]
一个对话回合开始时,wizard或apprentice中的一方先挑选一个主题并发送消息,另一方用户会收到主题以及消息并进行回复,对话流程有序进行。当apprentice方收到消息,他可以进行任意的答复,但是要确保这个话题要进行的深入;而当wizard方收到消息后,从系统给出的知识库中选择一个知识,并根据它做出答复,当然当系统给出的知识条目不相关时,wizard方也可以选择不使用外部知识,这在数据集中都会对应知识标签;对话持续进行直到有一方终止,对话轮数至少达到系统规定的下限(各4~5轮)。收集到的数据集按照比例分成训练集、验证集以及测试集。数据集的对话话题极其丰富多样,包含1365个不同话题。三个集合包含的数据量为:18,430/1,948/1,933。其中测试集被分为了测试可见(test seen)和测试不可见(test unseen),测试可见集合的对话话题在训练集中出现过,测试不可见集合的对话话题是全新未出现的,属于out of domain数据,难度更大。
[0130][0131]
表1
[0132]
如表1所示,本发明的基线模型包括了知识型对话生成的部分sota模型:memnet、skls、dukenet、diffks、mike、colv、knowledgpt。本发明使用精确率(accuracy)、bleu值、rouge、meteor来评估模型的效果。上表展示了本发明和基线模型在wizard of wikipedia数据集上的自动评估结果,加粗部分表示最优结果。可以看到在两个测试集上,本发明基本上在各项指标上都超过了基线模型。对于知识选择指标acc,本发明在test unseen数据集上的提升尤其明显,比基线模型中的最好结果22.5%高了3.3%的准确率。在test seen上也有一定的提升。这表明将知识选择器解耦合,以及针对每个样本根据话题选择更合适的选择器的策略是有效的,远程监督获得的伪标签具有指导意义,此外标签噪声学习方法提高了模型的鲁棒性。对于各生成指标,本发明在两测试集上都取得了显著提升,尤其是在bleu-1、meteor指标上提升明显。这其中一部分提升来自于预训练gpt-2模块拥有更良好的知识融入能力;另一部分则来自于知识选择器选到了更合适的知识,融入到解码器中生成了更贴近ground-truth的回复,这印证了知识选择模块在kgc任务中的重要性。
[0133]
实验结果证明,本技术知识选择的准确率更高,模型生成回复的质量更好,回复内容更贴近于真人的回复,不仅流畅而且富含知识性。
[0134]
以上所述为本发明的一个实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。