1.本发明属于电能能耗采集分析领域,特别涉及一种基于深度学习的电能能耗采集分析方法及系统。
背景技术:
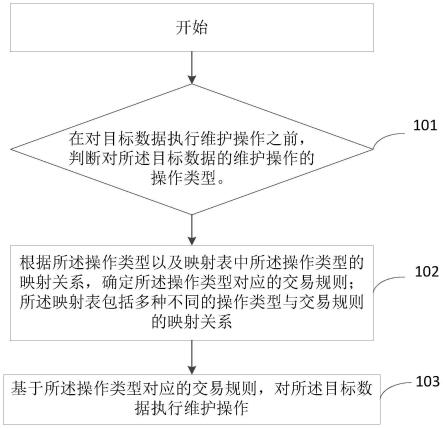
::2.目前市场电价形式主要包括固定电价、阶梯电价、分时电价、实时电价等。目前售电公司使用最多的电价形式为分时电价。分时电价中一天的电价随时间段变化,在用电高峰时电价较高,引导用户减少电力负荷,在用电低谷时电价较低,鼓励用户使用电力。3.不同类型的用户的用电特点不同,用电量和用电高峰和低谷时间段都存在差异,因此,售电公司为不同类型的用户制定不同的分时电价方案能够合理安排电能资源同时提高收入。4.在制定电价的过程中,需要对用户的用电行为进行采集和分析。目前的大多数能耗分析系统都是只针对于某一特殊领域或者对象进行能耗分析,当能耗数据涉及具有不同特点的多个领域时,模型分析的效果将大打折扣。目前售电公司需要一套通用的电能采集分析模型,能够针对不同特点的用户进行能耗使用分析。技术实现要素:5.本发明的目的是为了解决
背景技术:
:中的问题,提供了一种基于深度学习的电能能耗采集分析方法及系统。这种电能能耗采集分析方法及系统是一个从底层数据采集到顶层数据分析的能耗采集分析系统,同时在能耗分析时首先建立分类模型,对采集的能耗信息按特征进行分类,在分类的基础上建立预测模型,针对不同类型的用户有不同的预测模型进行能耗预测,提高准确率和泛化性以及可解释性。6.为达到上述目的,本发明第一方面提供了一种基于深度学习的电能能耗采集分析方法,包括以下步骤:7.步骤1,通过数据采集装置获取若干个行业中用户的智能电表的某一时间段的能耗数据,包括用电数据、日期、地区和天气数据并写入数据库;8.步骤2,对写入数据库的数据进行预处理;所述预处理是对于数据异常的问题,将异常的数据剔除,对于数据缺失问题,根据模型需要数据的格式对数据进行切片,避开存在缺失的部分;9.步骤3,把行业维度作为标签,将步骤2中预处理后的用电数据、日期、地区和天气数据四种数据作为特征分别输入lstm-fcn算法模型中进行模型的训练,并使用训练好的lstm-fcn算法模型根据采集输入的能耗数据对能耗的用户进行行业分类;10.步骤4,将获取的不同行业的特定时间段的电力数据分别对n-beats算法模型进行训练,并获得若干个不同行业的n-beats算法模型;根据步骤3中分类的用户所属行业,将采集的特定时间段的用电数据输入对应行业的训练完成的n-beats算法模型中,对未来特定时间段的用电数据进行预测。11.优选的,所述步骤1中的某一时间段为一年,采样间隔为1小时的采集于若干个行业的能耗数据;所述数据采集装置为树莓派,所述树莓派与电表之间使用rs485总线连接,并通过modbus协议对电表内的数据进行读取;所述树莓派通过电表所属区域信息从网上获取天气数据,并将获取的用电数据、日期、地区和天气数据存放至mysql数据库。12.优选的,所述步骤2中将异常的数据剔除是针对每个电表采集的数据,使用四分位数法判断采集的数据是否异常,具体如下:13.对每个电表采集的数据从小到大进行排序,q1、q2和q3分别为该样本中所有数值由小到大排列后第25%、50%和75%的数字,异常值判断的阈值设定为:阈值上限u=q3 1.5*(q3-q1)14.阈值下限d=q1-1.5*(q3-q1)15.超过此阈值的即为异常数据,对异常数据进行删除处理。16.优选的,所述lstm-fcn算法模型包括lstm块、fcn块、连接层和softmax层;所述lstm块和fcn块提取用电数据和协变量之间的特征,并将结果张量输入连接层;所述连接层纵向连接lstm块和fcn块的结果,将二者提取到的特征综合起来;所述softmax层对神经网络的输出结果进行换算,将输出结果用概率的形式表现出来,即将输入的数据划分为某类行业的概率。17.优选的,所述n-beats算法模型以堆栈-块的层次结构组成;所述堆栈包含多个块,针对于不同解释性对用电数据进行预测;所述块由全卷积块和可解释计算模块组成,所述全卷积块提取用电数据特征,所述可解释计算模块计算该可解释方面的预测值;具体工作步骤如下:18.s1:输入上个块输入与后向预测的残差;19.s2:输入的数据首先经过4层全卷积,提取用电数据的特征;20.s3:对步骤s2输出的数据进行可解释性计算,获得针对于该解释方面的预测;21.使用多项式拟合时间序列的趋势,拟合公式为:[0022][0023]使用三角函数拟合时间序列的季节性,拟合公式为:[0024][0025]其中n为多项式的最高次项指数,t为时间,为第s个堆栈中的第b个块全卷积层的输出,h表示时间序列的长度,nhr为超参数。[0026]本发明第二方面提供了一种基于深度学习的电能能耗采集分析系统,包括服务器和用于采集电能能耗数据的数据采集装置,所述服务器包括数据库、数据预处理模块、分类模块和预测模块;所述数据采集装置用于获取智能电表的能耗数据并写入数据库;所述数据预处理模块用于对数据库内存储的数据进行预处理,对于数据异常的问题,将异常的数据剔除,对于数据缺失问题,根据模型需要数据的格式对数据进行切片,避开存在缺失的部分;所述分类模块是训练完成的lstm-fcn算法模型,所述lstm-fcn算法模型根据采集的能耗数据对能耗的用户进行行业分类;所述预测模块为训练完成的多个与用户类型相对应的n-beats算法模型,根据分类模块的结果,将采集的用电数据输入相对应的n-beats算法模型中,对未来特定时间段的用电数据进行预测。[0027]优选的,所述电能能耗数据包括用电数据、日期、地区和天气数据;所述数据采集装置为树莓派,所述树莓派与电表之间使用rs485总线连接,并通过modbus协议对电表内的数据进行读取;所述树莓派通过电表所属区域信息从网上获取天气数据,并将获取的用电数据、日期、地区和天气数据存放至mysql数据库[0028]优选的,所述步骤2中将异常的数据剔除是针对每个电表采集的数据,使用四分位数法判断采集的数据是否异常,具体如下:[0029]对每个电表采集的数据从小到大进行排序,q1、q2和q3分别为该样本中所有数值由小到大排列后第25%、50%和75%的数字,异常值判断的阈值设定为:阈值上限u=q3 1.5*(q3-q1)[0030]阈值下限d=q1-1.5*(q3-q1)[0031]超过此阈值的即为异常数据,对异常数据进行删除处理。[0032]优选的,所述训练完成的lstm-fcn算法模型是把行业维度作为标签,将预处理后的用电数据、日期、地区和天气数据四种数据作为特征分别输入lstm-fcn算法模型中进行模型的训练;所述lstm-fcn算法模型包括lstm块、fcn块、连接层和softmax层;所述lstm块和fcn块提取用电数据和协变量之间的特征,并将结果张量输入连接层;所述连接层纵向连接lstm块和fcn块的结果,将二者提取到的特征综合起来;所述softmax层对神经网络的输出结果进行换算,将输出结果用概率的形式表现出来,即将输入的数据划分为某类行业的概率。[0033]优选的,所述n-beats算法模型是将获取的不同行业的特定时间段的电力数据分别对n-beats算法模型进行训练;所述n-beats算法模型以堆栈-块的层次结构组成;所述堆栈包含多个块,针对于不同解释性对用电数据进行预测;所述块由全卷积块和可解释计算模块组成,所述全卷积块提取用电数据特征,所述可解释计算模块计算该可解释方面的预测值。[0034]与现有技术相比,本发明具有以下优点和有益效果:[0035]1.使用数据采集装置树莓派实时采集用户的用电量和位置信息,并联网获取天气、日期、地区等相关信息进行实时存储,数据采集效率高。[0036]2.使用分类模型首先对用户类型进行分类,其次在分类的基础上建立若干预测模型,使具相似特征的用户使用一套预测模型进行用户用电预测,提高准确率。[0037]3.使用具有可解释性的预测模型进行用电预测,打破传统神经网络以及预测系统的黑盒特性,对预测结果进行解释,便于用户理解系统产生此结果的原因。[0038]4.模型最终产生未来特定时间段不同类型用户的用电量预测,便于售电公司把握用户用电情况,合理制定电价以及降低投资成本,为提高营收提供数据参考。附图说明[0039]为了更清楚地说明本发明或现有技术的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单的介绍,显而易见地,下面描述的仅仅是本发明的一个实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。[0040]图1为本发明提供的基于深度学习的电能能耗采集分析方法流程图。[0041]图2为本发明提供的使用lstm-fcn算法对能耗数据进行分类的结构及流程图。[0042]图3为本发明提供的n-beats算法模型的结构分解图。[0043]图4为本发明提供的基于深度学习的电能能耗采集分析系统的结构示意图。具体实施方式[0044]下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的范围。[0045]实施例1:[0046]作为本发明基础的且帮助理解本发明公知技术内容:[0047]n-beats:[0048]基于神经网络基底扩展分析的可解释的时间序列预测(neuralbasisexpansionanalysisforinterpretabletimeseriesforecasting,n-beats)是一种深度学习算法,在能够准确预测时间序列的同时,快速训练神经网络并且实现可解释性。[0049]可解释性即n-beats在给出预测结果的同时将时间序列分解成趋势和结节性,分析数据变化的趋势和变化的周期。[0050]lstm-fcn:[0051]是一种基于lstm和fcn的多变量时间序列分类模型,能够在对多变量时间序列进行分类的同时保持较高的性能。[0052]请参照图1,本发明提供了一种基于深度学习的电能能耗采集分析方法,主要包括以下步骤:[0053]步骤1,通过数据采集装置获取若干个行业中用户的智能电表的某一时间段的能耗数据,包括用电数据、日期、地区和天气数据并写入数据库;[0054]步骤2,对写入数据库的数据进行预处理;所述预处理是对于数据异常的问题,将异常的数据剔除,对于数据缺失问题,根据模型需要数据的格式对数据进行切片,避开存在缺失的部分;[0055]步骤3,把行业维度作为标签,将步骤2中预处理后的用电数据、日期、地区和天气数据四种数据作为特征分别输入lstm-fcn算法模型中进行模型的训练,并使用训练好的lstm-fcn算法模型根据采集输入的能耗数据对能耗的用户进行行业分类;[0056]步骤4,将获取的不同行业的特定时间段的电力数据分别对n-beats算法模型进行训练,并获得若干个不同行业的n-beats算法模型;根据步骤3中分类的用户所属行业,将采集的特定时间段的用电数据输入对应行业的训练完成的n-beats算法模型中,对未来特定时间段的用电数据进行预测。[0057]1.关于步骤1:[0058]数据采集装置可以为树莓派,树莓派与电表之间使用rs485总线连接,并通过modbus协议对电表内的数据进行读取;树莓派通过电表所属区域信息从网上获取天气数据,并将获取的用电数据、日期、地区和天气数据存放至mysql数据库。步骤1中的某一时间段优选为一年,采样间隔为1小时的采集于若干个行业的能耗数据。[0059]2.关于步骤2:[0060]采集的数据往往存在数据异常和数据缺失的情况:[0061]针对每个电表采集的数据,使用四分位数法判断采集的数据是否异常,具体如下:[0062]对每个电表采集的数据从小到大进行排序,q1,q2,q3分别为该样本中所有数值由小到大排列后第25%,50%,75%的数字。[0063]异常值判断的阈值设定为:[0064]阈值上限u=q3 1.5*(q3-q1)[0065]阈值下限d=q1-1.5*(q3-q1)[0066]超过此阈值的即为异常数据,对异常数据进行删除处理。[0067]数据缺失的情况处理方法如下:对数据进行切片处理,避开存在缺失数据的部分,保证输入预测模型的数据都是连续的。[0068]3.关于步骤3:[0069]lstm-fcn算法模型包括lstm块、fcn块、连接层和softmax层;所述lstm块和fcn块提取用电数据和协变量之间的特征,并将结果张量输入连接层;连接层纵向连接lstm块和fcn块的结果,将二者提取到的特征综合起来;所述softmax层对神经网络的输出结果进行换算,将输出结果用概率的形式表现出来,即将输入的数据划分为某类行业的概率。[0070]如图2所示,使用lstm-fcn算法对能耗数据进行分类,具体步骤如下:[0071]步骤一:输入能耗数据,包括电力数据、日期、地区和天气数据;[0072]步骤二:对输入的数据分别使用lstm(longshort-termmemory,长短期记忆人工神经网络)块和fcn(fullyconnectednetwork,全卷积网络)块进行处理。[0073]针对于fcn块,具体步骤如下:[0074]步骤1:(1)电力数据首先经过一维卷积,提取二位数据矩阵的特征;(2)一维卷积输出的数据经过批标准化并使用relu函数激活,完成数据的归一化和引入非线性因素;(3)得到的数据经过se网络(squeeze-and-excitationnetworks),提升模型对特征的敏感性。[0075]步骤2:重复步骤1。[0076]步骤3:重复步骤1中的(1),(2)。[0077]步骤4:步骤3得到的数据进行全局池化,降低信息冗余度。[0078]针对于lstm块,具体步骤如下:[0079]步骤1:输入的电力数据进行维度清洗,处理数据维度。[0080]步骤2:(1)步骤1得到的数据输入lstm网络,进行训练。(2)lstm网络输出的数据进入droupout层,减少过拟合。[0081]步骤三:fcn块和lstm块输出的数据进行连接。[0082]步骤四:步骤三输出的数据进入softmax(柔性最大值传输函数)层,对神经网络的输出结果进行换算,将输出结果用概率矩阵的形式表现出来,即将输入的数据划分为某类行业的概率。将得出的概率矩阵最为自然底数的指数,取出最大的值,即为最后预测的分类。类别集合包括教育、医疗、制造、公共设施、民用、办公等。[0083]目前的分时电价方案对于客户群体的划分仍比较宽泛,不能针对于特定行业制定特定的售电计划。针对不同的行业制定不同的分时电价,能更加准确地把握行业的用电特征,降低电网的投资成本和运行成本,保障电网的安全稳定运行。[0084]不同类型的用电客户的用电特征是不一样的,与天气、时间、节假日、地区等因素关系密切,如天气寒冷时用电量会提高、节假日公司的用电量会降低而居民的用电量会提高等。lstm-fcn模型建立用电量与以上变量之前的关系从而判断用电客户属于哪种类型。[0085]本模型使用的训练数据是为期1年,采样间隔为1小时的采集于多个行业的电力数据,包含日期、用电量、地区、天气,并以行业为标签维度。使用跨度1年的数据是为了保证全面掌握用电特征,便于模型提取小时、天、周、月份、季度等特征。由于各行业的用电量与多种因素息息相关,提供的作用因素越多,分类越准确。为在保证用户的隐私性的同时提高分类的准确率,本发明选择几个作用程度大以及售电公司易于获取的数据作为分类的依据,包括时间、用电量、地区、天气。[0086]把数据的“行业”维度作为标签,其他数据作为特征分别输入模型,为了提高训练速度和减少内存的使用,将经过异常处理后的数据切分为适合的大小输入模型进行训练,捕捉行业与数据与各维度之间的关系和特征,建立对应关系,不断调整模型权重,直至模型收敛。至此模型的训练完成,生成的模型可用于对用户类型进行分类。[0087]输入模型的测试数据需要与输入数据的格式保持相同,维度需要保持一致。将测试数据除“行业”外的其他数据切分为模型适合的大小后输入模型,模型的输出即为该数据所属行业的类型。[0088]4.关于步骤4:[0089]如图3所示,n-beats算法模型以堆栈-块的层次结构组成;堆栈包含多个块,针对于不同解释性对用电数据进行预测;块由全卷积块和可解释计算模块组成,全卷积块提取用电数据特征,可解释计算模块计算该可解释方面的预测值。[0090]在根据用户用电特征对用户进行分类的基础上,根据不同的类别,训练不同参数的n-beats模型对用户用电进行预测,保障预测的准确率。[0091]n-beats由多个堆栈组成,每个堆栈又包含多个块。[0092]n-beats堆栈层如图3中图c所示,工作步骤如下:[0093]步骤1:输入经过异常处理和缺失处理的电力数据。[0094]步骤2:输入的数据经过堆栈1,得到预测1和残差1,残差1为堆栈1无法处理的数据,预测1为对趋势的预测。[0095]步骤2:步骤1输出的残差输入堆栈2,得到预测2和残差2,预测2是对于季节性的预测.[0096]步骤3:堆栈输出的预测值相加得到整体的预测值,即趋势和季节性两个维度的预测构成整体的预测。[0097]块层如图3中图b所示,工作步骤如下:[0098]获取上个单元的残差输出,如果是第一个堆栈的第一个块,则输入为原始数据。输出为前向预测i和后向预测i,预测是对于趋势/季节的预测,后向预测是对于过去能耗的预测,与输入的残差即为无法处理的信息。[0099]所有块的前向预测和为块所属堆栈的预测,最后一个块的后向预测和其输入的残差为所属堆栈输出的残差。[0100]块内如图3中图a所示,具体工作步骤如下:[0101]步骤1:输入上个块输入与后向预测的残差。[0102]步骤2:输入的数据首先经过4层全卷积,提取能耗数据的特征。[0103]步骤2:对步骤2输出的数据进行可解释性计算,获得针对于该解释方面的预测。[0104]使用多项式拟合时间序列的趋势,拟合公式为:[0105][0106]使用三角函数拟合时间序列的季节性,拟合公式为:[0107][0108]其中n为多项式的最高次项指数,t为时间,为第s个堆栈中的第b个块全卷积层的输出,h表示时间序列的长度,nhr为超参数。[0109]预测模型使用的数据集与分类模型使用的数据集相同,但是要根据预测的时间步长对数据进行切片,如根据前24小时的数据预测底25小时的用电量,则将长度为24的二维时间数据矩阵作为特征,第25小时的用电量作为标签输入预测模型,进行模型训练。当模型收敛时,模型训练完成,保存的模型可用于预测用电量。[0110]使用模型进行预测时,输入数据的维度需要与训练维度保持一致,同时数据长度为24,模型的输出即为预测第25小时的用电量。同时模型在运行过程中还会产生对于数据的解释,将数据的季节性、趋势等计算出来,可以以图片的形式显示,为结果提供解释。[0111]实施例2:[0112]为实现实施例1中的电能能耗采集分析方法,本实施例提出了一种基于深度学习的电能能耗采集分析系统,如图4所示,包括服务器和用于采集电能能耗数据的数据采集装置,服务器包括数据库、数据预处理模块、分类模块和预测模块;数据采集装置用于获取智能电表的能耗数据并写入数据库;数据预处理模块用于对数据库内存储的数据进行预处理,对于数据异常的问题,将异常的数据剔除,对于数据缺失问题,根据模型需要数据的格式对数据进行切片,避开存在缺失的部分;分类模块是训练完成的lstm-fcn算法模型,所述lstm-fcn算法模型根据采集的能耗数据对能耗的用户进行行业分类;预测模块为训练完成的多个与用户类型相对应的n-beats算法模型,根据分类模块的结果,将采集的用电数据输入相对应的n-beats算法模型中,对未来特定时间段的用电数据进行预测。电能能耗数据包括用电数据、日期、地区和天气数据;数据采集装置为树莓派,树莓派与电表之间使用rs485总线连接,并通过modbus协议对电表内的数据进行读取;树莓派通过电表所属区域信息从网上获取天气数据,并将获取的用电数据、日期、地区和天气数据存放至mysql数据库。服务器通过用户界面将预测数据及信息向用户展示。[0113]以上所述仅为本技术的优选实施例而已,并不用于限制本技术,对于本领域的技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。[0114]上述虽然对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。当前第1页12当前第1页12
背景技术:
::2.目前市场电价形式主要包括固定电价、阶梯电价、分时电价、实时电价等。目前售电公司使用最多的电价形式为分时电价。分时电价中一天的电价随时间段变化,在用电高峰时电价较高,引导用户减少电力负荷,在用电低谷时电价较低,鼓励用户使用电力。3.不同类型的用户的用电特点不同,用电量和用电高峰和低谷时间段都存在差异,因此,售电公司为不同类型的用户制定不同的分时电价方案能够合理安排电能资源同时提高收入。4.在制定电价的过程中,需要对用户的用电行为进行采集和分析。目前的大多数能耗分析系统都是只针对于某一特殊领域或者对象进行能耗分析,当能耗数据涉及具有不同特点的多个领域时,模型分析的效果将大打折扣。目前售电公司需要一套通用的电能采集分析模型,能够针对不同特点的用户进行能耗使用分析。技术实现要素:5.本发明的目的是为了解决
背景技术:
:中的问题,提供了一种基于深度学习的电能能耗采集分析方法及系统。这种电能能耗采集分析方法及系统是一个从底层数据采集到顶层数据分析的能耗采集分析系统,同时在能耗分析时首先建立分类模型,对采集的能耗信息按特征进行分类,在分类的基础上建立预测模型,针对不同类型的用户有不同的预测模型进行能耗预测,提高准确率和泛化性以及可解释性。6.为达到上述目的,本发明第一方面提供了一种基于深度学习的电能能耗采集分析方法,包括以下步骤:7.步骤1,通过数据采集装置获取若干个行业中用户的智能电表的某一时间段的能耗数据,包括用电数据、日期、地区和天气数据并写入数据库;8.步骤2,对写入数据库的数据进行预处理;所述预处理是对于数据异常的问题,将异常的数据剔除,对于数据缺失问题,根据模型需要数据的格式对数据进行切片,避开存在缺失的部分;9.步骤3,把行业维度作为标签,将步骤2中预处理后的用电数据、日期、地区和天气数据四种数据作为特征分别输入lstm-fcn算法模型中进行模型的训练,并使用训练好的lstm-fcn算法模型根据采集输入的能耗数据对能耗的用户进行行业分类;10.步骤4,将获取的不同行业的特定时间段的电力数据分别对n-beats算法模型进行训练,并获得若干个不同行业的n-beats算法模型;根据步骤3中分类的用户所属行业,将采集的特定时间段的用电数据输入对应行业的训练完成的n-beats算法模型中,对未来特定时间段的用电数据进行预测。11.优选的,所述步骤1中的某一时间段为一年,采样间隔为1小时的采集于若干个行业的能耗数据;所述数据采集装置为树莓派,所述树莓派与电表之间使用rs485总线连接,并通过modbus协议对电表内的数据进行读取;所述树莓派通过电表所属区域信息从网上获取天气数据,并将获取的用电数据、日期、地区和天气数据存放至mysql数据库。12.优选的,所述步骤2中将异常的数据剔除是针对每个电表采集的数据,使用四分位数法判断采集的数据是否异常,具体如下:13.对每个电表采集的数据从小到大进行排序,q1、q2和q3分别为该样本中所有数值由小到大排列后第25%、50%和75%的数字,异常值判断的阈值设定为:阈值上限u=q3 1.5*(q3-q1)14.阈值下限d=q1-1.5*(q3-q1)15.超过此阈值的即为异常数据,对异常数据进行删除处理。16.优选的,所述lstm-fcn算法模型包括lstm块、fcn块、连接层和softmax层;所述lstm块和fcn块提取用电数据和协变量之间的特征,并将结果张量输入连接层;所述连接层纵向连接lstm块和fcn块的结果,将二者提取到的特征综合起来;所述softmax层对神经网络的输出结果进行换算,将输出结果用概率的形式表现出来,即将输入的数据划分为某类行业的概率。17.优选的,所述n-beats算法模型以堆栈-块的层次结构组成;所述堆栈包含多个块,针对于不同解释性对用电数据进行预测;所述块由全卷积块和可解释计算模块组成,所述全卷积块提取用电数据特征,所述可解释计算模块计算该可解释方面的预测值;具体工作步骤如下:18.s1:输入上个块输入与后向预测的残差;19.s2:输入的数据首先经过4层全卷积,提取用电数据的特征;20.s3:对步骤s2输出的数据进行可解释性计算,获得针对于该解释方面的预测;21.使用多项式拟合时间序列的趋势,拟合公式为:[0022][0023]使用三角函数拟合时间序列的季节性,拟合公式为:[0024][0025]其中n为多项式的最高次项指数,t为时间,为第s个堆栈中的第b个块全卷积层的输出,h表示时间序列的长度,nhr为超参数。[0026]本发明第二方面提供了一种基于深度学习的电能能耗采集分析系统,包括服务器和用于采集电能能耗数据的数据采集装置,所述服务器包括数据库、数据预处理模块、分类模块和预测模块;所述数据采集装置用于获取智能电表的能耗数据并写入数据库;所述数据预处理模块用于对数据库内存储的数据进行预处理,对于数据异常的问题,将异常的数据剔除,对于数据缺失问题,根据模型需要数据的格式对数据进行切片,避开存在缺失的部分;所述分类模块是训练完成的lstm-fcn算法模型,所述lstm-fcn算法模型根据采集的能耗数据对能耗的用户进行行业分类;所述预测模块为训练完成的多个与用户类型相对应的n-beats算法模型,根据分类模块的结果,将采集的用电数据输入相对应的n-beats算法模型中,对未来特定时间段的用电数据进行预测。[0027]优选的,所述电能能耗数据包括用电数据、日期、地区和天气数据;所述数据采集装置为树莓派,所述树莓派与电表之间使用rs485总线连接,并通过modbus协议对电表内的数据进行读取;所述树莓派通过电表所属区域信息从网上获取天气数据,并将获取的用电数据、日期、地区和天气数据存放至mysql数据库[0028]优选的,所述步骤2中将异常的数据剔除是针对每个电表采集的数据,使用四分位数法判断采集的数据是否异常,具体如下:[0029]对每个电表采集的数据从小到大进行排序,q1、q2和q3分别为该样本中所有数值由小到大排列后第25%、50%和75%的数字,异常值判断的阈值设定为:阈值上限u=q3 1.5*(q3-q1)[0030]阈值下限d=q1-1.5*(q3-q1)[0031]超过此阈值的即为异常数据,对异常数据进行删除处理。[0032]优选的,所述训练完成的lstm-fcn算法模型是把行业维度作为标签,将预处理后的用电数据、日期、地区和天气数据四种数据作为特征分别输入lstm-fcn算法模型中进行模型的训练;所述lstm-fcn算法模型包括lstm块、fcn块、连接层和softmax层;所述lstm块和fcn块提取用电数据和协变量之间的特征,并将结果张量输入连接层;所述连接层纵向连接lstm块和fcn块的结果,将二者提取到的特征综合起来;所述softmax层对神经网络的输出结果进行换算,将输出结果用概率的形式表现出来,即将输入的数据划分为某类行业的概率。[0033]优选的,所述n-beats算法模型是将获取的不同行业的特定时间段的电力数据分别对n-beats算法模型进行训练;所述n-beats算法模型以堆栈-块的层次结构组成;所述堆栈包含多个块,针对于不同解释性对用电数据进行预测;所述块由全卷积块和可解释计算模块组成,所述全卷积块提取用电数据特征,所述可解释计算模块计算该可解释方面的预测值。[0034]与现有技术相比,本发明具有以下优点和有益效果:[0035]1.使用数据采集装置树莓派实时采集用户的用电量和位置信息,并联网获取天气、日期、地区等相关信息进行实时存储,数据采集效率高。[0036]2.使用分类模型首先对用户类型进行分类,其次在分类的基础上建立若干预测模型,使具相似特征的用户使用一套预测模型进行用户用电预测,提高准确率。[0037]3.使用具有可解释性的预测模型进行用电预测,打破传统神经网络以及预测系统的黑盒特性,对预测结果进行解释,便于用户理解系统产生此结果的原因。[0038]4.模型最终产生未来特定时间段不同类型用户的用电量预测,便于售电公司把握用户用电情况,合理制定电价以及降低投资成本,为提高营收提供数据参考。附图说明[0039]为了更清楚地说明本发明或现有技术的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单的介绍,显而易见地,下面描述的仅仅是本发明的一个实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。[0040]图1为本发明提供的基于深度学习的电能能耗采集分析方法流程图。[0041]图2为本发明提供的使用lstm-fcn算法对能耗数据进行分类的结构及流程图。[0042]图3为本发明提供的n-beats算法模型的结构分解图。[0043]图4为本发明提供的基于深度学习的电能能耗采集分析系统的结构示意图。具体实施方式[0044]下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的范围。[0045]实施例1:[0046]作为本发明基础的且帮助理解本发明公知技术内容:[0047]n-beats:[0048]基于神经网络基底扩展分析的可解释的时间序列预测(neuralbasisexpansionanalysisforinterpretabletimeseriesforecasting,n-beats)是一种深度学习算法,在能够准确预测时间序列的同时,快速训练神经网络并且实现可解释性。[0049]可解释性即n-beats在给出预测结果的同时将时间序列分解成趋势和结节性,分析数据变化的趋势和变化的周期。[0050]lstm-fcn:[0051]是一种基于lstm和fcn的多变量时间序列分类模型,能够在对多变量时间序列进行分类的同时保持较高的性能。[0052]请参照图1,本发明提供了一种基于深度学习的电能能耗采集分析方法,主要包括以下步骤:[0053]步骤1,通过数据采集装置获取若干个行业中用户的智能电表的某一时间段的能耗数据,包括用电数据、日期、地区和天气数据并写入数据库;[0054]步骤2,对写入数据库的数据进行预处理;所述预处理是对于数据异常的问题,将异常的数据剔除,对于数据缺失问题,根据模型需要数据的格式对数据进行切片,避开存在缺失的部分;[0055]步骤3,把行业维度作为标签,将步骤2中预处理后的用电数据、日期、地区和天气数据四种数据作为特征分别输入lstm-fcn算法模型中进行模型的训练,并使用训练好的lstm-fcn算法模型根据采集输入的能耗数据对能耗的用户进行行业分类;[0056]步骤4,将获取的不同行业的特定时间段的电力数据分别对n-beats算法模型进行训练,并获得若干个不同行业的n-beats算法模型;根据步骤3中分类的用户所属行业,将采集的特定时间段的用电数据输入对应行业的训练完成的n-beats算法模型中,对未来特定时间段的用电数据进行预测。[0057]1.关于步骤1:[0058]数据采集装置可以为树莓派,树莓派与电表之间使用rs485总线连接,并通过modbus协议对电表内的数据进行读取;树莓派通过电表所属区域信息从网上获取天气数据,并将获取的用电数据、日期、地区和天气数据存放至mysql数据库。步骤1中的某一时间段优选为一年,采样间隔为1小时的采集于若干个行业的能耗数据。[0059]2.关于步骤2:[0060]采集的数据往往存在数据异常和数据缺失的情况:[0061]针对每个电表采集的数据,使用四分位数法判断采集的数据是否异常,具体如下:[0062]对每个电表采集的数据从小到大进行排序,q1,q2,q3分别为该样本中所有数值由小到大排列后第25%,50%,75%的数字。[0063]异常值判断的阈值设定为:[0064]阈值上限u=q3 1.5*(q3-q1)[0065]阈值下限d=q1-1.5*(q3-q1)[0066]超过此阈值的即为异常数据,对异常数据进行删除处理。[0067]数据缺失的情况处理方法如下:对数据进行切片处理,避开存在缺失数据的部分,保证输入预测模型的数据都是连续的。[0068]3.关于步骤3:[0069]lstm-fcn算法模型包括lstm块、fcn块、连接层和softmax层;所述lstm块和fcn块提取用电数据和协变量之间的特征,并将结果张量输入连接层;连接层纵向连接lstm块和fcn块的结果,将二者提取到的特征综合起来;所述softmax层对神经网络的输出结果进行换算,将输出结果用概率的形式表现出来,即将输入的数据划分为某类行业的概率。[0070]如图2所示,使用lstm-fcn算法对能耗数据进行分类,具体步骤如下:[0071]步骤一:输入能耗数据,包括电力数据、日期、地区和天气数据;[0072]步骤二:对输入的数据分别使用lstm(longshort-termmemory,长短期记忆人工神经网络)块和fcn(fullyconnectednetwork,全卷积网络)块进行处理。[0073]针对于fcn块,具体步骤如下:[0074]步骤1:(1)电力数据首先经过一维卷积,提取二位数据矩阵的特征;(2)一维卷积输出的数据经过批标准化并使用relu函数激活,完成数据的归一化和引入非线性因素;(3)得到的数据经过se网络(squeeze-and-excitationnetworks),提升模型对特征的敏感性。[0075]步骤2:重复步骤1。[0076]步骤3:重复步骤1中的(1),(2)。[0077]步骤4:步骤3得到的数据进行全局池化,降低信息冗余度。[0078]针对于lstm块,具体步骤如下:[0079]步骤1:输入的电力数据进行维度清洗,处理数据维度。[0080]步骤2:(1)步骤1得到的数据输入lstm网络,进行训练。(2)lstm网络输出的数据进入droupout层,减少过拟合。[0081]步骤三:fcn块和lstm块输出的数据进行连接。[0082]步骤四:步骤三输出的数据进入softmax(柔性最大值传输函数)层,对神经网络的输出结果进行换算,将输出结果用概率矩阵的形式表现出来,即将输入的数据划分为某类行业的概率。将得出的概率矩阵最为自然底数的指数,取出最大的值,即为最后预测的分类。类别集合包括教育、医疗、制造、公共设施、民用、办公等。[0083]目前的分时电价方案对于客户群体的划分仍比较宽泛,不能针对于特定行业制定特定的售电计划。针对不同的行业制定不同的分时电价,能更加准确地把握行业的用电特征,降低电网的投资成本和运行成本,保障电网的安全稳定运行。[0084]不同类型的用电客户的用电特征是不一样的,与天气、时间、节假日、地区等因素关系密切,如天气寒冷时用电量会提高、节假日公司的用电量会降低而居民的用电量会提高等。lstm-fcn模型建立用电量与以上变量之前的关系从而判断用电客户属于哪种类型。[0085]本模型使用的训练数据是为期1年,采样间隔为1小时的采集于多个行业的电力数据,包含日期、用电量、地区、天气,并以行业为标签维度。使用跨度1年的数据是为了保证全面掌握用电特征,便于模型提取小时、天、周、月份、季度等特征。由于各行业的用电量与多种因素息息相关,提供的作用因素越多,分类越准确。为在保证用户的隐私性的同时提高分类的准确率,本发明选择几个作用程度大以及售电公司易于获取的数据作为分类的依据,包括时间、用电量、地区、天气。[0086]把数据的“行业”维度作为标签,其他数据作为特征分别输入模型,为了提高训练速度和减少内存的使用,将经过异常处理后的数据切分为适合的大小输入模型进行训练,捕捉行业与数据与各维度之间的关系和特征,建立对应关系,不断调整模型权重,直至模型收敛。至此模型的训练完成,生成的模型可用于对用户类型进行分类。[0087]输入模型的测试数据需要与输入数据的格式保持相同,维度需要保持一致。将测试数据除“行业”外的其他数据切分为模型适合的大小后输入模型,模型的输出即为该数据所属行业的类型。[0088]4.关于步骤4:[0089]如图3所示,n-beats算法模型以堆栈-块的层次结构组成;堆栈包含多个块,针对于不同解释性对用电数据进行预测;块由全卷积块和可解释计算模块组成,全卷积块提取用电数据特征,可解释计算模块计算该可解释方面的预测值。[0090]在根据用户用电特征对用户进行分类的基础上,根据不同的类别,训练不同参数的n-beats模型对用户用电进行预测,保障预测的准确率。[0091]n-beats由多个堆栈组成,每个堆栈又包含多个块。[0092]n-beats堆栈层如图3中图c所示,工作步骤如下:[0093]步骤1:输入经过异常处理和缺失处理的电力数据。[0094]步骤2:输入的数据经过堆栈1,得到预测1和残差1,残差1为堆栈1无法处理的数据,预测1为对趋势的预测。[0095]步骤2:步骤1输出的残差输入堆栈2,得到预测2和残差2,预测2是对于季节性的预测.[0096]步骤3:堆栈输出的预测值相加得到整体的预测值,即趋势和季节性两个维度的预测构成整体的预测。[0097]块层如图3中图b所示,工作步骤如下:[0098]获取上个单元的残差输出,如果是第一个堆栈的第一个块,则输入为原始数据。输出为前向预测i和后向预测i,预测是对于趋势/季节的预测,后向预测是对于过去能耗的预测,与输入的残差即为无法处理的信息。[0099]所有块的前向预测和为块所属堆栈的预测,最后一个块的后向预测和其输入的残差为所属堆栈输出的残差。[0100]块内如图3中图a所示,具体工作步骤如下:[0101]步骤1:输入上个块输入与后向预测的残差。[0102]步骤2:输入的数据首先经过4层全卷积,提取能耗数据的特征。[0103]步骤2:对步骤2输出的数据进行可解释性计算,获得针对于该解释方面的预测。[0104]使用多项式拟合时间序列的趋势,拟合公式为:[0105][0106]使用三角函数拟合时间序列的季节性,拟合公式为:[0107][0108]其中n为多项式的最高次项指数,t为时间,为第s个堆栈中的第b个块全卷积层的输出,h表示时间序列的长度,nhr为超参数。[0109]预测模型使用的数据集与分类模型使用的数据集相同,但是要根据预测的时间步长对数据进行切片,如根据前24小时的数据预测底25小时的用电量,则将长度为24的二维时间数据矩阵作为特征,第25小时的用电量作为标签输入预测模型,进行模型训练。当模型收敛时,模型训练完成,保存的模型可用于预测用电量。[0110]使用模型进行预测时,输入数据的维度需要与训练维度保持一致,同时数据长度为24,模型的输出即为预测第25小时的用电量。同时模型在运行过程中还会产生对于数据的解释,将数据的季节性、趋势等计算出来,可以以图片的形式显示,为结果提供解释。[0111]实施例2:[0112]为实现实施例1中的电能能耗采集分析方法,本实施例提出了一种基于深度学习的电能能耗采集分析系统,如图4所示,包括服务器和用于采集电能能耗数据的数据采集装置,服务器包括数据库、数据预处理模块、分类模块和预测模块;数据采集装置用于获取智能电表的能耗数据并写入数据库;数据预处理模块用于对数据库内存储的数据进行预处理,对于数据异常的问题,将异常的数据剔除,对于数据缺失问题,根据模型需要数据的格式对数据进行切片,避开存在缺失的部分;分类模块是训练完成的lstm-fcn算法模型,所述lstm-fcn算法模型根据采集的能耗数据对能耗的用户进行行业分类;预测模块为训练完成的多个与用户类型相对应的n-beats算法模型,根据分类模块的结果,将采集的用电数据输入相对应的n-beats算法模型中,对未来特定时间段的用电数据进行预测。电能能耗数据包括用电数据、日期、地区和天气数据;数据采集装置为树莓派,树莓派与电表之间使用rs485总线连接,并通过modbus协议对电表内的数据进行读取;树莓派通过电表所属区域信息从网上获取天气数据,并将获取的用电数据、日期、地区和天气数据存放至mysql数据库。服务器通过用户界面将预测数据及信息向用户展示。[0113]以上所述仅为本技术的优选实施例而已,并不用于限制本技术,对于本领域的技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。[0114]上述虽然对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。当前第1页12当前第1页12
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。