1.本发明属于边缘智能计算领域,具体为一种基于稀疏神经网络的联邦元学习图像分类方法。
背景技术:
2.过去几十年来,智能手机的使用量急剧增加。与经典的pc设备相比,智能手机更便携,用户更容易接受。使用智能手机已经成为现代人日常生活的重要组成部分,而智能手机之间传输的数十亿数据为训练机器学习模型提供了巨大的支持。然而,传统的集中式机器学习要求本地客户端(例如智能手机用户)将数据直接上传到中央服务器进行模型训练,这可能会导致严重的私有信息泄漏。
3.最近提出了一种称为联邦学习的新兴技术,它允许中央服务器训练一个良好的全局模型,同时维护要在客户端设备上分发的训练数据。每个本地客户端都从服务器下载当前的全局模型,而不是直接向中央服务器发送数据,通过本地数据更新共享模型,然后将更新的全局模型上传回服务器。通过避免共享本地私有数据,可以在联邦学习中有效保护用户的隐私,而统计挑战和系统挑战成为算法设计的重要问题。对于统计挑战,由于不同设备间的离散化数据通常是高度个性化和异构的,导致训练的模型精度会显著降低。对于系统性的挑战,设备的数量通常比传统的分布式设置的设备数量大好几个数量级,此外,每个边缘设备在存储、计算和通信能力方面可能有很大的限制。
4.基于初始化的元学习算法,如maml,以快速适应新任务和良好的泛化而闻名,这使得它特别适合于边缘设备数据是非iid且高度个性化的去中心化联邦设置。元学习背后的基本原理是在多个任务上训练模型的初始参数,这样,仅使用与新任务相对应的少量数据,经过预训练的模型快速适应后,在新任务上实现最大性能。受此启发,提出一种联邦元学习方法,其中所有源边缘节点协作学习全局模型初始化,以便在目标边缘节点仅使用少量数据样本更新模型参数时获得最大性能,从而实现实时边缘智能。
5.联邦学习需要大量的通信资源,对于联邦学习的边缘设备通信能力限制,mcmahan等人提出的联邦平均(fedavg)算法可以通过减少本地训练批量大小或增加本地训练次数来减少通信轮次,从而提高通信效率。另一种降低通信成本的方法是通过降低神经网络模型的复杂性来缩小上传的参数。进化人工神经网络的早期思想中提出了系统的神经网络编码方法,然而,其中大多数是直接编码方法,不容易扩展到具有大量层和连接的深层神经网络。为了解决这个问题,增强拓扑的神经进化(neat)和无向图编码提出了增强神经网络编码灵活性的方法。尽管它们能够显著提高编码效率,但neat和无向图方法都占用了太多的计算资源。因此,我们提出从人工神经网络的设计阶段开始追求拓扑稀疏性,这将导致连接的大幅减少,进而提高内存和计算效率。我们进而发现在人工神经网络中,erdos r
è
nyi拓扑结构的稀疏连接层能在不降低精度的情况下替换完全连接的神经网络层,能减少优化包含大量连接的深层神经网络的搜索空间。
技术实现要素:
6.本发明的目的在于提供一种基于稀疏神经网络的联邦元学习图像分类方法,算法性能好,效率高,能够实现快速实时边缘智能。
7.实现本发明目的的技术方案为:一种基于稀疏神经网络的联邦元学习图像分类方法,包括以下步骤:
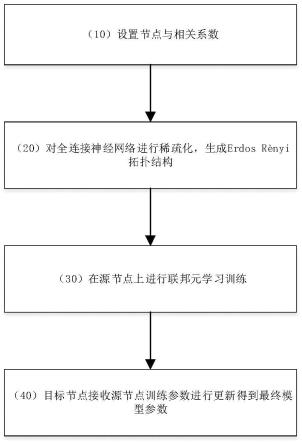
8.(10)设置全连接神经网络节点与相关系数,建立图像分类任务的源节点集合和目标节点集合;
9.(20)对全连接神经网络进行稀疏化,生成稀疏神经网络;
10.(30)初始化稀疏神经网络权重参数,并发送给所有的源节点作为每个源节点的初始参数;
11.(40)基于初始参数,在每个源节点的训练集数据上进行训练,以一步梯度下降进行内部更新;
12.(50)基于每个源节点内部更新后得到的参数,在每个源节点的测试集数据上进行训练,以一步梯度下降进行外部更新;
13.(60)移除外部更新后参数的权重矩阵每层最小的正数与最大的负数,通过判断迭代次数t是否为设置的本地迭代次数的整数倍以做出相应的处理:
14.若迭代次数t不是本地迭代次数的整数倍,则将每个源节点i外部更新后得到的参数作为每个源节点下一轮迭代内部更新的初始参数,判断迭代次数是否达到设置的迭代总次数,若达到则进行步骤(70),否则返回步骤(40);
15.若迭代次数t是本地迭代次数的的整数倍,则在每个源节点i稀疏连接的参数中随机添加与移除的连接相等数目的随机权重参数,将每个源节点i外部更新后得到的稀疏神经网络参数进行加权聚合,将加权聚合后的全局参数作为每个源节点i下一轮迭代内部更新的初始参数,判断迭代次数是否达到设置的迭代总次数,若达到则进行步骤(70),否则返回步骤(40);
16.(70)将源节点进行t次迭代后得到的参数作为每个目标节点的初始参数,以每个目标节点中的训练集数据进行梯度更新训练,得到目标节点微调后的模型参数;
17.(80)利用目标节点微调后的模型进行图像分类。
18.优选地,设置的全连接神经网络节点与相关系数具体包括:图像分类任务的源节点集合s,目标节点集合g,设置迭代总次数t,本地迭代次数t0,内部更新学习率α,外部更新学习率β,每个节点的训练集的数据占比p,稀疏神经网络参数ε。
19.优选地,步骤(20)中稀疏神经网络相邻两层神经元连接的概率为:
[0020][0021]
式中,ε是稀疏参数,,ε《《nk,ε《《n
k-1
,nk和n
k-1
是第k层和k-1层的神经元数量。
[0022]
优选地,内部更新公式具体为:
[0023][0024]
式中,α是内部更新的学习率,表示每个源节点i第t次内部更新时的初始模型参
数,为训练集数据,是每个源节点i的期望损失函数的梯度值,为每个源节点i第t次内部更新后的参数,t=1,2,...,t为迭代次数。
[0025]
优选地,节点的期望损失函数具体为:
[0026][0027]
其中,d表示节点的本地图像数据集{(x1,y1),...,(xj,yj),...,(xd,yd)},|di|表示数据集大小,l(θ,(xj,yj))表示损失函数,(xj,yj)∈d表示节点的本地图像数据集d中第j个图像数据采样点,xj是图像灰度处理后的矩阵,yj是图像类别,θ表示模型化参数。
[0028]
优选地,外部更新公式具体为:
[0029][0030]
式中,表示源节点i第t次外部更新前的参数,β是外部更新学习率,是源节点i测试集数据的期望损失函数的梯度值,是第t次外部更新之后得到的参数。
[0031]
优选地,将每个节点外部更新后得到的稀疏神经网络参数进行加权聚合的具体方法为:
[0032][0033]
其中,s表示所有的源节点i的集合,|di|表示源节点i本地数据集的数据量,是第t次外部更新之后得到的参数。
[0034]
优选地,目标节点t微调后的模型参数φ
t
具体为:
[0035][0036]
式中,α是内部更新学习率,是目标节点t训练集数据的期望损失函数的梯度值,θ为源节点的集合进行t次迭代后得到的外部更新后的参数。
[0037]
本发明与现有技术相比,其显著优点为:
[0038]
1、本发明中每个本地客户端都只与服务器传输模型参数,而不是直接向中央服务器发送数据,通过避免共享本地私有数据,可以在联邦学习中有效保护用户的隐私
[0039]
2、本发明中使用的元学习方法使得特别适合于边缘设备数据是非iid且高度个性化的去中心化联邦设置,在目标节点图像识别任务中可以仅使用少量数据,经过预训练的模型在微调后,就能在目标节点上实现较好的性能。
[0040]
3、本发明中稀疏神经网络的拓扑结构在优化包含大量连接的深层神经网络时减少了搜索空间,降低了通信成本与系统开销。
[0041]
下面结合附图对本发明作进一步详细描述。
附图说明
[0042]
图1是本发明基于稀疏神经网络的联邦元学习图像分类方法的主流程图。
[0043]
图2是图1中源节点进行联邦元学习训练的具体流程图。
[0044]
图3是图1中目标节点接收源节点训练参数后进行更新得到最终模型参数的流程图。
[0045]
图4是对比联邦学习fedavg与基于稀疏神经网络的联邦元学习fedmeta在源节点训练得到的参数传递给目标节点后,目标节点在少量次数迭代后对于图像分类任务的测试损失对比图。
[0046]
图5是对比联邦学习的图像分类方法与基于稀疏神经网络的联邦元学习图像分类方法对于图像进行分类的系统开销的对比图。
具体实施方式
[0047]
本发明基于稀疏神经网络的联邦元学习图像分类方法,基于以下场景来实施:
[0048]
建立边缘计算的场景模型,选择图像分类任务数据集并设置将数据分配给不同的节点以模拟携带数据的边缘设备,将边缘节点分为互不相交的源节点集合s与目标节点集合g。其中源节点的数量大于目标节点的数量,每个节点的数据分为训练集与测试集两部分。
[0049]
如图1所示,一种基于稀疏神经网络的联邦元学习图像分类方法,包括以下步骤:
[0050]
(10)设置全连接神经网络节点与相关系数,设置图像分类任务的源节点集合s,目标节点集合g,设置迭代总次数t,本地迭代次数t0,内部更新学习率α,外部更新学习率β,每个节点的训练集的数据占比p,稀疏神经网络参数ε。
[0051]
(20)对全连接神经网络进行稀疏化,生成稀疏参数为ε的erdos r
è
nyi拓扑结构的神经网络,其中,相邻两层神经元连接的概率为:
[0052][0053]
稀疏层中的神经元连接的连接数nw为
[0054][0055]
其中,表示的是一个随机图wk中相邻的k层和k-1层中任意两个神经元i,j的连接,ε是控制连接稀疏性的实数,ε《《nk,ε《《n
k-1
,nk和n
k-1
是第k层和k-1层的神经元数量。nw是稀疏化之后两层之间的连接总数,相对于nkn
k-1
的全连接数,稀疏化后神经网络的连接数则显著降低。
[0056]
(30)初始化稀疏神经网络权重参数,并发送给所有的源节点作为每个源节点i的初始参数。
[0057]
(40)每个源节点i接收初始参数基于初始参数,在每个源节点i的训练集数据上进行训练,以一步梯度下降进行内部更新,更新公式具体为:
[0058]
[0059]
式中,α是内部更新的学习率,表示每个源节点i第t次内部更新时的初始模型参数,为训练集数据,是每个源节点i的期望损失函数的梯度值,每个源节点i第t次内部更新后的参数为t为迭代次数。
[0060]
其中,节点的期望损失函数具体为:
[0061][0062]
d表示节点的本地图像数据集{(x1,y1),...,(xj,yj),...,(xd,yd)},其中d|表示数据集大小,l(θ,(xj,yj))表示损失函数,(xj,yj)∈d表示节点的本地图像数据集d中第j个图像数据采样点,xj是图像灰度处理后的矩阵,yj是图像类别,θ表示模型化参数。
[0063]
(50)基于每个源节点i第t次内部更新后得到的参数在其测试集数据上进行训练,以一步梯度下降进行外部更新,更新公式具体为:
[0064][0065]
式中,表示每个源节点i第t次外部更新前的参数,β是外部更新学习率,是每个源节点i测试集数据的期望损失函数的梯度值,是第t次外部更新之后得到的参数。
[0066]
(60)移除权重矩阵每层最小的正数与最大的负数。再通过判断迭代次数t是否为t0的整数倍以做出相应的处理:
[0067]
若迭代次数t不是t0的整数倍,则将每个源节点i外部更新后得到的作为下一轮迭代内部更新的初始参数,判断迭代次数是否达到设置的迭代总次数,若达到则进行步骤(70),否则返回步骤(40):
[0068][0069]
若迭代次数t是t0的整数倍,则在每个源节点稀疏连接的参数中随机添加与移除的连接相等数目的随机权重参数,再将每个源节点外部更新后得到的稀疏神经网络参数传输到中央服务器进行加权聚合。
[0070][0071]
其中s表示所有的源节点i的集合,|di|表示每个源节点i本地数据集的数据量。
[0072]
再将加权聚合后的全局参数作为每个源节点i下一轮迭代内部更新的初始参数,判断迭代次数是否达到设置的迭代总次数,若达到则进行步骤(70),否则返回步骤(40)。
[0073][0074]
(70)将源节点进行t次迭代后得到的参数θ,作为每个目标节点t的初始参数,以每个目标节点t中的训练集数据进行梯度更新训练,即得到目标节点t微调后的模型参数φ
t
。
[0075][0076]
式中,α是内部更新学习率,是目标节点t训练集数据的期望损失函数的梯度值。
[0077]
(80)φ
t
即作为每个目标节点的图像分类任务的模型参数,利用微调后的每个目标节点的图像分类任务的模型参数进行图像分类。
[0078]
实施例:
[0079]
选择mnist图像数据集作为模拟实验数据,有两种拆分mnist数据集的方法:一种是iid,其中数据被随机地分配到100个客户机中,每个客户端有600个样本;另一种是非iid,按照标记的类对整个mnist数据集进行排序,然后将其均匀地划分为200个片段,并随机地将其中两个片段分配给每个客户端。在本模拟实验设置中,使用非iid的设置,以最大限度的体现元学习方法的性能。
[0080]
在本发明的方法实验fedmeta中,对于每个节点,将本地数据集划分为一个训练集和一个测试集,稀疏参数ε=20,总共训练次数t=500,本地训练次数t0=10。选择80%的节点作为源节点并在其余目标节点上评估快速自适应性能。将内部更新学习率α和外部更新元学习率β都设置为0.01。改变每个节点的训练集的数据占比,分别设置为80%,50%,5%,基于以上所有参数进行图像分类实验模拟。
[0081]
利用上述数据的设置,通过fedavg实验进行对比。fedavg利用源节点所有数据进行联邦学习训练之后,最终得到的参数在目标节点的训练集进行更新之后再在其测试集数据中进行测试损失评估。
[0082]
根据所有节点的每秒浮点计算次数,以及上传到服务器和从服务器下载的总字节数来描述系统预算,以量化对比fedavg和fedmeta进行图像分类的通信开销。
[0083]
最终实验对比结果如图4、图5所示。
[0084]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
[0085]
应当理解,为了精简本发明并帮助本领域的技术人员理解本发明的各个方面,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时在单个实施例中进行描述,或者参照单个图进行描述。但是,不应将本发明解释成示例性实施例中包括的特征均为本专利权利要求的必要技术特征。
[0086]
应当理解,可以对本发明的一个实施例的设备中包括的模块、单元、组件等进行自适应性地改变以把它们设置在与该实施例不同的设备中。可以把实施例的设备包括的不同模块、单元或组件组合成一个模块、单元或组件,也可以把它们分成多个子模块、子单元或子组件。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。