1.本发明属于数据清洗领域,具有涉及一种自动推断数据清洗脚本的语义的方法。
背景技术:
2.数据清洗(data wrangling,data cleaning)是一种通过清洗和转换操作将复杂凌乱的数据整理成理想数据格式的过程,是数据存取、数据建模和数据可视分析等任务的重要前置步骤。利用python、r等编程语言来编写特定的清洗脚本是完成数据清洗工作的常用手段。在现实工作中,数据工作者通常需要理解清洗脚本中所执行的具体数据清洗过程,即清洗脚本的语义,以了解数据是如何发生变化的。例如,在程序复用中,数据工作者需要学习其它脚本中数据清洗的思路,以修改并应用于自己的数据上;在双重检验中,数据工作者需要验证其他人执行数据清洗的过程,以确保清洗结果的准确性;在代码维护中,数据工作者需要整理没有良好文档记录的代码,以避免维护任务中的错误。
3.完成数据清洗任务需要涉及各种各样的数据转换(data transformation)操作,如填充缺失值、去除重复行、按公式新增列等。数据清洗脚本的语义是指清洗代码所执行的数据转换操作的类型及其参数。例如,给定一行r语言的清洗代码“tb2=arrange(tb1,-num)”,此代码的清洗语义是对输入表tb1的num列做降序排序,然后得到输出表tb2,其中排序操作是一种数据转换操作类型,而排序的列num及降序的排序方式均为该操作的参数。然而,对于数据工作者而言,确定清洗代码中的数据转换操作类型及相关参数并不是件容易的事,其中包含两方面的困难:
4.其一是数据转换操作的种类繁多,部分操作十分复杂。相关研究曾按照操作对象及操作种类的不同将数据转换操作分为了15个大类,21个小类,而小类中又可以继续拆分,部分操作如pivot、unpivot等涉及表结构的转换,理解起来较为困难。因此数据工作者难以掌握全部种类的数据转换操作。
5.其二是实现数据转换操作的编程方式繁多。目前有许多编程语言及其相关的包(库)能够完成数据清洗任务,如python中的pandas包,r中的tidyr、dplyr包等。然而,对于同一种数据转换操作,可以有不同的代码实现方式;并且同一个函数在使用不同参数时也可能会执行不同的操作,这使得不精通这些编程语言的数据工作者难以理解数据清洗代码的语义。此外,初学者要掌握一种新的编程语言或用于数据清洗任务的工具包也需花费大量的时间和精力。
6.总之,理解复杂清洗脚本的语义需要数据工作者具备一定的数据清洗基础和编程技能,并且这个过程常常是枯燥费时且易于出错的。因此,如何帮助数据工作者理解数据清洗脚本中的数据转换语义是一个具有挑战性的研究问题。
7.目前有不少研究工作旨在帮助数据工作者理解清洗脚本的语义,这些工作可大致分为两类:
8.(1)一类是用于代码调试,如工具通过文本总结或可视化的方式能够很好地揭示程序执行一行数据清洗代码后对表格的影响,并支持数据工作者进一步探索及调试代码,
但这类工具都无法直接为数据工作者提供该行代码具体所执行的数据转换操作的类型及其参数;
9.(2)另一类是用于可视化数据清洗脚本的语义,工具能够通过精心设计的图形图符可视化或动画的形式展示清洗语义,虽然这类工具具备推断数据转换操作类型的功能,但它们依赖于一个基于规则的引擎来解析数据清洗脚本的语义,而基于规则的方法拥有较低的泛化性及可扩展性,使得它们难以拓展到不同的编程语言及其他各种清洗函数上。
技术实现要素:
10.本发明提供了一种自动推断数据清洗脚本的语义的方法,该方法能够简单方便的推断清洗代码中的数据转换操作的类型和参数。
11.一种自动推断数据清洗脚本的语义的方法,包括:
12.(1)获得原始表格、数据清洗脚本和多种数据转换操作,将原始表格加载至数据清洗脚本,基于加载后数据清洗脚本采用程序执行器保存每行数据清洗代码对应的输入表格和输出表格;
13.(2)通过每种数据转换操作对应的表格对象在表格属性上的第一表格变化特性构建表格变化空间,将从输入表格到输出表格过程中的表格对象的变化与表格变化空间进行比对得到每行数据清洗代码对应的第二表格变化特性集合;
14.(3)将每种数据转换操作类型对应的第一表格变化特性按照必然发生、不可能发生和可能发生进行划分以构建操作-特性映射表,将操作-特性映射表与第二表格变化特性集合进行比对,将使得第二表格变化特性集合均满足必然发生、不可能发生和可能发生的数据转换操作类型作为候选数据转换操作类型;
15.解析每行数据清洗代码的函数和函数参数,将对应的第二表格变化特性集合中的每个表格变化特性转换为描述性文本,将函数参数,函数和对应的多个描述性文本,通过fasttext嵌入模型进行转换和拼接得到第一语义向量,将第一语义向量输入至孪生卷积神经网络模型,通过与孪生卷积神经网络模型中的第二语义向量集进行比对实现对候选数据转换操作类型的可能性排序;
16.(4)将能够实现每种数据转换操作类型的参数作为参数槽,基于清洗代码按照可能性的排序依次推断候选数据转换操作类型的参数槽,将第一个推断成功的候选数据转换操作的类型和参数作为该行数据清洗代码对应的数据转换操作的类型和参数。
17.基于加载后数据清洗脚本采用程序执行器保存每行数据清洗代码对应的输入表格和输出表格,包括:
18.程序执行器包括程序加工器和程序解释器,程序加工器用于标记加载后的数据清洗脚本中的具有输入输出表格的表格信息数据,程序解释器,用于检测输入输出表格的表格信息数据,并以文件形式保存输入和输出表格。
19.通过将每种数据转换操作对应的表格对象在表格属性上的变化作为第一表格变化特性,第一表格变化特征集构建表格变化空间,其中,表格对象为表、行、列和单元格,表格属性为数量、顺序、关系、值和类型;
20.第一表格变化特性为表格对象在数量、顺序、关系或类型上的变化。
21.孪生卷积神经网络模型的训练过程包括:
22.获得数据清洗脚本,以及该数据清洗脚本中的每行数据清洗代码对应的第二语义向量和所属经过标注的数据转换操作类型,将第二语义向量集作为训练样本集;
23.构建训练模型,训练模型包括两个子网络,每个子网络依次包括多个卷积层和flatten层;
24.基于训练样本集通过对比损失函数训练训练模型得到孪生卷积神经网络模型。
25.孪生卷积神经网络模型包括第二语义向量集,从模型中保存的第二语义向量集中选取一个第二语义向量,且每个第二语义向量与其数据转换操作类型相对应,然后将第一语义向量与每个第二语义向量作为孪生卷积神经网络模型的输入,分别得到第一特征向量和第二特征向量,基于欧式距离计算第一特征向量和第二特征向量的相似程度,按照相似性程度得到每个候选数据转换操作类型的可能性大小。
26.将每种数据转换操作类型对应的第一表格变化特性按照必然发生、不可能发生和可能发生划分得到必然特性组、可能特性组和不可能特性组,以构建操作-特性映射表,其中,必然特性组为该数据转换操作类型操作时输入输出表必定发生的表格变化特性,可能特性组为该数据转换操作类型操作时输入输出表可能发生的表格变化特性,不可能特性组为该数据转换操作类型操作时输入输出表不可能发生的表格变化特性。
27.基于清洗代码按照可能性的排序依次推断候选数据转换操作类型的参数槽,包括:
28.首先基于构建的每种数据转换操作类型的参数槽,获得最大可能性的候选数据转换操作类型参数槽,利用对应行的数据清洗代码、表格内容(表格里的数据内容,即表格里单元格的值)和表格变化信息推断候选数据转换操作类型的参数槽,如果推断成功,则将最大可能性的候选数据转换操作类型和参数作为该行数据清洗代码对应的数据转换操作的类型和参数,如果至少一个参数槽推断不成功则按照推断候选数据转换操作类型的可能性由大到下的顺序依次进行推断,直至推断成功,结束推断。
29.与现有技术相比,本发明的有益效果为:
30.相比于现有工作利用基于规则的方法通过构建清洗函数与数据转换操作之间的映射来推断数据清洗脚本的语义,本发明借助表变化特性和机器学习模型自动推断数据转换操作,具备泛化性强、通用性高的特点,即可支持用不同编程语言及函数库编写的数据清洗脚本,并且支持非赋值语句、非函数等式等多种代码实现方式,极大地丰富了可推断的代码种类。本发明在我们自行收集和标注的数据集上取得了92.2%的类型推断准确率。
31.此外,本发明的输出(即数据清洗脚本中所执行的数据转换操作的类型及其参数)还可应用于多种现有工具中,以增加它们的实用性。如本发明可集成到somnus可视化系统中,以增强其代码解析的鲁棒性,提高其语义推断的能力;本发明还可作为jupyter notebook的插件,用以为清洗代码自动生成文本注释。
附图说明
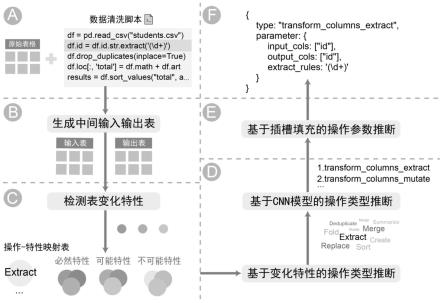
32.图1为具体实施方式提供的自动推断数据清洗脚本的语义的方法流程图;
33.图2为具体实施方式提供的操作-特性映射表与第二表格变化特性集合比对示意图;
34.图3为具体实施方式提供的孪生卷积神经网络模型的架构图;
35.图4为具体实施方式提供的孪生卷积神经网络模型的应用图;
36.图5为具体实施方式提供的自动推断数据清洗脚本的语义的方法集成到somnus可视化系统的效果图;
37.图6为具体实施方式提供的自动推断数据清洗脚本的语义的集成到jupyter notebook交互式编程工具的效果图。
具体实施方式
38.本发明提供一种自动推断数据清洗脚本的语义的方法,如图1所示,包括:
39.s1:生成中间输入表格和输出表格,如图1的a所示:获得原始表格、数据清洗脚本和多种数据转换操作,将原始表格加载至数据清洗脚本,基于加载后数据清洗脚本采用程序执行器保存每行数据清洗代码对应的输入表格和输出表格;程序执行器包括程序加工器和程序解释器,程序加工器用于标记加载后的数据清洗脚本中的具有输入输出表格的表格信息数据,程序解释器,用于检测输入输出表格的表格信息数据,并以文件形式保存输入和输出表格,如图1的b所示。
40.s2:检测表变化特性,构建操作-特性映射表:如图1的c所示,通过每种数据转换操作对应的表格对象在表格属性上的变化作为第一表格变化特性,第一表格变化特征集构建表格变化空间,其中,表格对象为表、行、列和单元格,表格属性为数量、顺序、关系、值和类型;例如,“列”与“数量”的变化特性为在执行完数据转换操作后输入表与输出表的列的数量是否发生变化(如增多,减少,或是不变)。基于此表变化的设计空间,该步骤分别对比并检测输入输出表的四种表格对象在这五种属性上的变化特性,将从输入表格到输出表格过程中的表格对象的变化与表格变化空间进行比对得到每行数据清洗代码对应的第二表格变化特性集合;
41.将每种数据转换操作类型对应的第一表格变化特性按照必然发生、不可能发生和可能发生划分得到必然特性组、可能特性组和不可能特性组,以构建操作-特性映射表,其中,必然特性组为该数据转换操作类型操作时输入输出表必定发生的表格变化特性,可能特性组为该数据转换操作类型操作时输入输出表可能发生的表格变化特性,不可能特性组为该数据转换操作类型操作时输入输出表不可能发生的表格变化特性;
42.例如,给定一行r语言的代码“df=df[df.num》1]”,该行代码所执行的数据转换操作类型为过滤操作,具体语义为“筛选出df表中num列单元格值大于1的数据”。在此操作中,列的数量、列的位置顺序等必定不会发生改变,这些属于必然特性,而行的数量不可能增多、列的数据类型不可能发生变化,这些属于不可能特性。此外,由于df表中num列可能存在大于1的单元格数据,也可能不存在,因此行的数量可能减少,也可能不变,因此这些属于可能特性。
[0043]
如图1的d所示,将操作-特性映射表与第二表格变化特性集合进行比对,将使得第二表格变化特性集合均满足必然发生、不可能发生和可能发生的数据转换操作类型作为候选数据转换操作类型,多个候选数据转换操作类型构建无序候选数据转换操作类型集,如图2所示,具体步骤为:
[0044]
其中包含两条推断策略:(1)若操作-特性映射表中的某个数据转换操作类型,其必然特性组中存在表变化特性集合中不存在的变化特性,则该数据转换操作类型不属于无
序候选数据转换操作类型集。如图2中的t1数据转换操作类型,其必然特性组中存在c1变化特性,但该变化特性并不在已检测到的表变化特性集合中,因此t1数据转换操作类型不在无序候选数据转换操作类型集中;(2)若操作-特性映射表中的某个数据转换操作类型,其不可能特性组中存在表变化特性集合中已存在的变化特性,则该数据转换操作类型不属于无序候选数据转换操作类型集中。如图2中的t3数据转换操作类型,其不可能特性组中存在c2变化特性,同时该变化特性在已检测到的表变化特性集合中也存在,因此t3数据转换操作类型不在无序候选数据转换操作类型集中。由于t2为均满足必然发生、不可能发生和可能发生的数据转换操作类型,因此t2数据转换操作类型在无序候选数据转换操作类型集中。
[0045]
s3:基于cnn模型的操作类型推断:解析每行数据清洗代码的函数和函数参数,将对应的第二表格变化特性集合中的每个表格变化特性转换为描述性文本,如图3所示,通过fasttext嵌入模型将函数参数和函数分别转化为1
×
300维的函数名向量及1
×
300维的函数参数向量,将对应的多个描述性文本转化为1
×
300维的句向量,并对这些句向量按位求均值,得到1
×
300维的变化特性向量;将上述三个向量进行拼接得到一个3
×
300维的第一语义向量,将第一语义向量输入至孪生卷积神经网络模型,通过与孪生卷积神经网络模型中的第二语义向量集进行比对以对候选数据转换操作类型进行可能性排序;该孪生卷积神经网络模型的架构如图3所示,它包含两个相同结构的子网络,且共享权值。每个子网络都由5个卷积层和1个flatten层构成。
[0046]
孪生卷积神经网络模型的训练过程包括:
[0047]
本发明收集了921行数据清洗代码,并为每行代码生成了相应的输入输出表,以及人工标注了该清洗代码所属的数据转换操作类型,以及每行数据清洗代码按照上述语义向量获得方法得到第二语义向量,将第二语义向量集作为训练样本集;
[0048]
构建训练模型,训练模型包括两个子网络,每个子网络依次包括多个卷积层和flatten层;
[0049]
基于训练样本集通过对比损失函数训练训练模型得到孪生卷积神经网络模型。在模型训练完成后,其推断操作类型的top-1准确率高达92.2%。该模型可为数据转换操作候选集中的每个可能的数据转换操作计算可能性,并根据可能性的大小,该子步骤最终输出一个从大到小排好序的操作候选集。
[0050]
如图4所示,孪生卷积神经网络模型包括第二语义向量集,即t
1-t5,从模型中保存的第二语义向量集中选取一个第二语义向量,且每个第二语义向量与其数据转换操作类型相对应,然后将第一语义向量与每个第二语义向量作为孪生卷积神经网络模型的输入,分别得到第一特征向量和第二特征向量,基于欧式距离计算第一特征向量和第二特征向量的相似程度,按照相似性程度得到候选数据转换操作类型t5的可能性大小,如图1的d所示。
[0051]
s4:数据转换操作的参数推断。将能够实现每种数据转换操作类型的参数作为参数槽,基于清洗代码按照可能性的排序依次推断候选数据转换操作类型的参数槽,将第一个推断成功的候选数据转换操作的类型和参数作为该行数据清洗代码对应的数据转换操作的类型和参数。如图1的e所示。具体步骤为:
[0052]
(1)为每一种数据转换操作预定义该操作所需的参数,即槽。例如,排序操作拥有4个参数槽,分别是输入表槽、输出表槽、排序列槽及排序方式槽;(2)利用对应行的数据清洗代码、表格内容和表格变化信息,即表格变化特性集合,为操作候选集中最大可能性的数据
转换操作推断其参数槽值。以清洗代码“tb2=arrange(tb1,-num)”为例,若操作候选集中最大可能性的数据转换操作类型是排序操作,则该步骤根据排序操作的参数槽为其填充槽值。在上述例子中,输入表槽和输出表槽的槽值可由步骤s1的处理结果直接得到,分别是tb1和tb2。为了继续推出排序列槽及排序方式槽的槽值,该步骤首先提取出清洗代码中涉及的列名,即num。然后根据表变化特性集合或者直接从输出表中查看num列是否是有序状态。在本例中,输出表的num列是降序状态,符合排序操作的执行结果。因此该排序操作的排序列槽值为num列,而排序方式槽值为降序排序。对于不同数据转换操作类型,由于其参数槽的不同,其槽值的推断方法也不尽相同;(3)若最大可能性的数据转换操作类型的参数能成功推出,则结束推断任务,得到该行代码的最终数据转换操作类型及其参数;若不能成功推出,则按照可能性大小选取操作候选集中其次可能性的数据转换操作继续推断其参数。重复该步骤,直至成功推断出操作类型的参数为止。例如,在上述例子中,若输出表中num列并不是有序状态,则不符合排序操作的执行结果,因此排序操作的参数无法成功推出,此时则选择操作候选集中第二可能性的数据转换操作,并根据该操作类型的参数槽推断其槽值。在推断完成后,该步骤确定并输出此行数据清洗代码的数据转换操作类型及其参数,如图1的f所示。
[0053]
发明可应用到许多已有工具中,以增加它们的实用性。以下是本发明的两个应用案例:
[0054]
集成到申请号为202210066324x的专利公开的somnus可视化系统中。somnus可视化系统利用基于图形图符的有向无环图展示数据清洗代码的语义,但由于somnus采用基于规则的方法推断清洗代码的数据转换操作类型及其参数,因此其拓展性和泛化性受限。为了提高somnus的推断能力,本发明的自动推断语义的技术方法可应用于somnus的后端,替换其原有的程序适配器模块,使得somnus能推断更加丰富的清洗代码。图5展示了somnus系统原本无法支持、但集成了本发明的技术方法后可成功推断出代码语义的三个例子,分别是可帮助somnus推断extract函数等式、非等式语句(即没有赋值等号的语句)和非函数等式(即没有调用函数的赋值语句)的清洗语义。
[0055]
集成到jupyter notebook交互式编程工具中。现如今,越来越多的数据工作者采用如jupyter notebook等基于web的交互式叙事编程平台完成代码编写工作,同时还会写下代码注释以方便分享。然而手动编写注释是件费时枯燥的工作。为了减轻数据工作者编写清洗代码的注释的负担,可将本发明集成到jupyter notebook中作为一个应用插件,以自动为数据清洗代码生成相应的代码注释。该插件利用本发明的语义推断结果(即数据转换操作类型及其参数)根据相应的数据转换操作注释模板,自动生成注释文本,并调用jupyter插件api将该注释文本插入到对应的清洗代码上方。如图6的a和b为两个清洗代码单元,当编写完清洗代码后,点击右上方的集成插件如图6的c,即可为notebook中的清洗代码生成注释文本如图6的d。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
