基于遗传优化算法的双层bp神经网络水质预测方法及系统
技术领域
1.本发明涉及水体水质预测领域,具体涉及基于遗传优化算法的双层bp神经网络水质预测方法及系统。
背景技术:
2.湖泊在水生生态系统和人类社会的发展中发挥着重要作用。据统计,湖泊环境可能受到各种人类活动的影响,全球99.8%以上的湖泊污染与人类活动有关。频繁的人类活动,如农村地区过度使用农药和化肥、排放牲畜和家禽废水,大量生活污水产生、污水收集和处理设施不完善,城市土地增加、城市化增加,以及各种工业活动导致河流水质恶化。湖泊中污染物的持续存在也会影响自然生态系统和人体。例如,用于灌溉的高盐和高碱度水可能会破坏土壤聚集体,减少粮食产量,以及氮磷含量过高造成水体富营养化。因此,为了控制水污染、保护水资源和支持生态可持续的发展,了解湖泊中染物的浓度、来源、分布和风险水平非常重要。政府已经建立了一个湖泊水质监测系统,它已经收集了大量的数据,包括物理特性和生物参数;从这些复杂的数据集中提取有效信息和实施全面和定量的水质评价对于有效地评估河流水环境至关重要。对于水质情况的预测分类对水资源的使用影响广大,不同质量的水资源的处理方案不同,而对于水质的预测过程,人工神经网络算法近几年在分类预测领域有着很大的应用,在河水水质预测,海水水质预测,以及后续的污染物分析都有着广泛的应用。
3.现存技术可以实时监测水质,但是由于湖泊水质的稳定性是可以实现提前预测的功能的,但大多数现有技术缺乏针对可能预测的污染程度,提前采取措施提高水质,导致在实际应用中,需要在出现了污染情况后再去解决,现有技术缺乏针对水体水质改良的先验性。
4.公布号为cn107153874a的现有发明专利文献《水质预测方法及系统》使用arima自回归积分滑动平均模型与bp神经网络相结合的方法对水质时间序列数据的预测,对待预测水域大量水质数据进行预测。该现有技术采用arima自回归积分滑动平均模型与bp神经网络相结合,需要进行例如确定时间序列分析模型的阶数等一系列操作,同时还需要采用自相关函数及偏自相关函数进行模型识别,其预测水质所需参数量较大,且过程复杂,整体系统算法的鲁棒性较低。
5.公布号为cn105913411a的现有发明专利申请文献《一种基于因子定权模型的湖泊水质评价预测系统及方法》包括:通过不同湖泊区域污染热力图着色情况,了解到各湖泊污染对比度;通过获取湖泊流域天气指数,向用户反馈时间向量性天气温度信息和各天气指数;改进的因子定权模型成果展示;结合相关分析算法对当前各项超标水质指标和预测超标指标向用户发出警报。本发明建立了能够更加准确的对水质做出评定的因子定权评价模型。该现有技术采用的定权因子为针对特定种类参数,例如图像热力数据等数据进行处理得到,可见该现有技术对水体污染参数处理的参数形式以及数据处理逻辑较为单一,且该方案采用的权重矩阵在具体的应用场景中,无法充分表征不同水体应用场景中的差异参
数,限制了该现有方案的使用场景种类,该现有技术的适用性较低。
6.综上,现有技术存在污染治理效果差、缺乏先验性、水质预测过程繁复以及适用性较低的技术问题。
技术实现要素:
7.本发明所要解决的技术问题在于如何解决现有技术中污染治理效果差、缺乏先验性、水质预测过程繁复以及适用性较低的技术问题。
8.本发明是采用以下技术方案解决上述技术问题的:基于遗传优化算法的双层bp神经网络水质预测方法包括:
9.s1、从预置存储中获取历史水质监测数据,据以作为训练集,并从监测站中获取水质标准数据以及监测点输入样本数据;
10.s2、初始遗传种群;
11.s3、对监测点输入样本数据进行数据清洗,利用拉格朗日插值法对存在缺失的监测点输入样本数据进行补充;
12.s4、利用主成分分析法处理水质标准数据,以得到主要污染条件;
13.s5、利用预置智能遗传算法,对水质标准数据进行实数编码并进行归一化处理;
14.s6、根据预置定义逻辑得到惩罚函数,选择并复制优良个体参数作为父体参数进行繁殖处理,并适应调整惩罚函数,设定并采用特定基因位置作为交叉点,以交叉处理历史水质监测数据,挑选预置比例的个体参数的预置基因参数,以利用预置变异算子进行变异处理,以得到变异参数;
15.s7、在变异参数不满足预设优化准则时,生产新种群,并循环执行步骤s3至s6;
16.s8、在变异参数满足预设优化准则时,以双层bp神经网络根据训练集中的教师信号进行前向操作,以利用预置前向逻辑处理得到样本误差,据以获取目标函数最小二乘表示关系数据,利用连续微分链规则,以预置反向逻辑获取隐含误差及多层神经元误差,以得到权重梯度,据以更新权重数据,根据权重数据及主要污染条件处理得到水质预测结果。
17.本发明对监测点的污染指标进行数据收集,并进行数据清洗后对关键污染指标确认,并进行遗传-双层bp神经网络模型预测,通过改良的双层bp神经网络预测结果可以准确预测实时监测结果,对后续的污染因素预判提供了可靠的方案。本发明对于可能预测的污染程度,可以提前采取措施提高水质,而不是出现了污染情况再去解决,这样就提升了水质改良的先验性,使得预测结果更具有实用性。
18.在更具体的技术方案中,步骤s3包括:
19.s31、对于缺失维度为1的监测点输入样本数据,利用拉格朗日插值算法,以下述逻辑进行数据补充:
[0020][0021]
其中,th,t,t
h 1
为相邻的3天数值,xh,x,x
h 1
为相邻的3天的水质指标;
[0022]
s32、淘汰处理缺失维度超过2个的监测点输入样本数据,以得到适用监测点数据;
[0023]
s33、利用最值归一法,以下述逻辑归一化处理适用监测点数据,步骤s33包括:
[0024]
s331、以下述逻辑预处理适用监测点数据:
[0025][0026]
s332、以下述逻辑反预处理适用监测点数据:
[0027][0028]
其中,x为水质的原始数据,x’为处理后的数据。
[0029]
本发明针对水质数据范围波动较大时,影响数学模型的收敛速度的问题,通过改进的最值归一法,避免0值的出现,优化的水质预测效果。本发明采用湖泊数据清洗模式,针对部分缺失的数据采取拉格朗日插值法进行补充,因为湖泊数据具有后影响性,避免因盲目舍去数据造成的数值误差。
[0030]
在更具体的技术方案中,步骤s4包括:
[0031]
s41、根据监测点输入样本数据获取协方差矩阵;
[0032]
s42、利用主成分分析法pca从协方差矩阵中提取特征值和相关数据;
[0033]
s43、通过varimax旋转操作,线性组合监测点输入样本数据,据以生成新正交变量,据以获取主要污染条件。
[0034]
本发明利用pca从第一手数据的协方差矩阵中提取特征值和相关,并通过varimax旋转生成新的正交变量。本发明需要处理的数据被减少,原始信息的损失最小,保持最有意义的参数的信息。保证了水质预测的准确率,同时提高了预测效率。
[0035]
在更具体的技术方案中,步骤s5包括:
[0036]
s51、获取并根据实际编码需求数据,将水质标准数据实数编码为9位;
[0037]
s52、给出实数编码范围:
[0038]
min={1,1,1,1,5,0,0,0,0,0},max={10,10,10,10,10,10,10,15,2,0.5}。
[0039]
本发明采用的实数编码过程会删除重复结果,并且可以自动生成相应的非支配排序等级,支配个体数,支配个体组成的集合,提供了水质预测精度。
[0040]
在更具体的技术方案中,步骤s6包括:
[0041]
s61、利用下述逻辑定义惩罚函数的最大值集为所有的约束条件的最大值组成的集合,并定义惩罚函数的最小值集为所有的约束条件的最小值组成的集合:
[0042][0043]
其中,φ是惩罚函数,ri是惩罚因子,fi(x)为某种指标的数值,如fn(x)为含氨氮量的指标数值;
[0044]
s62、获取并根据适应度值选择复制优良个体,以作为父体进行繁殖;
[0045]
s63、利用单点交叉模式确定一个基因位置作为交叉点,并进行归一化处理得到交叉参数;
[0046]
s64、利用变异算子pm根据交叉参数,随机挑选5%的个体的第7列基因进行变异,并进行归一化处理得到变异参数;
[0047]
s65、在变异参数满足预置算法终止条件时,结束执行只能遗传算法,其中算法终止条件包括目标函数稳定状态:
[0048]
|j
i-j
i-1
|《ε。
[0049]
其中,ε为允许的误差范围,通常设为0.05。
[0050]
在更具体的技术方案中,步骤s61中,以下述逻辑表示氨氮指数的约束:
[0051][0052]
其中,q
na
是氨氮值的上限,q
nb
是氨氮值的下限,fn(x)为含氨氮量的指标数值对于差异约束的惩罚函数放至100。
[0053]
在更具体的技术方案中,步骤s8包括:
[0054]
s81、对应m个样本,选定对应的教师信号{d1,d2,...,d
p
};
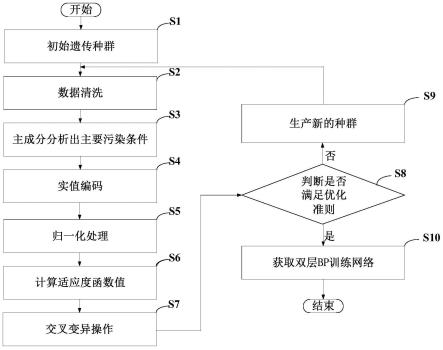
[0055]
s82、利用前向操作,以下述激活函数为relu函数:
[0056]
f(x)=max{0,x}
[0057]
据以根据教师信号产生对应输出元
[0058]
s83、利用下述逻辑处理对应输出元,以得到样本误差:
[0059][0060]
s84、利用下述逻辑处理样本误差,以得到目标函数最小二乘表示关系数据:
[0061][0062]
s85、利用反向操作,利用连续微分链规则处理得到隐含层误差,xi是第i个神经元,输入层是第0层,yi是第i个隐含1层,zi是第i个输出样本;
[0063]
s86、处理隐含层误差,据以得到多层神经元误差;
[0064]
s87、以下述逻辑处理多层神经元误差及隐含层误差,据以得到权重梯度:
[0065][0066]
其中,为第二层第i个误差、i为任意数、j第一层指标个数、k第二层指标个数、l输出层指标数、w
l 1k,j
输出层加权系数、输出层第i 1个误差、输出误差。
[0067]
本发明反向传播将每层节点的误差作为反向输入,这样就把误差当做输入层一样往回传播。可得每一个权重的梯度都是前一层节点的输出乘以后一层的反向传播输出,这样就更新了权重。同时激发函数采用rule函数,加快收敛,解决弥漫梯度的问题。
[0068]
在更具体的技术方案中,步骤s85中,利用连续微分链规则,以下述逻辑处理得到隐含层误差:
[0069][0070]
[0071][0072][0073]
其中,a为输出样本加权系数的适配常数,b为输出样本适配常数,zi是第i个输出样本,w
ki
是第i个加权系数。
[0074]
在更具体的技术方案中,步骤s86中,利用下述逻辑处理隐含层误差,据以得到多层神经元误差:
[0075][0076]
在更具体的技术方案中,基于遗传优化算法的双层bp神经网络水质预测系统包括:
[0077]
原始数据模块,用以从预置存储中获取历史水质监测数据,据以作为训练集,并从监测站中获取水质标准数据以及监测点输入样本数据;
[0078]
种群初始模块,用以初始遗传种群;
[0079]
数据清洗模块,用以对监测点输入样本数据进行数据清洗,利用拉格朗日插值法对存在缺失的监测点输入样本数据进行补充,数据清洗模块与原始数据模块连接;
[0080]
主要调节分析模块,用以利用主成分分析法处理水质标准数据,以得到主要污染条件,主要调节分析模块与原始数据模块连接;
[0081]
实数编码模块,用以利用预置智能遗传算法,对水质标准数据进行实数编码并进行归一化处理,实数编码模块与原始数据模块连接;
[0082]
个体繁殖及交叉变异模块,用以根据预置定义逻辑得到惩罚函数,选择并复制优良个体参数作为父体参数进行繁殖处理,并适应调整惩罚函数,设定并采用特定基因位置作为交叉点,以交叉处理历史水质监测数据,挑选预置比例的个体参数的预置基因参数,以利用预置变异算子进行变异处理,以得到变异参数,个体繁殖及交叉变异模块与种群初始模块、数据清洗模块及实数编码模块连接;
[0083]
新种群生产模块,用以在变异参数不满足预设优化准则时,生产新种群,新种群生产模块与个体繁殖及交叉变异模块及种群初始模块连接;
[0084]
水质预测模块,用以在变异参数满足预设优化准则时,以双层bp神经网络根据训练集中的教师信号进行前向操作,以利用预置前向逻辑处理得到样本误差,据以获取目标函数最小二乘表示关系数据,利用连续微分链规则,以预置反向逻辑获取隐含误差及多层
神经元误差,以得到权重梯度,据以更新权重数据,根据权重数据及主要污染条件处理得到水质预测结果,水质预测模块与新种群生产模块及数据清洗模块连接。
[0085]
本发明相比现有技术具有以下优点:本发明对监测点的污染指标进行数据收集,并进行数据清洗后对关键污染指标确认,并进行遗传-双层bp神经网络模型预测,通过改良的双层bp神经网络预测结果可以准确预测实时监测结果,对后续的污染因素预判提供了可靠的方案。本发明对于可能预测的污染程度,可以提前采取措施提高水质,而不是出现了污染情况再去解决,这样就提升了水质改良的先验性,使得预测结果更具有实用性。
[0086]
本发明针对水质数据范围波动较大时,影响数学模型的收敛速度的问题,通过改进的最值归一法,避免0值的出现,优化的水质预测效果。本发明采用湖泊数据清洗模式,针对部分缺失的数据采取拉格朗日插值法进行补充,因为湖泊数据具有后影响性,避免因盲目舍去数据造成的数值误差。
[0087]
本发明利用pca从第一手数据的协方差矩阵中提取特征值和相关,并通过varimax旋转生成新的正交变量。本发明需要处理的数据被减少,原始信息的损失最小,保持最有意义的参数的信息。保证了水质预测的准确率,同时提高了预测效率。
[0088]
本发明采用的实数编码过程会删除重复结果,并且可以自动生成相应的非支配排序等级,支配个体数,支配个体组成的集合,提供了水质预测精度。
[0089]
本发明反向传播将每层节点的误差作为反向输入,这样就把误差当做输入层一样往回传播。可得每一个权重的梯度都是前一层节点的输出乘以后一层的反向传播输出,这样就更新了权重。同时激发函数采用rule函数,加快收敛,解决弥漫梯度的问题。本发明解决了现有技术中存在的污染治理效果差、缺乏先验性、水质预测过程繁复以及适用性较低的技术问题。
附图说明
[0090]
图1为本发明实施例1的基于遗传优化算法的双层bp神经网络水质预测方法步骤示意图;
[0091]
图2为本发明实施例1的智能遗传算法具体步骤示意图;
[0092]
图3为本发明实施例1的双层bp结构示意图;
[0093]
图4为本发明实施例1的双层bp神经网络的数据处理过程示意图;
[0094]
图5为本发明实施例2的实时数据、bp预测分类、遗传 bp预测分类对比图。
具体实施方式
[0095]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0096]
实施例1
[0097]
如图1所示,本发明提供基于遗传优化算法的双层bp神经网络水质预测方法包括以下步骤:
[0098]
s1、初始遗传种群;
[0099]
s2、数据清洗;
[0100]
s3、主成分分析出主要污染条件;
[0101]
s4、实值编码;
[0102]
s5、归一化处理;
[0103]
s6、计算适应度函数值;
[0104]
s7、交叉变异操作;
[0105]
s8、判断是否满足优化准则;
[0106]
s9、若否,则生产新的种群;
[0107]
s10、若是,则获取双层bp训练网络。
[0108]
如图2所示,本发明提供的基于遗传优化算法的双层bp神经网络水质预测方法中采用的智能遗传算法,包括以下具体步骤:
[0109]
s1’、通过实数编码操作删除重复信息,并生成个体支配信息;
[0110]
根据实际需要,实数编码为9位,前4位位混掺煤序号,后4位位混掺煤配比,并给出相应的范围:
[0111]
min={1,1,1,1,5,0,0,0,0,0},max={10,10,10,10,10,10,10,15,2,0.5}
[0112]
算法过程会删除重复结果,并且可以自动生成相应的非支配排序等级,支配个体数,支配个体组成的集合。
[0113]
s2’、定义并调整惩罚函数;
[0114]
定义惩罚函数的最大值集为所有的约束条件的最大值组成的集合,惩罚函数的最小值集为所有的约束条件的最小值组成的集合。
[0115]
目标函数j的最小化:其中φ是惩罚函数,ri是惩罚因子
[0116]
比如对于氨氮指数的约束
[0117][0118]
其中q
na
是氨氮值的上限,q
nb
是氨氮值的下限,对于不同的约束,为了节省时间,本发明将惩罚函数均放到100
[0119]
s3’、选择优良个体进行繁殖;
[0120]
选择和复制优良个体作为父体进行繁殖,判断个体是否优良是看适应度的值,适应度越好,就复制,适应度不好,则引入惩罚函数,惩罚范围放到103.
[0121]
s4’、利用交叉算子进行交叉操作;
[0122]
由于数据体量庞大,为了快速收敛,本发明采取单点交叉的模式,等概率的随机确定一个基因位置作为交叉点,如果是8列数,本发明选取第6个作为基因点,进行交叉。并把结果进行归一化处理。
[0123]
s5’、利用变异算子pm进行基因变异操作;
[0124]
随机挑选5%的个体的第7列基因进行变异,需要归一化处理。
[0125]
s6’、判断是否符合算法终止条件,若是,则结束智能遗传算法,若否,则循环执行
前述步骤s1’至s5’。
[0126]
目标函数出现稳定状态即
[0127]
|j
i-j
i-1
|《ε
[0128]
双层bp神经网络:
[0129]
如图3所示,在本实施例中,双层双层bp神经网络算法,xi是第i个神经元,输入层是第0层,yi是第i个隐含1层,zi是第i个输出样本,对应m个样本,选定对应的教师信号{d1,d2,...,d
p
}。
[0130]
如图4所示,在本实施例中,双层bp神经网络的数据处理过程包括以下具体步骤:
[0131]
s101、利用前向过程获取样本误差;
[0132]
在本实施例中,上一层的神经元的输出为下一层神经元的输入,本发明采取的激活函数为relu函数:
[0133]
f(x)=max{0,x}
[0134]
产生相应的输出元如此可以求得样本误差即
[0135]
可得目标函数用最小二乘法表示为
[0136]
s102、利用反向过程获取隐含层误差及多层神经元误差;
[0137]
在本实施例中,对于隐含层的误差,由于连续微分链规则可得多层神经元误差。
[0138]
隐含层误差:
[0139][0140][0141][0142][0143]
第i层第j个神经元的误差
[0144][0145]
可得权重梯度
[0146]
反向传播将每层节点的误差作为反向输入,这样就把误差当做输入层一样往回传播。可得每一个权重的梯度都是前一层节点的输出乘以后一层的反向传播输出,这样就更新了权重。
[0147]
同时激发函数采用rule函数,加快收敛,解决弥漫梯度的问题
[0148]
f(x)=max{0,x}
[0149]
数据清洗:
[0150]
对于拿到的21个监测点的数据,本发明对于原始数据进行清洗。
[0151]
对于缺失维度为1的数据进行拉格朗日插值算法进行补充
[0152][0153]
其中th,t,t
h 1
为相邻的3天数值,xh,x,x
h 1
为相邻的3天的水质指标
[0154]
对于缺失维度超过2个的数据进行淘汰处理
[0155]
对剩下的数据进行归一化处理:
[0156]
当水质数据范围波动较大时,会影响数学模型的收敛速度,因此需要预处理。通过改进的最值归一法,可以避免0值的出现。
[0157]
数据预处理公式:
[0158][0159]
数据反预处理公式化:
[0160][0161]
其中x为水质的原始数据,x’为处理后的数据。
[0162]
主成分分析法:
[0163]
主成分分析(pca)是一种常用的源分配方法。pca从第一手数据的协方差矩阵中提取特征值和相关,并通过varimax旋转(即原始数据的线性组合)生成新的正交变量。数据被减少,原始信息的损失最小,保持最有意义的参数的信息。
[0164]
污染指标:
[0165]
常用的水质检测指标是ph,溶解氧,高锰酸盐指数,氨氮,总磷。对应国家地表水质监测标准,本发明得到相关的限制量:
[0166][0167]
表1国家检测标准范围。
[0168]
实施例2
[0169]
本发明提出一种基于遗传优化算法的的双层bp神经网络的巢湖水质预测评价模型。该模型对于巢湖21个监测点的污染指标进行近一整年的数据收集,并进行数据清洗后对关键污染指标确认,并进行遗传-双层bp神经网络模型预测,该实验证明通过改良的双层bp神经网络预测结果可以准确预测实时监测结果,对后续的污染因素预判提供了可靠的方案。
[0170]
数据来源
[0171]
巢湖位于长江中下游,由合肥肥东、肥西、庐江一市三县环抱,位于安徽省中部合肥市,中国五大淡水湖之一,鱼虾储量极大,对整个安徽省,江苏省居民用水,食用鱼虾有着重要的影响。选取2022年上一整年数据作为训练集,7月11日数据作为教师集,从巢湖及其支流21个监测站获得水温,ph值,溶解氧,电导率,浊度,高锰酸盐指数(codmn),氨氮(nh3),总磷,总氮等以中国地表水环境质量标准作为数据的分析标准。
[0172]
数据选取
[0173]
选取1-6月的巢湖水域的历史数据作为训练集,选取7.11日的巢湖水域的监测结果为教师集,经过数据清洗后可以得到表2中的数据(7.11日数据)。
[0174][0175]
表2 7月11日巢湖水域检测结果清洗后数据对于数据进行方案编码,对所有数据进行归一化处理,
[0176][0177]
得到归一后的函数据
[0178]
根据主成分分析法,选定国家标准的5项主要指标:ph,溶解氧,高锰酸盐指数,氨氮,总磷。对超过指标的数据进行剔除后,采取通过双层bp神经网络对于现有数据进行分类以及预测。对于神经网络模型隐含层采用的激活函数是logsig,输出层采用的激活函数是purelin,训练方法采用的是trainlm,训练次数为100次,训练目标为0.1,学习率为0.1。可得预测分类和实际分类,不同预测方法对比如表3(7月11日实时数据部分)。
[0179][0180][0181]
表3通过双层bp神经网络预测值和遗传 双层bp神经网络预测值与7.11日的检测值的对比结果
[0182]
如图5所示,本发明将7.11日实时监测数据与近一整年的累计数据通过双层bp神经网络预测分类结果和遗传-双层bp神经网络预测分类结果进行对照,可以得到实时数据、bp预测分类、遗传 bp预测分类对比结果。
[0183]
综上,本发明对监测点的污染指标进行数据收集,并进行数据清洗后对关键污染指标确认,并进行遗传-双层bp神经网络模型预测,通过改良的双层bp神经网络预测结果可以准确预测实时监测结果,对后续的污染因素预判提供了可靠的方案。本发明对于可能预测的污染程度,可以提前采取措施提高水质,而不是出现了污染情况再去解决,这样就提升了水质改良的先验性,使得预测结果更具有实用性。
[0184]
本发明针对水质数据范围波动较大时,影响数学模型的收敛速度的问题,通过改进的最值归一法,避免0值的出现,优化的水质预测效果。本发明采用湖泊数据清洗模式,针对部分缺失的数据采取拉格朗日插值法进行补充,因为湖泊数据具有后影响性,避免因盲
目舍去数据造成的数值误差。
[0185]
本发明利用pca从第一手数据的协方差矩阵中提取特征值和相关,并通过varimax旋转生成新的正交变量。本发明需要处理的数据被减少,原始信息的损失最小,保持最有意义的参数的信息。保证了水质预测的准确率,同时提高了预测效率。
[0186]
本发明采用的实数编码过程会删除重复结果,并且可以自动生成相应的非支配排序等级,支配个体数,支配个体组成的集合,提供了水质预测精度。
[0187]
本发明反向传播将每层节点的误差作为反向输入,这样就把误差当做输入层一样往回传播。可得每一个权重的梯度都是前一层节点的输出乘以后一层的反向传播输出,这样就更新了权重。同时激发函数采用rule函数,加快收敛,解决弥漫梯度的问题。本发明解决了现有技术中存在的污染治理效果差、缺乏先验性、水质预测过程繁复以及适用性较低的技术问题。
[0188]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。